目錄
基礎理論
一、生成驗證碼資料集
1、生成驗證碼訓練集
1-0、判斷檔案夾是否為空
1-1、創建字符集(數字、大小寫英文字母)
1-2、隨機生成驗證碼(1000個,長度為4)
2、生成驗證碼測驗集
代碼
二、獲取資料(訓練集、測驗集)
1、獲取資料和標簽
1-1、獲取訓練集資料和標簽(路徑和標簽)
1-2、獲取測驗集資料和標簽(路徑和標簽)
1-3、資料組合(影像路徑和標簽)
2、打亂資料
3、處理每條資料
4、自定義重復周期和批次大小
5、處理每批資料
6、獲取一批次資料和標簽
三、創建神經網路
1、創建50層殘差神經網路
2、設定輸入層
3、平均池化(壓縮資料)
4、配置輸出層
5、配置模型
6、編譯(多任務學習)
7、回呼函式配置
8、訓練模型
總代碼
基礎理論
多任務學習(Multi-task Learning)是深度學習中很常用的一種模型訓練策略,意思其實也很簡單,就是同時訓練多個任務,給大家舉兩個例子大家就明白了,比如目標檢測專案中,我們既要知道1、目標所在的位置(也就是預測框坐標值),也要知道2、預測框內是什么物體,預測框的坐標值是連續型資料,所以是一個回歸任務;預測框的物體是一個具體的類別,所以是一個分類任務,
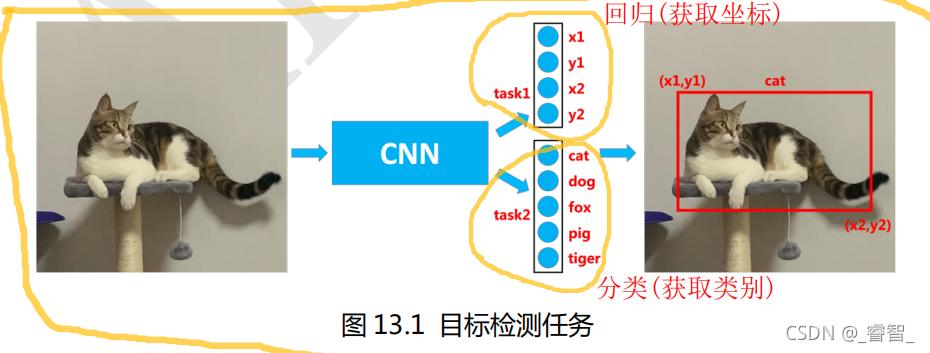

不同的任務其實也可以共享卷積層,因為卷積層的作用主要是特征提取,先提取影像的特征,然后再使用這些特征來預測人的年齡,表情,性別, 用于特征提取的卷積層可以共享 ,不過 不同的任務還需要有自己的 task layer,專門用于訓練特定任務 ,
我們要識別的驗證碼有 4 個字符,我們可以給模型定義 4 個任務,每個任務負責識別 1 個字符,第一個任務識別第一個字符,第二個任務識別第二個字符,第三個任務識別第三個字符,第四個任務識別第四個字符,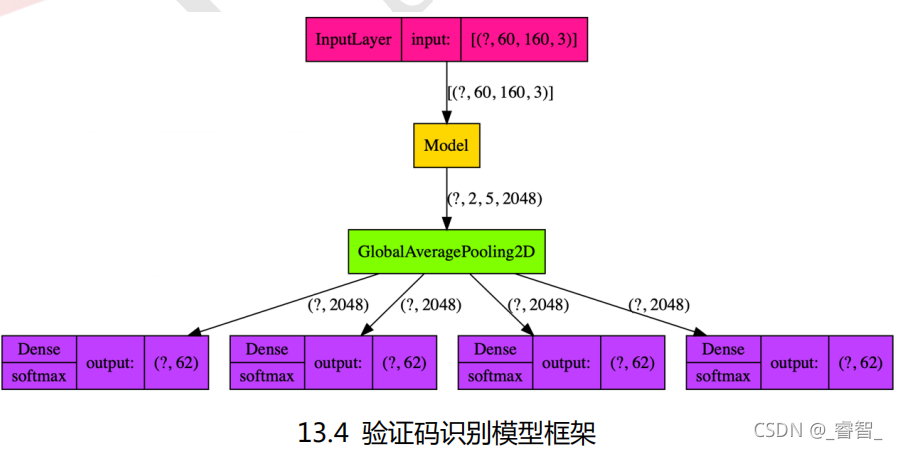
一、生成驗證碼資料集
1、生成驗證碼訓練集
1-0、判斷檔案夾是否為空
if not os.listdir('D:\\Study\\AI\OpenCV\\draft.py\\captcha\\train'):
Create_train_data() # 生成驗證碼訓練集1-1、創建字符集(數字、大小寫英文字母)
# 1、創建字符集(字符包含所有數字和所有大小寫英文字母,一共62(10+26+26)個)
characters = string.digits + string.ascii_letters
# 數字 英文字母(大小寫)得到如下資料:0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
1-2、隨機生成驗證碼(1000個,長度為4)
# 2、隨機產生驗證碼(共1000個,每個長度為4)
for i in range(1000):
verification_list = []1、生成隨機字符:
# 2-1、開始生產隨機字符(4位)
for j in range(4):
c = random.choice(characters) # 隨機選擇(從characters里面隨機抽取)
verification_list.append(c)2、實體化驗證碼生成器:
# 2-2、實體化驗證碼生成器
image = ImageCaptcha(width=160, height=60) # 寬:160,高:603、連接串列字符(轉字串)
# 2-3、連接串列字符
verification_list = ''.join(verification_list)4、生成驗證碼
# 2-4、生成驗證碼
image.write(verification_list, 'captcha/train/' + verification_list + '.jpg')
2、生成驗證碼測驗集
程序同上,測驗集資料不需要那么多,把1000張換成200張即可,

代碼
# 創建訓練集(驗證碼)
def Create_train_data():
# 1、創建字符集(字符包含所有數字和所有大小寫英文字母,一共62(10+26+26)個)
characters = string.digits + string.ascii_letters
# 數字 英文字母(大小寫)
# 2、隨機產生驗證碼(共1000個,每個長度為4)
for i in range(1000):
verification_list = []
# 2-1、開始生產隨機字符(4位)
for j in range(4):
c = random.choice(characters) # 隨機選擇(從characters里面隨機抽取)
verification_list.append(c)
# 2-2、實體化驗證碼生成器
image = ImageCaptcha(width=160, height=60) # 寬:160,高:60
# 2-3、連接串列字符
verification_list = ''.join(verification_list)
# 2-4、生成驗證碼
image.write(verification_list, 'captcha/train/' + verification_list + '.jpg')
# 創建測驗集(驗證碼)
def Create_test_data():
