前言
語意分割的目標是輸入影像的每個像素分配一個標簽,即像素級別的物體分類任務;主要是通過演算法模型對輸入影像的像素進行預測并分類,生成語意標簽,如下圖所示,

其中一張場景影像及該場景對應的語意分割標簽影像,道路所屬的所有像素區域都被標注為紫色,即道路類,
隨著語意分割技術的不斷發展與進步,它可以廣泛地應用于人臉分割、醫學影像處理和自動駕駛領域的感知應用,在醫學影像處理領域中,利用語意分割技術實作病灶點分割、癌細胞分割等功能是目前研究的熱點方向,在智能車場景下,語意分割技術應用更為廣泛,通常將相機放置于智能車的前方,語意分割技術通過對可行駛區域、行人、車輛等目標進行精準分析,為實作車輛周圍環境資訊感知提供可能,
目錄
一、國內外研究現狀
1.1 通用語意分割
1.2 實時語意分割
二、語意分割技識訓礎
2.1 編碼器技術
2.2 解碼器技術
2.3 多尺度特征融合
三、語意分割評價標準
四、自動駕駛——語意分割相關資料集
參考文獻
一、國內外研究現狀
1.1 通用語意分割
FCN:Fully Convolution Network(FCN),也稱全卷積網路,2014年,作為語意分割在深度學習領域的開山之作,它第一次將語意分割任務分解成編碼器、解碼器兩大部分;
特點:它將影像分類網絡的最后一層全連接層替換為一系列反卷積層,使得經過下采樣的特征圖層可以通過反卷積層上采樣恢復回輸入影像解析度,從而完成像素級別的物體分類任務,自此,語意分割網路的基本結構大都沿用FCN采用的編碼器-解碼器(Encoder-Decoder)的結構,
模型思路:該方法將 VGG 基本分類網路作為編碼器,將輸入的圖片經過編碼器中的多個卷積層來進行特征提取和下采樣操作之后,其解析度降低為原始輸入圖片的 1/32 從而得到編碼 器輸出特征圖,然后在解碼器階段通過上采樣演算法將所得到的特征圖恢復到原始圖片大 小,得到分割結果,
FCN 對細節資訊的不足導致類別之間的邊界輪廓等分割不明顯,整體網路對小目標物體的分割效果不佳,同時類別之間的背景關系關系并沒有很好地捕獲,導致各個類別之間容易產生混淆,
UNet:隨后Olaf Ronneberger 等人提出的UNet,在編碼器和解碼器之間,通過采用跳躍連接將編碼器獲取的低級特征資訊(Low-level,表征影像的紋理、色彩、明暗、輪廓等資訊)和解碼器獲取的高級特征資訊(High-level,富含語音資訊、表征物體類別的資訊)進行拼接,從而彌補了由于快速下采樣而導致的影像邊緣細節資訊丟失的問題,
U-net 網路在定位準確性和獲取背景關系資訊中需要權衡,影響了模型的效果,同時,U-net 網路在分割的程序中存在很多以像素為中 心的重疊區域,導致計算量大,冗余計算多,
SegNet:2015 年,Badrinarayanan 等人在 FCN 的基礎上提出面向城市道路環境的語意分割模型 SegNet,它將反卷積替換為反池化層,利用編碼器階段帶索引的池化資訊去恢復特征圖,
