- 單服務器無論如何優化,無論采用多好的硬體,總會有一個性能天花板,當單服務器的性能無法滿足業務需求時,就需要設計高性能集群來提升系統整體的處理性能
- 高性能集群的本質很簡單,通過增加更多的服務器來提升系統整體的計算能力,計算本身存在一個特點:同樣的輸入資料和邏輯,無論在哪臺服務器上執行,都應該得到相同的輸出 ,因此高性能集群設計的復雜度主要體現在任務分配這部分,需要設計合理的任務分配策略,將 計算任務分配到多臺服務器上執行
- 高性能集群的復雜性主要體現在需要增加一個任務分配器,以及為任務選擇一個合適的任務分配演算法,對于任務分配器,現在更流行的通用叫法是“負載均衡器”,但這個名稱有一定的誤導性,會讓人潛意識里認為任務分配的目的是要保持各個計算單元的負載達到均衡狀態,而實際上任務分配并不只是考慮計算單元的負載均衡,不同的任務分配演算法目標是不一樣的,有的基于負載考慮、有的基于性能(吞吐量、回應時間〉考慮、有的基于業務考慮,負載均衡不只是為了計算單元的負載達到均衡狀態,
負載均衡分類
常見的負載均衡系統包括 3 種: DNS 負載均衡、硬體負載均衡和軟體負載均衡,
DNS負載均衡
DNS是最簡單也是最常見的負載均衡方式,一般用來實作地理級別的均衡,例如,北方的用戶訪問北京的機房,南方的用戶訪問深圳的機房,DNS 負載均衡的本質是DNS決議同一個域名可以回傳不同的IP地址,例如,同樣是 www.baidu.com,北方用戶決議后獲取的地址是 61.135 .165.224,南方用戶決議后獲取的地址是 14 .2 15.177.38
DNS 負載均衡
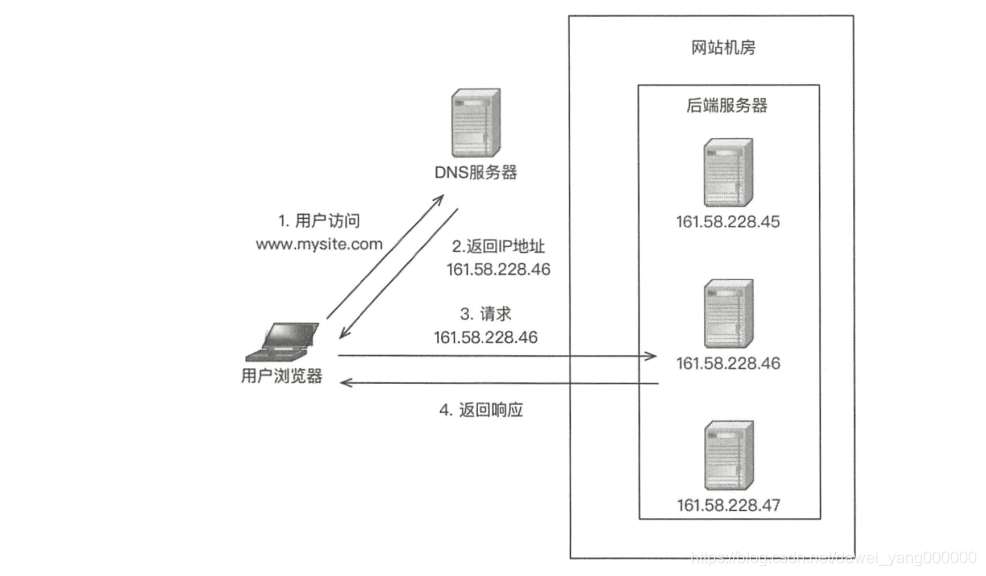
DNS負載均衡實作簡單、成本低,但也存在粒度太租、負載均衡演算法少等缺點
- 簡單 、成本低 : 負載均衡作業交給DNS服務器處理,無須自己開發或維護負載均衡設備
- 就近訪問,提升訪問速度:DNS決議時可以根據請求來源IP,決議成距離用戶最近的服務器地址,可以加快訪問速度,改善性能
- 更新不及時 : DNS 快取的時間比較長,修改 DNS 配置后,由于快取的原因,還是有很多用戶會繼續訪問修改前的 I P ,這樣的訪問會失敗,達不到負載均衡的目 的, 并且也影響用 戶正常使用業務
- 擴展性差 : DNS 負載均衡 的控制權在域名商那里 ,無法根據業務特點針對其做更多 的定制化功能和擴展特性
- 分配策略比較簡單 : DNS 負 載均衡支持的演算法少:不能區分服務器的差異(不能根 據系統與服務的狀態來判斷負載);也無法感知后端服務器的狀態
