文章目錄
- 0 前言
- 1 網路整體框架
- 2 Patch Merging詳解
- 3 W-MSA詳解
- MSA模塊計算量
- W-MSA模塊計算量
- 4 SW-MSA詳解
- 5 Relative Position Bias詳解
- 6 模型詳細配置引數
0 前言
Swin Transformer是2021年微軟研究院發表在ICCV上的一篇文章,并且已經獲得ICCV 2021 best paper的榮譽稱號,Swin Transformer網路是Transformer模型在視覺領域的又一次碰撞,該論文一經發表就已在多項視覺任務中霸榜,該論文是在2021年3月發表的,現在是2021年11月了,根據官方提供的資訊可以看到,現在還在COCO資料集的目標檢測以及實體分割任務中是第一名(見下圖State of the Art表示第一),

論文名稱:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
原論文地址: https://arxiv.org/abs/2103.14030
官方開源代碼地址:https://github.com/microsoft/Swin-Transformer
Pytorch實作代碼: pytorch_classification/swin_transformer
1 網路整體框架
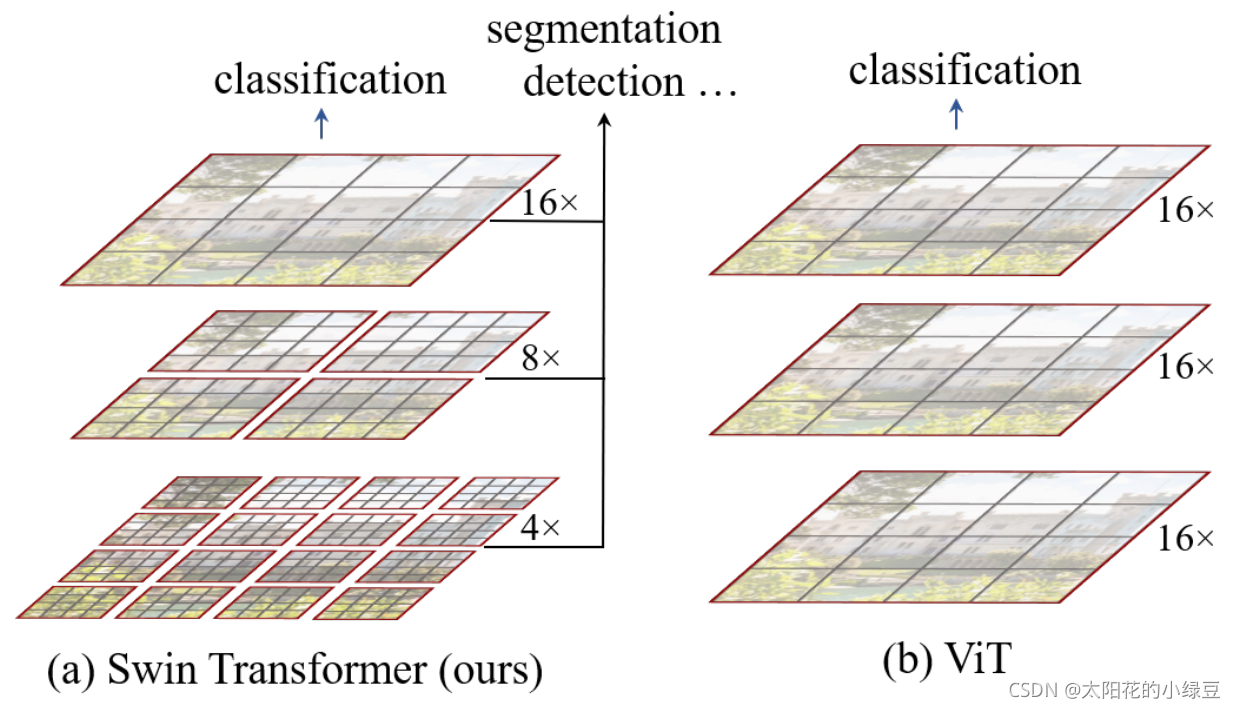
在正文開始之前,先來簡單對比下Swin Transformer和之前的Vision Transformer進行簡單對比(如果不了解Vision Transformer的建議先去看下我之前的文章),下圖是Swin Transformer文章中給出的圖1,左邊是本文要講的Swin Transformer,右邊邊是之前講的Vision Transformer,通過對比至少可以看出兩點不同:
- Swin Transformer使用了類似卷積神經網路中的層次化構建方法(Hierarchical feature maps),比如特征圖尺寸中有對影像下采樣4倍的,8倍的以及16倍的,這樣的backbone有助于在此基礎上構建目標檢測,實體分割等任務,而在之前的Vision Transformer中是一開始就直接下采樣16倍,后面的特征圖也是維持這個下采樣率不變,
- 在Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如在下圖的4倍下采樣和8倍下采樣中,將特征圖劃分成了多個不相交的區域(Window),并且Multi-Head Self-Attention只在每個視窗(Window)內進行,相對于Vision Transformer中直接對整個(Global)特征圖進行Multi-Head Self-Attention,這樣做的目的是能夠減少計算量的,尤其是在淺層特征圖很大的時候,這樣做雖然減少了計算量但也會隔絕不同視窗之間的資訊傳遞,所以在論文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通過此方法能夠讓資訊在相鄰的視窗中進行傳遞,后面會細講,
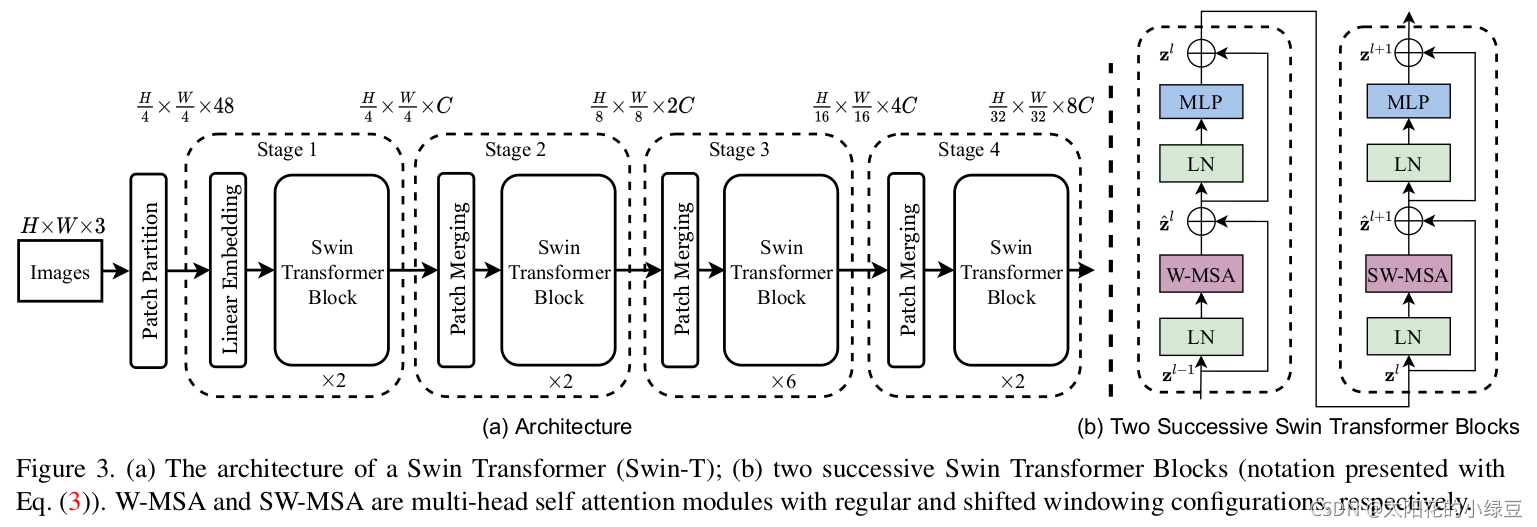
接下來,簡單看下原論文中給出的關于Swin Transformer(Swin-T)網路的架構圖,通過圖(a)可以看出整個框架的基本流程如下:
-
首先將圖片輸入到Patch Partition模塊中進行分塊,即每4x4相鄰的像素為一個Patch,然后在channel方向展平(flatten),假設輸入的是RGB三通道圖片,那么每個patch就有4x4=16個像素,然后每個像素有R、G、B三個值所以展平后是16x3=48,所以通過Patch Partition后影像shape由
