這是我的本科畢設內容,參考了ICCV頂會論文:
《Seasonal Contrast:
Unsupervised Pre-Training from Uncurated Remote Sensing Data》
翻譯:《季節對比:來自未經管理的遙感資料的無監督的預訓練》
以下內容除了背景為論文翻譯外,其余思路均為原創所想,因此在這里進行記錄并擴充思路以免忘記,
一.背景
遙感和地球自動監測是解決全球范圍挑戰的關鍵,如防災、土地利用監測或應對氣候變化,雖然存在大量的遙感資料,但其中大部分都是未標記的,因此無法用于監督學習演算法,遷移學習方法可以降低深度學習演算法對資料的要求,然而,這些方法大多是在ImageNet上預先訓練的,由于域間隙,不能保證它們對遙感影像的泛化,在這項作業中,我們提出了季節對比(SeCo),這是一個有效的管道,利用未標記資料進行域內遙感表示的預訓練,SeCo管道由兩部分組成,首先,一個有原則的程式來收集大規模的、未標記的和未經整理的遙感資料集,其中包含來自不同時間戳的多個地球位置的影像,其次,利用時間和位置不變性的自監督演算法來學習遙感應用中的可轉移表示,我們的經驗表明,在多個下游任務中,SeCo訓練的模型比ImageNet預訓練的模型和最先進的自我監督學習方法取得了更好的性能,SeCo的資料集和模型將公開,以促進遷移學習并使遙感應用取得迅速進展.
二.關于遙感特征識別的技術實作流程
1.預訓練
本文提出了一種先通過ImageNet進行預訓練的方法,因為如果一開始不通過一個有標注大資料集的進行預訓練的話,意味著每個卷積核都由初始化值進行訓練,又由于遙感影像特征單一的原因,每個卷積核很有可能會提取相同的特征,但我們希望每個卷積核都能提取有用的特征,那么為了做到這一點,就需要大量的資料集,
一個好的大量資料集,以ImageNet為例,有兩個特點:①. 資料量巨大,什么類別的圖都有,能清楚地劃分出語意特征;②. 它有一千個類標,類標數量多會使卷積核學到很好的特征,
如果直接把一個神經網路不用預訓練的話,直接拿遙感資料集做訓練,很有可能因為資料量過小或類別量少而導致很多卷積核學到相同的特征,這樣的神經網路效果就會很差,但如果將神經網路在ImageNet上訓練后再放遙感資料,相當于這個神經網路已經定型了,每個卷積核已經具備了一定的類別特征,它再去學習(資料微調)的時候,可能只是把這個特征做一些微調,這時候就會發現它保留了很多原始學到的特征,這便是用ImageNet預訓練的原因,