特點:池化層記錄像素點的空間位置,為解碼器能夠快速有效地找回對應的位置提供便利,從而快速有效地找回位置實作精準的上采樣,
模型結構:
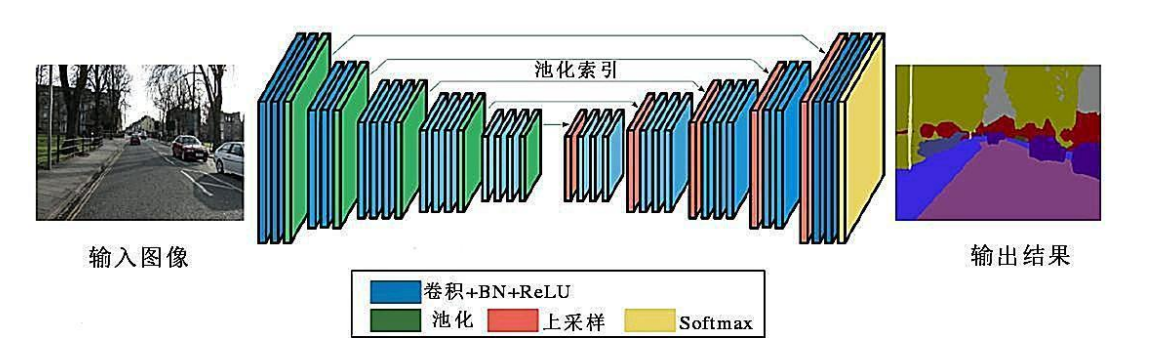
但是由于 SegNet 對特征資訊并沒有很好地融合,物體邊界輪廓的分割效果較差,
RefineNet:為了更好地融合特征,2017 年 Lin 等人提出了 RefineNet 網路模型,該模型的主要思想是將不同解析度的特征圖以特定的方式進行融合,使用這種融合方式主要是為 了解決小目標物體的分割精度低的問題,
由于這樣的融合操作使得整體網路結構 較復雜,不免會有引數量大的缺點,
DeepLab V1:提出的膨脹卷積(空洞卷積)在不增加模型復雜的的情況下增大了模型的感受野,并在最終的分類階段結合條件隨機場(Conditional Random Field,CRF)來修正分割結果,
空洞卷積結構應用于語意分割領域最具有代表性的作業是由谷歌公司提出的 DeepLab 系列模型,2014 年提出的 DeepLab v1 模型使用不同采樣率的空洞卷積來聚 合不同尺度的感受野從而解決多尺度目標的分割問題,為了得到更加精細的結果,在后 處理環節使用了條件隨機場演算法,同時,在論文中也引入了多尺度訓練的技巧,為之后 的方法提高語意分割精度提供了參考,
DeepLab V2 :在DeepLab V1基礎上通過編碼器和解碼器中加入ASPP(Atrous Spatial Pyramid Pooling)模塊,使得網路可以提取不同大小特征圖的資訊進而增加感受野,從而提升分割表現,
2017 年,Chen 通過改進 DeepLab v1 模型提出了 DeepLab v2 模型,模型中通過帶空洞卷積的空間池化金字塔 ASPP(Atrous Sptial Pyramid Pooling)結構進一步聚合不 同尺度的感受野并捕捉影像的背景關系資訊,同樣地,同年所提出的 DeepLab v3 模型通過將全域平均池化和 1 *1卷積引入到 ASPP 結構中來捕獲全域資訊,但是 DeepLab v3 模型解析度恢復環節較為粗糙,同時由于采用空洞卷積來聚合感受野資訊,這極大的增加了記憶體消耗,
DeepLab 的 v3+:為改進 DeepLab v3 網路模型的缺點,2018 年 DeepLab 的 v3+網路模型被提出, 新版本的網路結構以改進版的 Xception作為基礎網路,并在 DeepLab v3 的基礎上加 入解碼器,在解碼器中直接將編碼器的輸出上采樣4倍,使其解析度和低層特征圖一致, 對物體邊緣資訊有很好的保留,
模型結構:
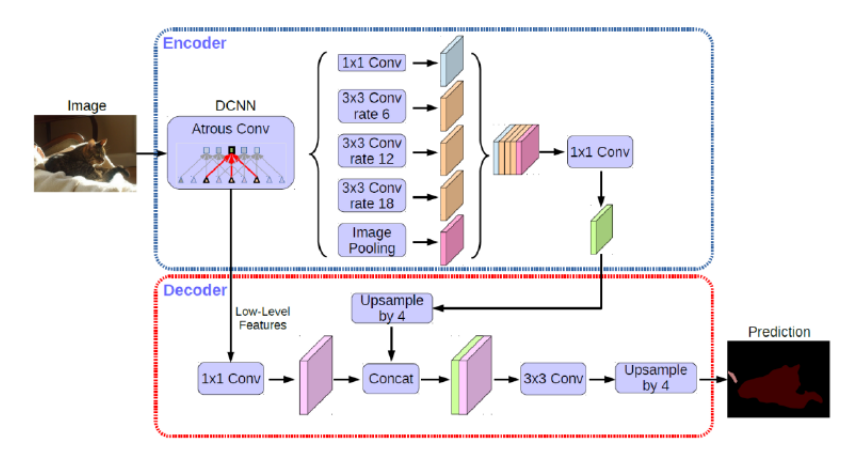
PSPNet:通過“不同尺寸的池化層”并利用“金字塔池化結構”更好地提取區域背景關系資訊和全域資訊從而達到良好地分割變現,