[H, W, 3]變成了[H/4, W/4, 48],然后在通過Linear Embeding層對每個像素的channel資料做線性變換,由48變成C,即影像shape再由[H/4, W/4, 48]變成了[H/4, W/4, C],其實在原始碼中Patch Partition和Linear Embeding就是直接通過一個卷積層實作的,和之前Vision Transformer中講的 Embedding層結構一模一樣, -
然后就是通過四個Stage構建不同大小的特征圖,除了Stage1中先通過一個Linear Embeding層外,剩下三個stage都是先通過一個Patch Merging層進行下采樣(后面會細講),然后都是重復堆疊Swin Transformer Block注意這里的Block其實有兩種結構,如圖(b)中所示,這兩種結構的不同之處僅在于一個使用了W-MSA結構,一個使用了SW-MSA結構,而且這兩個結構是成對使用的,先使用一個W-MSA結構再使用一個SW-MSA結構,所以你會發現堆疊Swin Transformer Block的次數都是偶數(因為成對使用),
-
最后對于分類網路,后面還會接上一個Layer Norm層、全域池化層以及全連接層得到最終輸出,圖中沒有畫,但原始碼中是這樣做的,
接下來,在分別對Patch Merging、W-MSA、SW-MSA以及使用到的相對位置偏執(relative position bias)進行詳解,關于Swin Transformer Block中的MLP結構和Vision Transformer中的結構是一樣的,所以這里也不在贅述,參考,
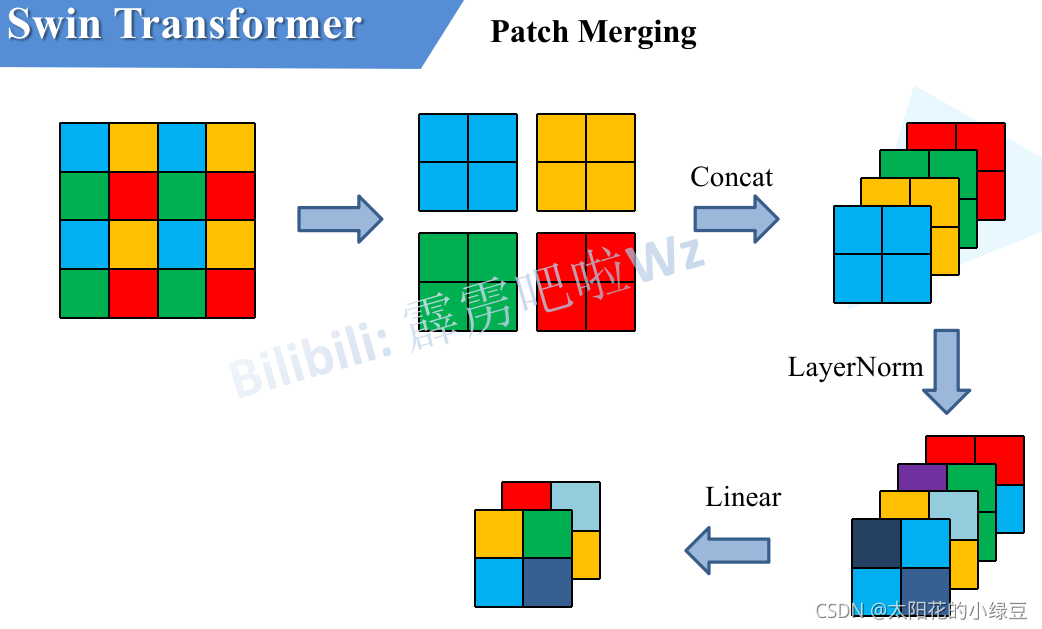
2 Patch Merging詳解
前面有說,在每個Stage中首先要通過一個Patch Merging層進行下采樣(Stage1除外),如下圖所示,假設輸入Patch Merging的是一個4x4大小的單通道特征圖(feature map),Patch Merging會將每個2x2的相鄰像素劃分為一個patch,然后將每個patch中相同位置(同一顏色)像素給拼在一起就得到了4個feature map,接著將這四個feature map在深度方向進行concat拼接,然后在通過一個LayerNorm層,最后通過一個全連接層在feature map的深度方向做線性變化,將feature map的深度由C變成C/2,通過這個簡單的例子可以看出,通過Patch Merging層后,feature map的高和寬會減半,深度會翻倍,
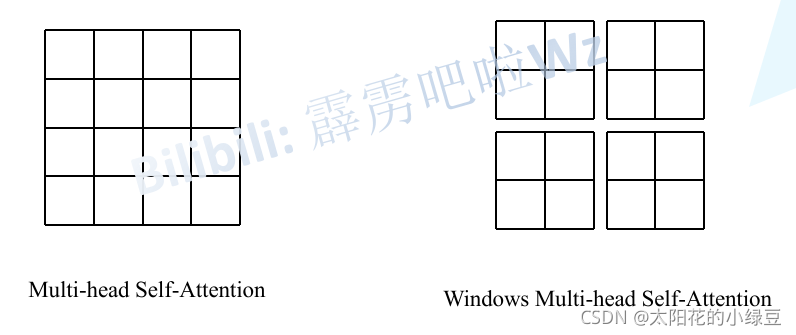
3 W-MSA詳解
引入Windows Multi-head Self-Attention(W-MSA)模塊是為了減少計算量,如下圖所示,左側使用的是普通的Multi-head Self-Attention(MSA)模塊,對于feature map中的每個像素(或稱作token,patch)在Self-Attention計算程序中需要和所有的像素去計算,但在圖右側,在使用Windows Multi-head Self-Attention(W-MSA)模塊時,首先將feature map按照MxM(例子中的M=2)大小劃分成一個個Windows,然后單獨對每個Windows內部進行Self-Attention,
兩者的計算量具體差多少呢?原論文中有給出下面兩個公式,這里忽略了Softmax的計算復雜度,:
Ω
(
M
S
A
)
=
4
h
w
C
2
+
2
(
h
w
)
2
C
(
1
)
Ω
(
W
?
