上篇blog安裝了可視化的監控工具后,就到了我們最常用的環節,也就是通過代碼來控制Kafka,使用API來呼叫,Kafka檔案地址為Kafka官方檔案,接下來我們會充分使用到官方檔案中的示例,本篇blog分為如下幾個部分:
- 環境準備:創建一個java project,用來進行kafka代碼的撰寫
- 生產者API:探討生產者的發送方式,使用不同的生產者介面發送【同步發送、異步發送】
- 消費者API:探討生產者的發送方式,使用不同的生產者介面發送【offset提交】
接下來按照如下流程來一起學習吧,奧利給!
環境準備
首先新建一個java project,打開idea新建一個maven專案:
然后引入kafka的的maven依賴:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>kafka</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>7</source>
<target>7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.5</version>
</dependency>
</dependencies>
</project>
生產者API
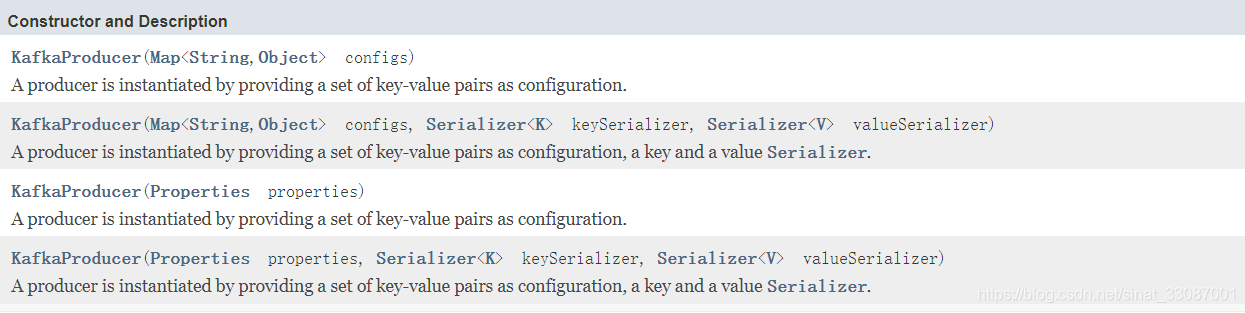
在官方檔案中,我們可以看到Kafka的消費者API串列生產者API,這些都是當前Kafka支持的生產者相關的API,有如下四種構造方法:
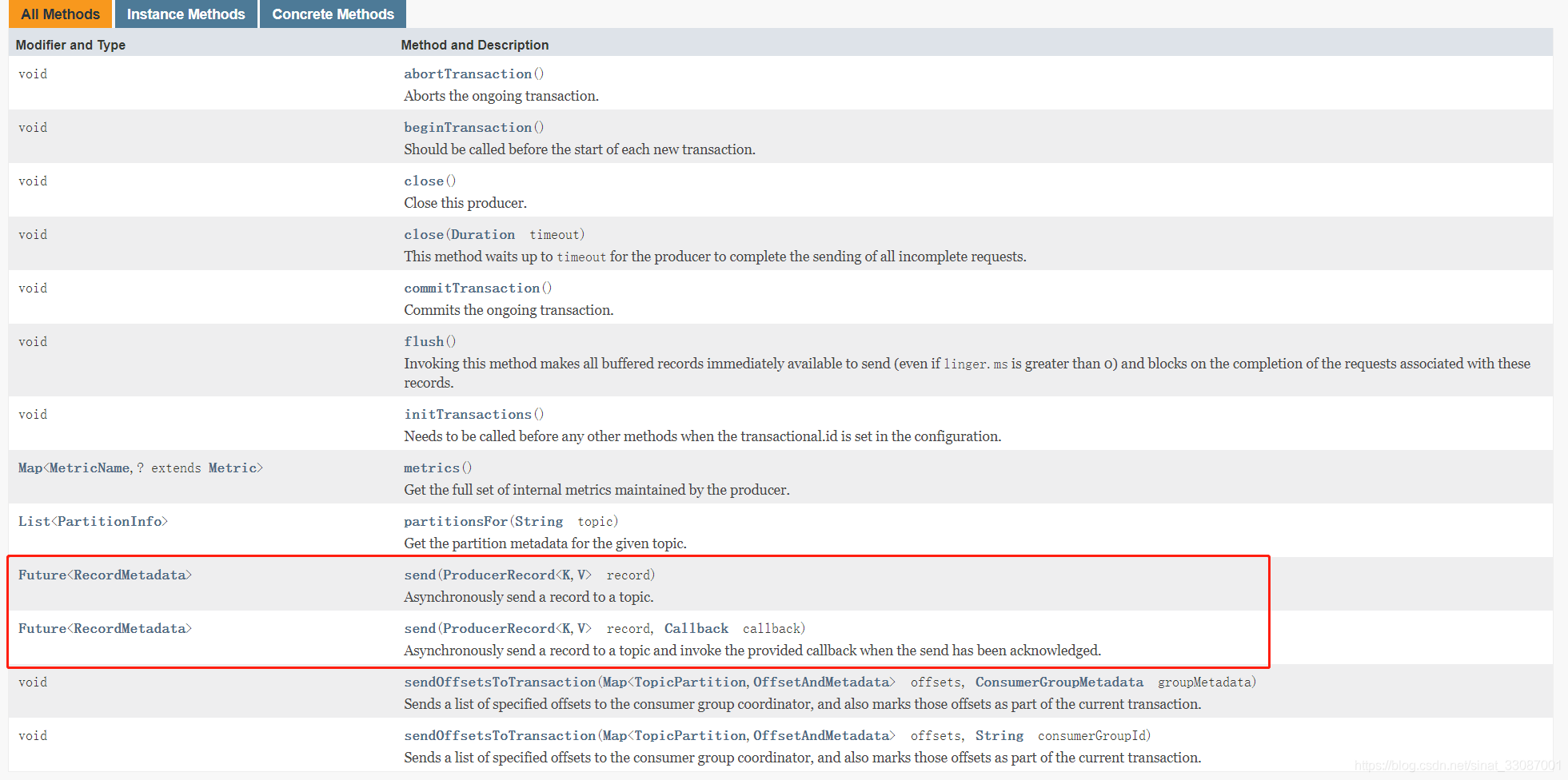
也有如下13種方法【非抽象的實體方法】:接下來分成幾個模式分別介紹下
發送方式
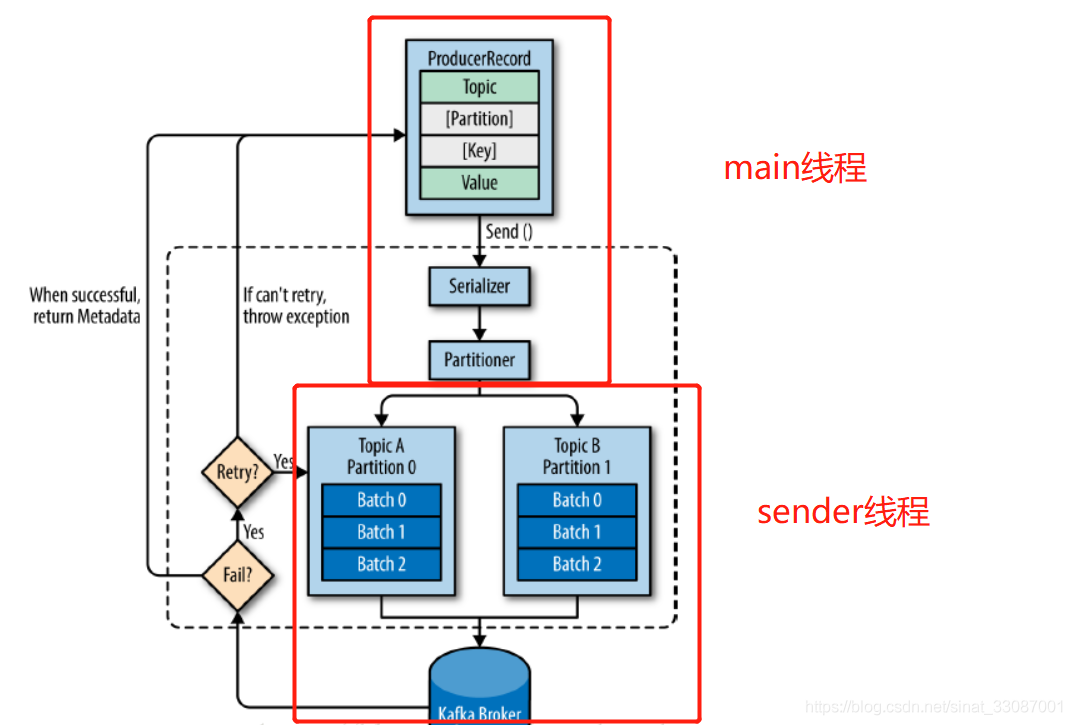
發送方式分為兩種,同步發送和異步發送,主體的發送流程二者是相同的,主體流程如下:
- 首先創建ProducerRecord物件,此物件除了包括需要發送的資料value之外還必須指定topic,另外也可以指定key和磁區,當發送ProducerRecord的時候,生產者做的第一件事就是把key和value序列化為ByteArrays,以便它們可以通過網路發送,
- 接下來,資料會被發送到磁區器,如果在ProducerRecord中指定了一個磁區,那么磁區器會直接回傳指定的磁區;否則,磁區器通常會基于ProducerRecord的key值計算出一個磁區,一旦磁區被確定,生產者就知道資料會被發送到哪個topic和磁區,然后資料會被添加到同一批發送到相同topic和磁區的資料里面,一個單獨的執行緒會負責把那些批資料發送到對應的brokers,