# 1、創建字符集(字符包含所有數字和所有大小寫英文字母,一共62(10+26+26)個)
characters = string.digits + string.ascii_letters
# 數字 英文字母(大小寫)
# 2、隨機產生驗證碼(共200個,每個長度為4)
for i in range(200):
verification_list = []
# 2-1、開始生產隨機字符(4位)
for j in range(4):
c = random.choice(characters) # 隨機選擇(從characters里面隨機抽取)
verification_list.append(c)
# 2-2、實體化驗證碼生成器
image = ImageCaptcha(width=160, height=60) # 寬:160,高:60
# 2-3、連接串列字符
verification_list = ''.join(verification_list)
# 2-4、生成驗證碼
image.write(verification_list, 'captcha/test/' + verification_list + '.jpg')
二、獲取資料(訓練集、測驗集)
1、獲取資料和標簽
1-1、獲取訓練集資料和標簽(路徑和標簽)
# 1-1、獲取訓練集資料和標簽(路徑和標簽)
train_data, train_target = get_filenames_and_classes("./captcha/train/")# 1000張圖片,長度4獲取所有圖片路徑,標簽轉獨熱編碼 :
# 獲取所有驗證碼圖片路徑和標簽
def get_filenames_and_classes(dataset_dir):
# 圖片路徑和標簽
paths ,targets = [], []
# 獲取每個圖片的路徑和標簽
for filename in os.listdir(dataset_dir):
# 1、獲取檔案路徑
path = os.path.join(dataset_dir, filename)
# 路徑 檔案名
# 完成1:保存圖片路徑
paths.append(path)
# 2、獲取驗證碼標簽(取檔案名的前 4 位,也就是驗證碼的標簽)
target = filename[0:4]
# 定義一個空label(獲取4*62的陣列,用0填充)
label = np.zeros((4, classes_num), dtype=np.uint8)
# 3、標簽轉獨熱編碼
for i, ch in enumerate(target):
# i:索引 ch:字符
# 標記(設定標簽):獨熱編碼 one-hot 格式
label[i, characters.find(ch)] = 1
# 陣列索引 字符下標(字符ch在characters中的下標)
# 完成2:保存獨熱編碼的標簽
targets.append(label)
# 回傳圖片路徑和標簽
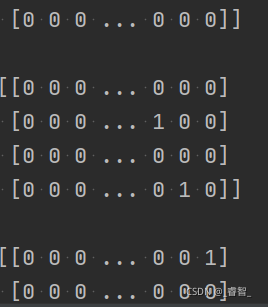
return np.array(paths), np.array(targets)
1-2、獲取測驗集資料和標簽(路徑和標簽)
# 1-2、獲取測驗集資料和標簽(路徑和標簽)
test_data, test_target = get_filenames_and_classes("./captcha/test/") # 200張圖片,長度4獲取資料函式同上,
1-3、資料組合(影像路徑和標簽)
# 1-3、資料組合(影像路徑和標簽) (創建 dataset 物件,傳入圖片路徑和標簽)
dataset_train = tf.data.Dataset.from_tensor_slices((train_data, train_target))
dataset_test = tf.data.Dataset.from_tensor_slices((test_data, test_target))2、打亂資料
# 2、打亂資料
dataset_train = dataset_train.shuffle(buffer_size=100, reshuffle_each_iteration=True) # map-可以自定義一個函式來處理每一條資料
dataset_test = dataset_test.shuffle(buffer_size=20, reshuffle_each_iteration=True)
# 資料緩沖器大小 隨機打亂(是/否)3、處理每條資料
# 3、對每條資料進行處理(影像地址->3通道影像->歸一化)
dataset_train = dataset_train.map(image_function)
dataset_test = dataset_test.map(image_function)
# map函式:可以自定義一個函式來處理每一條資料4、自定義重復周期和批次大小
# 4、自定義重復周期和批次大小
dataset_train = dataset_train.repeat(1) # 資料重復生成 1 個周期
dataset_test = dataset_test.repeat(1) # 資料重復生成 1 個周期
dataset_train = dataset_train.batch(64) # 定義批次大小64
