Github下載鏈接:https://github.com/Unity-Technologies/ml-agents
參考視頻:年輕人的第一個游戲AI:Unity強化學習工具MLAgents全流程實體教程、unity人工智能工具mlagents最新版教程
ML-Agents是游戲引擎Unity3D中的一個插件,也就是說,這個軟體的主業是用來開發游戲的,實際上,它也是市面上用得最多的游戲引擎之一,而在幾年前隨著人工智能的興起,強化學習演算法的不斷改進,使得越來越多的強化學習環境被開發出來,例如總所周知的OpenAI的Gym,同時還有許多實驗室都采用的星際爭霸2環境來進行多智能體強化學習的研究,那么,我們自然想到,可不可以開發屬于自己的強化學習環境來實作自己的演算法,實際上,作為一款備受歡迎的游戲引擎,Unity3D很早就有了這么一個想法,
詳情見論文:Unity: A General Platform for Intelligent Agents
作為一個對游戲開發和強化學習都非常感興趣的人,自然也了解到了這款插件,使得能夠自己創造一個獨一無二,與眾不同,又充滿智慧的游戲AI成為可能,
在Github的官方包中有更為詳細的英文指導,如果不想翻譯,也可以跟著我下面的步驟走,
檔案說明
ML-Agents工具包包含幾個部分:
- Unity包com.unity.ml-agents包含了集成到Unity 專案中的 Unity C# SDK,,可以幫助你使用 ML-Agents 的Demo,
- Unity包ml-agents.extensions依賴于com.unity.ml-agents,包含的是實驗性組件,還未成為com.unity.ml-agents的一部分,
- 三個Python包:mlagents包含機器學習演算法可以讓你訓練智能體,大多數ML-Agents的用戶值需要直接安裝這個檔案,mlagents_envs包含了Python的API可以讓其與Unity場景進行互動,這使得Python機器學習演算法和Unity場景間的管理變得便利,mlagents依賴于mlagents_envs,gym_unity提供了Unity場景支持OpenAI Gym介面的封裝,
- Project檔案夾包含了幾個示例環境,展示了ML-Agents的幾個特點,可以幫助你快速上手,
需要的環境
- 安裝高于Unity2019.4的版本
- 安裝高于Python3.6.1的版本
- 克隆Github倉庫(可選)
- 安裝com.unity.ml-agents這個Unity包
- 安裝com.unity.ml-agents.extensions這個Unity包(可選)
- 安裝mlagents這個Python包
環境配置
在正式開始我們的專案之前是比較痛苦的配置環境的環節了,
-
首先通過上面的鏈接從Github上下載ML-Agents的官方包,**切記路徑中不能有中文!**否則無法正常訓練!
-
安裝anaconda,
-
在Anaconda Prompt中創建一個專門用于ML-Agents的Python環境,
# 查看所有環境 conda-env list # 安裝新環境 conda create -n ml-agents python=3.6 # 激活新環境 activete ml-agent -
解壓從Github上下載的檔案,分別cd到ml-agents和ml-agents-envs兩個目錄,執行以下命令安裝兩個包:
pip install . -
執行以下命令看看安裝是否成功
mlagents-learn --help如果安裝不成功,出現Error,那么可能是因為新配的環境沒有裝Pytorch,此時要去官網復制需要版本的pip命令進行安裝,注意在安裝pytorch的時候直接使用官方的命令下載速度極慢(甚至多次中斷),因此我們需要配置清華源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ conda config --set show_channel_urls yes#下載時顯示檔案來源并且在使用官方的命令時去掉結尾的-c pytorch,因為這個指令是強制在官網下載,這樣下載速度會有大幅提升,
-
下一步打開Unity編輯器,創建一個3D工程,點擊windows選單下的Package Manager,點擊左上角的加號,選擇Add package from disk,然后彈出的視窗中打開com.unity.ml-agents中的package.json檔案,即可把包添加到Unity中,com.unity.ml-agents.extensions同理,安裝完之后,就可以在下方檔案中的Packages看到ML-Agents以及ML-Agent Extensions,
小試牛刀
首先把官方包下的Project用Unity編輯器打開,進入到ML-Agents -->Examples目錄下,里面的全部都是ML-Agents各種實作的示例,包含了ML-Agents的主要功能展示,我們打開第一個專案3DBall,點擊場景Scenes中的第一個:

現在可以看到畫面了,這是一個相當簡單的初級專案,我們只需要訓練一個智能體頂著小球不讓它落下即可,
我們打開Anaconda Prompt,切換到我們創建的環境,cd到官方包的目錄,執行命令:
mlagents-learn config/ppo/3DBall.yaml --run-id=3DBallTest --force
這條命令的意思是采用的組態檔是3DBall.yaml,以3DBallTest這個名字來進行訓練,訓練資料也將保存在官方包下results目錄下的同名檔案夾,–force是強制執行,這會覆寫上一次的資料,如果沒有寫–force而存在同名檔案夾,則訓練無法執行,
執行命令后,它會彈出以下界面,然后你可以在Unity中點擊運行了:
如果前面的步驟沒有問題,就可以看到Unity中的畫面是加速運行的,并且控制臺逐漸輸出以下資訊:
[INFO] Connected to Unity environment with package version 2.1.0-exp.1 and communication version 1.5.0
[INFO] Connected new brain: 3DBall?team=0
[INFO] Hyperparameters for behavior name 3DBall:
trainer_type: ppo
hyperparameters:
batch_size: 64
buffer_size: 12000
learning_rate: 0.0003
beta: 0.001
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
beta_schedule: linear
epsilon_schedule: linear
network_settings:
normalize: True
hidden_units: 128
num_layers: 2
vis_encode_type: simple
memory: None
goal_conditioning_type: hyper
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
network_settings:
normalize: False
hidden_units: 128
num_layers: 2
vis_encode_type: simple
memory: None
goal_conditioning_type: hyper
init_path: None
keep_checkpoints: 5
checkpoint_interval: 500000
max_steps: 500000
time_horizon: 1000
summary_freq: 12000
threaded: False
self_play: None
behavioral_cloning: None
[INFO] Listening on port 5004. Start training by pressing the Play button in the Unity Editor.
[INFO] Connected to Unity environment with package version 2.1.0-exp.1 and communication version 1.5.0
[INFO] Connected new brain: 3DBall?team=0
[INFO] 3DBall. Step: 12000. Time Elapsed: 152.628 s. Mean Reward: 1.182. Std of Reward: 0.671. Training.
[INFO] 3DBall. Step: 24000. Time Elapsed: 194.462 s. Mean Reward: 1.430. Std of Reward: 0.893. Training.
當結束Unity的運行時,模型會自動保存到官方包下results下對應的檔案夾,找到onnx后綴的檔案,這是訓練好的神經網路模型,導進專案中后,拖到Behavior Parameters組件的Model引數中,點擊運行就可以查看實際的運行效果啦!
具體實作
首先在布置好環境之后,我們需要在智能體下掛載以下腳本:
為了驅動智能體,我們需要在智能體下掛上Behavior Parameters組件來調節各種引數,然后我們可以在里面設定組件引數:
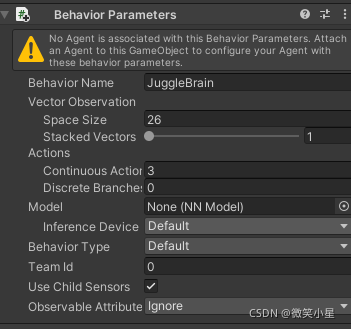
其中我們需要修改的有Space Size,代表輸入的維度,通常位置的輸入是三維的,旋轉涉及四元數所以是四維的,速度和角速度都是三維的,這樣我們就可以根據需要觀察的智能體的引數來計算輸入的維度,Action是輸出,其中的Continuous Action是輸出的連續動作,Descrete Branch是離散動作,我們根據需求填寫數量,
還有一個必要的組件是Decision Requester,這個組件提供了方便快捷的方式觸發智能體決策程序,可以調節采取決策的步數,和不采取決策時是否執行動作,
最后一個必要組件就是需要我們自己寫的Agent腳本了,這個腳本必須繼承Agent類,默認只需要設定MaxStep一個引數,設定為0代表無限,下面詳細講解其中函式的用法,
ML-Agents提供了若干個方法供我們實作,
Initialize方法,初始化環境,獲取組件資訊,設定引數在這里完成,
CollectObservations方法,這個方法會收集當前游戲的各種環境,包括智能體的位置,速度等資訊,ML-Agents會把這些資訊自動生成Tensor,進行計算,這里相當于設定神經網路的輸入,如果是攝像機輸入而不是向量輸入的情況下此函式什么都不用做,
然后是OnActionReceived方法,實作的是整個游戲中一個Step中的操作,接收神經網路的輸出,使其轉換為智能體的動作,設定獎勵函式,并且判斷游戲是否結束,
OnEpisodeBegin方法,每次游戲結束后,重開一輪需要做的處理,比如重置位置資訊等,
如果我們想自己操作智能體,還需要定義一個Heuristic方法,這樣游戲就會采集玩家的輸出資訊,可以學習玩家的思維,大大促進訓練教程,
CollectDiscreteActionMasks方法,在特殊情況下屏蔽某些不需要的AI操作(如地圖邊界阻止),
接下來看看3D小球游戲的智能體代碼:
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;
using Random = UnityEngine.Random;
類的成員變數:
[Header("Specific to Ball3D")]
public GameObject ball;
[Tooltip("Whether to use vector observation. This option should be checked " +