- 當broker接收到資料的時候,如果資料已被成功寫入到Kafka,會回傳一個包含topic、磁區和偏移量offset的RecordMetadata物件;如果broker寫入資料失敗,會回傳一個例外資訊給生產者,當生產者接收到例外資訊時會嘗試重新發送資料,如果嘗試失敗則拋出例外,
Kafka 的 Producer 發送訊息采用的是異步發送的方式,在訊息發送的程序中,涉及到了兩個執行緒 ——main 執行緒和 Sender 執行緒,以及 一個執行緒共享變數 ——RecordAccumulator,main 執行緒將訊息發送給RecordAccumulator,Sender 執行緒不斷從 RecordAccumulator 中拉取訊息發送到 Kafka broker
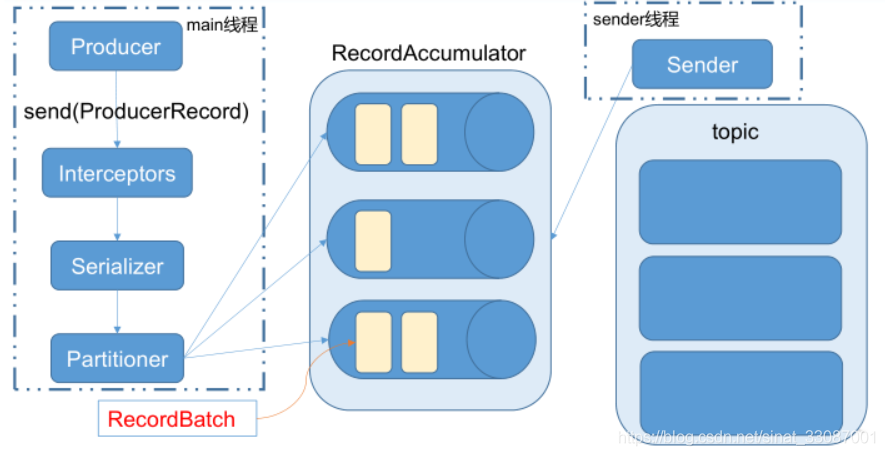
只有資料積累到 batch.size 之后,sender 才會發送資料,如果資料遲遲未達到 batch.size,sender 等待 linger.time 之后就會發送資料,也就是發往broker的資料是一批一批過去的,
異步發送
異步發送的含義是:訊息的發送者只是將訊息發送過去,并不關心訊息的發送狀態,如果leader在發送ack后宕機的話,重復發送的訊息將不能保證原來的順序,最好選用帶回呼函式的方法,
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
public class Producer {
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
//設定kafka集群的地址
props.put("bootstrap.servers", "192.168.5.101:9092,192.168.5.102:9092,192.168.5.103:9092");
//ack模式,all是最慢但最安全的
props.put("acks", "-1");
//失敗重試次數
props.put("retries", 1);
//每個磁區未發送訊息總位元組大小(單位:位元組),超過設定的值就會提交資料到服務端
props.put("batch.size", 10);
//props.put("max.request.size",10);
//訊息在緩沖區保留的時間,超過設定的值就會被提交到服務端
props.put("linger.ms", 10000);
//整個Producer用到總記憶體的大小,如果緩沖區滿了會提交資料到服務端
//buffer.memory要大于batch.size,否則會報申請記憶體不足的錯誤
props.put("buffer.memory", 10240);
//序列化器
