前言
爬蟲是門很有意思的技術,可以通過爬蟲技識訓取一些別人拿不到或者需要付費才能拿到的東西,也可以對大量資料進行自動爬取和保存,減少時間和精力去手動做一些累活,
可以說很多人學編程,不玩點爬蟲確實少了很多意思,不管是業余、接私活還是職業爬蟲,爬蟲世界確實挺精彩的,
今天來給大家淺談一下爬蟲,目的是讓準備學爬蟲或者剛開始起步的小伙伴們,對爬蟲有一個更深更全的認知,

文章目錄
- 前言
- 一、認識爬蟲
- 1.什么是爬蟲?
- 2.爬蟲的分類
- 3.Robots協議
- 二、爬蟲的基本流程
- 1.爬蟲的4步
- 2.Request和Response
- 三、了解Request
- 1.請求方式
- 2.請求URL
- 3.請求頭
- 4.請求體
- 5.實操查看Request
- 四、了解Response
- 1.回應狀態
- 2.回應頭
- 3.回應體
- 五、爬蟲能獲取到什么樣的資料?
- 六、如何決議資料?
- 七、怎么保存資料?
一、認識爬蟲
1.什么是爬蟲?
用一句話來給大家介紹大名鼎鼎的爬蟲:請求網站并提取資料的自動化程式,
我們來拆開理解一下爬蟲:
請求網站的意思就是向網站發送請求,比如去百度搜索關鍵字“Python”,這個時候我們的瀏覽器就會向網站發送請求;
提取資料,資料包括了圖片、文字、視頻等等,都叫資料,在我們發送請求之后,網站會呈現搜索結果給我們,這其實就是回傳了資料,這時候我們就可以對資料進行提取;
自動化程式,也就是我們寫的代碼,實作了自動提取程資料,比如批量對回傳的圖片進行下載和保存,替代我們一張一張圖片進行手工操作,