M
S
A
)
=
4
h
w
C
2
+
2
M
2
h
w
C
(
2
)
\Omega (MSA)=4hwC^2 + 2{(hw)}^2C \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (1) \\ \Omega (W-MSA)=4hwC^2 + 2M^2hwC\ \ \ \ \ (2)
Ω(MSA)=4hwC2+2(hw)2C (1)Ω(W?MSA)=4hwC2+2M2hwC (2)
- h代表feature map的高度
- w代表feature map的寬度
- C代表feature map的深度
- M代表每個視窗(Windows)的大小
這個公式是咋來的,原論文中并沒有細講,這里簡單說下,首先回憶下單頭Self-Attention的公式,如果對Self-Attention不了解的,請看下我之前寫的文章,
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
M
a
x
(
Q
K
T
d
)
V
Attention(Q, K, V)={\rm SoftMax}(\frac{QK^T}{\sqrt d})V
Attention(Q,K,V)=SoftMax(d
?QKT?)V
MSA模塊計算量
對于feature map中的每個像素(或稱作token,patch),都要通過
W
q
,
W
k
,
W
v
W_q, W_k, W_v
Wq?,Wk?,Wv?生成對應的query(q),key(k)以及value(v),這里假設q, k, v的向量長度與feature map的深度C保持一致,那么對應所有像素生成Q的程序如下式:
A
h
w
×
C
?
W
q
C
×
C
=
Q
h
w
×
C
A^{hw \times C} \cdot W^{C \times C}_q=Q^{hw \times C}
Ahw×C?WqC×C?=Qhw×C
- A h w × C A^{hw \times C} Ahw×C為將所有像素(token)拼接在一起得到的矩陣(一共有hw個像素,每個像素的深度為C)
- W q C × C W^{C \times C}_q WqC×C?為生成query的變換矩陣
- Q h w × C Q^{hw \times C} Qhw×C為所有像素通過 W q C × C W^{C \times C}_q WqC×C?得到的query拼接后的矩陣
根據矩陣運算的計算量公式可以得到生成Q的計算量為
h
w
×
C
×
C
hw \times C \times C
hw×C×C,生成K和V同理都是
h
w
C
2
hwC^2
hwC2,那么總共是
3
h
w
C
2
3hwC^2
3hwC2,接下來
Q
Q
Q和
K
T
K^T
KT相乘,對應計算量為
(
h
w
)
2
C
(hw)^2C
(hw)2C:
Q
h
w
×
C
?
K
T
(
C
×
h
w
)
=
X
h
w
×
h
w
Q^{hw \times C} \cdot K^{T(C \times hw)}= X^{hw \times hw}
Qhw×C?KT(C×hw)=Xhw×hw
接下來忽略除以
d
\sqrt d
d
?以及softmax的計算量,假設得到
Λ
h
w
×
h
w
\Lambda ^{hw \times hw}
Λhw×hw,最后還要乘以V,對應的計算量為
(
h
w
)
2
C
(hw)^2C
(hw)2C:
Λ
h
w
×
h
w
?
V
h
w
×
C
=
B
h
w
×
C
\Lambda ^{hw \times hw} \cdot V^{hw \times C}=B^{hw \times C}
Λhw×hw?Vhw×C=Bhw×C
那么對應單頭的Self-Attention模塊,總共需要
3
h
w
C
2
+
(
h
w
)
2
C
+
(
h
w
)
2
C
=
3
h
w
C
2
+
2
(
h
w
)
2
C
3hwC^2 + (hw)^2C + (hw)^2C=3hwC^2 + 2(hw)^2C
3hwC2+(hw)2C+(hw)2C=3hwC2+2(hw)2C,而在實際使用程序中,使用的是多頭的Multi-head Self-Attention模塊,在之前的文章中有進行過實驗對比,多頭注意力模塊相比單頭注意力模塊的計算量僅多了最后一個融合矩陣
W
O
W_O
WO?的計算量
h
w
C
2
hwC^2
hwC2,
B
h
w
×
C
?
W
O
C
×
C
=
O
h
w
×
C
B^{hw \times C} \cdot W_O^{C \times C} = O^{hw \times C}
Bhw×C?WOC×C?=Ohw×C
所以總共加起來是:
4
h
w
C
2
+
2
(
h
w
)
2
C
4hwC^2 + 2(hw)^2C
4hwC2+2(hw)2C
W-MSA模塊計算量
對于W-MSA模塊首先要將feature map劃分到一個個視窗(Windows)中,假設每個視窗的寬高都是M,那么總共會得到
h
M
×
w
M
\frac {h} {M} \times \frac {w} {M}
Mh?×Mw?個視窗,然后對每個視窗內使用多頭注意力模塊,剛剛計算高為h,寬為w,深度為C的feature map的計算量為
4
h
w
C
2
+
2
(
h
w
)
2
C
4hwC^2 + 2(hw)^2C
4hwC2+2(hw)2C,這里每個視窗的高為M寬為M,帶入公式得:
4
(
M
C
)
2
+
2
(
M
)
4
C
4(MC)^2 + 2(M)^4C
4(MC)2+2(M)4C
又因為有
h
M
×
w
M
\frac {h} {M} \times \frac {w} {M}
Mh?×Mw?個視窗,則:
h
M
×
w
M
×
(
4
(
M
C
)
2
+
2
(
M
)
4
C
)
=
4
h
w
C
2
+
2
M
2
h
w
C
\frac {h} {M} \times \frac {w} {M} \times (4(MC)^2 + 2(M)^4C)=4hwC^2 + 2M^2 hwC
Mh?×Mw?×(4(MC)2+2(M)4C)=4hwC2+2M2hwC
故使用W-MSA模塊的計算量為:
4
h
w
C
2
+
2
M
2
h
w
C
4hwC^2 + 2M^2 hwC
4hwC2+2M2hwC
假設feature map的h、w都為112,M=7,C=128,采用W-MSA模塊相比MSA模塊能夠節省約40124743680 FLOPs:
2
(
h
w
)
2
C
?
