ElasticSearch——倒排索引和正向索引
1、正向索引
正向索引 (forward index) 以檔案的ID為關鍵字,表中記錄檔案中每個字的位置資訊,查找時掃描表中每個檔案中字的資訊直到找出所有包含查詢關鍵字的檔案
這種組織方法在建立索引的時候結構比較簡單,建立比較方便且易于維護:
- 若是有新的檔案加入,直接為該檔案建立一個新的索引塊,掛接在原來索引檔案的后面,
- 若是有檔案洗掉,則直接找到該檔案號檔案對應的索引資訊,將其直接洗掉
缺點:
- 檢索效率太低,只能在一起簡單的場景下使用
假設有檔案一(id為doc_1)和檔案二(id為doc_2),
檔案一:my name is zhangsan
檔案二:my car is BMW
檔案一和檔案二的正向索引為:
| 檔案id | 關鍵詞 |
|---|---|
| doc_1 | my ,name, is, zhangsan |
| doc_2 | my ,car ,is ,BMW |
假設使用正向索引,那么當你搜索 ‘name’ 的時候,搜索引擎必須檢索檔案中的每一個關鍵詞,假設一個檔案中包含成千上百個關鍵詞,可想而知,會造成大量的資源浪費,于是倒排索引應運而生,
2、倒排索引
倒排索引 ,一般也被稱為反向索引(inverted index),帶有倒排索引的檔案我們稱為倒排索引檔案,簡稱倒排檔案(inverted file),
倒排索引以字或詞為關鍵字進行索引,表中關鍵字所對應的記錄表項記錄了出現這個字或詞的所有檔案,
一個表項就是一個欄位,它記錄該檔案的ID和字符在該檔案中出現的位置情況,
優缺點:
- 查詢的時候由于可以一次得到查詢關鍵字所對應的所有檔案,所以查詢效率高于正排索引,
- 由于每個字或詞對應的檔案數量在動態變化,所以倒排表的建立和維護都較為復雜
假設有檔案一(id為doc_1)和檔案二(id為doc_2),
檔案一:my name is zhangsan
檔案二:my car is BMW
檔案一和檔案二的倒排索引為:
| 關鍵詞 | 檔案id |
|---|---|
| my | doc_1,doc_2 |
| name | doc_1 |
| is | doc_1,doc_2 |
| zhangsan | doc_1 |
| car | doc_2 |
| BMW | doc_1 |
倒排索引是相對正向索引而言的,你也可以將其理解為逆向索引,它是一種關鍵詞與檔案一一對應的資料結構,
3、倒排索引的組成
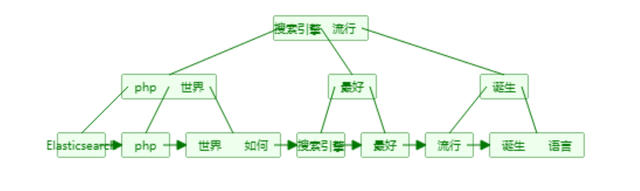
ES 倒排索引包含兩個部分:單詞詞典和倒排串列
單詞詞典(Term Dictionary)
單詞詞典是倒排索引中非常重要的組成部分,它用來維護檔案集合中出現過的所有單詞的相關資訊,同時用來記載某個單詞對應的倒排串列在倒排檔案中的位置資訊,在支持搜索時,根據用戶的查詢詞,去單詞詞典里查詢,就能夠獲得相應的倒排串列,并以此作為后續排序的基礎,
對于一個規模很大的檔案集合來說,可能包含幾十萬甚至上百萬的不同單詞,能否快速定位某個單詞,這直接影響搜索時的回應速度,所以需要高效的資料結構來對單詞詞典進行構建和查找,常用的資料結構包括哈希加鏈表結構和樹形詞典結構,
單詞詞典的特性:
- 是檔案集合中所有單詞的集合
- 它是保存索引的最小單位
- 其中記錄著指向倒排串列的指標