針對 DNS 負載均衡的 一 些缺點,對于時延和故障敏感的業務,有一些公司自 己實作了 HTTP-DNS 的功能,即使用 HTTP 協議實作一個私有的 DNS 系統,這樣的方案和通用的 DNS優缺點正好相反,
硬體負載均衡
硬體負載均衡是通過單獨的硬體設備來實作負載均衡功能,這類設備和路由器交換機類似,可以理解為一個用于負載均衡的基礎網路設備,目前業界典型的硬體負載均衡設備有兩款 : FS 和 A10 ,這類設備性能強勁,功能強大,但價格都不便宜 , 一般只有“土豪” 公司才會考慮使 用此類設備,普通業務量級的公司一是負擔不起,二是業務量沒那么大,用這些設備也是浪費,
硬體負載均衡的優缺點如下
- 功能強大 : 全面支持各層級的負載均衡,支持全面的負載均衡演算法,支持全域負載均衡
- 性能強大 : 對比一下,軟體負載均衡支持到 10萬級井發己經很厲害了,硬體負載均 衡可以支持 100 萬以上的并發
- 穩定性高 : 商用硬體負載均衡,經過了良好的嚴格測驗,經過大規模使用, 在穩定性方面高
- 支持安全防護 : 硬體均衡設備除具備負載均衡功能外,還具備防火墻、防 DDOS 攻 擊等安全功能
- 價格昂貴 : 幾十萬上百萬
- 擴展能力差:硬體設備,可以根據業務進行配置 , 但無法進行擴展和定制
軟體負載均衡
- 軟體負載均衡通過負載均衡軟體來實作負載均衡功能,常見的有Nginx和LVS, 其中Nginx 是軟體的 7 層負載均衡,LVS是 Linux內核的4層負載均衡,4層和7層的區別就在于協議和 靈活性, Nginx支持HTTP、E-mail 協議, 而LVS是4層負載均衡,和協議無關 ,幾乎所有應 用都可以做,例如,聊天、資料庫等
- 軟體和硬體的最主要區別就在于性能,硬體負載均衡性能遠遠高于軟體負載均衡性能, Ngxin的性能是萬級,一般的Linux服務器上裝一個Nginx大概能到5萬/每秒:LVS的性能是十萬級,據說可達到80萬/每秒 ;而自性能是百萬級,從200 萬/每秒到800 萬/每秒都有,當然,軟體負載均衡的最大優勢是便宜
- 除了使用開源的系統進行負載均衡 ,如果業務 比較特殊, 也可能基于開源系統進行定制(例如, Nginx 插件),甚至進行自研,
Nginx 的負載均衡架構
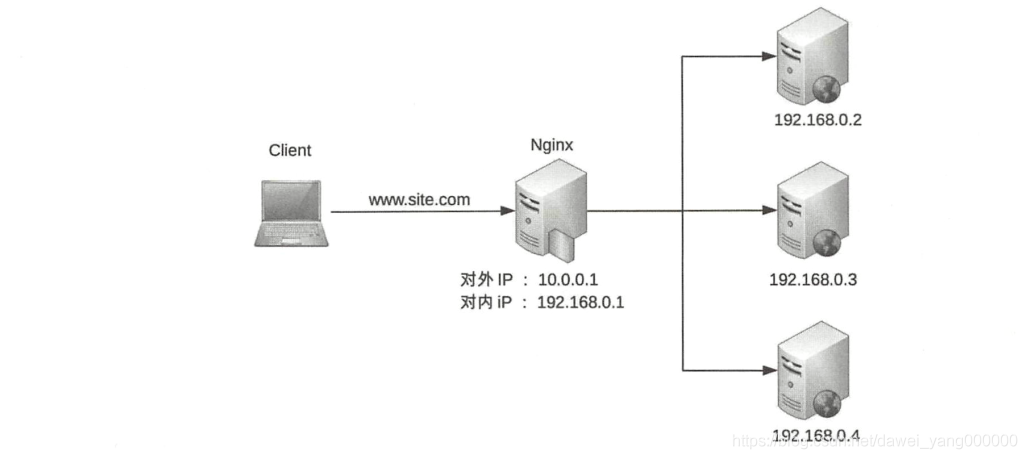
軟體負載均衡的優缺點如下:
- 簡單:無論部署,還是維護都比較簡單
- 便宜:只要買個 Linux 服務器,裝上軟體即可
- 靈活: 4層和7層負載均衡可以根據業務進行選擇;也可以根絕業務進行比較方便的擴展,例如,可以通過 Nginx 的插件來實作業務的定制化功能