看到這里,我迸發了一個問題:預訓練的資料集極大,并且有很多生活影像(人、動物、花草等)與遙感影像特征相去甚遠,那么我們的卷積核一定會學到一些我們用不到的特征,
是的沒錯,但實際上神經網路提的特征,我們認為無法手動洗掉,因為我們也不知道這些特征的意義是什么,但神經網路理論上設計的越大,它包含有效特征的可能性就越多,但是這樣會引來一個問題:
一旦特征量大到一定程度,會將一些有效特征沖淡,
要解決這個問題要設計到一個領域叫做計算智能,查閱后發現是個非常龐大的學術體系,但是還有一個辦法可以解決:
自監督學習中的知識蒸餾(自蒸餾),自蒸餾(Self Distillation): 是采用有監督學習進行知識蒸餾,只是知識蒸餾的方法,采用的方式是teacher模型和student模型是一個模型,也就是一個模型來指導自己進行學習,完成知識蒸餾,所以是自蒸餾,自己蒸餾知識來指導自己,
舉個栗子,一個教師網路,這個網路學的是ImageNet,然后再做一個很小的學生網路學習高光譜影像,然后教師網路去教學生網路,教的方法通過微調資料集(資料集用遙感高光譜影像)輸入到IN網路這個大的教師模型,然后會輸出屬于遙感影像的特征出來,然后我讓學生網路去學習這些遙感特征,非遙感特征就不存了,
2.自監督學習
首先,預訓練和自監督學習解決的是兩個完全不同的問題,預訓練技術屬于知識遷移,他關注的問題是怎么讓這個模型學習更加泛化,能通過借助別人的知識,讓自己學到更好的一個特征;自監督學習要解決的問題是人為地找到一個普適性的分類方法,通過有效利用沒標注對的原始樣本
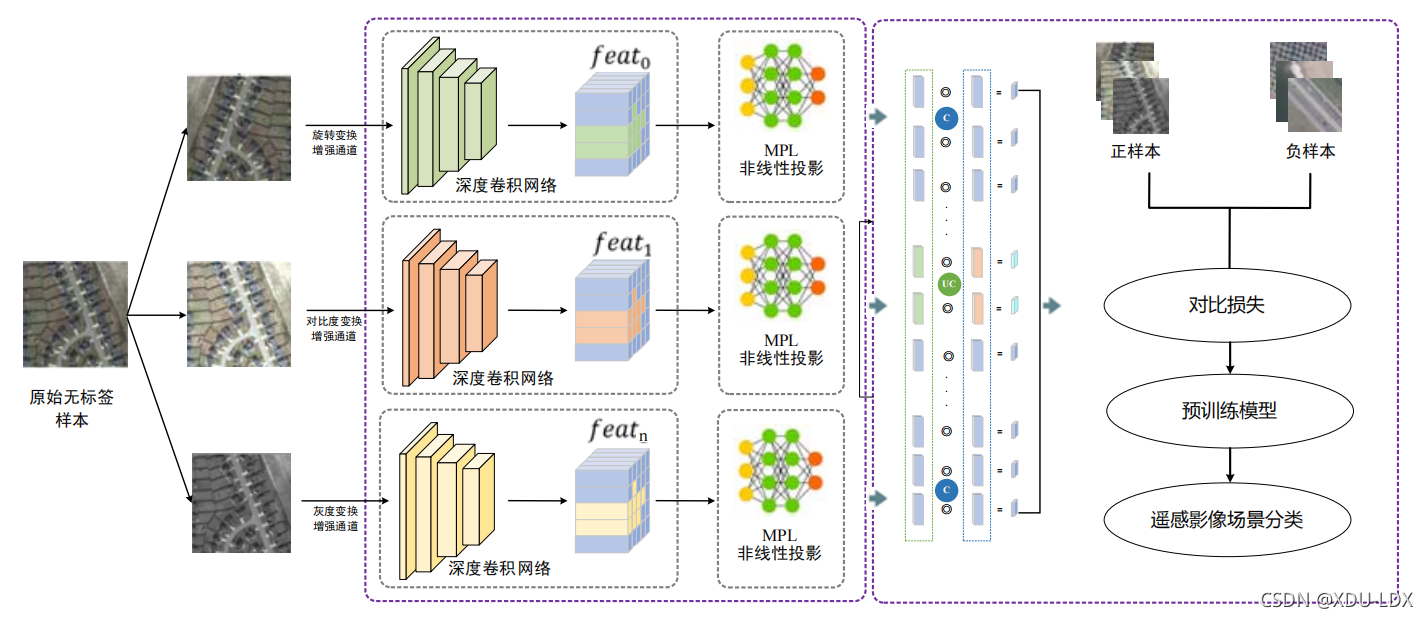
通過圖可以看到最終生成了正樣本和負樣本,正樣本就是通過一張圖自己做特征增強后的資料,負樣本就是一個別的領域的圖,對于一個好的卷積核(特征提取器)他要學習的是一個哪怕進行旋轉調色后也不發生改變的特征,但實際上對于一張圖來講,將它進行旋轉后,這個特征會在低層發生變化,在高層不發生變化,因為神經網路本身的卷積核是一個濾波器,同樣一個圖發生旋轉通過濾波器輸出的結果一定是不一樣的,但是越到深層卷積后,旋轉前后的照片,就會趨于一致,因為淺層神經網路學習到的是一個影像的邊緣或者是幾何圖形(比如發現一張圖里有一個圓形、矩形等),但越往后學習的是語意圖形(比如里面有沒有耳朵、鼻子,這個是旋轉也沒辦法改變的語意資訊),所以說這篇文章便是利用了神經網路低層級的語意資訊,容易受旋轉和色彩進行改變的而去做的特征增強,
這里又會產生一個新的問題:為什么最終通過深層神經網路都會趨于一致,特征增強還能提高識別精度呢?