dataset_test = dataset_test.batch(64) # 定義批次大小645、處理每批資料
# 5、處理每批資料
# 注意這個 map 和前面的 map 有所不同,第一個 map 在 batch 之前,所以是處理每一條資料
# 這個 map 在 batch 之后,所以是處理每一個 batch 的資料
dataset_train = dataset_train.map(label_function)
dataset_test = dataset_test.map(label_function)6、獲取一批次資料和標簽
# 獲取一批資料和標簽
trainx, trainy = next(iter(dataset_train))
testx, testy = next(iter(dataset_test))資料(歸一化后的):
標簽(獨熱編碼):
三、創建神經網路
1、先配置好50層殘差神經網路;
2、(用已配置好的殘差神經網路)配置輸入層;
3、把配置好的輸入層池化;
4、(用池化后的結果)配置輸出層(多任務學習);
5、(用輸入層的shape和輸出層)配置模型,
# 三、構造神經網路
Create_Network()1、創建50層殘差神經網路
# 1、構造resnet50神經網路(50層殘差網路)
resnet50 = ResNet50(weights='imagenet', include_top=False, input_shape=(height, width, 3)) # 設定輸入
# weights:權重(imagenet:加載預訓練權重)
# include_top:是否保留頂層的全連接網路
# input_shape:指明輸入圖片的shape,僅當include_top=False有效2、設定輸入層
# 2、設定輸入層
inputs = Input((height, width, 3)) # 設定輸入層大小
x = resnet50(inputs) # 使用 resnet50 進行特征提取3、平均池化(壓縮資料)
# 3、平均池化(壓縮資料)
x = GlobalAvgPool2D()(x)4、配置輸出層
多任務學習,把驗證碼識別的4個字符看成是4個不同的任務,每個任務負責識別1個字符,
# 4、配置輸出層(多任務學習)
# 把驗證碼識別的4個字符看成是4個不同的任務,每個任務負責識別1個字符
x0 = Dense(classes_num, activation='softmax', name='out0')(x)
x1 = Dense(classes_num, activation='softmax', name='out1')(x)
x2 = Dense(classes_num, activation='softmax', name='out2')(x)
x3 = Dense(classes_num, activation='softmax', name='out3')(x)5、配置模型
# 5、配置模型(輸入層、輸出層)
model = Model(inputs, [x0, x1, x2, x3])6、編譯(多任務學習)
損失函式、權重、優化器、監視等等設定,
# 6、編譯(多任務學習)(損失函式、權重、優化器、監視等等設定)
# (4個任務我們可以定義4個loss)
model.compile(loss={'out0': 'categorical_crossentropy',
'out1': 'categorical_crossentropy',
'out2': 'categorical_crossentropy',
'out3': 'categorical_crossentropy'},
loss_weights={'out0': 1, 'out1': 1, 'out2': 1, 'out3': 1},
optimizer=SGD(lr=0.01, momentum=0.9),
metrics=['acc'])
# loss:損失函式 loss_weights:權重 optimizer:優化器(lr:學習率;momentum:帶動量的梯度下降)
# metrics:監視(acc)7、回呼函式配置
# 7、回呼函式(停止訓練、保存資料、保存模型、調整學習率)
callbacks = [EarlyStopping(monitor='val_loss', patience=6, verbose=1),
CSVLogger('Captcha_tfdata.csv'),
ModelCheckpoint('Best_Captcha_tfdata.h5', monitor='val_loss', save_best_only=True),
ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1)]
# monitor='val_loss':監控指標'val_loss'
# EarlyStopping:讓模型停止(6個周期,val_loss沒有下降則訓練結束)
# CSVLogger: 保存訓練資料
# ModelCheckpoint:保存模型(保存所有訓練周期中val_loss最低的模型)
# ReduceLROnPlateau 學習率調整,連續3個周期,val_loss沒有下降,則當前學習率乘以0.18、訓練模型
# 8、訓練模型
model.fit(x=dataset_train, epochs=epochs, validation_data=dataset_test, callbacks=callbacks)訓練效果:
