新建一個 php 檔案:a.php
<?php
$a = "a.txt";
include("php://filter/resource=" . $a);
在同一目錄下新建一個檔案:a.txt(內容為 <?php phpinfo();?> 的 base64 編碼)
PD9waHAgcGhwaW5mbygpOz8+
在對應檔案的相關函式下個斷點:
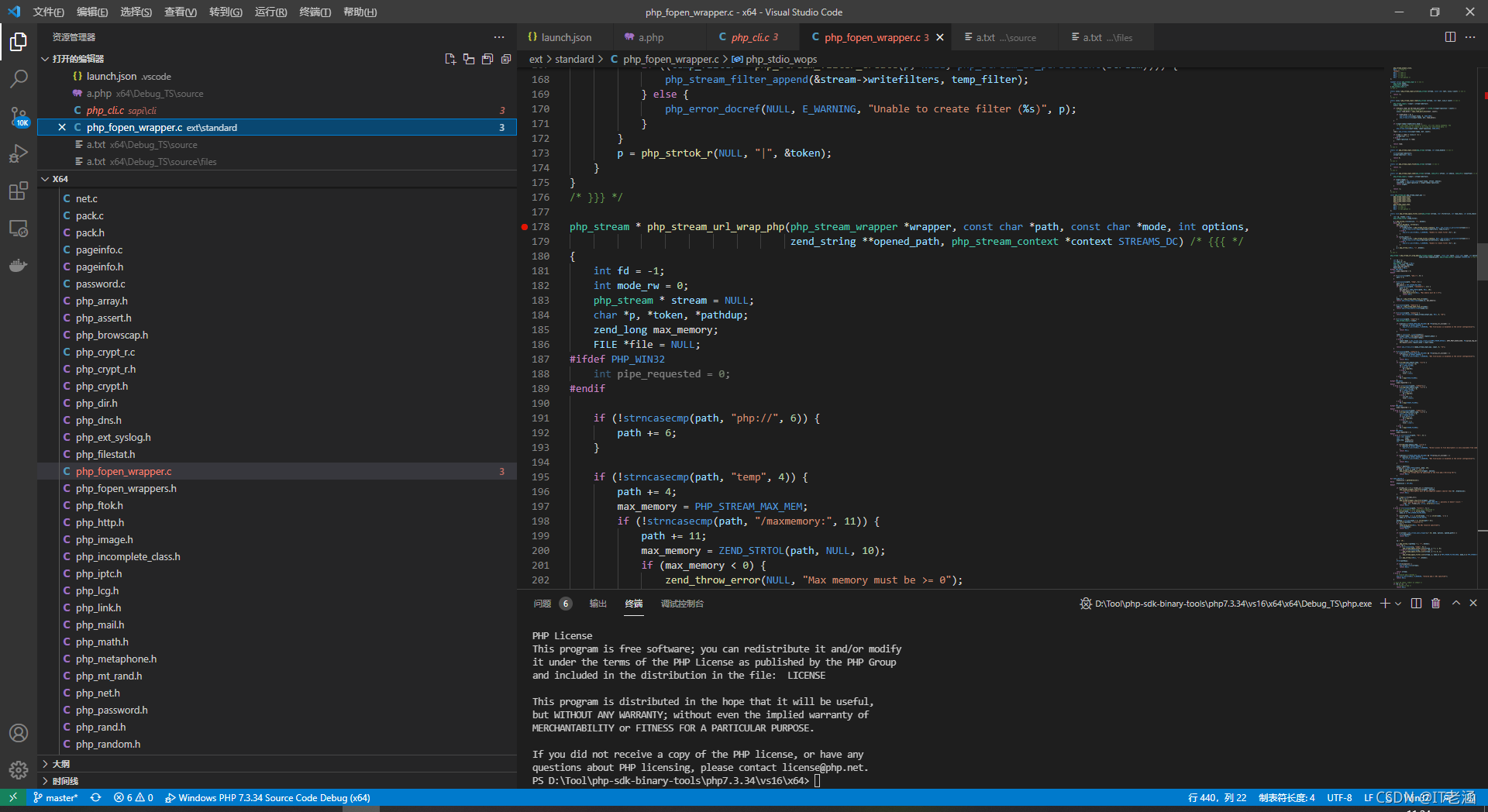
【資料】
貼一下關鍵代碼:
php_stream * php_stream_url_wrap_php(php_stream_wrapper *wrapper, const char *path, const char *mode, int options,
zend_string **opened_path, php_stream_context *context STREAMS_DC) /* {{{ */
{
...