2017 年 Zhao 等人提出的 PSPNet 網路通過 使用不同內核大小的池化層完成多尺度資訊的融合,并使用全域池化層為整個網路提供 相應的全域資訊,有利于細節資訊的把握,另外,網路中加入了額外的深度監督損失,
1.2 實時語意分割
傳統語意分割將研究重點定位于提高模型的分割表和評價指標,而不考慮摸型的計算效率,因此不利于模型被部署于自動駕駛、盲人視覺輔助等實時性要求極高的環境感知應用,
實時語意分割對比非實時語意分割,如下圖所示:
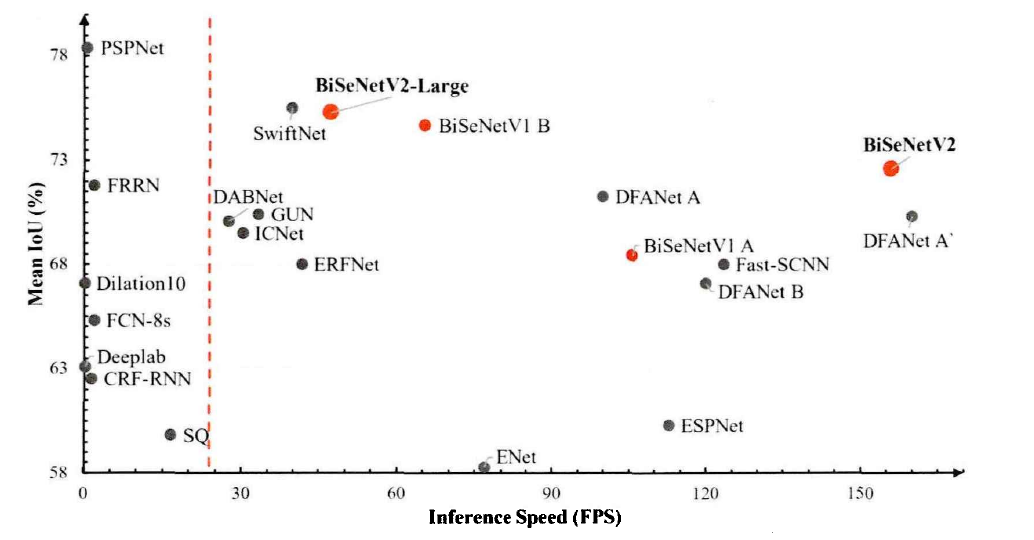
紅色虛線右側代表實時語意分割模型,橫坐標代表每秒的運算幀數,縱坐標代表模型在Cityscape測驗集上的表現指標,實時語意分割隨著ENet 的問世而得到了廣泛研究,
實時語意分割研究方案主要分為三類:
1)設計輕量化模塊結構,如DUpsampling模塊、ERF-PSPNet采用的殘差分解卷積模塊等;
2)設計新型網路設計范式,如ICNet 和 BiSeNet采用的多支路進行資訊補充的結構、將超解析度演算法引入指導低解析度影像語意分割的方式、利用知識蒸餾指導實時語意分割網路的訓練等;
3)采用輕量級基礎網路提取低級特征資訊,如SwiftNet和DFANet等,
ENet:采用殘差網路結構和輕量的模塊設計提高了模型的計算效率,ERFNet 和 ERF-PSPNet 利用殘差分解卷積模塊在保證良好特征抽取能力的基礎上進一步減少計算引數從而提升計算效率,此外,基于資料的上采樣池化模塊(DUpsampling)使得模型可以在更小的特征圖上恢復資訊,進而可以在低解析度特征圖上獲取資訊,從而減少運算量,
ICNet 和 BiSeNet:為了讓實時語意分割的輸出結果在兼具運算效率的同時具有更加精細的空間細節,學界對ICNet和BiSeNet這類多支路網路結構進行了大量研究,它們的具體思路是將網路結構分成兩條支路,其中一條深層網路支路用來處理低解析度的影像,去提取出影像的語意資訊從而減少計算量;另一條淺層網路支路用來處理高解析度影像,去獲取低級的空間分布特征資訊從而修正語意資訊的空間精細程度,最終融合層將各支路資訊通過相關模塊進行特征融合,這類網路在輸出精細程度、語意資訊提取能力和計算效率上進行了良好的平衡,
2018 年,Yu 等人提出了 BiSeNet(Bilateral Segmentation Network)將語意分割 任務分為兩大路徑:空間路徑和背景關系路徑,其中空間路徑主要用于解決空間資訊的缺 失,而背景關系路徑則用于解決感受野縮小的問題,BiSeNet 主要用于實時語意分割,在 精度和速度上力求兼顧,
超分辨演算法:Wang等人將超分辨演算法和語意分割演算法相結合去提升計算效率,其通過共享編碼器的方式有效地提取低解析度影像的低級特征資訊,再利用超分辨演算法支路在模型訓練程序中修正語意分割網路的輸出精細程度,并在最終的前向傳播程序中將超分辨支路去除從而可以使得語意分割模型在低解析度影像上完成特征提取和整合,