暫時沒有訓練太多次,不過通過這幾次的訓練,已經可以看到準確率明顯提高了許多,


雖說沒有完全訓練完,但是可以看到,第12次每個字符的平均正確率已經可以達到99%+了,效果挺好的,
總代碼
# 驗證碼生成與識別
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
from tensorflow.keras.layers import Dense,GlobalAvgPool2D,Input
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.models import Model
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.callbacks import EarlyStopping,CSVLogger,ModelCheckpoint,ReduceLROnPlateau
import string
import numpy as np
import os
import random
from captcha.image import ImageCaptcha
from plot_model import plot_model
# 字符包含所有數字和所有小寫英文字母,一共 62 個
characters = string.digits + string.ascii_letters
# 數字 字母
# 類別數(62)
classes_num = len(characters)
# 周期數
epochs = 100
# 圖片寬度
width = 160
# 圖片高度
height = 60
# 創建訓練集(驗證碼)
def Create_train_data():
# 1、創建字符集(字符包含所有數字和所有大小寫英文字母,一共62(10+26+26)個)
characters = string.digits + string.ascii_letters
# 數字 英文字母(大小寫)
# 2、隨機產生驗證碼(共1000個,每個長度為4)
for i in range(1000):
verification_list = []
# 2-1、開始生產隨機字符(4位)
for j in range(4):
c = random.choice(characters) # 隨機選擇(從characters里面隨機抽取)
verification_list.append(c)
# 2-2、實體化驗證碼生成器
image = ImageCaptcha(width=160, height=60) # 寬:160,高:60
# 2-3、連接串列字符
verification_list = ''.join(verification_list)
# 2-4、生成驗證碼
image.write(verification_list, 'captcha/train/' + verification_list + '.jpg')
# 創建測驗集(驗證碼)
def Create_test_data():
# 1、創建字符集(字符包含所有數字和所有大小寫英文字母,一共62(10+26+26)個)
characters = string.digits + string.ascii_letters
# 數字 英文字母(大小寫)
# 2、隨機產生驗證碼(共200個,每個長度為4)
for i in range(200):
verification_list = []
# 2-1、開始生產隨機字符(4位)
for j in range(4):
c = random.choice(characters) # 隨機選擇(從characters里面隨機抽取)
verification_list.append(c)
# 2-2、實體化驗證碼生成器
image = ImageCaptcha(width=160, height=60) # 寬:160,高:60
# 2-3、連接串列字符
verification_list = ''.join(verification_list)
# 2-4、生成驗證碼
image.write(verification_list, 'captcha/test/' + verification_list + '.jpg')
# 獲取所有驗證碼圖片路徑和標簽
def get_filenames_and_classes(dataset_dir):
# 圖片路徑和標簽
paths ,targets = [], []
# 獲取每個圖片的路徑和標簽
for filename in os.listdir(dataset_dir):
# 1、獲取檔案路徑
path = os.path.join(dataset_dir, filename)
# 路徑 檔案名
# 完成1:保存圖片路徑
paths.append(path)
# 2、獲取驗證碼標簽(取檔案名的前 4 位,也就是驗證碼的標簽)
target = filename[0:4]
# 定義一個空label(獲取4*62的陣列,用0填充)
label = np.zeros((4, classes_num), dtype=np.uint8)