if (!strncasecmp(path, "php://", 6)) {
}
if (!strncasecmp(path, "temp", 4)) {
}
if (!strcasecmp(path, "memory")) {
}
if (!strcasecmp(path, "output")) {
}
if (!strcasecmp(path, "input")) {
}
if (!strcasecmp(path, "stdin")) {
} else if (!strcasecmp(path, "stdout")) {
} else if (!strcasecmp(path, "stderr")) {
} else if (!strncasecmp(path, "fd/", 3)) {
} else if (!strncasecmp(path, "filter/", 7)) {
/* Save time/memory when chain isn't specified */
if (strchr(mode, 'r') || strchr(mode, '+')) {
mode_rw |= PHP_STREAM_FILTER_READ;
}
if (strchr(mode, 'w') || strchr(mode, '+') || strchr(mode, 'a')) {
mode_rw |= PHP_STREAM_FILTER_WRITE;
}
pathdup = estrndup(path + 6, strlen(path + 6));
p = strstr(pathdup, "/resource=");
if (!p) {
zend_throw_error(NULL, "No URL resource specified");
efree(pathdup);
return NULL;
}
if (!(stream = php_stream_open_wrapper(p + 10, mode, options, opened_path))) {
efree(pathdup);
return NULL;
}
*p = '\0';