"in 3DBall scene, and unchecked in Visual3DBall scene. ")]
public bool useVecObs;
Rigidbody m_BallRb;
EnvironmentParameters m_ResetParams;
Initialize方法:
public override void Initialize()
{
m_BallRb = ball.GetComponent<Rigidbody>();
m_ResetParams = Academy.Instance.EnvironmentParameters;
SetResetParameters();
}
CollectObservations方法:
public override void CollectObservations(VectorSensor sensor)
{
if (useVecObs)
{
sensor.AddObservation(gameObject.transform.rotation.z);
sensor.AddObservation(gameObject.transform.rotation.x);
sensor.AddObservation(ball.transform.position - gameObject.transform.position);
sensor.AddObservation(m_BallRb.velocity);
}
}
在hard版本的3DBall中,采用了另一種方式代替CollectObservations方法(輸入維度為5,忽略小球速度):
// 標記該變數可觀察,觀察狀態的幀數為9
[Observable(numStackedObservations: 9)]
Vector2 Rotation
{
get
{
return new Vector2(gameObject.transform.rotation.z, gameObject.transform.rotation.x);
}
}
[Observable(numStackedObservations: 9)]
Vector3 PositionDelta
{
get
{
return ball.transform.position - gameObject.transform.position;
}
}
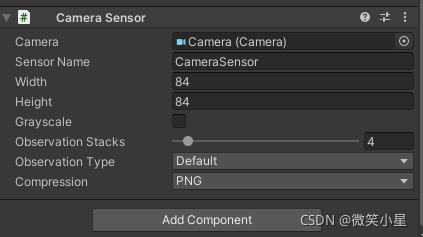
第三種替代CollectObservations是加上相機腳本即Camera Sensor腳本,再把相機的預制體拖入其中,設定好引數,相機自己就會獲取畫面作為輸入,但會大大增加訓練時間,
OnActionReceived方法:
public override void OnActionReceived(ActionBuffers actionBuffers)
{
var actionZ = 2f * Mathf.Clamp(actionBuffers.ContinuousActions[0], -1f, 1f);
var actionX = 2f * Mathf.Clamp(actionBuffers.ContinuousActions[1], -1f, 1f);
if ((gameObject.transform.rotation.z < 0.25f && actionZ > 0f) ||
(gameObject.transform.rotation.z > -0.25f && actionZ < 0f))
{
gameObject.transform.Rotate(new Vector3(0, 0, 1), actionZ);
}
if ((gameObject.transform.rotation.x < 0.25f && actionX > 0f) ||
(gameObject.transform.rotation.x > -0.25f && actionX < 0f))
{
gameObject.transform.Rotate(new Vector3(1, 0, 0), actionX);
}
if ((ball.transform.position.y - gameObject.transform.position.y) < -2f ||
Mathf.Abs(ball.transform.position.x - gameObject.transform.position.x) > 3f ||
Mathf.Abs(ball.transform.position.z - gameObject.transform.position.z) > 3f)
{
SetReward(-1f);
EndEpisode();
}
else
{
SetReward(0.1f);
}
}
OnEpisodeBegin方法:
public override void OnEpisodeBegin()
{
gameObject.transform.rotation = new Quaternion(0f, 0f, 0f, 0f);
gameObject.transform.Rotate(new Vector3(1, 0, 0), Random.Range(-10f, 10f));
gameObject.transform.Rotate(new Vector3(0, 0, 1), Random.Range(-10f, 10f));
m_BallRb.velocity = new Vector3(0f, 0f, 0f);
ball.transform.position = new Vector3(Random.Range(-1.5f, 1.5f), 4f, Random.Range(-1.5f, 1.5f))
+ gameObject.transform.position;
//Reset the parameters when the Agent is reset.