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
org.apache.kafka.clients.producer.Producer producer=new KafkaProducer(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("tml-second", Integer.toString(i), "tml-second訊息:"+i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println("訊息發送狀態監測");
}
});
producer.close();
}
}
我們可以從機器上看到訊息記錄
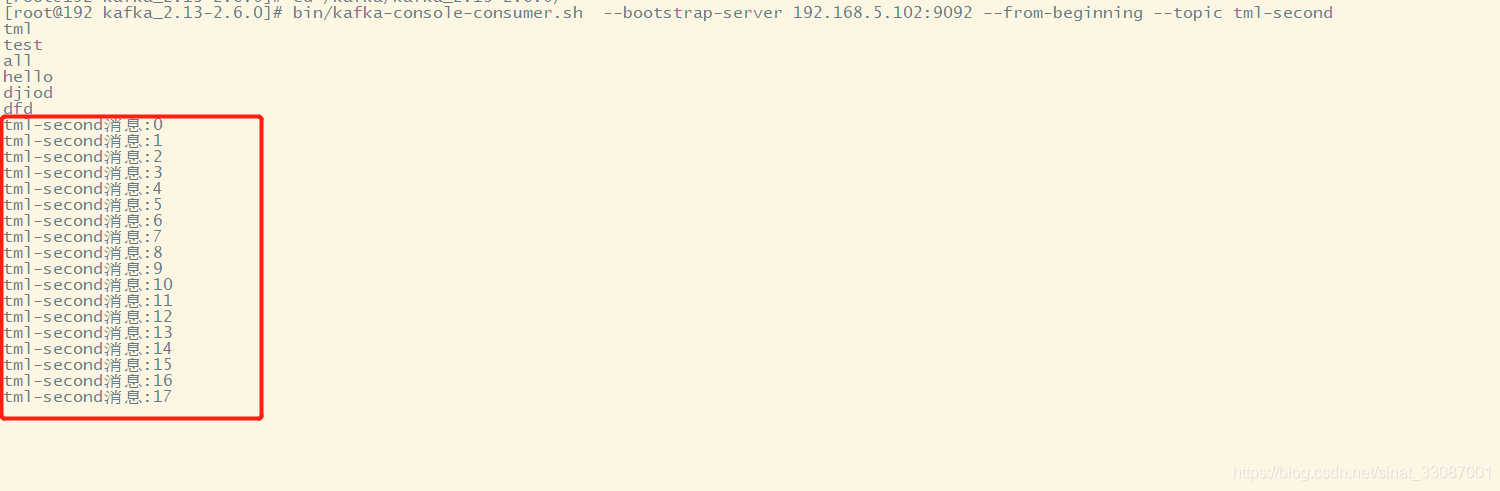
為了更準確一些,我們用命令消費一下:
同步發送
同步發送用的比較少,唯一的不同就是他要求發送時按照順序,如果當條資料發送失敗,那么就阻塞執行緒,這樣就保證了訊息的嚴格順序【即使在重試狀態下發送的訊息】
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class Producer {
public static void main(String[] args) throws InterruptedException, ExecutionException {
Properties props = new Properties();
//設定kafka集群的地址
props.put("bootstrap.servers", "192.168.5.101:9092,192.168.5.102:9092,192.168.5.103:9092");
//ack模式,all是最慢但最安全的
props.put("acks", "-1");
//失敗重試次數
props.put("retries", 1);
//每個磁區未發送訊息總位元組大小(單位:位元組),超過設定的值就會提交資料到服務端
props.put("batch.size", 10);
//props.put("max.request.size",10);
//訊息在緩沖區保留的時間,超過設定的值就會被提交到服務端
props.put("linger.ms", 10000);
//整個Producer用到總記憶體的大小,如果緩沖區滿了會提交資料到服務端
//buffer.memory要大于batch.size,否則會報申請記憶體不足的錯誤
props.put("buffer.memory", 10240);
//序列化器
