1、詞頻相關實戰問題
最近詞頻統計問題被問到的非常多,詞頻統計問題清單如下:
Q1:Elasticsearch可以根據檢索詞在doc中的詞頻進行檢索排序嘛?
Q2:求教 ES 可以查詢某個索引中某個text型別欄位的詞頻數量最大值和詞所在檔案數最大值么?例:索引中有兩個檔案 doc1:{"text":""} 分詞結果有兩個北京,一個南京 doc2:{"text":""} 分詞結果有一個北京想要一下結果:北京:詞頻3,檔案量2 南京:詞頻1,檔案量1
Q3:對某些文章的詞頻統計除了用fielddata之外還有沒有效率比較高的解決辦法呢?目前統計有時候會遇到十萬級的文章數直接在通過聚合效率上不是特別理想,
如上三個問題都可以歸結為:Elasticsearch 檔案詞頻統計問題,該問題在檢索、統計領域應用的非常多,
那么 Elasticsearch 如何實作詞頻統計呢?有必要梳理一下,
2、詞頻統計探討
之前的文章《Elasticsearch詞頻統計實作與原理解讀》,解決的是:Q3 提及的某索引中特定關鍵詞統計的問題,
解決方案是:text 欄位開啟 fielddata,咱們在《長津湖影評可視化
那么,對于給定檔案的詞頻統計呢?
原來開啟 fielddata 的方案就可以實作,舉例如下:
DELETE message_index
PUT message_index
{
"mappings": {
"properties": {
"message": {
"analyzer": "ik_smart",
"type": "text",
"fielddata": "true"
}
}
}
}
POST message_index/_bulk
{"index":{"_id":1}}
{"message":"沉溺于「輕易獲得高成就感」的事情:沉溺于有意無意地尋求用很小付出獲得很大「huibao」的偏方,哪怕huibao是虛擬的"}
{"index":{"_id":2}}
{"message":"過度追求“短期huibao”可以先思考這樣一個問題:為什么玩王者榮耀沉溺我們總是停不下來huibao"}
{"index":{"_id":3}}
{"message":"過度追求的努力無法帶來超額的huibao,就因此放棄了努力,這點在聰明人身上尤其明顯,以前念本科的時候身在沉溺"}
POST message_index/_search
{
"size": 0,
"query": {
"term": {
"_id": 1
}
},
"aggs": {
"messages": {
"terms": {
"size": 10,
"field": "message"
}
}
}
}無非在聚合的時候,加上query 陳述句指定了特定 id 進行檢索,
這種方法的缺點在于:正如 Q3 所說,聚合效率低,
看過上次直播的同學,可能會閃現一種想法,寫入前打 tag 的方式能解決嗎?
可以解決,但有個前提,先畫個圖解釋一下:
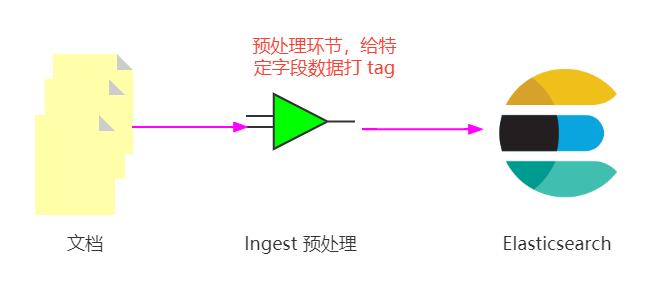
這個打 tag 的欄位非全量,而是特定的指定腳本處理的部分,下一小節詳細實作一把,
其實,除了開啟 fielddata 和 打 tag 之外,在 Elasticsearch 中有 termvectors 介面也能實作檔案詞頻統計,下一小節一并實作,
3、詞頻統計實作
3.1 text 開啟 fielddata 后聚合方案
第 2 部分已有實作說明,不再贅述,
3.2 寫入前打 tag,寫入后聚合統計方案
還是用第 2 部分的資料,說明如下:
PUT _ingest/pipeline/add_tags_pipeline
{
"processors": [
{
"append": {
"field": "tags",
"value": []
}
},
{
"script": {
"description": "add tags",
"lang": "painless",
"source": """
if(ctx.message.contains('成就')){
ctx.tags.add('成就')
}
if(ctx.message.contains('王者榮耀')){
ctx.tags.add('王者榮耀')
}
if(ctx.message.contains('沉溺')){
ctx.tags.add('沉溺')
}
"""
}
}
]
}
POST message_index/_update_by_query?pipeline=add_tags_pipeline
{
"query": {
"match_all": {}
}
}
POST message_index/_search
{
"size":0,
"aggs": {
"terms_aggs": {
"terms": {
"field": "tags.keyword"
}
}
}
}實作后,結果如下:
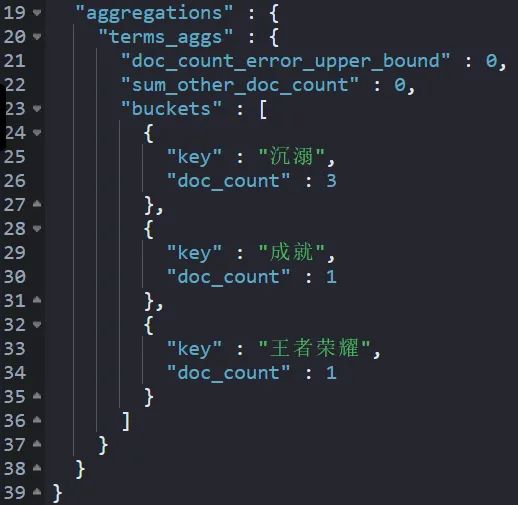
這種統計的依然是:關鍵詞(key)和檔案(doc_count)的統計關系,
什么意思呢?