2
M
2
h
w
C
=
2
×
11
2
4
×
128
?
2
×
7
2
×
11
2
2
×
128
=
40124743680
2(hw)^2C-2M^2 hwC=2 \times 112^4 \times 128 - 2 \times 7^2 \times 112^2 \times 128=40124743680
2(hw)2C?2M2hwC=2×1124×128?2×72×1122×128=40124743680
4 SW-MSA詳解
前面有說,采用W-MSA模塊時,只會在每個視窗內進行自注意力計算,所以視窗與視窗之間是無法進行資訊傳遞的,為了解決這個問題,作者引入了Shifted Windows Multi-Head Self-Attention(SW-MSA)模塊,即進行偏移的W-MSA,如下圖所示,左側使用的是剛剛講的W-MSA(假設是第L層),那么根據之前介紹的W-MSA和SW-MSA是成對使用的,那么第L+1層使用的就是SW-MSA(右側圖),根據左右兩幅圖對比能夠發現視窗(Windows)發生了偏移(可以理解成視窗從左上角分別像右側和下方各偏移了 ? M 2 ? \left \lfloor \frac {M} {2} \right \rfloor ?2M??個像素),看下偏移后的視窗(右側圖),比如對于第一行第2列的2x4的視窗,它能夠使第L層的第一排的兩個視窗資訊進行交流,再比如,第二行第二列的4x4的視窗,他能夠使第L層的四個視窗資訊進行交流,其他的同理,那么這就解決了不同視窗之間無法進行資訊交流的問題,
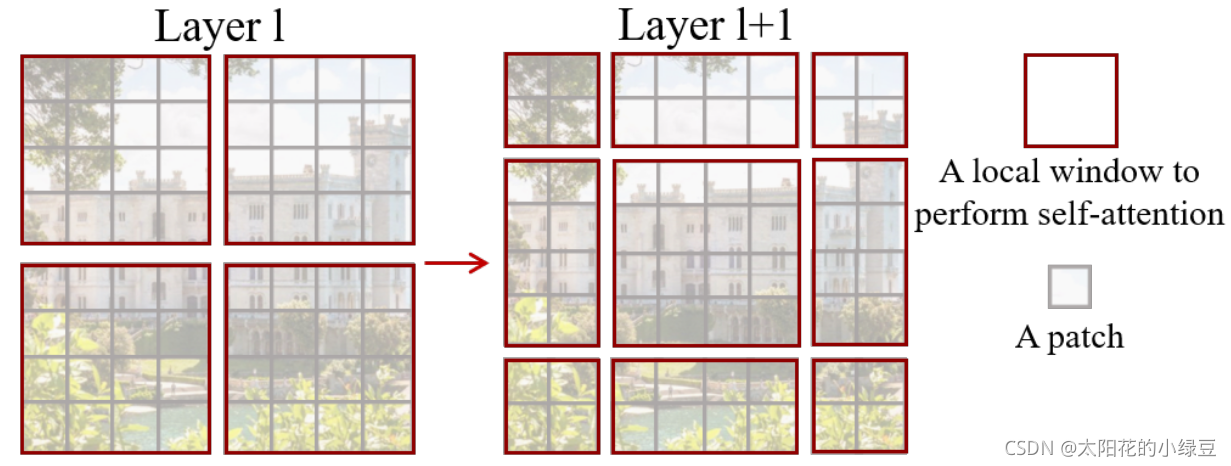
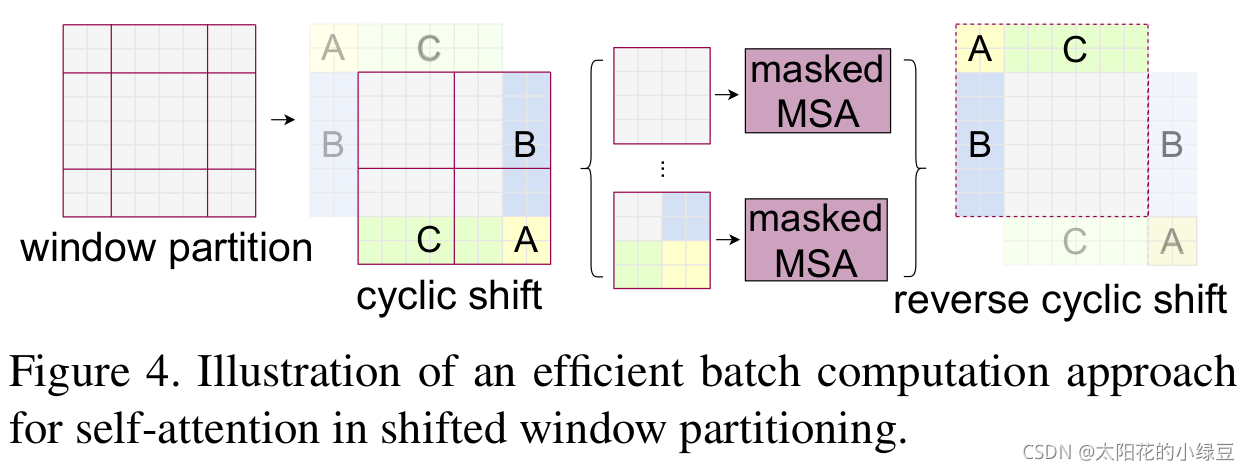
根據上圖,可以發現通過將視窗進行偏移后,由原來的4個視窗變成9個視窗了,后面又要對每個視窗內部進行MSA,這樣做感覺又變麻煩了,為了解決這個麻煩,作者又提出而了Efficient batch computation for shifted configuration,一種更加高效的計算方法,下面是原論文給的示意圖,