p = php_strtok_r(pathdup + 1, "/", &token);
while (p) {
if (!strncasecmp(p, "read=", 5)) {
php_stream_apply_filter_list(stream, p + 5, 1, 0);
} else if (!strncasecmp(p, "write=", 6)) {
php_stream_apply_filter_list(stream, p + 6, 0, 1);
} else {
php_stream_apply_filter_list(stream, p, mode_rw & PHP_STREAM_FILTER_READ, mode_rw & PHP_STREAM_FILTER_WRITE);
}
p = php_strtok_r(NULL, "/", &token);
}
efree(pathdup);
if (EG(exception)) {
php_stream_close(stream);
return NULL;
}
return stream;
} else {
/* invalid php://thingy */
php_error_docref(NULL, E_WARNING, "Invalid php:// URL specified");
return NULL;
}
...
return stream;
}
我們先來測驗一下它的邏輯叭,我們設定變數 a 為 a/…/a.txt,那么就相當于我們 include 了一個 php://filter/resource=a/…/a.txt,在 filter 的判斷斷個點,逐步調過去:
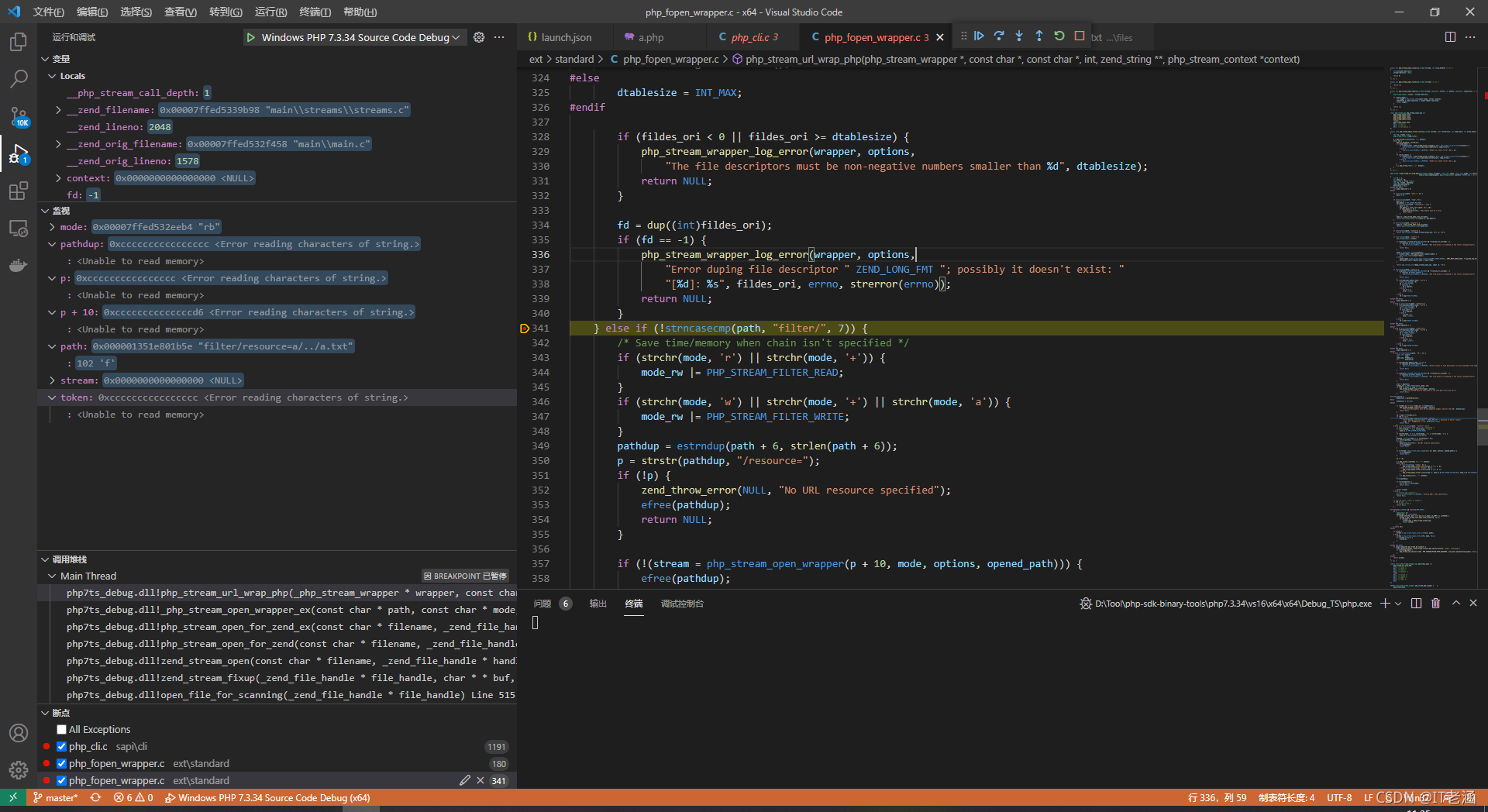
首先是判斷讀或寫,這里不用管,繼續往下看,
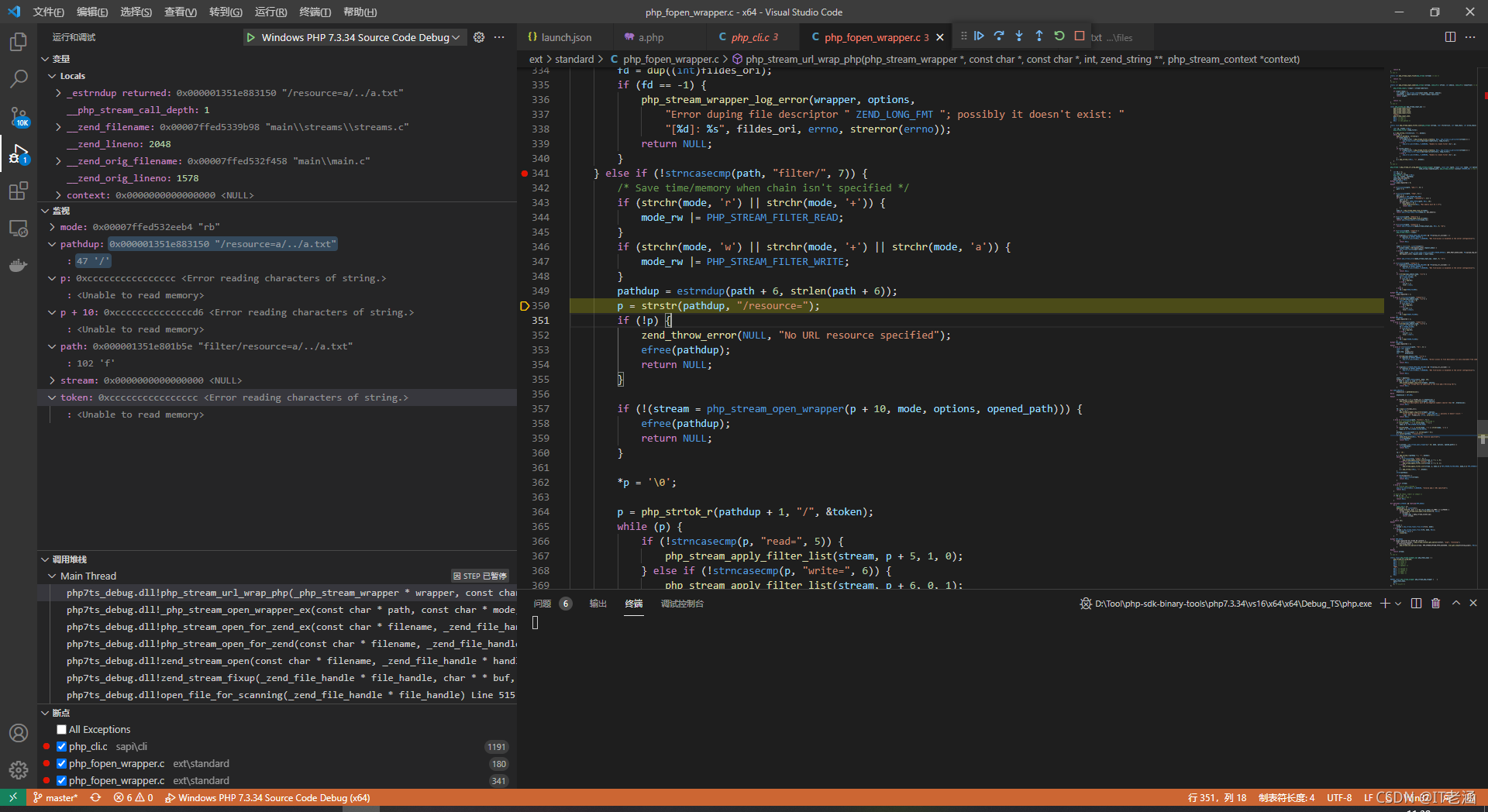
這里有兩個字串的操作,并分別賦值給了 pathdup 和 p,對了,path 最開始是我們傳入 include 的值,也就是 php://filter/resource=a/…/a.txt,在前面有一個 