# 3、標簽轉獨熱編碼
for i, ch in enumerate(target):
# i:索引 ch:字符
# 標記(設定標簽):獨熱編碼 one-hot 格式
label[i, characters.find(ch)] = 1
# 陣列索引 字符下標(字符ch在characters中的下標)
# 完成2:保存獨熱編碼的標簽
targets.append(label)
# 回傳圖片路徑和標簽
return np.array(paths), np.array(targets)
# 影像處理函式
# 輸入:影像路徑、標簽
# 輸出:影像、標簽
def image_function(filenames, label):
# 1、根據圖片路徑讀取圖片內容
image = tf.io.read_file(filenames)
# 2、解碼為jpeg格式、3通道(正規影像)
image = tf.image.decode_jpeg(image, channels=3)
# 3、歸一化
image = tf.cast(image, tf.float32) / 255.0
# 回傳圖片資料和標簽
return image, label
# 標簽處理函式
# 獲得每一個批次的圖片資料和標簽
def label_function(image, label):
# transpose 改變資料的維度,比如原來的資料 shape 是(64,4,62)
# 這里的 64 是批次大小,驗證碼長度為 4 有 4 個標簽,62 是 62 個不同的字符
# tf.transpose(label,[1,0,2])計算后得到的 shape 為(4,64,62)
# 原來的第 1 個維度變成了第 0 維度,原來的第 0 維度變成了 1 維度,第 2 維不變
# (64,4,62)->(4,64,62)
label = tf.transpose(label, [1, 0, 2])
# 回傳圖片內容和標簽,注意這里標簽的回傳,我們的模型會定義 4 個任務,所以這里回傳 4 個標簽
# 每個標簽的 shape 為(64,62),64 是批次大小,62 是獨熱編碼格式的標簽
return image, (label[0], label[1], label[2], label[3])
# 獲取資料(訓練集、測驗集)
def GetData():
global dataset_train, dataset_test
# 1、獲取資料和標簽
# 1-1、獲取訓練集資料和標簽(路徑和標簽)
train_data, train_target = get_filenames_and_classes("./captcha/train/")# 1000張圖片,長度4
# 1-2、獲取測驗集資料和標簽(路徑和標簽)
test_data, test_target = get_filenames_and_classes("./captcha/test/") # 200張圖片,長度4
# 1-3、資料組合(影像路徑和標簽) (創建 dataset 物件,傳入圖片路徑和標簽)
dataset_train = tf.data.Dataset.from_tensor_slices((train_data, train_target))
dataset_test = tf.data.Dataset.from_tensor_slices((test_data, test_target))
# 2、打亂資料
dataset_train = dataset_train.shuffle(buffer_size=100, reshuffle_each_iteration=True) # map-可以自定義一個函式來處理每一條資料
dataset_test = dataset_test.shuffle(buffer_size=20, reshuffle_each_iteration=True)
# 資料緩沖器大小 隨機打亂(是/否)
# 3、對每條資料進行處理(影像地址->3通道影像->歸一化)
dataset_train = dataset_train.map(image_function)
dataset_test = dataset_test.map(image_function)
# map函式:可以自定義一個函式來處理每一條資料
# 4、自定義重復周期和批次大小
dataset_train = dataset_train.repeat(1) # 資料重復生成 1 個周期
dataset_test = dataset_test.repeat(1) # 資料重復生成 1 個周期
dataset_train = dataset_train.batch(64) # 定義批次大小64
dataset_test = dataset_test.batch(64) # 定義批次大小64
# 5、處理每批資料
# 注意這個 map 和前面的 map 有所不同,第一個 map 在 batch 之前,所以是處理每一條資料
# 這個 map 在 batch 之后,所以是處理每一個 batch 的資料
dataset_train = dataset_train.map(label_function)
dataset_test = dataset_test.map(label_function)