2.爬蟲的分類
根據使用場景,爬蟲可以分為三類:
①通用爬蟲(大而全)
功能強大,采集面廣泛,通常用于搜索引擎,比如百度瀏覽器就是一個很大的爬蟲程式,
②聚焦爬蟲(小而精)
功能相對單一,只針對特定網站的特定內容進行爬取,比如說去某個網站批量獲取某些資料,這也是我們個人最常用的一種爬蟲了,
③增量式爬蟲(只采集更新后的內容)
這其實是聚焦爬蟲的一個迭代爬蟲,它只采集更新后的資料,對老資料是不采集,相當于一直存在并運行,只要有符合要求的資料更新了,就會自動爬取新的資料,

3.Robots協議
在爬蟲中有一個叫Robots協議需要注意一下,又稱為“網路爬蟲排除標準”,它的作用就是網站告訴你哪些東西能爬,哪些不能爬,
這個Robots協議去哪看?一般情況下直接在網站首頁網址后面加/robots.txt就能查看,比如百度的Robots協議就在https://www.baidu.com/robots.txt ,可以看到里面有很多網址都規定了不能爬,比如Disallow:/shifen/ 說明當前Disallow:/shifen以及Disallow:/shifen下面的子目錄網頁均不能爬,
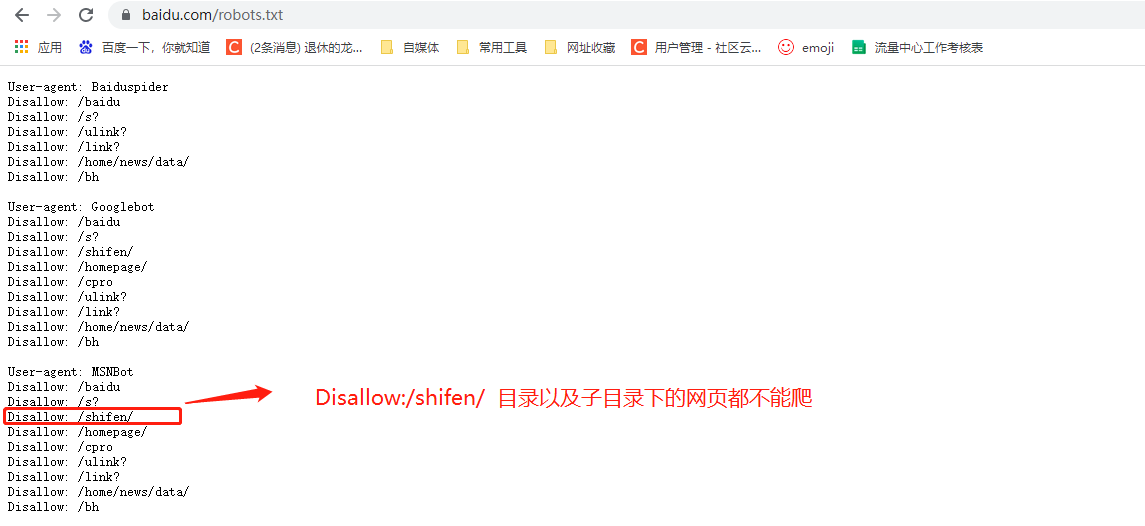
其實這個Robots協議屬于一個君子協議,對于爬蟲者來說,基本上就是口頭協議,你違反了它你有可能會被追究法律責任,但不違反它,爬蟲將是爬不到什么資料,所以平時雙方都是睜一只閉一眼,不要太囂張就可以了,

二、爬蟲的基本流程
1.爬蟲的4步
爬蟲是怎么干活的?爬蟲程式大致上可以分為四步走:
①發起請求
通過HTTP庫向目標站點發起請求,即發送一個Request,請求可以包含額外的headers等資訊,等待服務器回應,
②獲取回應內容
如果服務器能正常回應,會得到一個Response,Response的內容便是所要獲取的頁面內容,型別可能有HTML、Json字串和二進制資料(如圖片視頻)等型別,
③決議內容
得到的內容可能是HTML,可以用正則運算式、網頁決議庫進行決議,可能是Json,可以直接轉為Json物件決議,可能是二進制資料,可以做保存或者進一步的處理,
④保存資料
保存的資料樣式很多,可以保存為文本,也可以保存至資料庫,或者保存為特定格式的檔案,
基本上這就是爬蟲要遵循的四步了,
2.Request和Response
Request和Response是爬蟲中最重要的一部分,Request和Response是什么關系?它們兩的關系如下圖:
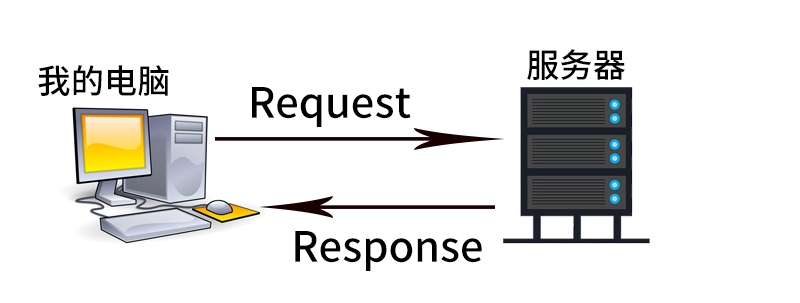
簡單理解一下,當我們在電腦的瀏覽器上搜索某個東西的時候,比如前面的所說的在百度搜索“Python”,你點擊百度一下,就已經向百度的服務器發送了一個Request請求,Request包含了很多的資訊,比如身份資訊、請求資訊等等,服務器接收請求之后做判斷,然后回傳一個Response給我們的電腦,這其中也包含了很多資訊,比如請求成功與否,比如我們請求的資訊結果(文字、圖片和視頻等等),
這樣講應該很好理解吧?接下來我們再好好去看一下Request和Response,
三、了解Request