php:// 是否存在的判斷,如果存在則將 path 的指標向后移 6 位,這里再將 path 指標向后移 6 位的地址給 pathdup,也就是將 filter 之后一位的地址賦給 pathdup,而 p 則是用 strstr 函式來獲取到第一個 /resource= 的地址,然后會判斷 p 是否被賦值,如果沒有的話就報錯,有的話就繼續往下走,
接下來是第一個關鍵點,這里呼叫了 php_stream_open_wrapper 來判斷檔案是否存在,它這里對于檔案的判斷是將 p 指標向后移動 10 位,也就是取 /resource= 之后的那一段,也就是我們這里的 a/…/a.txt,雖然我們沒有創建 a 這個檔案夾,但是可以目錄穿越直接穿回來,所以這里已經把檔案讀取出來將流賦給了 stream 變數,
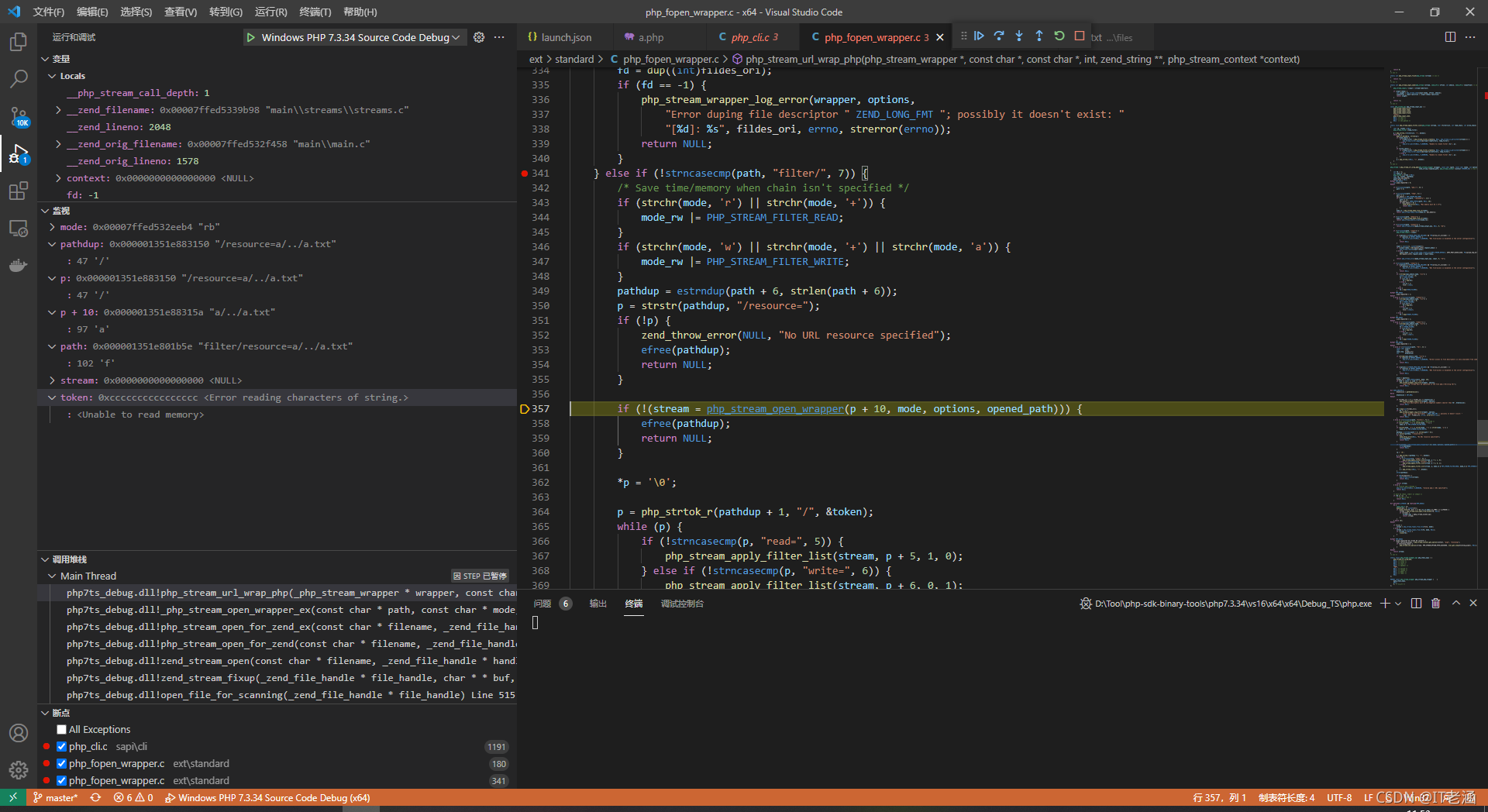
然后 *p = ‘0’ 將 p 清空,就到了最有意思的一段了,也是第二個關鍵點,
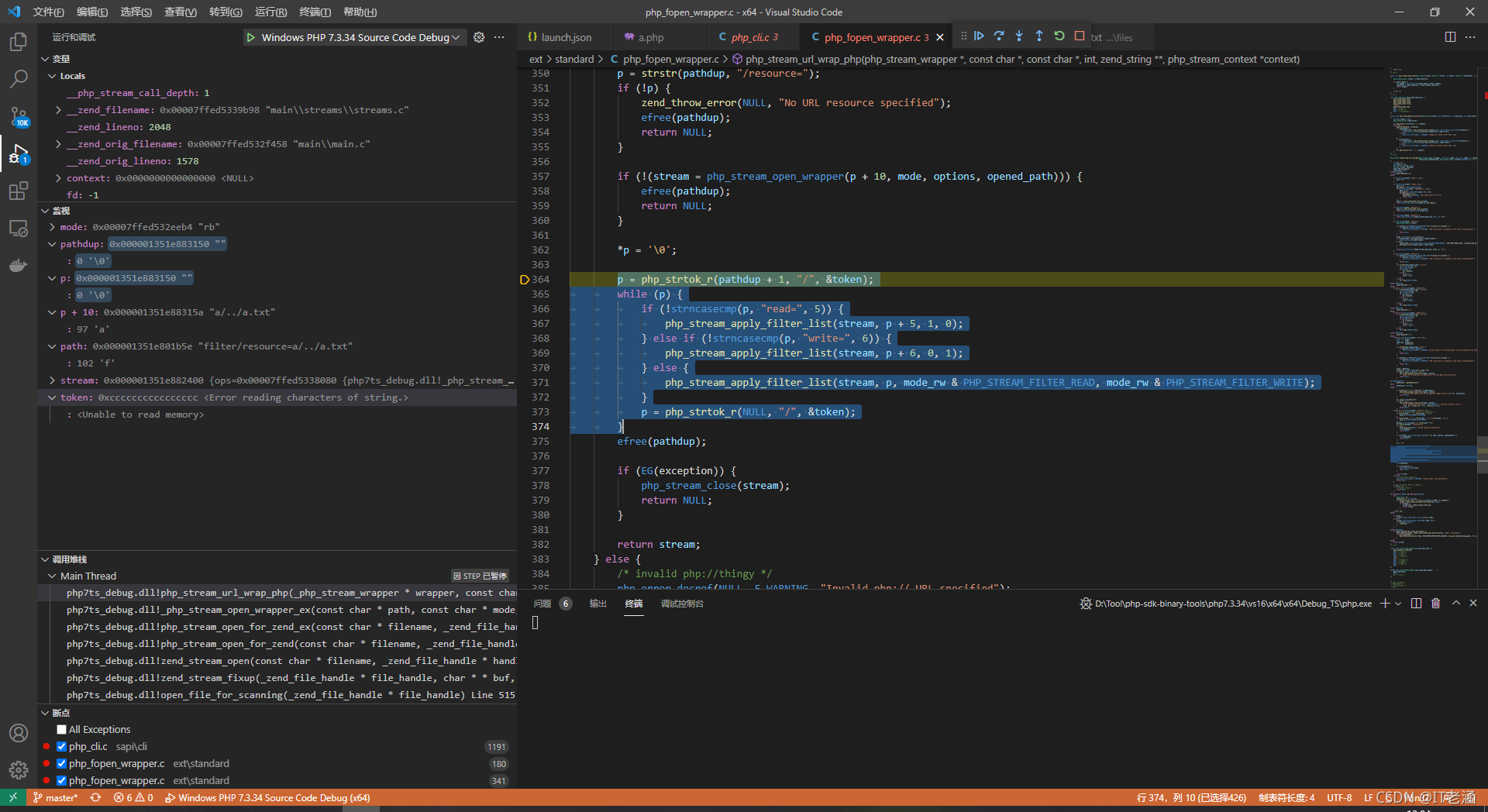