感覺不太好描述,然后我自己又重新畫了個,下圖左側是剛剛通過偏移視窗后得到的新視窗,右側是為了方便大家理解,對每個視窗加上了一個標識,然后0對應的視窗標記為區域A,3和6對應的視窗標記為區域B,1和2對應的視窗標記為區域C,
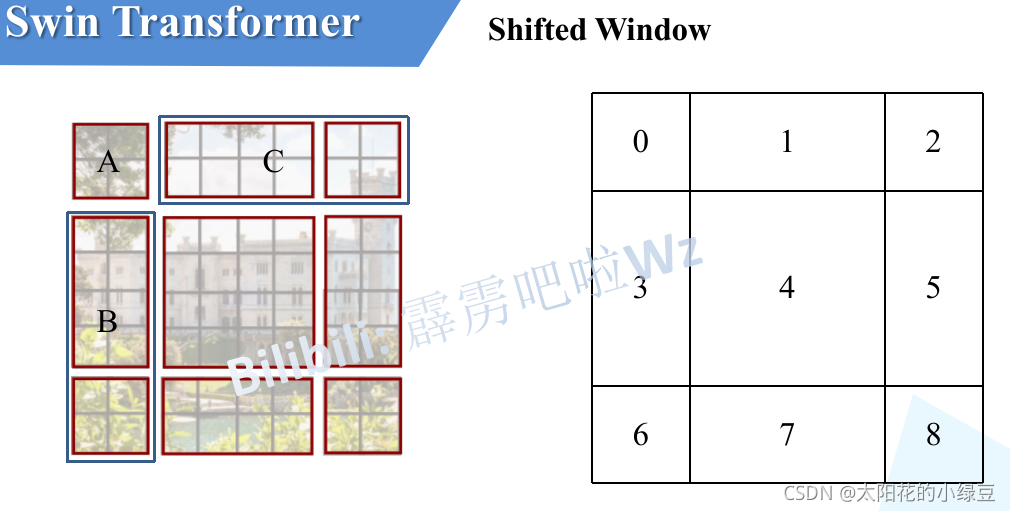
然后先將區域A和C移到最下方,
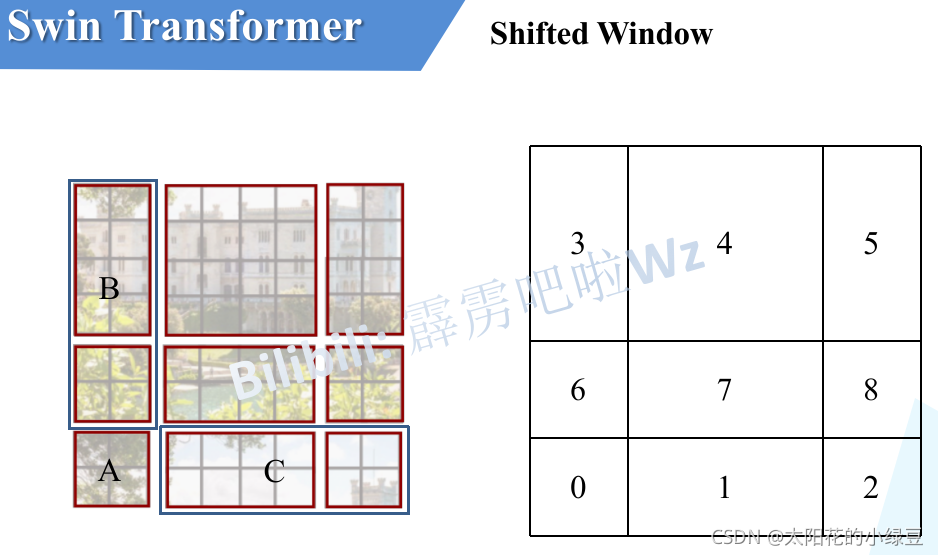
接著,再將區域A和B移至最右側,
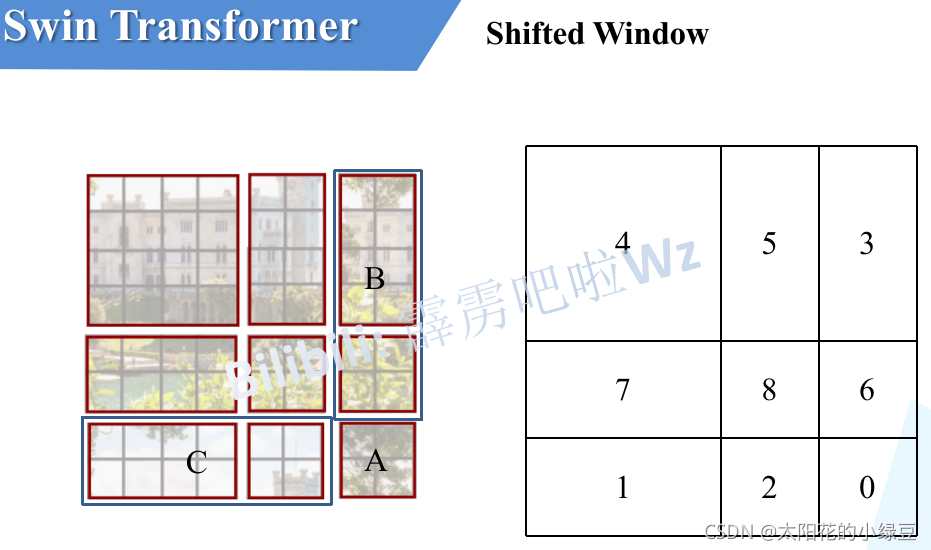
移動完后,4是一個單獨的視窗;將5和3合并成一個視窗;7和1合并成一個視窗;8、6、2和0合并成一個視窗,這樣又和原來一樣是4個4x4的視窗了,所以能夠保證計算量是一樣的,這里肯定有人會想,把不同的區域合并在一起(比如5和3)進行MSA,這資訊不就亂竄了嗎?是的,為了防止這個問題,在實際計算中使用的是masked MSA即帶蒙板mask的MSA,這樣就能夠通過設定蒙板來隔絕不同區域的資訊了,關于mask如何使用,可以看下下面這幅圖,下圖是以上面的區域5和區域3為例,
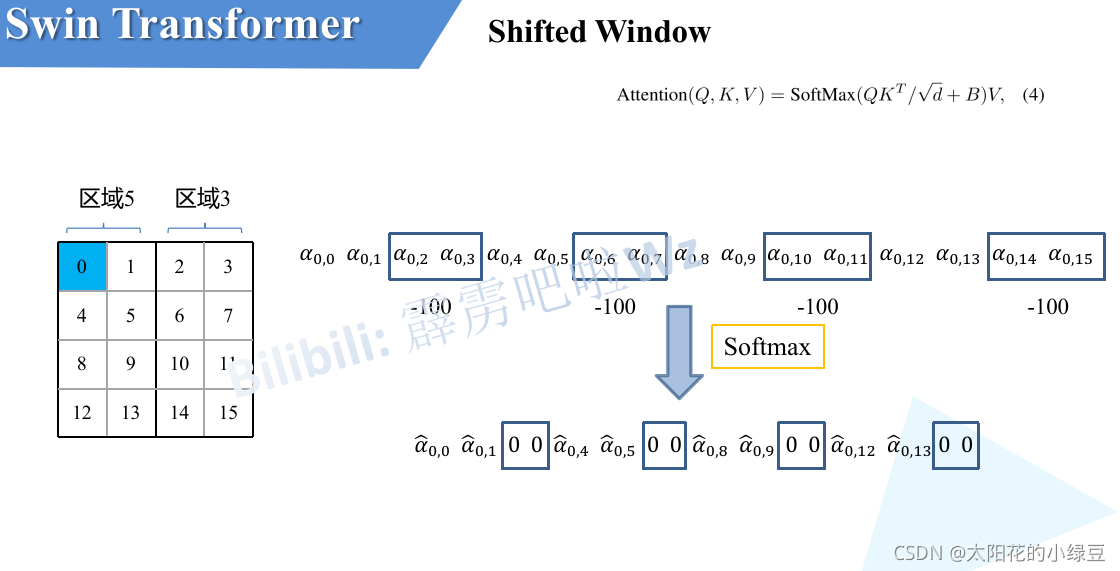
對于該視窗內的每一個像素(或稱token,patch)在進行MSA計算時,都要先生成對應的query(q),key(k),value(v),假設對于上圖的像素0而言,得到
q
0
q^0
q0后要與每一個像素的k進行匹配(match),假設
α
0
,
0
\alpha _{0,0}
α0,0?代表
q
0
q^0
q0與像素0對應的
k
0
k^0
k0進行匹配的結果,那么同理可以得到
α
0
,
0
\alpha _{0,0}
α0,0?至
α
0
,
15
\alpha _{0,15}
α0,15?,按照普通的MSA計算,接下來就是SoftMax操作了,但對于這里的masked MSA,像素0是屬于區域5的,我們只想讓它和區域5內的像素進行匹配,那么我們可以將像素0與區域3中的所有像素匹配結果都減去100(例如
α
0
,
2
,
α
0
,
3
,
α
0
,
6
,
α
0
,
7