SetResetParameters();
}
Heuristic方法:
public override void Heuristic(in ActionBuffers actionsOut)
{
var continuousActionsOut = actionsOut.ContinuousActions;
continuousActionsOut[0] = -Input.GetAxis("Horizontal");
continuousActionsOut[1] = Input.GetAxis("Vertical");
}
其他方法:
public void SetBall()
{
//Set the attributes of the ball by fetching the information from the academy
m_BallRb.mass = m_ResetParams.GetWithDefault("mass", 1.0f);
var scale = m_ResetParams.GetWithDefault("scale", 1.0f);
ball.transform.localScale = new Vector3(scale, scale, scale);
}
public void SetResetParameters()
{
SetBall();
}
到這里智能體的腳本就寫完了,接下來我們需要設定演算法和引數,進入到config檔案夾下,里面存放著演算法的配置,對于單智能體強化學習,Unity官方提供了兩種演算法,PPO和SAC,這里我們使用PPO演算法,進入PPO檔案夾中,打開3DBall.yaml,通過修改其中的引數就能改變訓練的配置,這需要對相應的強化學習演算法有一定的了解,具體可以參考配置檔案:https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Training-Configuration-File.md
behaviors:
3DBall:
trainer_type: ppo
hyperparameters:
batch_size: 64
buffer_size: 12000
learning_rate: 0.0003
beta: 0.001
epsilon: 0.2
lambd: 0.99
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 500000