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
org.apache.kafka.clients.producer.Producer producer=new KafkaProducer(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("tml-second", Integer.toString(i), "tml-second訊息:"+i)).get();
producer.close();
}
}
防止訊息重復提交
在生產者策略的時候我們提到過,需要防止訊息重復提交,也即精準一次提交,我們有兩種級別,一種是冪等模式【一個broker的會話周期精準一次】,另一種是事務模式【全域的精準一次】,
冪等模式
代碼寫法類似,只需要給配置里加一個配置項
//冪等模式
props.put("enable.idempotence", true);
一旦設定了該屬性,那么retries默認是Integer.MAX_VALUE ,acks默認是all【-1】,
事務模式
事務模式的寫法略有不同:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.KafkaException;
import org.apache.kafka.common.errors.AuthorizationException;
import org.apache.kafka.common.errors.OutOfOrderSequenceException;
import org.apache.kafka.common.errors.ProducerFencedException;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class Producer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.5.101:9092,192.168.5.102:9092,192.168.5.103:9092");
props.put("transactional.id", "my_transactional_id");
org.apache.kafka.clients.producer.Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
producer.initTransactions();
try {
//資料發送必須在beginTransaction()和commitTransaction()中間,否則會報狀態不對的例外
producer.beginTransaction();
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<>("tml-second", Integer.toString(i), Integer.toString(i)));
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// 這些例外不能被恢復,因此必須要關閉并退出Producer
producer.close();
} catch (KafkaException e) {
// 出現其它例外,終止事務
producer.abortTransaction();
}
producer.close();
}
}
消費者API
在官方檔案中,我們可以看到Kafka的消費者API串列消費者API,有構造方法,和實體方法,構造方法有如下四種:
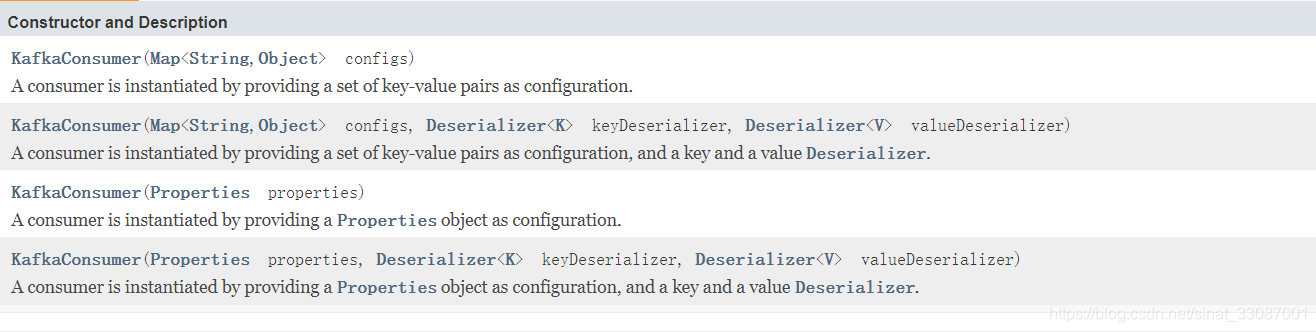
也有45種方法【非抽象的實體方法】以及4種棄用方法,消費者提交方式有以下幾種:
- 自動提交:kafka管理offset的提交
- 手動提交:手動同步提交和手動異步提交
按照這種結構我們看下提交方式,
自動提交offset
提交的代碼如下:
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class Consumer {
public static void main(String[] args) {
Properties props = new Properties();
//設定kafka集群的地址
props.put("bootstrap.servers", "192.168.5.101:9092,192.168.5.102:9092,192.168.5.103:9092");
//設定消費者組,組名字自定義,組名字相同的消費者在一個組
props.put("group.id", "tml-group");
//開啟offset自動提交
props.put("enable.auto.commit", "true");
//自動提交時間間隔
props.put("auto.commit.interval.ms", "1000");
//序列化器
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//實體化一個消費者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//消費者訂閱主題,可以訂閱多個主題
consumer.subscribe(Arrays.asList("tml-second"));
//死回圈不停的從broker中拿資料