大概講一下這里的意思叭,它會把 pathdup 指標向后移動一位之后的字串以 / 作為分割,每個被分割的部分都會被丟入 php_stream_apply_filter_list 函式中進行判斷,也就是說,這里我們本來 pathdup 是 /resource=a/…/a.txt,會被分割為 resource=a & … & a.txt,每個都會被丟入 php_stream_apply_filter_list 中,那么這個函式是干什么的呢,我們可以跟進一下:
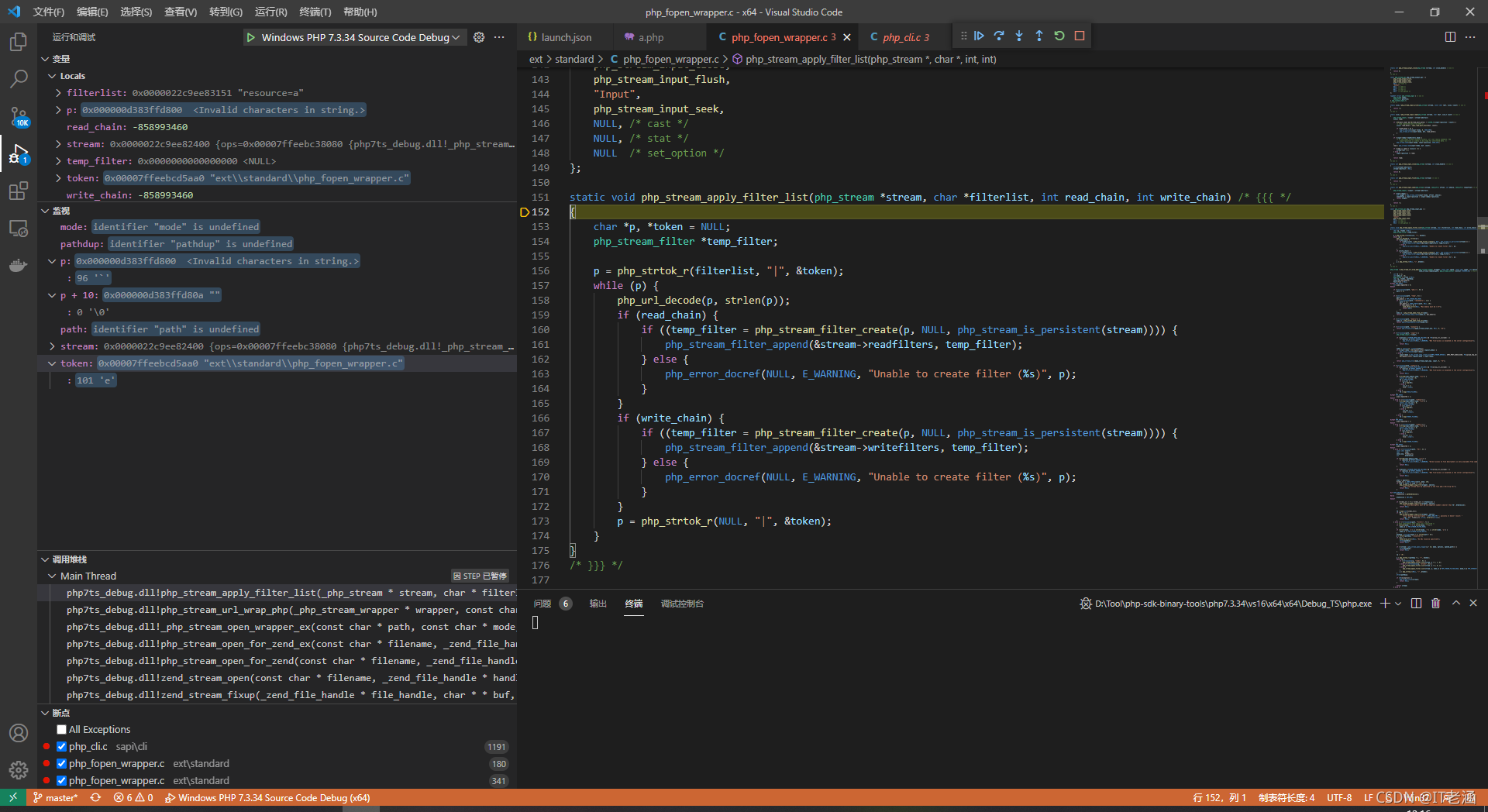
我們把中間最重要的一段單獨提出來:
if (read_chain) {
if ((temp_filter = php_stream_filter_create(p, NULL, php_stream_is_persistent(stream)))) {
php_stream_filter_append(&stream->readfilters, temp_filter);
} else {