Request包含了哪些東西?它主要包含了以下一些東西:
1.請求方式
請求方式可以理解為你跟網站打招呼的方式,你要從網站拿到資料,你就得用正確的方式去跟它打招呼,它才有可能理你,就好比你要別人家借個東西,你得先敲門再說你好,你直接爬窗戶進去這誰瞧見了都得給你攆出去,

主要的請求方式有GET和POST,另外還有HEAD/PUT/DELETE/OPTIONS等等其他方式,其中最常用的還是GET這種請求方式,
2.請求URL
什么是URL?URL全稱統一資源定位符,比如一個網頁檔案、圖片、視頻等等都有唯一的URL,在爬蟲中我們可以理解為網址或者鏈接,
3.請求頭
什么是請求頭?英文名Request Headers,通常是指請求時包含的頭部資訊,比如User-Agent、Host、Cookies等等,
這些東西它相當于你向網站發送請求時你的身份資訊,這里面經常需要偽裝一下自己,偽裝成普通用戶,避免你的目標網站識別出來你是爬蟲程式,規避一些反扒問題,順利拿到資料,
4.請求體
官方一點的說辭就是請求時額外攜帶的資料,如表單提交時的表單資料,
怎么理解?就比如說你去你岳父家提親,你不能空著手過去提親對吧?你得帶點東西才像個提親的樣子,你岳父才會把女兒許配給你,這是大家通用的禮數,少不了的,

在爬蟲當中怎么理解?比如說在某些頁面你得先登錄了或者你得告訴我你請求什么,比如說你在百度這個網頁中搜索“Python”,那么這個“Python”這個關鍵字就是你要攜帶的請求體,看到了你的請求體,百度才知道你要干什么,
當然了,請求體通常是用在POST這種請求方式里面,在GET請求時我們通常是拼接在URL里面,這里先理解一下就可以了,后續具體爬蟲可以去加深理解,