輕量級特征提取網路:此外,一系列以輕量級特征提取網路為基礎網路的實時語意分割模型被廣泛提出并投入應用,SwiftNet采用ResNet-18為基礎網路并結合U-Shape型編碼器-解碼器結構達到了良好的分割表現;DFANet采用改良的Xception網路作為基礎網路,并讓特征圖多次經過該特征提取網路進而得到不同解析度下的特征圖從而進一步提取有效的語意資訊,
2019 年,越來越多的研究者在考慮語意分割任務的實時性與精度的兼顧,例如,曠視科技提出的 DFANet(Deep Feature Aggregation Network) 就通過所設計的級聯子網 和級聯子階段來聚合相應的特征,同時具有實時性和準確性,
二、語意分割技識訓礎
語意分割的本質是像素級別的物體分類任務,其基本結構可以被概括為編碼器-解碼器結構(Encoder-Decoder),輸入影像經過“編碼”階段提取出顏色、紋理、邊緣等低級特征,再經過“解碼”階段將獲取的低級特征資訊進行加工獲取富含語意資訊和物體分類相關的高級特征資訊,然后通過相關上采樣技術將下采樣后的特征圖上采樣回原始輸入影像解析度,最終經過分類層完成像素級別的物體分類任務,
2.1 編碼器技術
編碼器主要的技術手段是利用卷積操作去提取影像中含有的低級特征資訊,這類低級特征資訊往往含有與物體相關的邊緣資訊、顏色資訊和紋理資訊等等,
通常在“編碼”階段,模型需要采用池化層或者帶有跨步操作的卷積層進行下采樣,從而減少模型的計算量,提高模型的運算效率,
普通的卷積操作如下圖所示,當輸入張量的維度為H*W*M時,H代表張量行數,W代表張量列數,M代表張量的通道數;
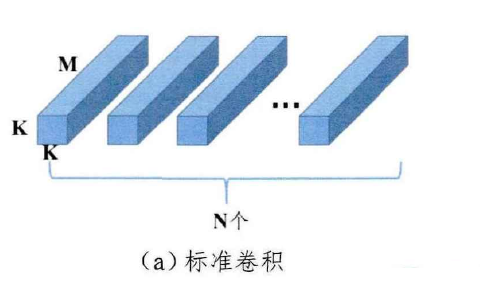
若輸出張量的通道數為N,則一個標準卷積需要N個通道數為M的卷積核去與輸入張量做點運算(假設卷積核大小為K*K),因此,其引數量可以表示為:
Number of Parameter = K * K * M * N
解釋:普通卷積中,卷積核行列是K * K;輸入張量通道數為M,所以卷積核的通道數也為M;輸出張量的通道數為N,所以需要N個卷積核,即:K * K * M * N
深度可分離卷積,能減少標準卷積的引數量,提升模型的運算效率,深度可分離卷積核如下圖所示,它的每一個卷積核只負責輸入張量的一個通道,
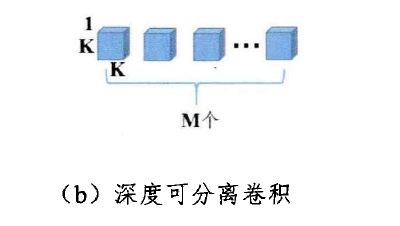
因此,深度可以分離卷積的卷積核數等于輸入張量的通道數,輸出張量的通道數和輸入張量的通道數一致,
但深度可分離卷積缺乏各個不同通道之間特征資訊的互動,為了進一步增加跨通道資訊,深度可分離卷積之后往往需要增加下圖所示的卷積核大小為1*1的普通卷積(逐點卷積),由此可以得到跨通道互動的特征資訊,