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
可以看到提交的效果
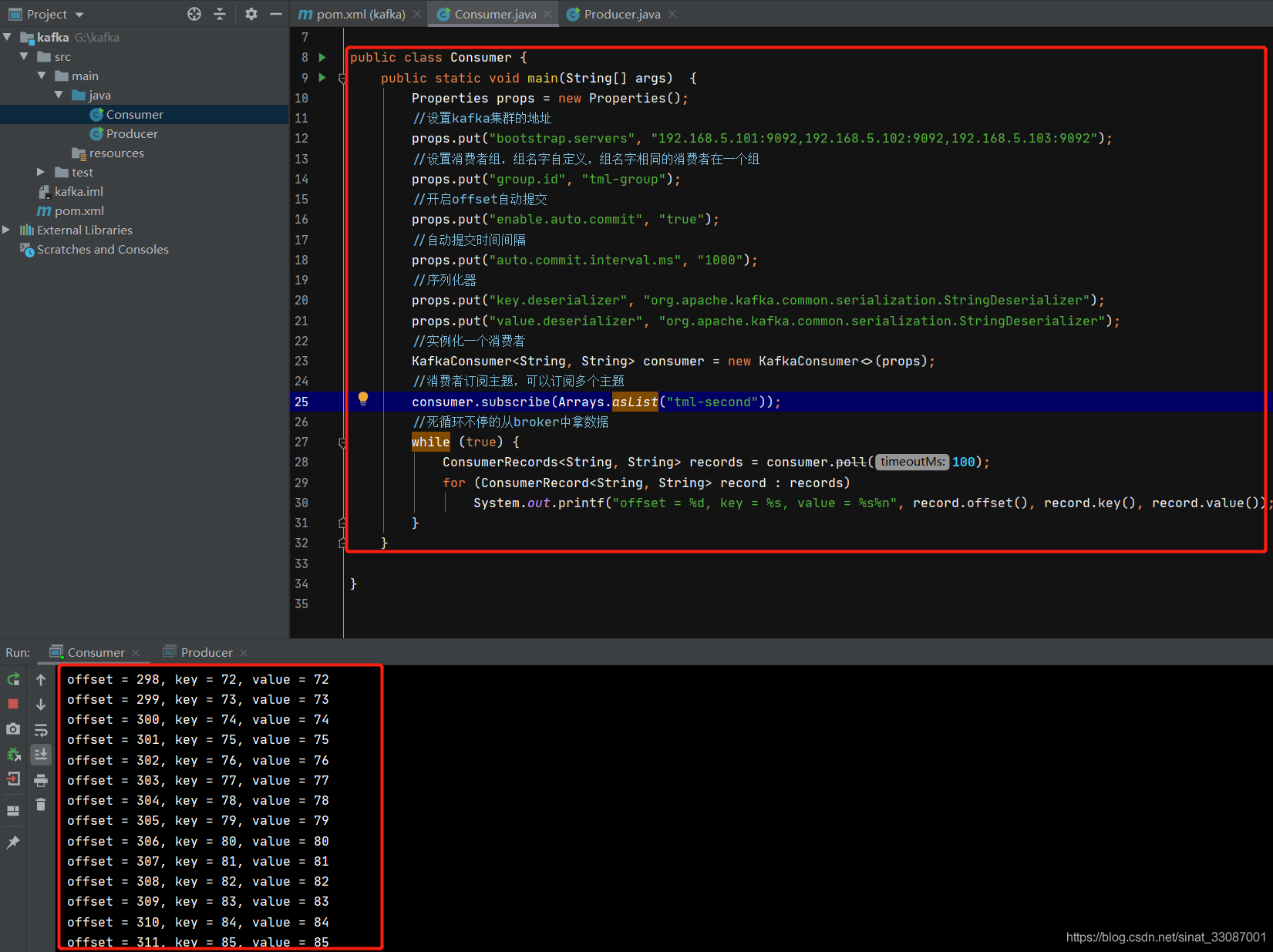
手動同步提交offset
通常從Kafka拿到的訊息是要做業務處理,而且業務處理完成才算真正消費成功,所以需要客戶端控制offset提交時間
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
public class Consumer {
public static void main(String[] args) {
Properties props = new Properties();
//設定kafka集群的地址
props.put("bootstrap.servers", "192.168.5.101:9092,192.168.5.102:9092,192.168.5.103:9092");
//設定消費者組,組名字自定義,組名字相同的消費者在一個組
props.put("group.id", "tml_group");
//開啟offset自動提交
props.put("enable.auto.commit", "false");
//序列化器
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//實體化一個消費者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//消費者訂閱主題,可以訂閱多個主題
consumer.subscribe(Arrays.asList("tml-second"));
final int minBatchSize = 50;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
//insertIntoDb(buffer);
for (ConsumerRecord bf : buffer) {
System.out.printf("offset = %d, key = %s, value = %s%n", bf.offset(), bf.key(), bf.value());
}
consumer.commitSync();
buffer.clear();
}
}
}
}
手動異步提交offset
雖然同步提交 offset 更可靠一些,但是由于其會阻塞當前執行緒,直到提交成功,因此吞吐量會收到很大的影響,因此更多的情況下,會選用異步提交 offset 的方式
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.util.*;