5.實操查看Request
既然Request的理論我們已經講過了,那么我們就可以去實操看一下Request具體在哪個位置以及包含哪些東西,
以谷歌瀏覽器Chrome為例,我輸入關鍵字“Python”可以搜索出一堆結果,我們來用網頁自帶的控制臺視窗來分析一下我們發出的Request請求,
按住F12或者在網頁空白處右鍵選擇“檢查”,然后可以看到控制臺里面有很多選擇,比如說上面那一欄有一個選單欄,初級爬蟲一般我們就比較常用到的是Elements(元素)和Network(網路),其他的東西暫時用不到,等你學到了高級一點的爬蟲就會用到了,比如JS逆向的時候可能會用到Application這個視窗,后面用到了再了解,
Elements包含了所有的請求結果的每一個元素,比如每一個圖片的源代碼都是有的,尤其是當你點了左上角的小箭頭之后,你移動到的每一個地方在Elements視窗下都會顯示對于的源代碼,
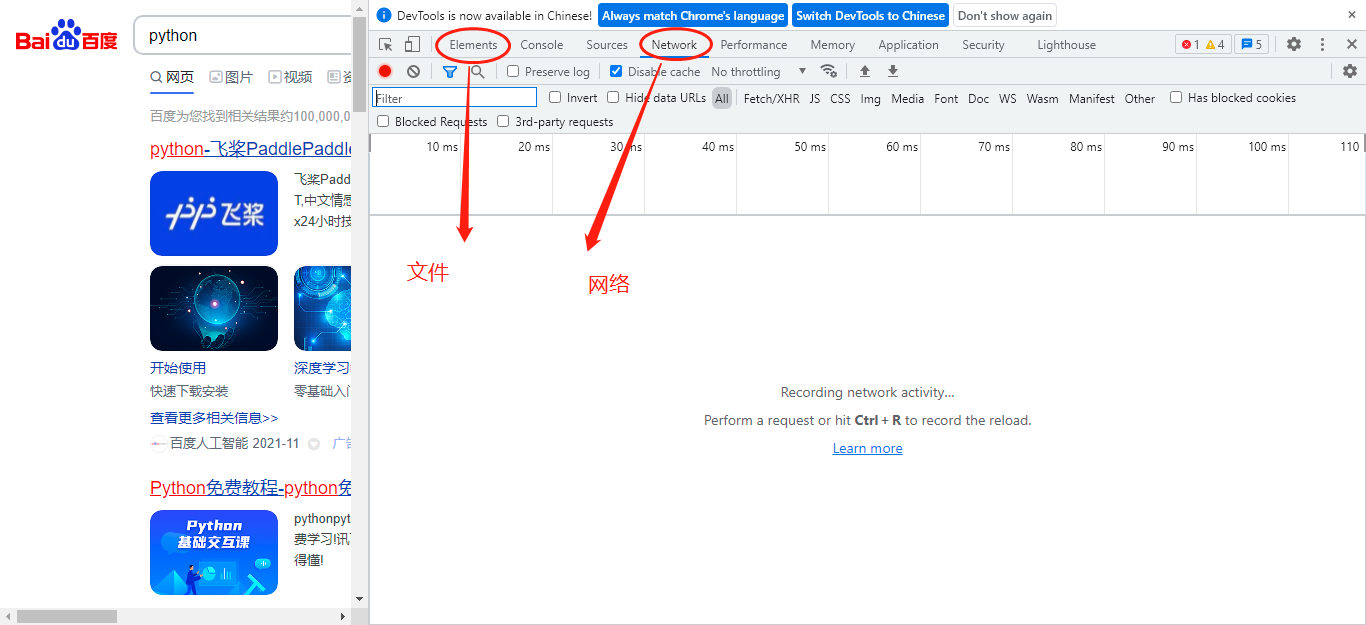
Network就是爬蟲常用到的網路資訊,其中就有我們的Request,我們來看一下,在Network視窗下,勾選Disable cache(禁用快取),并把All點上,
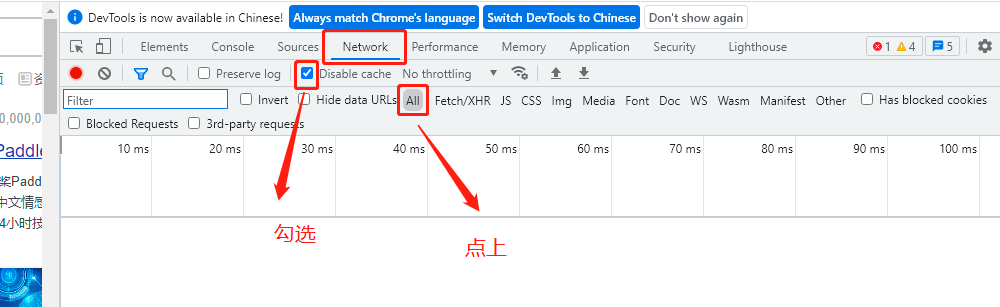
重繪一下網頁看看效果,可以看出我們發出了132個Request請求,這個不用好奇,雖然我們只是向百度發出了“Python”這么一個請求,但有些是網頁附帶的請求,