\alpha _{0,2}, \alpha _{0,3}, \alpha _{0,6}, \alpha _{0,7}
α0,2?,α0,3?,α0,6?,α0,7?等等),由于
α
\alpha
α的值都很小,一般都是零點幾的數,將其中一些數減去100后在通過SoftMax得到對應的權重都等于0了,所以對于像素0而言實際上還是只和區域5內的像素進行了MSA,那么對于其他像素也是同理,具體代碼是怎么實作的,后面會在代碼講解中進行詳解,注意,在計算完后還要把資料給挪回到原來的位置上(例如上述的A,B,C區域),
5 Relative Position Bias詳解
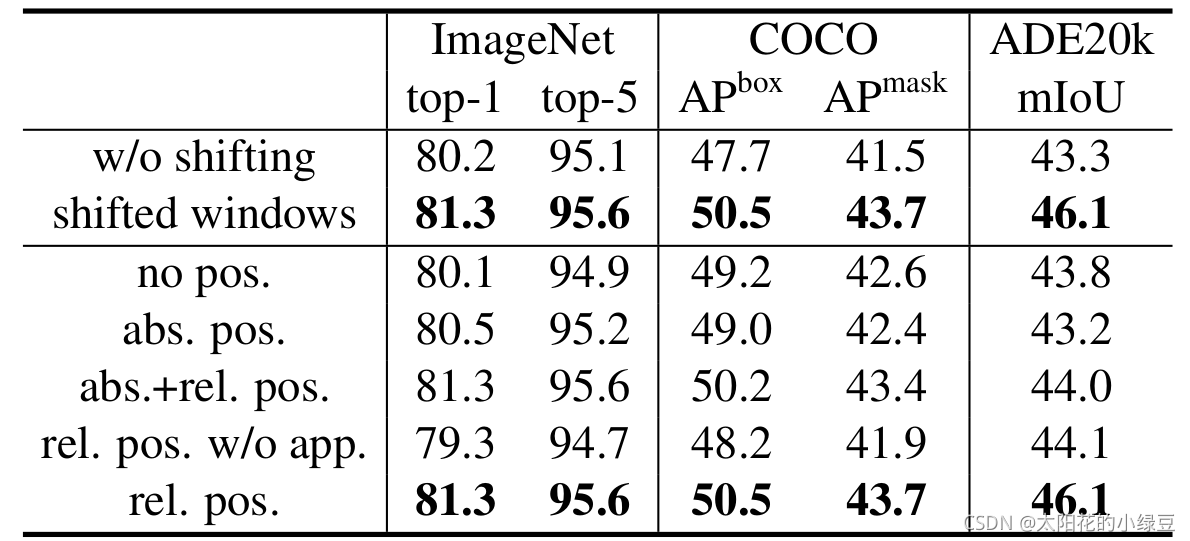
關于相對位置偏執,論文里也沒有細講,就說了參考的哪些論文,然后說使用了相對位置偏執后給夠帶來明顯的提升,根據原論文中的表4可以看出,在Imagenet資料集上如果不使用任何位置偏執,top-1為80.1,但使用了相對位置偏執(rel. pos.)后top-1為83.3,提升還是很明顯的,
那這個相對位置偏執是加在哪的呢,根據論文中提供的公式可知是在Q和K進行匹配并除以
d
\sqrt d
d
?后加上了相對位置偏執B,
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
M
a
x
(
Q
K
T
d
+
B
)
V
Attention(Q, K, V)=SoftMax(\frac {QK^T} {\sqrt d} + B)V
Attention(Q,K,V)=SoftMax(d
?QKT?+B)V
由于論文中并沒有詳解講解這個相對位置偏執,所以我自己根據閱讀原始碼做了簡單的總結,如下圖,假設輸入的feature map高寬都為2,那么首先我們可以構建出每個像素的絕對位置(左下方的矩陣),對于每個像素的絕對位置是使用行號和列號表示的,比如藍色的像素對應的是第0行第0列所以絕對位置索引是 ( 0 , 0 ) (0,0) (0,0),接下來再看看相對位置索引,首先看下藍色的像素,在藍色像素使用q與所有像素k進行匹配程序中,是以藍色像素為參考點,然后用藍色像素的絕對位置索引與其他位置索引進行相減,就得到其他位置相對藍色像素的相對位置索引,例如黃色像素的絕對位置索引是 ( 0 , 1 ) (0,1) (0,1),則它相對藍色像素的相對位置索引為 ( 0 , 0 ) ? ( 0 , 1 ) = ( 0 , ? 