php_error_docref(NULL, E_WARNING, "Unable to create filter (%s)", p);
}
}
不難發現,它會嘗試以這個字串為過濾器名去創建這個過濾器,如果創建成功,則會對我們之前讀取的檔案流進行過濾器的相關操作,而如果不存在的話,則會彈一個警告:
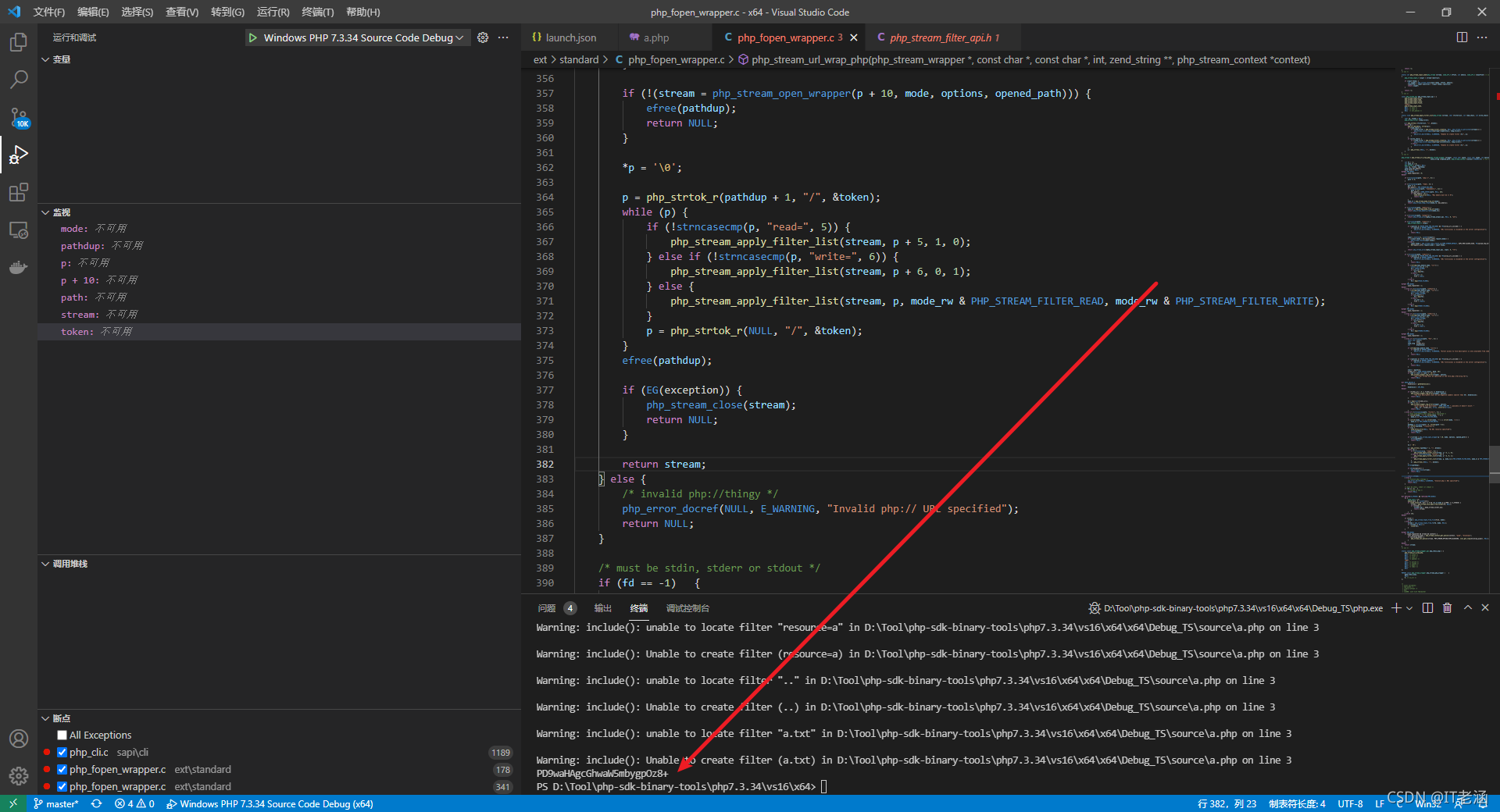
所以到這里我們也就理解了它的搞法,不難構造出 php://filter/resource=a/convert.base64-decode/…/…/a.txt:
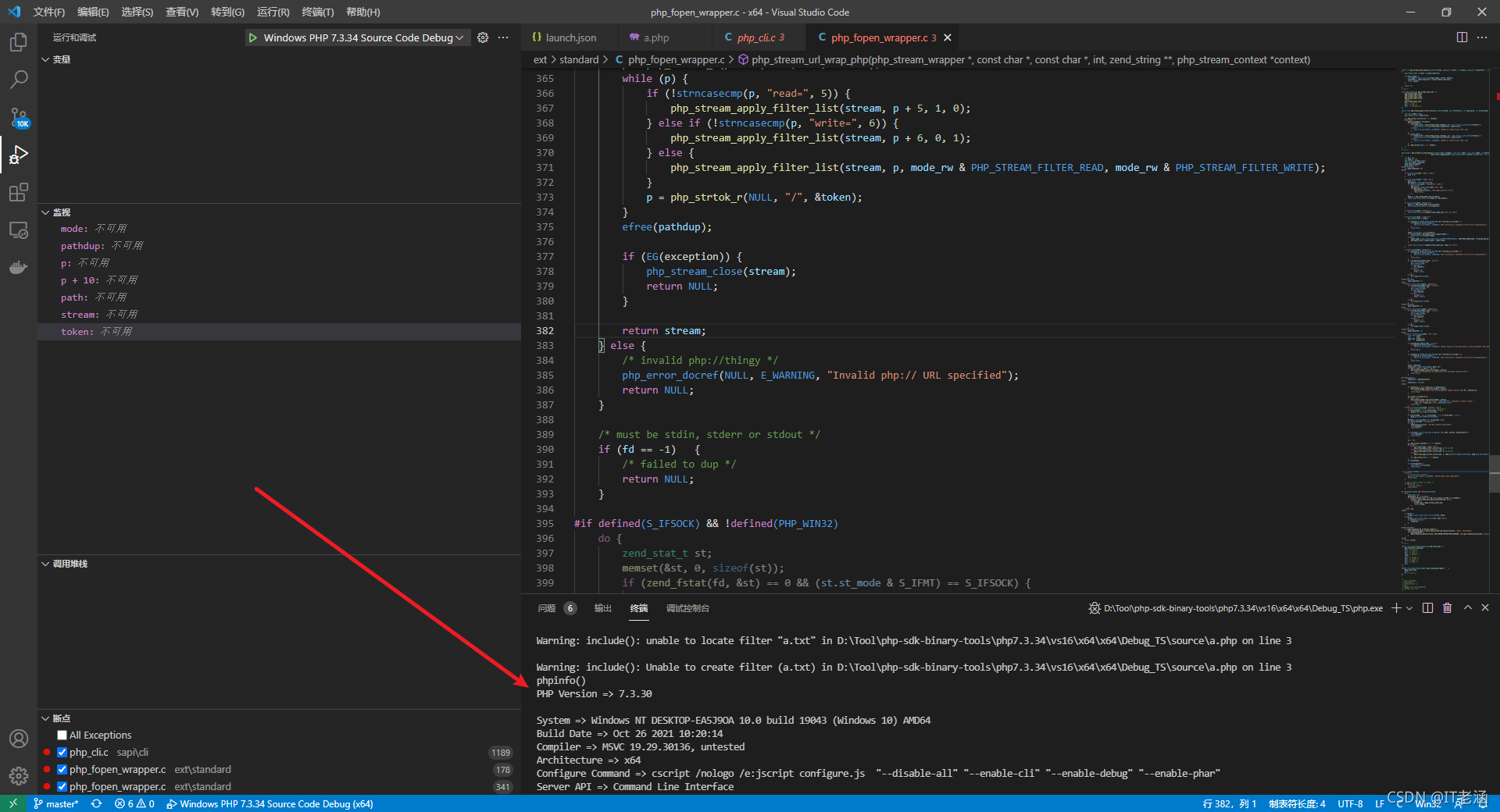
不局限于 base64 編碼,也可以嘗試些別的,
PS:先前測的時候發現似乎從 5.x 到 8.x 都是這樣的……
參考文獻
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/347061.html
標籤:其他
下一篇:Linux中磁盤磁區清理方法