time_horizon: 1000
summary_freq: 12000
其中在Behavior Parameters中,Behavior Name中的名字必須要和第二行的那個名字一致,如果想設定不同的智能體使用不同的配置同時進行訓練,只需要在下面加上不同名字的配置,然后再相應的智能體的Behavior Name中使用那個名字即可,
訓練時檔案路徑要寫對:
mlagents-learn config/ppo/3DBall.yaml --run-id=3DBallTest --force
如果想繼續上次的訓練:
mlagents-learn config/ppo/3DBall.yaml --run-id=3DBallTest --rusume
TensorBoard的使用
在上面的控制臺環境下輸入下列命令(訓練程序中可以另外開一個Anaconda Prompt):
tensorboard --logdir .\results\ --port 6006
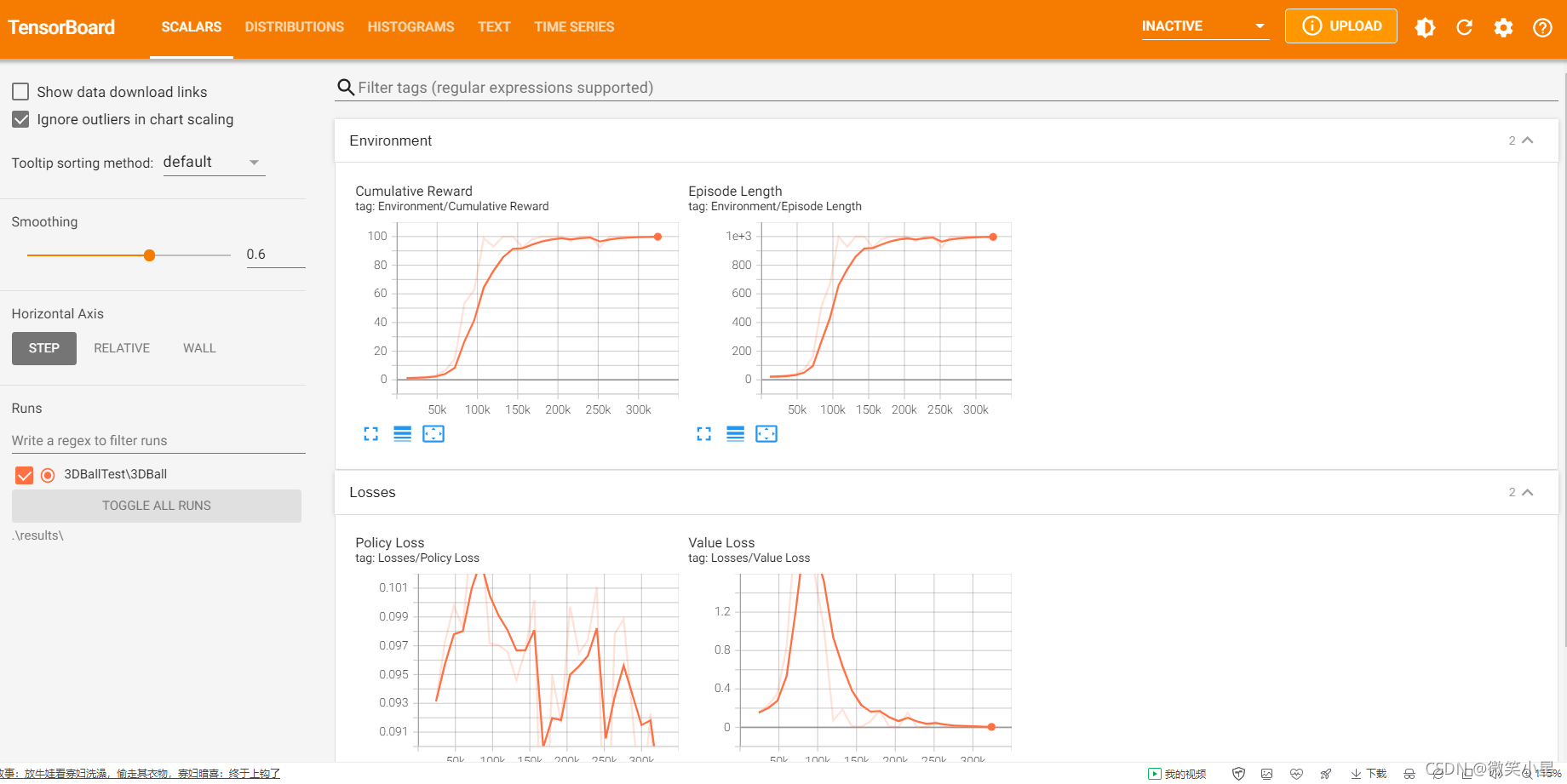
在瀏覽器中的網址欄輸入localhost:6006,就可以看到tensorboard的界面了,這樣就能把資料進行可視化,獎勵和Loss的變化一清二楚,
加速訓練
在編輯器中的訓練是需要消耗非常多性能的,因此我們需要先把它打包成exe檔案,具體操作是File–>Build Settings–>Build,
打包好后,把組態檔yaml檔案也放入檔案夾中,cd到該檔案夾中,輸入以下命令:
mlagents-learn 組態檔名.yaml --run-id=自己隨意起名 --env=執行檔案名.exe --num-envs=9 --force
就可以開啟9個視窗同時訓練,如果不顯示圖形界面可以快一大截,只需在命令后面加上–no-graphics即可,
總結
本文中介紹了Unity插件ML-Agents的安裝和使用方法,并且跑通了ML-Agents的第一個入門級示例,現在算是對ML-Agents的整體框架有了大概的了解,后面還有更加復雜功能的實作,自創環境,自創演算法等著我們去探索,我會另外開文章對每個要點進行詳細的解讀,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/347224.html
標籤:其他
上一篇:ML-Agents命令及配置大全