public class Consumer {
public static void main(String[] args) {
Properties props = new Properties();
//設定kafka集群的地址
props.put("bootstrap.servers", "192.168.5.101:9092,192.168.5.102:9092,192.168.5.103:9092");
//設定消費者組,組名字自定義,組名字相同的消費者在一個組
props.put("group.id", "tml_group");
//開啟offset自動提交
props.put("enable.auto.commit", "false");
//序列化器
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//實體化一個消費者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//消費者訂閱主題,可以訂閱多個主題
consumer.subscribe(Arrays.asList("tml-second"));
final int minBatchSize = 50;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
//insertIntoDb(buffer);
for (ConsumerRecord bf : buffer) {
System.out.printf("offset = %d, key = %s, value = %s%n", bf.offset(), bf.key(), bf.value());
}
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition,
OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
System.err.println("Commit failed for" +
offsets);
}
}
});
buffer.clear();
}
}
}
}
趟了無數的坑,終于把Kafka學習完了,接下來開始Redis之旅,開始由業務架構向基礎架構滲透,上可接客戶,中可玩兒平臺,下可探基礎,完成SaaS、PaaS以及IaaS的倍訓
部分內容來自 https://blog.csdn.net/wangzhanzheng/article/details/80801059
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/34680.html
標籤:其他