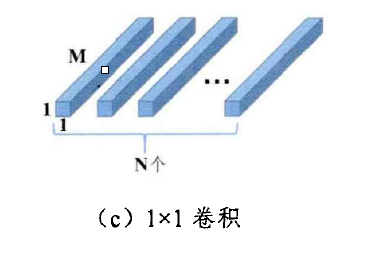
最終在達到相同感受野及相同大小輸出張量時,深度可分離卷積和逐點卷積可將普通卷積的引數數量減少為:
Number of Parameter = K * K *1 * M + 1 * 1 *M * N
因此,深度可分離卷積和逐點卷積的結合可以在相同感受野和通道寄到胡的情況下大大減少普通卷積的引數量,從而有助于模型的輕量化與移動端設備的部署,
空洞卷積,Dilated Convocation,也被譯作膨脹卷積、帶孔卷積、擴張卷積,隨著模型對感受野需求的增大被引入到模型設計中,它可以在保持模型引數量不變的情況下,增大模型的感受野進而跟更好提取特征圖中的背景關系資訊,從而提高模型對有效特征的選擇和利用,
空洞卷積相當于通過對普通卷積核本身進行補零,然后在輸入特征圖的兩個維度上進行卷積運算的方法增加感受野,普通卷積就相當于膨脹率為1時的空洞卷積,
如下圖所示,其中a圖代表核大小為3*3的普通卷積核;b圖代表膨脹率為2,核大小為3*3的空洞卷積核(通過對普通卷積核進行間隔補零),

它們具有明顯的感受野差異,同樣為3*3大小的卷積核,普通卷積核的感受野為3*3,而膨脹率為2的空洞卷積的感受野為7*7,
除了上述卷積操作外,還有可變形卷積、空間變換卷積模型等等特殊的卷積操作,它們可以提取出與輸入物體空間分布相關的特征,池化層是在“編碼”階段下采樣的另一種常用操作,它不需要任何訓練引數即可以較好地保留特征,池化層主要分為平均池化層核最大池化層,平均池化層在對應池化核中平均相應區域的特征值,而最大池化層在對應池化核保留該區域內特征圖的最大值,
2.2 解碼器技術
語意分割解碼器階段主要的任務是將經過編碼器階段的下采樣后的低級特征資訊進行處理,進而提取富含語意資訊的高級特征資訊,并通過相關技術將其解析度恢復為輸入影像的解析度大小,
其主要核心技術目標是解決上采樣問題,語意分割的上采樣技術主要包括插值、反卷積和反池化操作,
插值:插值操作是語意分割常見的技術方案,主要包括最近鄰插值、雙線性插值和雙立方插值,為了保證特征圖的連續性和良好的計算效率,雙線性插值是常用的方法,
反池化:反池化是池化操作的反向操作,可以在不引入額外引數的情況下實作特征圖尺寸的恢復,SegNet是第一個運用反池化技術的語意分割模型,反池化程序如下圖所示,
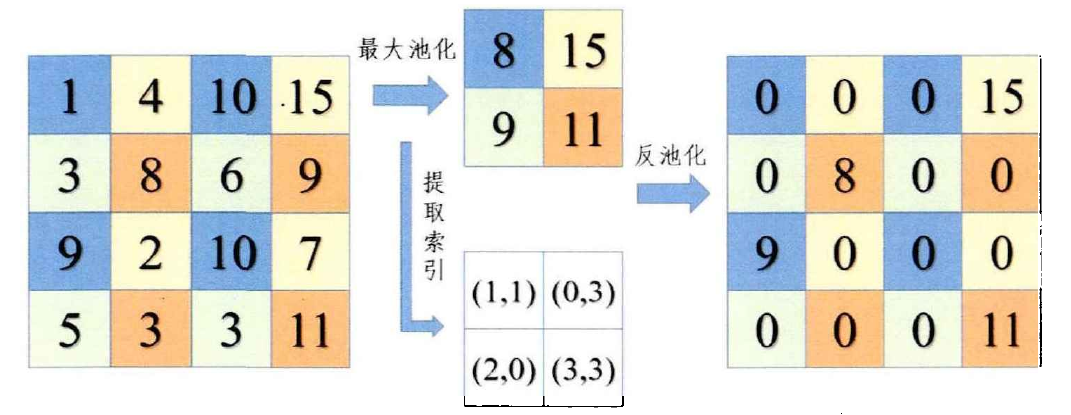
“編碼”階段利用最大池化層獲取降采樣特征圖,同時保留了相應的位置索引資訊;“解碼”階段利用該索引資訊將特征圖的資訊和解析度進行恢復,
反卷積:又稱為轉置卷積,最早由FCN使用而被廣泛運用在語意分割模型中,反卷積并不是卷積運算的逆運算,相反它是一種特殊的卷積運算,它先按照一定的比例通過對特征圖補零來擴大輸入特征圖的尺寸,接著再利用和普通卷積一樣的運算程序進行正向卷積,