- 性能一般 : 一個 Nginx 大約能支撐 5 萬并發
- 功能沒有硬體負載均衡那么強大
- 一般不具備防火墻和防 DDOS 攻擊等安全功能
負載均衡架構
DNS 負載均衡、硬體負載均衡、軟體負載均衡, 每種方式都有一些優缺點,但并不意味著在實際應用中只能基于它們的優缺點進行非此即彼的選擇,反而是基于它們的優缺點進行組合使用 , 具體來說,組合的基本原則為 : DNS 負載均衡 用于實作地理級別的負載均衡;硬體負載均衡用于實作集群級別的負載均衡;軟體負載均衡用于實作機器級別的負載均衡
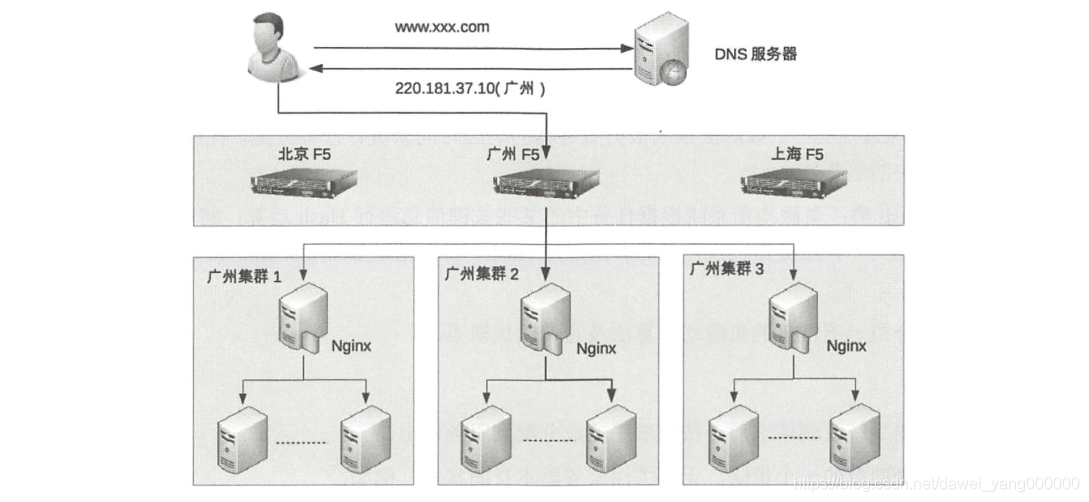
負載均衡演算法
負載均衡演算法數量較多,而且可以根據-些業務特性進行定制開發,拋開細節上的差異, 根據演算法期望達到的目的,大體上可以分為如下幾類:
- 任務平分類 : 負載均衡系統將收到的任務平均分配給服務器進行處理,這里的“平均” 可以是絕對數量的平均,也可以是比例或權重上的平均
- 負載均衡類 : 負載均衡系統根據服務器的負載來進行分配,這里的負載井不一定是通 常意義上我們說的接數、I/O使用率、網卡吞吐量等來衡量系統的壓力
- 性能最優類 : 負載均衡系統根據服務器的回應時間來進行任務分配,優先將新任務分配給回應最快的服務器
- Hash類:負載均衡系統根據任務中的某些關鍵資訊進行Hash運算,將相同Hash值的請求分配到同一臺服務器上 ,常見的有源地址Hash、目標地址hash 、session id hash 、用戶id hash等
輪詢
負載均衡系統收到請求后,按照順序輪流分配到服務器上,輪詢是最簡單的一個策略,無須關注服務器本身的狀態,例如:
- 某個服務器當前因為觸發了程式bug進入了死回圈導致CPU負載很高,負載均衡系統是不感知的,還是會繼續將請求源源不斷地發送給它
- 集群中有新的機器是32核的,老的機器是16核的,負載均衡系統也是不關注的,新老機器分配的任務數是一樣的
需要注意的是負載均衡系統無須關注“服務器本身狀態”,這里的關鍵詞是“本身”,也就是說,只要服務器在運行,運行狀態是不關注的,但如果服務器直接巖機了,或者服務器和負 載均衡系統斷連了,則負載均衡系統是能夠感知的,也需要做出相應的處理,例如,將服務器 從可分配服務器串列中洗掉,否則就會出現服務器都巖機了,任務還不斷地分配給它,這明顯 是不合理的,總而言之,“簡單”是輪詢演算法的優點, 也是它的缺點
加權輪詢