1 ) (0, 0) - (0, 1)=(0, -1) (0,0)?(0,1)=(0,?1),這里是嚴格按照原始碼中來講的,請不要杠,那么同理可以得到其他位置相對藍色像素的相對位置索引矩陣,同樣,也能得到相對黃色,紅色以及綠色像素的相對位置索引矩陣,接下來將每個相對位置索引矩陣按行展平,并拼接在一起可以得到下面的4x4矩陣 ,
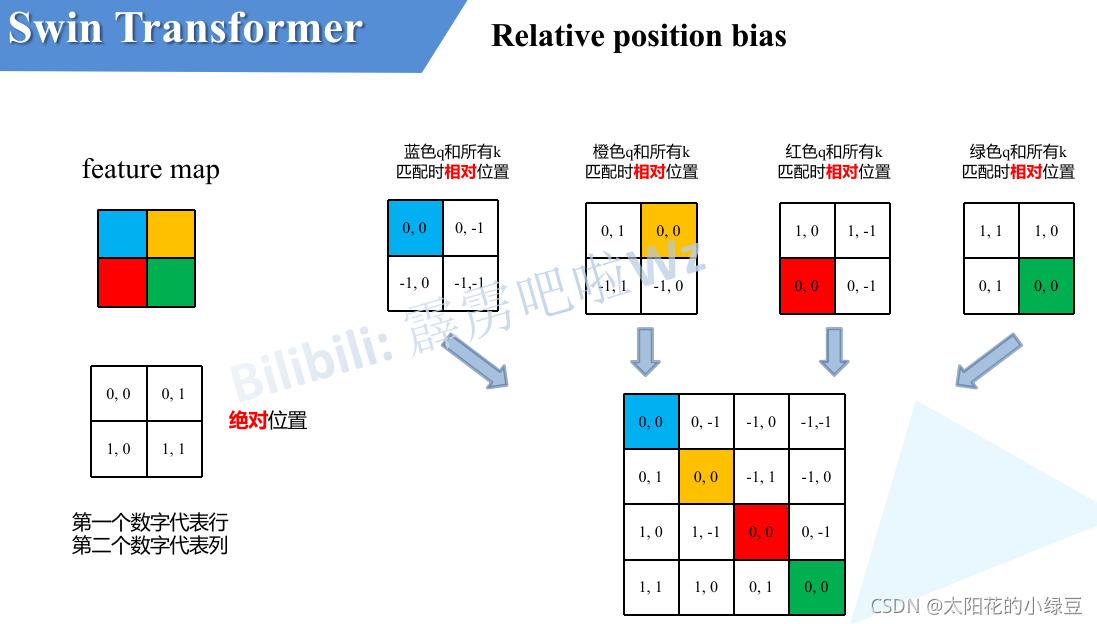
請注意,我這里描述的一直是相對位置索引,并不是相對位置偏執引數,因為后面我們會根據相對位置索引去取對應的引數,比如說黃色像素是在藍色像素的右邊,所以相對藍色像素的相對位置索引為
(
0
,
?
1
)
(0, -1)
(0,?1),綠色像素是在紅色像素的右邊,所以相對紅色像素的相對位置索引為
(
0
,
?
1
)
(0, -1)
(0,?1),可以發現這兩者的相對位置索引都是
(
0
,
?
1
)
(0, -1)
(0,?1),所以他們使用的相對位置偏執引數都是一樣的,其實講到這基本已經講完了,但在原始碼中作者為了方便把二維索引給轉成了一維索引,具體這么轉的呢,有人肯定想到,簡單啊直接把行、列索引相加不就變一維了嗎?比如上面的相對位置索引中有
(
0
,
?
1
)
(0, -1)
(0,?1)和
(
?
1
,
0
)
(-1,0)
(?1,0)在二維的相對位置索引中明顯是代表不同的位置,但如果簡單相加都等于-1那不就出問題了嗎?接下來我們看看原始碼中是怎么做的,首先在原始的相對位置索引上加上M-1(M為視窗的大小,在本示例中M=2),加上之后索引中就不會有負數了,

接著將所有的行標都乘上2M-1,
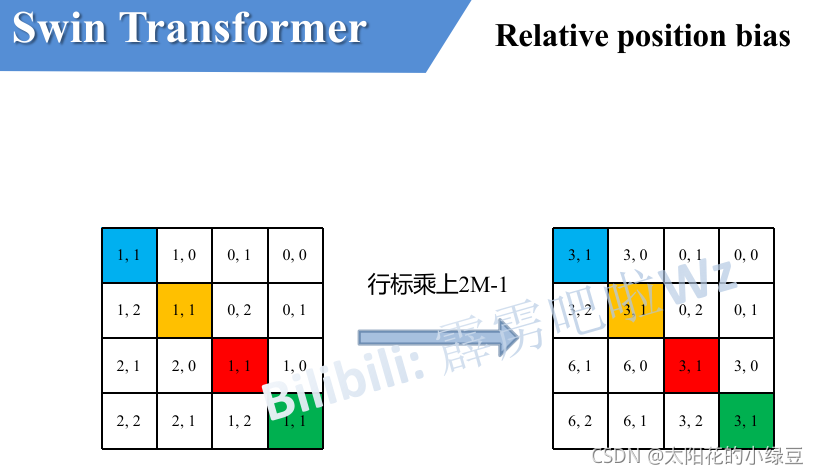
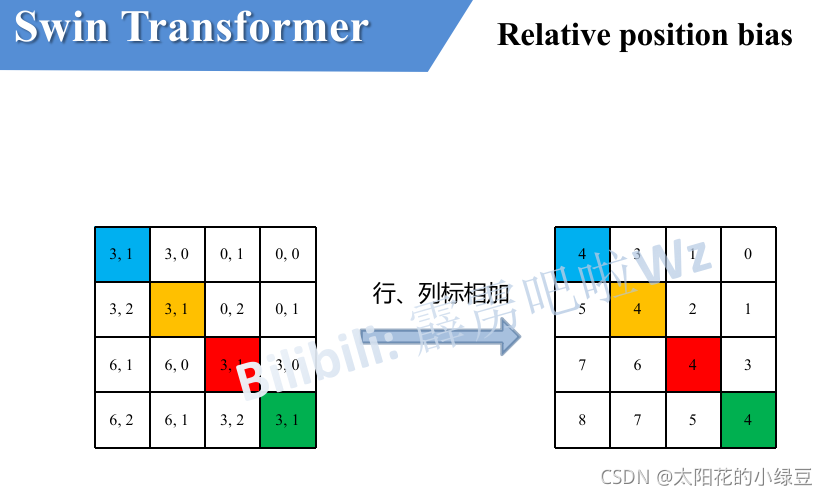
最后將行標和列標進行相加,這樣即保證了相對位置關系,而且不會出現上述
0
+
(
?