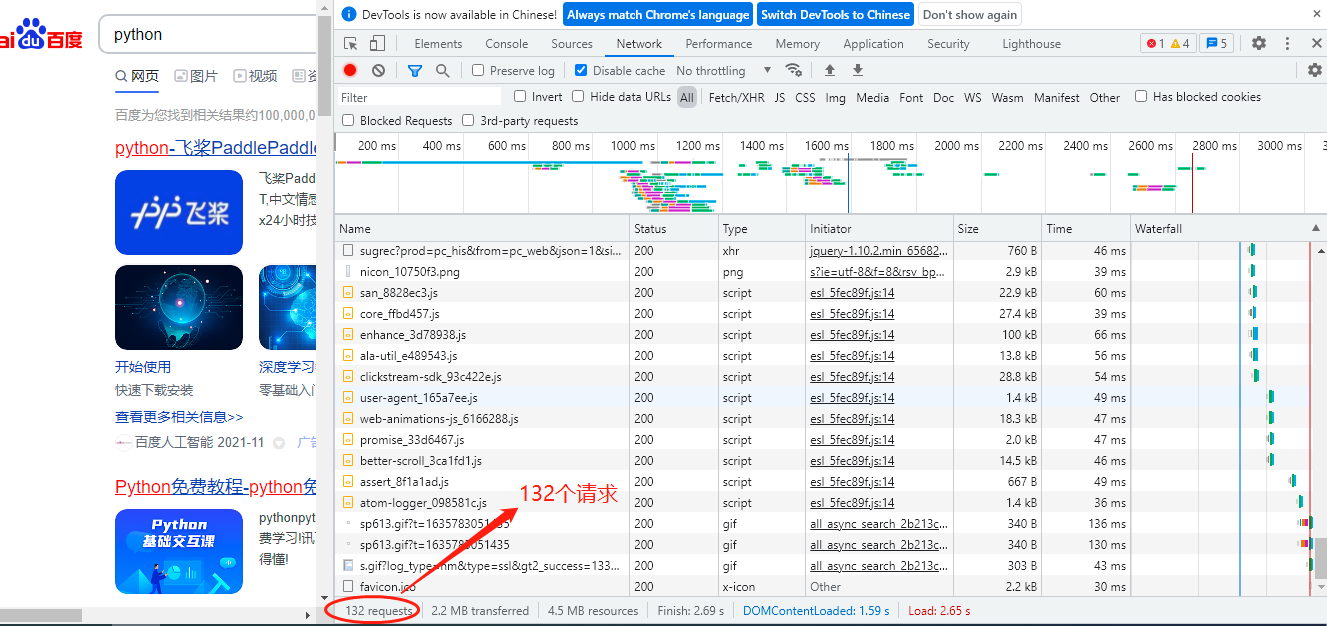
雖然里面有很多型別,什么圖片格式的png啊jpeg等等,但是你可以滑動到最上面,在Type(型別)那一列中有document這種型別,就是網頁檔案的意思,點擊進去就有我們的Request資訊,
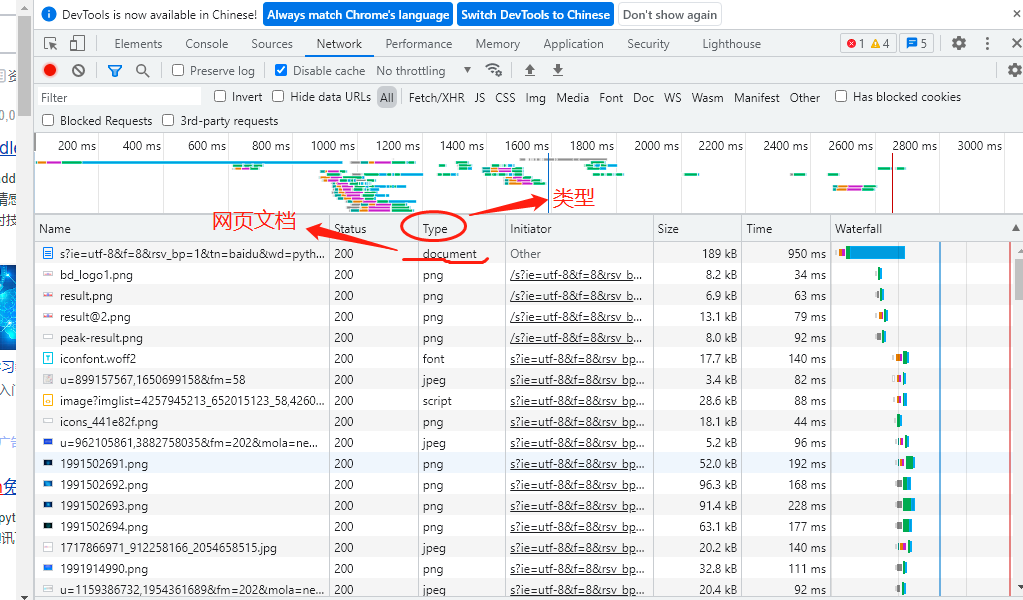
點擊document進去之后,又有一欄新的選單欄,在Headers那一欄下面,我們可以看到 Request URL,也就是我們前面說的請求URL,這個URL才是我們真正向網頁請求的URL,然后還有請求方式,可以看出來是GET請求這種方式,
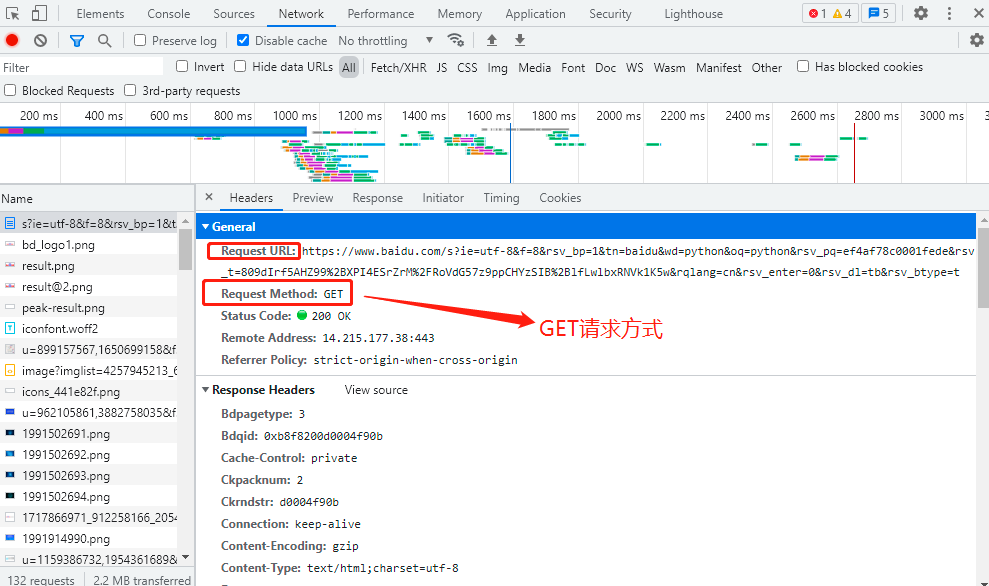
往下再滑動一下,還可以看到我們前面講的請求頭 Request Headers ,資訊很多,但我們前面講的User-Agent、Host、Cookies都是有的,這些都是我們給服務器的資訊,
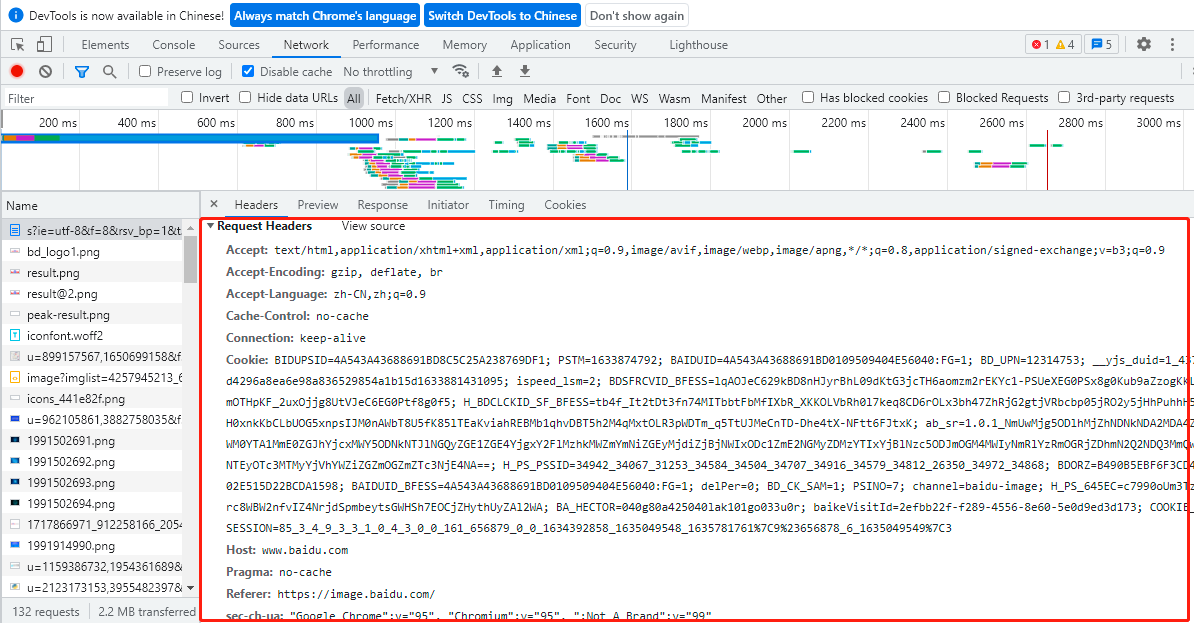
Request Headers里面內容雖然多,我們在寫爬蟲程式的時候也是要在這方面做偽裝作業,但并不是所有的資訊我們都要寫,選擇性地寫一些重要的資訊就可以了,比如User-Agent必帶,Referer和Host是選擇性地帶,cookie在要登錄的情況下會帶,常用的也就4項要做偽裝,
至于請求體這里我就暫時不做查看了,因為我們這里的請求方式是GET請求,在POST請求中才能查看到請求體,沒關系,爬蟲用到了你自然就會明白的,
