L2正則化
定義:旨在減小泛化誤差而不是訓練誤差,通俗理解為凡是能夠減小過擬合的方式都可以成為正則化,
權重衰減
原損失函式:J(w,b)
原權重更新:w = w - ??J(w)
使用正則化(L2正則化):J1(w) = J(w) + (λ/2)||w||
使用正則化后的權重更新:w = w - ?[?J(w) + λw] = (1 - ?λ)w -??J(w)
即每一次更新權重都會將w的學習范圍進行縮小
理解:例如一個一元高次函式中,通過對高次項權重的衰減,來使影像中的曲折更少,從而減小函式對資料的擬合程度(如果函式曲折更多,則幾乎可以將訓練集所有的正負樣本區分開),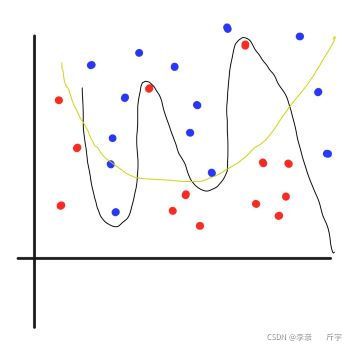
(黃色曲線代表衰減高次項的權重,由于衰減高次項的權重,函式曲線不會完全擬合訓練集,從而提高泛化能力;黑色代表未衰減高次項的權重,如過未使用權重衰減,函式會將訓練集的資料近乎完全分開)
看到一個很形象的例子,把訓練程序比作吃雞游戲,目的就是活到最后或者將所有敵人擊殺,未使用權重衰減之前,比作沒有毒圈的吃雞游戲,大家可以在整張地圖活動,而毒圈縮小就是權重衰減,大家每一次的活動空間都會縮小(權重W的可學習的范圍縮小),
Hession矩陣
想要理解L2矩陣,首先需要了解Hession矩陣:首先需要了解Hession矩陣:對于多維函式f(X),對其進行二階求導,得到的結果合并成一個矩陣即Hession矩陣,Hession矩陣作為二階導數可以反映梯度下降是否符合預期,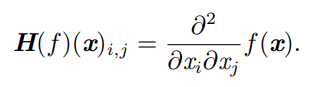
Hession矩陣是一個實對稱矩陣,可以被分解為一組特征值和特征向量的正交基,即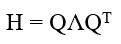
L2正則化
向目標函式增加一個w的L2范數作為懲罰項λ||W||2(并沒有使用λ||W - C||2, 沒有指定圓的半徑),即給W限定了一個范圍,更新后的W的值只能落在給定的范圍中,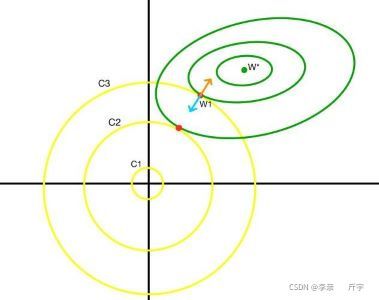 由于沒有指定C,所以黃色區域的半徑是沒有通過C來確定的,W1為約束條件下的最值點,橙色代表約束條件的梯度,藍色為損失函式的梯度,而λ代表的就是損失函式梯度的大小比上約束條件梯度的大小,對于不同的半徑,兩個梯度的比值λ的大小是不同的,從而通過人為確定λ來確定限定范圍的大小,
由于沒有指定C,所以黃色區域的半徑是沒有通過C來確定的,W1為約束條件下的最值點,橙色代表約束條件的梯度,藍色為損失函式的梯度,而λ代表的就是損失函式梯度的大小比上約束條件梯度的大小,對于不同的半徑,兩個梯度的比值λ的大小是不同的,從而通過人為確定λ來確定限定范圍的大小,
L2正則化能夠實作權重衰減的推導程序如下:
-
首先將使用L2正則化后的的損失函式在未使用正則化時的最優解W* 處進行二階泰勒展開,:
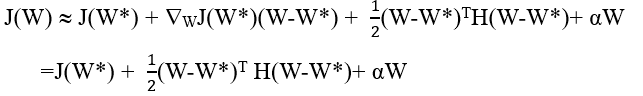 由于W*為最優解,所以其一階導為0
由于W*為最優解,所以其一階導為0 -
然后求一階導并讓其等于0:
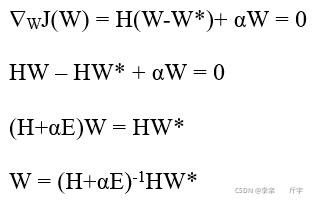
-
由上面提到的Hession矩陣的性質以及正交矩陣的性質得到:
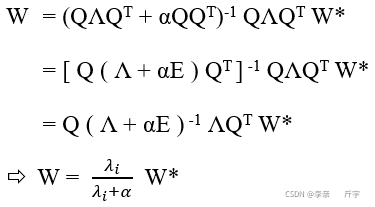
從推到結果可以看出通過調節損失函式梯度大小與約束函式梯度大小的比值α來進行權重衰減,如上方的圖中所示,如果α的大小趨向零則代表限定區域的半徑為無窮大,正則化后的解就會趨向W*,如果α在的值合適,W就會更新到一個比較好的值,既不會學習到一個導致過擬合的W*,也不會導致欠擬合,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/345917.html
標籤:其他
上一篇:谷歌查詢或公式來查找缺失的月費