因為我們所有的分類器本質上是在一個空間上采樣,這是一個擬合的程序,理論上講我們能夠采樣的點越多,空間就會更快且精準地收斂,這是神經網路中最經典的奧斯卡姆剃刀,在自監督學中最大的特點就是,我需要讓神經網路建立足夠多的影像(特征增強),他不像有標注的資料集,采樣點非常精準,無標注的點可能并不是很準,但它會在我們標注的范圍內變化,如果能很好的利用起這個點那就會是曲線畫的更好(K-means),因此,無監督學習它更重要的是在解決淺層神經網路,因為深層神經網路他更受限于你設計的對比損失或者人為制定的語意,對于淺層神經網路來講,他會建立足夠多的樣本,學出來的特征就會更具有魯棒性,
再舉個栗子,比如我們現在去實作一個二分類任務,我們在圖上畫了10個正樣本,10個負樣本,我們找出一條線去進行劃分,那么這條線的可能性是比較大的,但如果我們通過特征增強去讓一個點開始變換,在圖中的反應就是開始抖動,那么這個點就從一個點變成了一個范圍,那么中間這潭訓分的線就會變得更加清晰,
遙感影像樣本少,標簽殘缺,需要自監督學習,為了擴充樣本量,又引入了特征增強這個概念,《學習筆記1》有提到就不贅述了,上次提出了一個三分支的自監督學習方式,通過旋轉、對比度、灰度三種值變換以獲得更多樣本,ICCV這篇文章是上一篇論文的升級版,它加入了時間維度,將最近的對比自監督學習方法與衛星提供的時間資訊相結合,學習對季節變化同時具有變化和不變的良好視覺表示,用人話來說就是利用哨兵二號的環球周期,對一個地區一年中發生的季節變化進行采集,同時為了避免獲得來自同一時期的影像,每隔一年拍一次,以此達到特征增強的效果
三.針對該論文的創新點
1.對于神經網路預訓練
目前國內由于衛星較少,資料集匱乏,大部分論文都采用ImageNet去做預訓練來生成一個初步的神經網路,因為現在人們更傾向于用一個很大的資料集去做預處理,哪怕很多圖不相關,那也比見的圖少要好,但是遙感影像與IN資料集的色域和特征區別很大,因此不能保證初始神經網路對遙感影像的泛化能力,因此,我認為可以選擇更加貼近于遙感影像且很大的資料集進行預訓練,ICCV這篇文章的資料集:SeCo目前已經開源,如果它具備我們需要的特征類別的話,將會是一個很好的資料集,雖然也可以考慮自己找更好的資料集,但這個難度應該很大,不然之前大家也不會用IN了,如果之后能夠找到一個更適用于遙感預訓練的資料集,感覺這都是一個很厲害的論文,
這里在之后可以關注一下HRNet,這個網路結構使得不用預訓練也能達到很好的效果,由于還沒認真學它在此只是立個flag,
2.對于神經網路自監督學習
目前這里看過兩篇論文做自監督學習的特征增強,一篇是國內:旋轉、對比度、灰度值,一篇是頂會:裁剪、顏色抖動、翻轉、不同時間,頂會論文是增加了時間維度,以此來增多了影像特征的數量,但鑒于我的目標是對飛機等目標進行檢測,時間維度的意義并不大(一年后飛機也估計都沒影了),因此我這里提出一個思想:發掘一個場景的變與不變,
以飛機為例,變的是背后的場景,不變的是飛機本身的形狀,那么我們可以找到很多飛機的圖(最好要比我們訓練集的樣本清晰,不清晰也問題不大,因為直接會做標注),先把它裁剪地只剩下飛機,然后貼到我們的無飛機的遙感背景中,以此實作特征增強的效果,