如下圖所示,3*3特征圖經過3*3卷積核大小,步長為1的反卷積程序,其中,橙色區域代表輸入3*3特征圖;灰色區域代表卷積操作的區域;藍色區域代表經過反卷積之后的5*5特征圖,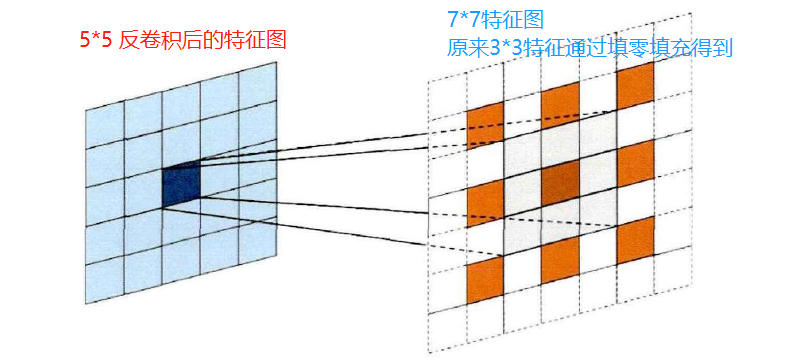
首先通過對輸入解析度為3*3的特征圖進行補零,獲取7*7的特征圖(虛框區域),再經過一個3*3卷積核進行普通卷積運算即可得到5*5的特征圖,
影像經過“編碼”和“解碼”階段特征重構后,模型的最后階段將利用一個輸出通道數為類別數的普通卷積操作進行特征選取以完成語意分割,
2.3 多尺度特征融合
隨著模型深度的不斷加大,與輸入影像輪廓特征有關的資訊會逐層丟失,傳統的語意分割模型在“編碼”層和“解碼”層之間通過直接相連的方式進行特征圖和資訊的傳遞,因此在“編碼”階段,特征圖各個位置均以相同的感受野獲取輸入影像的資訊,但是對于尺寸、體積大小不同的物體,感受野需求往往是不一樣的,
例如,汽車和房屋需要相對較大的感受野獲取足夠的語意資訊完成物體的識別,而人以及其他小物體所需的感受野相對較小,完全一致的單一感受野難以適應真實場景下各類物體大小不同的分割問題,于是多尺度特征融合得到了廣泛研究和采用,
多尺度特征融合,它主要解決的問題是對“編碼”階段獲取的低級特征進行相關操作獲取不同尺度下的特征,然后進行多尺度特征融合使得“編碼”可以獲取不同感受野大小的特征,
多尺度特征融合一般分為兩種型別,影像金字塔和特征金字塔模式,影像金字塔模型在傳統資料影像處理中得到了廣泛的應用,如下圖所示:
影像金字塔:在語意分割領域,多支路結構是典型的影像金字塔模型,如ICNet、BiSeNet等,這類模型在不同模塊或處理支路中輸入不同解析度大小的影像,通過對不同解析度大小影像的處理提取出不同感受野下的特征,最終將特征進行融合以補充輸出結果中缺失的空間輪廓細節資訊,
影像金字塔充分利用了多尺度影像的各類資訊,模仿人眼觀察不同大小解析度影像獲取資訊的方式,較好地補充了多尺度資訊,但是,影像金字塔并行的網路結構使得模型的記憶體消耗較大,
特征金字塔:它解決了影像金字塔記憶體消耗較大的問題,主要思路是利用不同解析度大小的特征圖進行融合,獲取不同感受野大小的特征,帶有跳躍連接的U-Shape型網路是典型的利用不同層特征圖資訊的結構,在語意分割領域得到廣泛應用的特征金字塔模型,包括金字塔池化模型(Pyramid Pooling Module,PPN)和空洞空間金字塔池化模塊(Atrous Spatial Pyramid Pooling,ASPP)等,
金字塔池化模型最早由H Zhao等人提出的PSPNet使用,如下圖所示,“編碼器”獲取的特征首先利用自適應池化獲取不同解析度的特征圖,然后用一系列1*1卷積對獲取的特征圖處理獲取新特征,再用雙線性插值將新特征圖恢復為初始解析度,最終將特征值通過堆疊的方式進行特征融合從而完成了對不同感覺野特征的融合,