負載均衡系統根據服務器權重進行任務分配,這里的權重一般是根據硬體配置進行靜態配置的,采用動態的方式計算會更加契合業務,但復雜度也會更高,加權輪詢是輪詢的一種特殊形式,其主要目的就是為了解決不同服務器處理能力有差異的問題 , 例如,集群中有新的機器是32核的,老的機器是16核的,那么理論上我們可以假設新機器的處理能力是老機器的2倍,負載均衡系統就可以按照 2 : 1 的比例分配更多的任務給新機 器,從而充分利用新機器的性能,
加權輪詢解決了輪詢演算法中無法根據服務器的配置差異進行任務分配的問題,但同樣存在 無法根據服務器的狀態差異進行任務分配的問題 ,
負載最低優先
負載均衡系統將任務分配給當前負載最低的服務器,這里的負載根據不同的任務型別和業 務場景,可以用不同的指標來衡量,例如:
- LVS 這種 4 層網路負載均衡設備,可以以“連接數”來判斷服務器的狀態,服務器連接 數越大,表明服務器壓力越大
- Nginx這種 7 層網路負載系統,可以以“ HTTP 請求數”來判斷服務器狀態 CNginx 內 置的負載均衡演算法不支持這種方式,需要進行擴展)
- 如果我們自己開發負載均衡系統,可以根據業務特點來選擇指標衡量系統壓力 , 如果是 CPU 密集型,可以以“ CPU負載”來衡量系統壓力:如果是 I/O 密集型 ,則可以以“IIO 負載”來衡量系統壓力
負載最低優先的演算法解決了輪詢演算法中無法感知服務器狀態的問題,由此帶來的代價是復 雜度要增加很多 , 例如:
- 最少連接數優先的演算法要求負載均衡系統統計每個服務器當前建立的連接,其應用場景僅限于負載均衡接收的任何連接請求都會轉發給服務器進行處理,否則如果負載均衡系 統和服務器之間是固定的連接池方式,就不適合采取這種演算法,例如,LVS 可以采取這 種演算法進行負載均衡,而一個通過連接池的方式連接MySQL集群的負載均衡系統就不適合采取這種演算法進行負載均衡,
- CPU 負載最低優先的演算法要求負載均衡系統以某種方式收集每個服務器的CPU負載, 而且要確定是以1分鐘的負載為標準,還是以15分鐘的負載為標準,不存在1分鐘肯定比15分鐘要好或差,不同業務最優的時間間隔是不一樣的,時間間隔太短容易造成頻繁波動,時間間隔太長又可能造成峰值來臨時回應緩慢
負載最低優先演算法基本上能夠比較完美地解決輪詢演算法的缺點,因為采用這種演算法后,負載均衡系統需要感知服務器當前的運行狀態 ,當然,其代價是復雜度大幅上升,通俗來講,輪詢可能是5行代碼就能實作的演算法,而負載最低優先演算法可能要 1000 行才能實作,甚至需要負載均衡系統和服務器都要開發代碼 ,負載最低優先演算法如果本身沒有設計好,或者不適合業務的運行特點,演算法本身就可能成為性能的瓶頸,或者引發很多莫名其妙的問題 , 所以負載最低優先演算法雖然效果看起來很美好, 但實際上真正應用的場景反而沒有輪詢(包括加權輪詢)那么多