1
)
=
(
?
1
)
+
0
0+(-1)=(-1)+0
0+(?1)=(?1)+0的問題了,是不是很神奇,
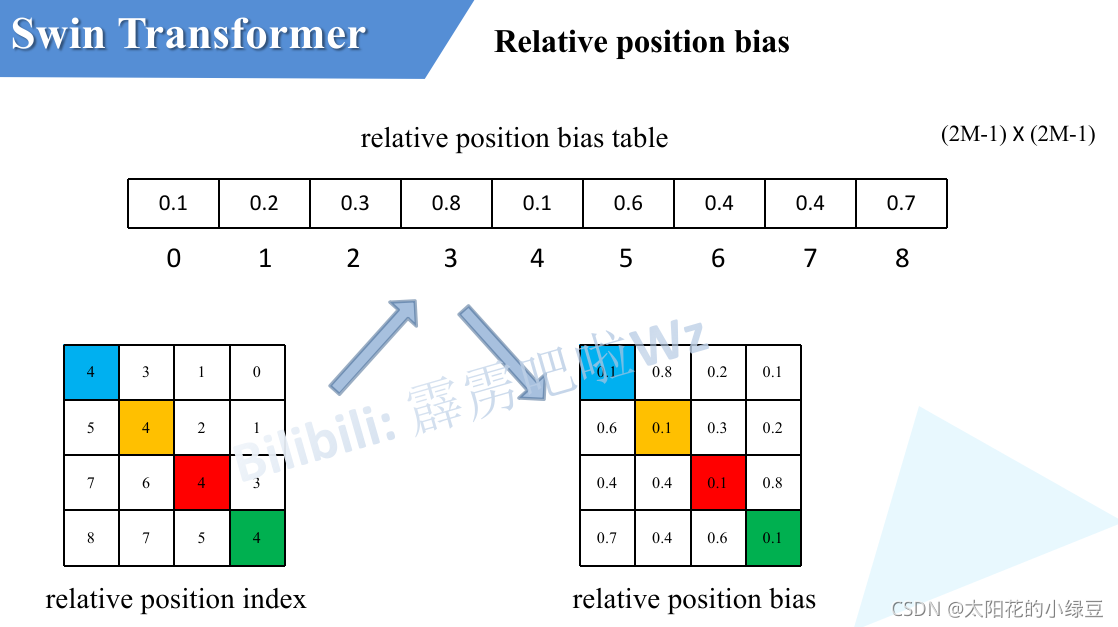
剛剛上面也說了,之前計算的是相對位置索引,并不是相對位置偏執引數,真正使用到的可訓練引數
B
^
\hat{B}
B^是保存在relative position bias table表里的,這個表的長度是等于
(
2
M
?
1
)
×
(
2
M
?
1
)
(2M-1) \times (2M-1)
(2M?1)×(2M?1)的,那么上述公式中的相對位置偏執引數B是根據上面的相對位置索引表根據查relative position bias table表得到的,如下圖所示,
6 模型詳細配置引數
首先回憶下Swin Transformer的網路架構:
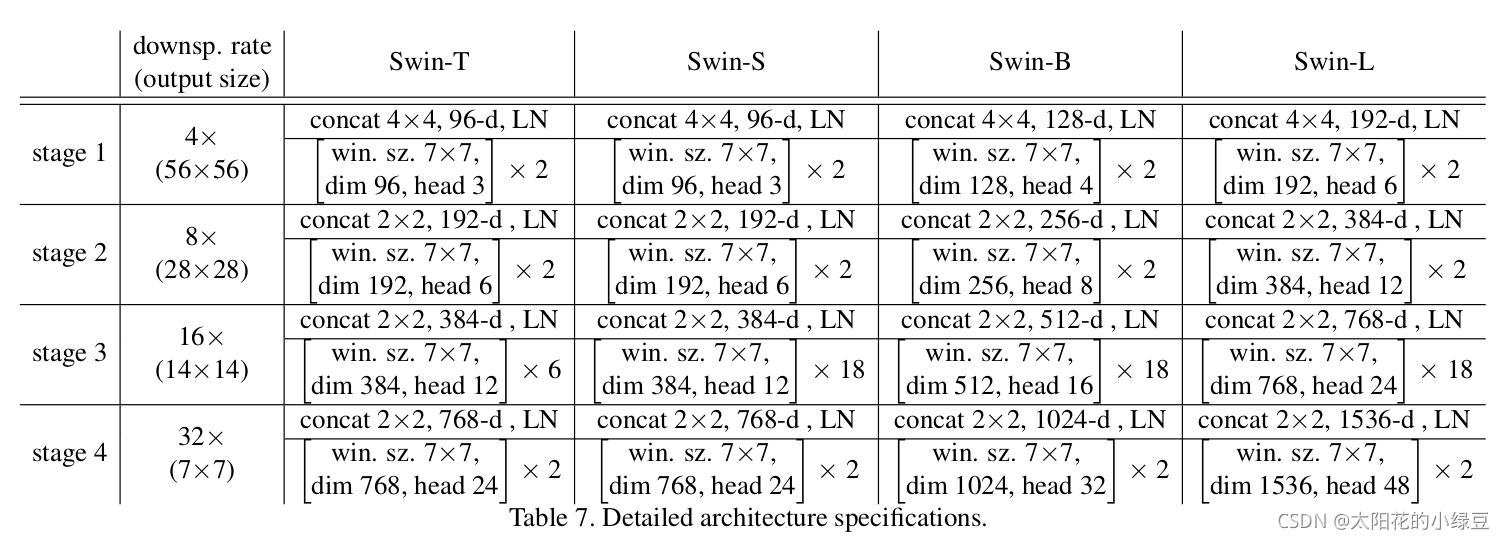
下圖(表7)是原論文中給出的關于不同Swin Transformer的配置,T(Tiny),S(Small),B(Base),L(Large),其中:
win. sz. 7x7表示使用的視窗(Windows)的大小dim表示feature map的channel深度(或者說token的向量長度)head表示多頭注意力模塊中head的個數
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/348387.html
標籤:其他
上一篇:深度學習100例 | 第53天:用YOLOv5訓練自己的資料集(超級詳細完整版)
下一篇:MQTT測驗環境搭建