四、了解Response
Response主要包括3塊內容,我們來一一了解一下,
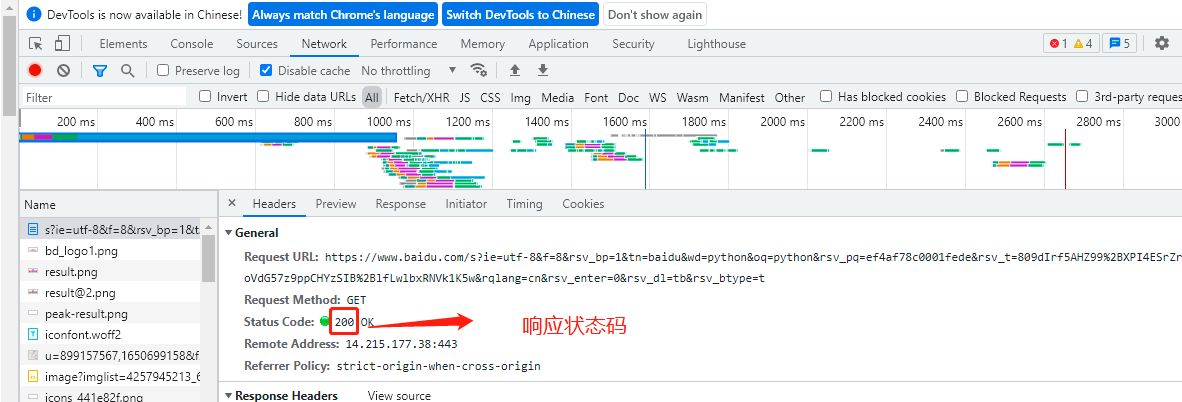
1.回應狀態
我們發送請求之后,網站會回傳給我們一個Response,這其中就包括了回應狀態碼對于的回應狀態,大致可以分為以下幾種:
①兩百范圍,比如回應狀態碼200則表示成功,
②三百范圍,比如301表示跳轉,
③四百范圍,比如404找不到網頁,
④五百范圍,比如502找不到網頁,
對于爬蟲來說,兩三百則是我們最希望看到的回應狀態,有可能會拿到資料,四五百基本上就涼了,拿不到資料的,
比如我們剛在在前面的Request請求發送時,在document檔案中,在Headers視窗下的General里面可以看出回應狀態碼是200,說明網頁成功回應了我們的請求,
2.回應頭
服務器給我們的資訊里面也會有回應頭這一部分,這里面包含了內容型別、內容長度、服務器資訊和設定Cookie等等,
其實回應頭對我們來說并不是那么重要,這里了解一下就可以了,
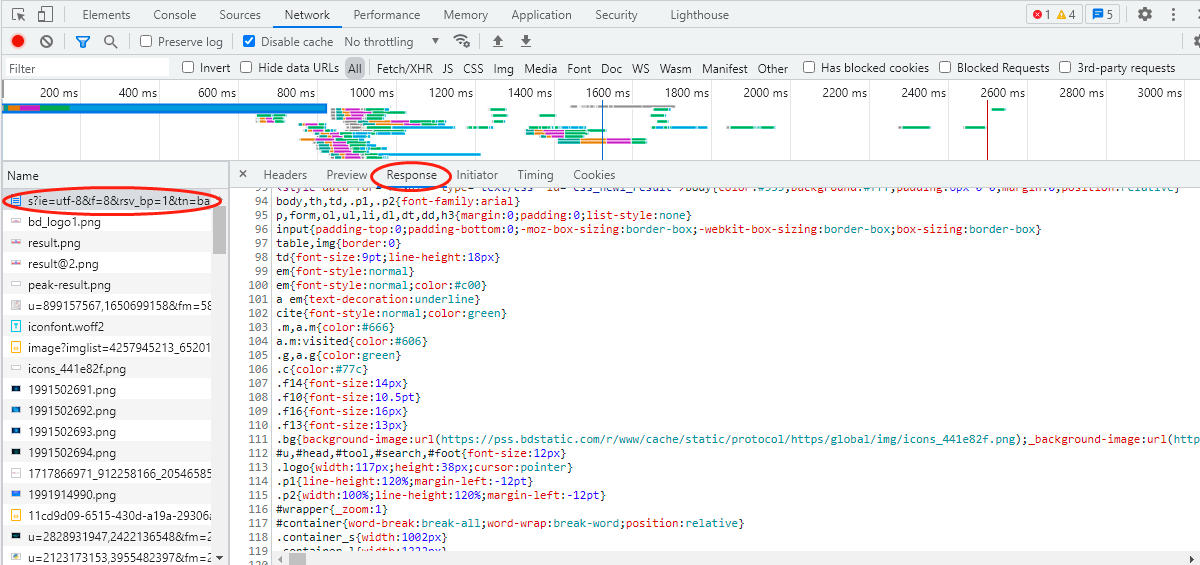
3.回應體
這個就很重要了,除了前面第一點的回應狀態,就是它了,因為它包含了請求資源的內容,比如網頁HTML和圖片二進制數等等,
回應體在哪里呢?也是在document檔案里面的Response那一欄,可以往下滑動就可以看出里面有很多回應的資料,這就是我們獲取到的資料,有的是可以直接下載的,有的則是需要用技術去決議才能拿到,
五、爬蟲能獲取到什么樣的資料?