性能最優類
負載最低優先類演算法是站在服務器的角度來進行分配的,而性能最優優先類演算法則是站在客戶端的角度來進行分配的,優先將任務分配給處理速度最快的服務器,通過這種方式達到最 快回應客戶端的目的 ,
和負載最低優先類演算法類似,性能最優優先類演算法本質上也是感知了服務器的狀態,只是 通過回應時間這個外部標準來衡量服務器狀態而己,因此性能最優優先類演算法存在 的問題和負 載最低優先類演算法類似,復雜度都很高,主要體現在:
- 負載均衡系統需要收集和分析每個服務器每個任務的回應時間,在大量任務處理的場景下,這種收集和統計本身也會消耗較多的性能
- 為了減少這種統計上的消耗,可以采取采樣的方式來統計,即不統計所有任務的回應時間, 而是抽樣統計部分任務的回應時間來估算整體任務的回應時間,采樣統計雖然能夠減少性 能消耗,但使得復雜度進一步上升, 因為要確定合適的采樣率,來樣率太低會導致結果不準確,采樣率太高會導致性能消耗較大,找到合適的來樣率也是一件復雜的事情
- 無論全部統計,還是采樣統計,都需要選擇合適的周期: 是10秒內性能最優,還是1分鐘內性能最優 ,還是5分鐘內性能最優……沒有放之四海而皆準的周期,需要根據實際業務進行判斷和選擇, 這也是一件比較復雜的事情,甚至出現系統上線后需要不斷地調優才能達到最優設計
Hash 類
負載均衡系統根據任務中的某些關鍵資訊進行 Hash 運算,將相同 Hash 值的請求分配到同一臺服務器上,這樣做的目的主要是為了滿足特定的業務需求, 例如:
- 源地址 Hash
將來源于同一個源IP地址的任務分配給同一個服務器進行處理,適合于存在事務、會話的業務, 例如,當我們通過瀏覽器登錄網上銀行時,會生成一個會話資訊,這個會話是臨時的, 關閉瀏覽器后就失效,網上銀行后臺無須持久化會話資訊,只需要在某臺服 務器上臨時保存這個會話就可以了,但需要保證用戶在會話存在期間,每次都能訪問到同一個服務器,這種業務場景就可以用源地址 Hash 來實作 - ID Hash
將某個ID標識的業務分配到同一個服務器中進行處理,這里的ID一般是臨時性資料的ID(例如 ,session id)例如,上述的網上銀行登錄的例子,用session id hash同樣可以實作同一個會話期間,用戶每次都是訪問到同一臺服務器的目的
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/34702.html
標籤:其他
上一篇:通過RabitMQ實作分布式事務