# 獲取一批次資料和標簽
trainx, trainy = next(iter(dataset_train))
testx, testy = next(iter(dataset_test))
# print(trainx)
# print(trainy)
# print(testx)
# print(testy)
# 創建神經網路
def Create_Network():
# 1、構造resnet50神經網路(50層殘差網路)
resnet50 = ResNet50(weights='imagenet', include_top=False, input_shape=(height, width, 3)) # 設定輸入
# weights:權重(imagenet:加載預訓練權重)
# include_top:是否保留頂層的全連接網路
# input_shape:指明輸入圖片的shape,僅當include_top=False有效
# 2、設定輸入層
inputs = Input((height, width, 3)) # 設定輸入層大小
x = resnet50(inputs) # 使用 resnet50 進行特征提取
# 3、平均池化(壓縮資料)
x = GlobalAvgPool2D()(x)
# 4、配置輸出層(多任務學習)
# 把驗證碼識別的4個字符看成是4個不同的任務,每個任務負責識別1個字符
x0 = Dense(classes_num, activation='softmax', name='out0')(x)
x1 = Dense(classes_num, activation='softmax', name='out1')(x)
x2 = Dense(classes_num, activation='softmax', name='out2')(x)
x3 = Dense(classes_num, activation='softmax', name='out3')(x)
# 5、配置模型(輸入層、輸出層)
model = Model(inputs, [x0, x1, x2, x3])
# 6、編譯(多任務學習)(損失函式、權重、優化器、監視等等設定)
# (4個任務我們可以定義4個loss)
model.compile(loss={'out0': 'categorical_crossentropy',
'out1': 'categorical_crossentropy',
'out2': 'categorical_crossentropy',
'out3': 'categorical_crossentropy'},
loss_weights={'out0': 1, 'out1': 1, 'out2': 1, 'out3': 1},
optimizer=SGD(lr=0.01, momentum=0.9),
metrics=['acc'])
# loss:損失函式 loss_weights:權重 optimizer:優化器(lr:學習率;momentum:帶動量的梯度下降)
# metrics:監視(acc)
# 7、回呼函式(停止訓練、保存資料、保存模型、調整學習率)
callbacks = [EarlyStopping(monitor='val_loss', patience=6, verbose=1),
CSVLogger('Captcha_tfdata.csv'),
ModelCheckpoint('Best_Captcha_tfdata.h5', monitor='val_loss', save_best_only=True),
ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=3, verbose=1)]
# monitor='val_loss':監控指標'val_loss'
# EarlyStopping:讓模型停止(6個周期,val_loss沒有下降則訓練結束)
# CSVLogger: 保存訓練資料
# ModelCheckpoint:保存模型(保存所有訓練周期中val_loss最低的模型)
# ReduceLROnPlateau 學習率調整,連續3個周期,val_loss沒有下降,則當前學習率乘以0.1
# 8、訓練模型
model.fit(x=dataset_train, epochs=epochs, validation_data=dataset_test, callbacks=callbacks)
if __name__ == '__main__':
# 一、創建驗證碼資料集
# 判斷訓練集檔案夾是否為空
if not os.listdir('D:\\Study\\AI\OpenCV\\draft.py\\captcha\\train'):
Create_train_data() # 生成驗證碼訓練集
# 判斷測驗集檔案夾是否為空
if not os.listdir('D:\\Study\\AI\OpenCV\\draft.py\\captcha\\test'):
Create_test_data() # 生成驗證碼測驗集
# 二、獲取資料
GetData()
# 三、構造神經網路
Create_Network()轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/347054.html
標籤:AI