"key":“沉溺”,“doc_count”:3 本質含義是:“沉溺”在三個不同的檔案中出現了,
細心的讀者會發現,檔案 1 中“沉溺”出現了2次,這種打 tag 統計是不準確的,
3.3 term vectors 統計
PUT message_index
{
"mappings": {
"properties": {
"message": {
"type": "text",
"term_vector": "with_positions_offsets_payloads",
"store": true,
"analyzer": "ik_max_word"
}
}
}
}解釋一下:
term_vector: 檢索特定檔案欄位中分詞單元的資訊和統計資訊,
store: 默認未開啟存盤,需要手動設定為true,
with_positions_offsets_payloads 是Lucene 的引數之一,釋義如下:
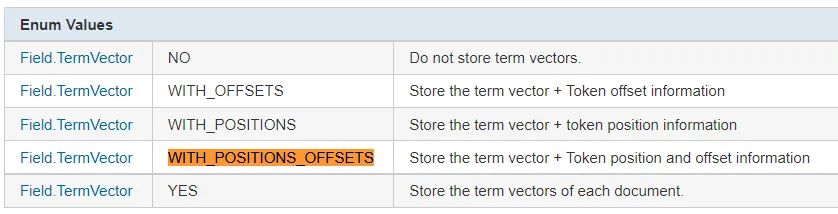
可以理解為:存盤分詞單元(term vector)、位置(Token position)、偏移值(offset)、有效負載(payload,猜測是ES 新增的),
默認會統計詞頻資訊,默認term information 為true,此外,還有 term statistics 和 field statistics 型別供設定和實作不同的統計,詳細內容參考官方檔案即可,
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-termvectors.html
執行:
GET message_index/_termvectors/1?fields=message后的回傳結果如下:
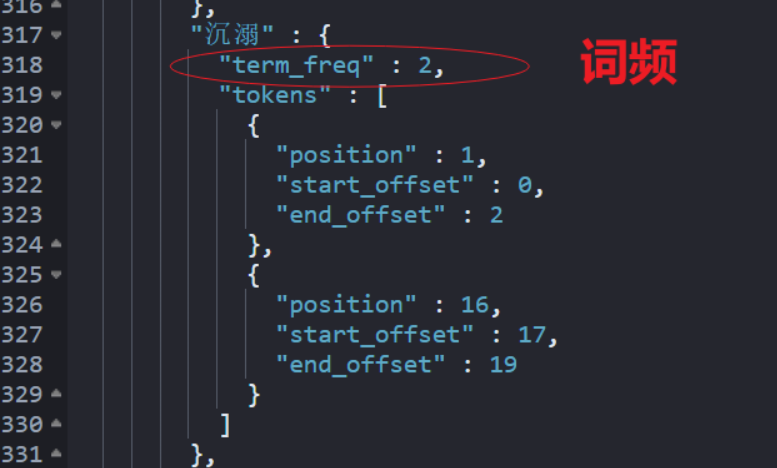
這種基于特定檔案的詞頻統計是傳統意義上我們理解的詞頻統計,
默認情況下,term vectors是實時的,而不是接近實時的,可以通過將 realtime 引數設定為 false 來更改,實時就意味著可能會有性能問題,
3.4 先分詞,后 term vectors 統計
在我擔心僅 termvectors 可能帶來的性能問題的時候,我想到了如下的解決方案,
前提:寫入之前除了存盤 message 欄位,加了一個分詞結果組合欄位,該欄位每個詞用空格做分隔,
message 欄位的前置分詞需要自己呼叫 analyzer API 實作,
有了切詞后的欄位,再做統計會更快,
具體實作如下:
DELETE message_ext_index
PUT message_ext_index
{
"mappings": {
"properties": {
"message_ext": {
"type": "text",
"term_vector": "with_positions_offsets_payloads",
"store": true,
"analyzer": "whitespace"
}
}
}
}
POST message_ext_index/_bulk
{"index":{"_id":1}}
{"message_ext":"沉溺 于 輕易 獲得 高 成就感 的 事情 沉溺 有意 無意 地 尋求 用 很小 付出 獲得 很大 huibao 的 偏方 哪怕 huibao 是 虛擬 的"}
GET message_ext_index/_termvectors/1?fields=message_ext強調一下:message_ext 使用的 whitespace 分詞器,
4、小結
關于詞頻統計,本文給出四種方案,只有第3、4種方案結合termvectors 實作是嚴格意義上的詞頻統計,其他兩種是詞頻-檔案關系的統計,
考慮到方式3的實時分詞可能的性能問題,擴展想到方案4前置分詞的方式,能有效提高統計效率,本質也是空間換時間,
你的實戰中如何實作的詞頻統計呢?歡迎留言說一下你的實作方式和思考,
參考
https://titanwolf.org/Network/Articles/Article?AID=7c417f9f-5bde-4519-9bd5-39957d184a07 https://discuss.elastic.co/t/word-count-frequency-per-field/159910 https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-termvectors.html
推薦
1、重磅 | 死磕 Elasticsearch 方法論認知清單(2021年國慶更新版)
2、Elasticsearch 7.X 進階實戰私訓課(口碑不錯)
更短時間更快習得更多干貨!
已帶領70位球友通過 Elastic 官方認證!
中國僅通過百余人

比同事搶先一步學習進階干貨!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345689.html
標籤:其他
上一篇:基于Linux安裝kafka
下一篇:資料庫從入門到精通03