爬蟲能獲取到什么樣的資料?基本上可以分為這么幾類:
①網頁檔案,如果HTML檔案、Json格式文本等,
②圖片,獲取的是二進制檔案,保存為圖片格式即可,
③視頻,也是二進制檔案,保存為視頻格式即可,
④其他的,反正其他能夠看得見的東西,理論上都是可以用爬蟲獲取的,具體的話得看難度的大小,
六、如何決議資料?
從前面我們可以發送請求成功之后,網頁會給我們回傳很多的資料,有幾千甚至幾萬條代碼,那么如何在這么多的代碼中找到我們想要的資料?常用的方法有以下幾個:
①直接處理,當網頁回傳資料就是一些文本,就是我們想要的內容,不需要過濾處理,直接處理就可以,
②Json決議,如果網頁回傳的不是HTML資料是Json資料,那么就需要用到Json決議技術,
③正則運算式,如果回傳的資料是符合正則運算式的資料,就可以用正則去做決議,
④其他決議方式,常用的有XPath、BeautifulSoup和PyQuery,這些都是爬蟲常用的決議庫,
七、怎么保存資料?
拿到資料后,常用的保存資料方法有以下幾種:
①文本,可以直接保存為純文本、EXCEL、Json、Xml等等型別的文本,
②關系型資料庫,資料可以保存到關系型資料庫,比如MySQL和Oracle等等資料庫,
③非關系型資料庫,如MongoDB、Readis和Key-Value形式儲存,
④二進制檔案,如圖片、視頻、音頻等等直接保存為特定格式即可,
關于爬蟲,今天就先講到這里,歡迎在下方評論區留言交流,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345676.html
標籤:其他