還有一個思路,目前我們現在只有正樣本和負樣本,那么我們可以建立一種中立樣本:把兩張遙感影像疊在一起,相當于把兩張圖都變成半透明,然后全部融合到一起,比如把兩個人的臉融合到一張圖上,甲80%透明度,乙20%透明度,目前看到的是甲的臉,但隨著透明度比例不斷發生變化,人們會慢慢發現甲的臉變成乙的臉,那么對于神經網路來說,兩張圖是remix到一起的時候,神經網路應該輸入一個在甲和乙兩個類標之間的一個值,是最合理的,這也是特征增強的一種方式,輸出的結果也從原先的確定值變為了可能性的比例數字,
意義在于: 神經網路前面的分類器把淺層特征提取來后,后面的分類是根據淺層特征猜到底是什么語意,但實際上神經網路是一個比較混沌的東西,假設一張飛機的圖,她可能會送出9張飛機的特征,但可能也送出1份車的特征,因為有可能飛機中的背景里,有個東西長得看起來似乎是一輛車,通過這種remix的方法可以讓神經網路更加清晰地去理解該怎樣正確輸出值,舉個例子,我對一個飛機圖加了20%車進去,但我逼著他輸出飛機的結果,這樣便能一定程度上將結果進行銳化,類似于將結果做了一個L1范數正則化(也就是減少誤差),這樣便可以更關注車和飛機到底有哪些不同,
3.對于神經網路的卷積核
傳統深度學習中,卷積核一般都是3* 3的方形,因為對于傳統影像而言,一個人站著就是站著,方形能夠最好的表現出語意資訊,但對于遙感領域,歪曲角度表現資訊的情況是比較常見的,它沒有方向的統一性 ,所以在遙感領域卷積核怎么旋轉,形狀也是一個問題,
對于現在的卷積核而言,都是3* 3的18個引數,因為5* 5的卷積核的引數是25個,兩層3* 3的卷積核就相當于覆寫了一個5* 5的卷積核,兩個3* 3的卷積核的感受野相當于一個5* 5的卷積核,但是引數量減少了三分之一,因為引數越多模型越難訓練,因此我們盡可能讓他卷積層多來減少引數量,
目前很多遙感影像都是用VGG去做神經網路而不用Resnet,盡管rn的表現效果遠好于VGG,但大家還是用VGG,因為對于遙感任務,他對空間的要求非常高,但resnet他是犧牲了空間的識別能力換區了語意的復雜程度,因為rn經過一百多層以后他左上角的那個像素點不一定對應的是原始影像的左上角,但由于VGG他的結構和層數比較淺,他提取的特征圖左上角和原始左上角的對應關系相對較強,所以一般遙感都用VGG做,
微軟在做影像分類的時候提出過一個可變卷積核,是否可以用到遙感領域的深度學習,可以之后進一步挖掘一下,資料:https://zhuanlan.zhihu.com/p/338004985
三.技術實作路徑
針對一個遙感地面目標檢測技術,
1. 首先,通過類似ImageNet這樣的大資料集進行預訓練,目前選擇SeCo資料集進行嘗試,可能會有比IN更好的效果,初步建立一個具有特征類別的神經網路(如果模型太大還可以用知識蒸餾去做模型剪枝,后話了)
2. 通過自監督學習中的特征增強進行資料微調,鑒于我要做的是針對地面中飛機、車輛等物體的類別識別,目前想到的特征增強的方式,【隨機裁剪】【隨機色域變換】【增加物體】【隨機旋轉】,并加入中立樣本去減少識別誤差
3. 完成一些下游任務,做一些測驗作業,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/347047.html
標籤:AI
下一篇:人工智能之數學基礎篇—微積分