用B+Tree 實作單詞詞典,存盤在記憶體:
倒排串列
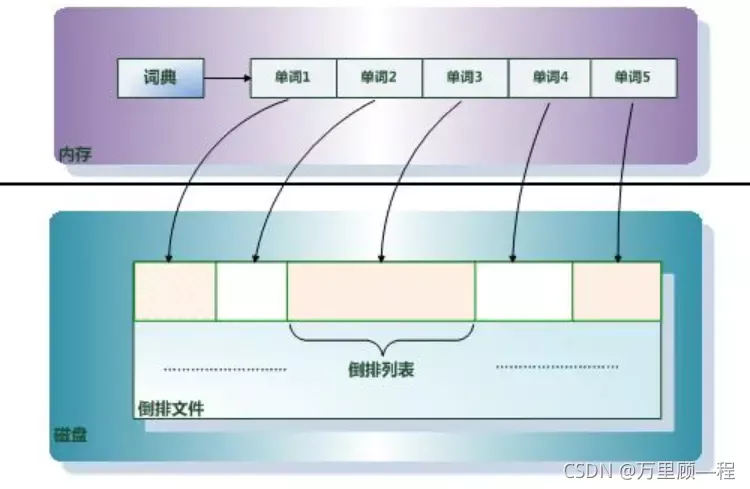
倒排串列記載了出現過某個單詞的所有檔案的檔案串列及單詞在該檔案中出現的位置資訊及頻率(作關聯性算分),每條記錄稱為一個倒排項(Posting),
根據倒排串列,即可獲知哪些檔案包含某個單詞,
倒排項(Posting)主要包含如下資訊:
-
檔案id用于獲取原始資訊
-
單詞頻率(TF,Term Frequency),記錄該單詞在該檔案中出現的次數,用于后續相關性算分
-
位置(Position),記錄單詞在檔案中的分詞位置(多個),用于做詞語搜索(Phrase Query)
-
偏移(Offset),記錄單詞在檔案的開始和結束位置,用于高亮顯示
單詞詞典和倒排串列整合到一起的結構如下:
4、倒排索引的更新策略
搜索引擎需要處理的檔案集合往往都是動態集合,即在建好初始的索引后,不斷有新檔案進入系統,同時原先的檔案集合內有些檔案可能被洗掉或更改,
動態索引通過在記憶體中維護臨時索引,可以實作對動態檔案和實時搜索的支持,
服務器記憶體總是有限的,隨著新加入系統的檔案越來越多,臨時索引消耗的記憶體也會隨之增加,
當最初分配的記憶體將被使用完時,要考慮將臨時索引的內容更新到磁盤索引中,以釋放記憶體空間來容納后續的新進檔案,
索引基本更新思想:
- 倒排索引就是對初始檔案集合建立的索引結構,一般單詞詞典都存盤在記憶體,對應的倒排串列存盤在磁盤檔案中
- 臨時索引是在記憶體中實時建立的倒排索引,其結構和前述的倒排索引是一樣的,區別在于詞典和倒排串列都在記憶體中存盤,
- 新檔案進入系統時,實時決議檔案并將其加入到臨時索引結構中,
- 洗掉檔案串列則用來存盤已被洗掉的檔案的相應的檔案ID,形成一個檔案ID串列,
- 修改檔案可以認為是舊檔案先被洗掉,然后系統在增加一篇新的檔案,通過這種間接方式實作對內容更改的支持,
5、倒排索引四種更新策略
常用的索引更新策略主要有四種:完全重建策略、再合并策略、原地更新策略及混合策略,
- **完全重建策略:**當新增檔案到達一定數量,將新增檔案和原先的老檔案整合,然后利用靜態索引創建方法對所有檔案重建索引,新索引建立完成后老索引會被遺棄,此法代價高,但是主流商業搜索引擎一般是采用此方式來維護索引的更新(這句話是書中原話)
- 再合并策略:當新增檔案進入系統,決議檔案,之后更新記憶體中維護的臨時索引,檔案中出現的每個單詞,在其倒排表串列末尾追加倒排表串列項;一旦臨時索引將指定記憶體消耗光,即進行一次索引合并,這里需要倒排檔案里的倒排串列存放順序已經按照索引單詞字典順序由低到高排序,這樣直接順序掃描合并即可,其缺點是:因為要生成新的倒排索引檔案,所以對老索引中的很多單詞,盡管其在倒排串列并未發生任何變化,也需要將其從老索引中取出來并寫入新索引中,這樣對磁盤消耗是沒必要的,
- **原地更新策略:**試圖改進再合并策略,在原地合并倒排表,這需要提前分配一定的空間給未來插入,如果提前分配的空間不夠了需要遷移,實際顯示,其索引更新的效率比再合并策略要低,
- **混合策略:**出發點是能夠結合不同索引更新策略的長處,將不同索引更新策略混合,以形成更高效的方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/348303.html
標籤:其他