我有一個來自我的巨大資料幀的示例資料幀,如下所示。
import pandas as pd
import numpy as np
NaN = np.nan
data = {
'ID':['AAQRB','AAQRB','AAQRB',
'AHXSJ','AHXSJ','AHXSJ','GABOY','GABOY','GABOY','GHZGS','GHZGS','GHZGS'],
'Date':['10/18/2021 10:52:53 PM','10/18/2021 10:53:55 PM', '10/25/2021 5:55:43 PM',
'10/22/2021 10:37:06 PM','10/22/2021 10:38:22 PM','10/22/2021 10:39:56 PM',
'11/1/2021 1:27:15 AM','11/1/2021 1:28:45 AM','11/2/2021 8:53:39 PM',
'10/29/2021 11:13:57 PM', '10/29/2021 11:17:47 PM', '10/29/2021 11:19:15 PM'],
'Race_x':[NaN,NaN,NaN,NaN,NaN,1,NaN,NaN,1, NaN,NaN,1],
'Vaccine':['TRUE',NaN,NaN,'TRUE',NaN,NaN,'TRUE',NaN,NaN,'FALSE',NaN,NaN],
'Study_activity':
[NaN,'continue',NaN,NaN,'continue',NaN,NaN,'continue',NaN,NaN,'continue',NaN],
'Who_Contacted':
[NaN,NaN,'WeContacted',NaN,NaN,'WeContacted',NaN,NaN,NaN,NaN,NaN,'WeContacted']}
test_df = pd.DataFrame(data)
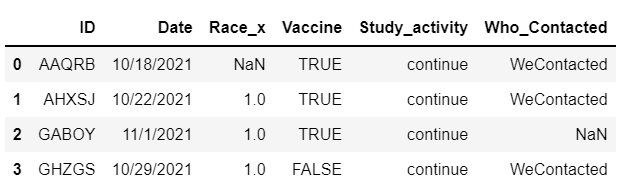
目標是獲取每個 ID 的所有第一個值,并將參與者的幾行過濾為包含所有資訊的一行。最終的資料框應如下圖所示。
代碼嘗試
我嘗試使用 Grouper() 函式,代碼如下。
test_df['Date'] = pd.to_datetime(test_df['Date'])
test_df1 = (test_df.groupby(['ID', pd.Grouper(key='Date', freq='D')])
.agg("first")
.reset_index())
baseline_df = test_df1[~test_df1.duplicated(subset = ['ID'], keep='first')]
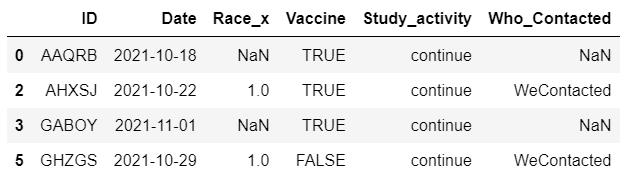
但問題是,如果我使用 freq='D',那么第二天輸入的 Race_x 值就會丟失。輸出如下圖所示。
如果我使用 freq='M' 或 freq='Y',則會捕獲其他值,但更改日期列值,我們將獲得每個 ID 的月底日期,如下所示。
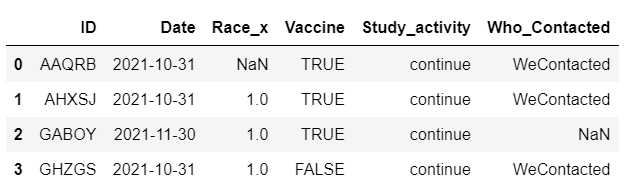
最后的“日期”列應該是每個 ID 的“日期”的第一個條目,并且不應更改。
任何幫助是極大的贊賞。謝謝!
uj5u.com熱心網友回復:
創建一個虛擬列以按月分組:
>>> test_df.assign(month=test_df['Date'].dt.strftime('%Y-%m')) \
.groupby(['ID', 'month']).agg('first') \
.droplevel(1).reset_index() \
.assign(Date=lambda x: x['Date'].dt.date)
ID Date Race_x Vaccine Study_activity Who_Contacted
0 AAQRB 2021-10-18 NaN TRUE continue WeContacted
1 AHXSJ 2021-10-22 1.0 TRUE continue WeContacted
2 GABOY 2021-11-01 1.0 TRUE continue None
3 GHZGS 2021-10-29 1.0 FALSE continue WeContacted
uj5u.com熱心網友回復:
看起來您只想groupbyID 并Date首先聚合,其他所有內容都與您有有效值時一樣。
假設所有Race_x, Vaccine, Study_activity,Who_Contacted始終是 ID 的單個非 NaN 值。你可以bfill先聚合再聚合。
這會將非 NaN 值收集到參與者的第一個條目中。
test_df['Date'] = pd.to_datetime('Date').dt.date
test_df.update(test_df.groupby('ID').bfill())
然后,嘗試聚合。
test_df.groupby('ID').first().reset_index()
>>> ID Date Race_x Vaccine Study_activity Who_Contacted
0 AAQRB 2021-10-18 NaN TRUE continue WeContacted
1 AHXSJ 2021-10-22 1.0 TRUE continue WeContacted
2 GABOY 2021-11-01 1.0 TRUE continue NaN
3 GHZGS 2021-10-29 1.0 FALSE continue WeContacted
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/347946.html
上一篇:轉置并保存一列熊貓資料框