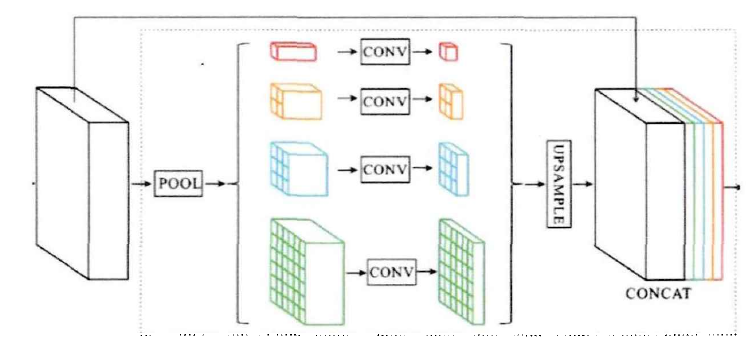
ASPP模型采用相似的方式,利用不同膨脹率的空洞卷積對特征圖進行操作獲取不同感覺野大小的特征圖,然后將各特征圖進行通道堆疊,
三、語意分割評價標準
語意分割演算法的評價指標主要包括執行時間、記憶體占用、準確度三部分,
其中執行時間和記憶體占用反映的是演算法模型的運行速度和引數量,而準確度主要分為像素精度和交并比 IoU 兩大類,
模型運行速度主要由每秒幀數 fps(frames per second)和浮點運算元體現,
模型引數量代表模型的引數規模,通常模型生成的權重是用模型體積來衡 量占用空間大小的,由于深度學習模型的引數一般是單精度浮點型(32 位浮點型),每個引數占用 4B,因此模型的體積大約為引數量的 4 倍,
四、自動駕駛——語意分割相關資料集
面向自動駕駛場景下的語意分割任務,由于非結構化場景的復雜性,是一個非常具有 挑戰性的任務,所以有許多研究者和研究機構公開了很多相關的資料集推動語意分割領域的發展,這些資料集通過使用多個攝像頭采集圖片資料,并影像上進行精細的標注形成準確的標簽值,
在本文中選用了常用的 Cityscapes 資料集和 CamVid 資料集,下面是 這兩個資料集的簡介:
(1)Cityscapes 資料集
Cityscapes 資料集上專門針對城市街道場景的資料集,整個資料集由 50 個不同 城市的街景組成,資料集包括了 5000 張精準標注的圖片和 20000 張粗略標注的圖片,
其中精準標注的圖片主要用于強監督學習,可分為訓練集、驗證集和測驗集,而粗略標 注的圖片主要用于弱監督語意分割演算法的訓練與測驗,在 Cityscapes 資料集中通常使用 19 種常用的類別用于類別分割精度的評估,
(2)CamVid 資料集
CamVid 資料集是由劍橋大學公開發布的城市道路場景的資料集,資料集包 括 700 多張精準標注的圖片用于強監督學習,可分為訓練集、驗證集、測驗集,同時, 在 CamVid 資料集中通常使用 11 種常用的類別來進行分割精度的評估,分別為:道路 (Road)、交通標志(Symbol)、汽車(Car)、天空(Sky)、行人道(Sidewalk)、電線桿 (Pole)、圍墻(Fence)、行人(Pedestrian)、建筑物(Building)、自行車(Bicyclist)、 樹木(Tree),
參考文獻
[1] 項凱特.面向交通場景感知的語意分割技術研究[D].浙江大學,2021
[2] 向石方.面向智能車場景的語意分割演算法研究[D].華南理工大學,2020
本文直供大家參考和學習,謝謝,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/347074.html
標籤:其他