遷移型別
- 同時遷移表及其資料(使用
import和export) - 分步遷移表和資料
- 遷移表(
show create table <tab_name>) - 遷移資料
- 關聯表和資料(
msck repair)
- 遷移表(
遷移步驟
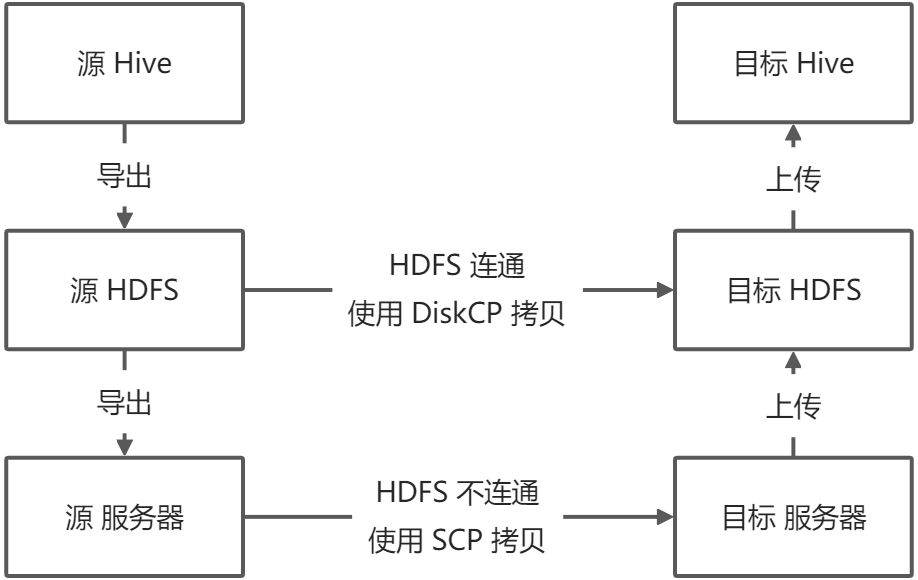
- 將表和資料從 Hive 匯出到 HDFS
- 將表和資料從 HDFS 匯出到本地服務器
- 將表和資料從本地服務器復制到目標服務器
- 將表和資料從目標服務器上傳到目標 HDFS
- 將表和資料從目標 HDFS 上傳到目標 Hive 庫
- 如果原始 HDFS 和目標 HDFS 集群連通,可使用
DiskCP工具直接跨集群復制,而跳過2~4步
實施程序
目標集群和服務器檢查
df -lh # 查看本地空間使用情況
hadoop dfsadmin -report # 查看HDFS集群使用情況
hadoop fs -find / -name warehouse # 查找Hive庫位置
hadoop fs -du -h /user/hive/warehouse # 查看Hive庫占用同時遷移表及其資料(使用import和export)
- export 工具匯出時會同時匯出元資料和資料
- import 工具會根據元資料自行創建表并匯入資料
- 如果涉及事物表需要預先開啟目標庫的事物機制
-- 開啟事務
-- https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions#HiveTransactions-Configuration
SET hive.support.concurrency = true;
SET hive.enforce.bucketing = true;
SET hive.exec.dynamic.partition.mode = nonstrict;
SET hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
SET hive.compactor.initiator.on = true;
SET hive.compactor.worker.threads = 1;遷移步驟
## 源服務器
cat <<EOF > /home/ap/dip/lzy/hive_sel_tables.hql
use cwmp;
show tables;
EOF
# 羅列要遷移的表清單
beeline -f /home/ap/dip/lzy/hive_sel_tables.HQL \
| grep -e "^|" \
| grep -v "tab_name" \
| sed "s/|//g" \
| sed "s/ //g" \
> /home/ap/dip/lzy/hive_table_list.txt
# 生成匯出腳本
cat /home/ap/dip/lzy/hive_table_list.txt \
| awk '{printf "export table cwmp.%s to |/tmp/cwmp/%s|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /home/ap/dip/lzy/hive_export_table.HQL
# 生成匯入腳本
cat /home/ap/dip/lzy/hive_table_list.txt \
| awk '{printf "import table cwmp.%s from |/tmp/cwmp/%s|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /home/ap/dip/lzy/hive_import_table.HQL
# 創建 HDFS 匯出目錄
hadoop fs -mkdir -p /tmp/cwmp/
# 匯出表結構到資料到 HDFS
beeline -f /home/ap/dip/lzy/hive_export_table.HQL
## HDFS 集群連通時使用 DiskCP 進行拷貝
hadoop distcp hdfs://scrNmaeNode/tmp/cwmp hdfs://targetNmaeNode/tmp
## HDFS 集群不連通
hadoop fs -get /tmp/cwmp /home/ap/dip/lzy/
scp -r /home/ap/dip/lzy/ root@targetAP:/home/ap/dip/
## 目標服務器
# 創建 HDFS 匯出目錄
hadoop fs -mkdir -p /tmp/cwmp/
# 上傳到目標 HDFS
hadoop fs -put /home/ap/dip/lzy/cwmp /tmp
# 匯入到目標 Hive
beeline -f /home/ap/dip/lzy/hive_import_table.HQL分步遷移表和資料
備份表
cat <<EOF > /home/ap/dip/lzy/hive_sel_tables.hql
use cwmp;
show tables;
EOF
# 羅列要遷移的表清單
beeline -f /home/ap/dip/lzy/hive_tables_sel.HQL \
| grep -e "^|" \
| grep -v "tab_name" \
| sed "s/|//g" \
| sed "s/ //g" \
> /home/ap/dip/lzy/hive_tables_rst.HQL
# 生成DDL查詢陳述句
cat /home/ap/dip/lzy/hive_tables_rst.HQL \
| awk '{printf "show create table cwmp.%s ;\n",$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /home/ap/dip/lzy/hive_table_ddl_sel.HQL
# 生成 DDL 查詢結果
beeline -f /home/ap/dip/lzy/hive_table_ddl_sel.HQL \
> /home/ap/dip/lzy/hive_table_ddl_rst.HQL遷移資料
通過 HDFS 復制資料
- 這種方式無法備份外部表的資料
- 保證遷移前后的HDFS資料目錄一致
- 資料遷移同樣考慮集群連通時使用
Diskcp進行復制,不連通時先 GET 到本地,傳到目標服務器侯 再 PUT 到 HDFS
/user/hive/warehouse/database.db/table_name # Hive 默認路徑
# 跨HDFS集群復制
hadoop distcp hdfs://scrNmaeNode/user/hive/warehouse/database.db/ hdfs://scrNmaeNode/user/hive/warehouse/通過 HiveQL 遷移資料
- 需要預先構建表和磁區
desc 表名;
show partitions 磁區表名;- 這種方式適合表比較少,表結構不是很復雜的表的遷移
-- 匯出資料到服務器
INSERT OVERWRITE LOCAL DIRECTORY "路徑"
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
SELECT 欄位1,欄位2,... FROM <table_name>;
-- 匯出資料到HDFS
INSERT OVERWRITE DIRECTORY "路徑"
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
SELECT 欄位1,欄位2,... FROM <table_name>;
-- 匯入資料
LOAD DATA LOCAL INPATH '/root/my/bookstore.txt'
OVERWRITE INTO TABLE <table_name>;關聯表和資料
- 關聯前需要在目標庫預先創建表
msck repair table <tableName>參考:
?????????????????????HIVE資料遷移
Hive中的資料遷移--遷移多庫資料以及實際遇到的問題解決
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/348319.html
標籤:其他