李沐《動手學深度學習v2》學習筆記(二):線性回歸和實作
目錄:
- 李沐《動手學深度學習v2》學習筆記(二):線性回歸和實作
- 一、線性回歸概述
- 二、構建線性模型和優化演算法(Optimal)
- 1.最小二乘法(LSM)
- 2.梯度下降
- 2.1 批量梯度下降(BGD)
- 2.2 隨機梯度下降(SGD)
- 2.3 小批量隨機梯度下降(MBGD)
- 3.正則化
- 3.1 嶺回歸(Ridge Regression)—— L 2 L_2 L2?范數正則化
- 3.2 套索回歸(Lasso Regression)—— L 1 L_1 L1?范數正則化
- 三、手動構建線性回歸模型
- 1.制作人工資料集
- 2.實作小批量隨機抽樣
- 3.初始化模型
- 4.定義損失函式和優化演算法
- 5.訓練程序
- 四、利用PyTorch函式簡潔實作線性回歸
- 1.PyTorch資料集處理模塊
- 2.實作流程
一、線性回歸概述
什么是回歸問題?
- 有監督學習分為兩類,即分類和回歸問題,預測某一事物屬于哪一類別,屬于分類問題,如:貓狗分類;而當需要預測的內容是一個連續的值,屬于回歸問題,如:預測房價
什么是線性回歸?
- 線性回歸是回歸問題的一種,當輸出值與輸入值之間滿足線性關系時,即滿足方程: h ( x ) = w 1 x 1 + w 2 x 2 + . . . + w n x n + w 0 ( b ) h(x)=w_1x_1+w_2x_2+...+w_nx_n+w_0(b) h(x)=w1?x1?+w2?x2?+...+wn?xn?+w0?(b),稱為線性回歸
- 在二維平面中,它表現為一條直線,在多維空間中,它表現為一個超平面
- 在構建這個超平面時,我們需要使預測值與真實值之間的誤差最小化
符號約定:
| 符號 | 含義 |
|---|---|
| m m m | 訓練集中樣本的數量 |
| n n n | 特征的數量 |
| x x x | 樣本的特征變數/輸入變數 |
| y y y | 樣本的目標變數/輸出變數 |
| ( x , y ) (x,y) (x,y) | 訓練集中的樣本: ( 輸 入 變 量 , 輸 出 變 量 ) (輸入變數,輸出變數) (輸入變量,輸出變量) |
| ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i)) | 代表第 i i i 個觀察樣本的特征和輸出 |
| h h h | 代表學習演算法的解決方案或函式,也稱為假設(hypothesis) |
| y ^ = h ( x ) {\hat y}=h(x) y^?=h(x) | 代表預測值 |
例如:
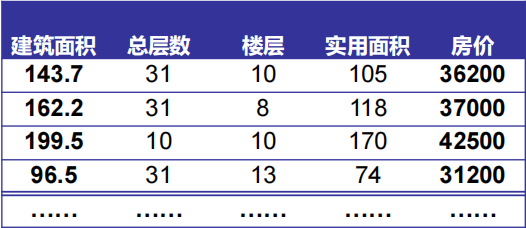
x
(
2
)
=
[
162.2
31
8
118
]
,
y
(
2
)
=
37000
,
x
2
(
2
)
=
31
,
x
3
(
2
)
=
8
x^{(2)}=\left[\begin{matrix}162.2\\31\\8\\118\end{matrix}\right],y^{(2)}=37000,x^{(2)}_2=31,x^{(2)}_3=8
x(2)=?????162.2318118??????,y(2)=37000,x2(2)?=31,x3(2)?=8
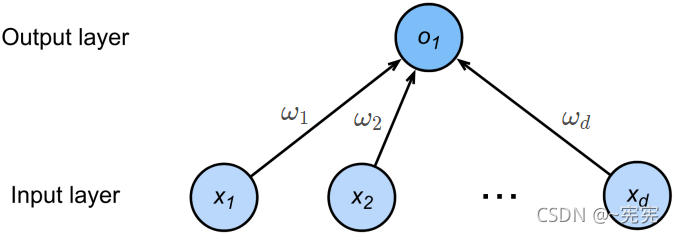
線性模型可以看作是一個單層神經網路(單層全連接層):
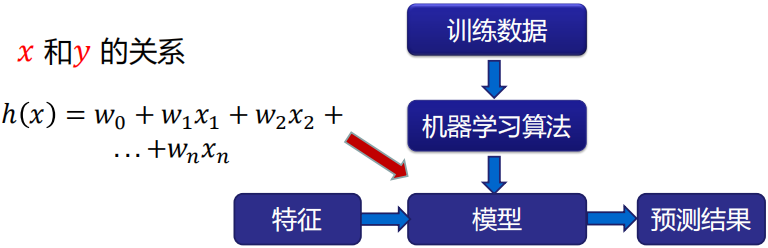
二、構建線性模型和優化演算法(Optimal)
構建線性模型的核心問題是找到: h ( x ) = w 1 x 1 + w 2 x 2 + . . . + w n x n + w 0 ( b ) h(x)=w_1x_1+w_2x_2+...+w_nx_n+w_0(b) h(x)=w1?x1?+w2?x2?+...+wn?xn?+w0?(b) 中的 w ( w 1 , w 2 , . . . , w n ) {\bf w}(w_1,w_2,...,w_n) w(w1?,w2?,...,wn?) 和 w 0 ( b ) w_0(b) w0?(b)
為了方便計算,可以設
x
0
=
1
x_0=1
x0?=1,則方程變為:
h
(
x
)
=
w
0
x
0
+
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
n
x
n
=
w
T
x
=
?
w
,
x
?
h(x)=w_0x_0+w_1x_1+w_2x_2+...+w_nx_n={\bf w}^T{\bf x}=\langle {\bf w},{\bf x}\rangle
h(x)=w0?x0?+w1?x1?+w2?x2?+...+wn?xn?=wTx=?w,x?
w i w_i wi? 的取值越大,線性模型越復雜
損失函式(Loss Function):
對學習結果的度量,度量單樣本預測的錯誤程度,損失函式值越小,模型就越好
| 損失函式名稱 | 損失函式定義 |
|---|---|
| 0-1損失函式 | L o s s ( y ( i ) , h ( x ( i ) ) ) = { 1 , h ( x ( i ) ) ≠ y ( i ) 0 , h ( x ( i ) ) = y ( i ) Loss(y^{(i)},h(x^{(i)}))=\begin{cases} 1, & h(x^{(i)}) \neq y^{(i)} \\ 0, & h(x^{(i)}) = y^{(i)} \end{cases} Loss(y(i),h(x(i)))={1,0,?h(x(i))?=y(i)h(x(i))=y(i)? |
| 平方損失函式 | L o s s ( y ( i ) , h ( x ( i ) ) ) = ( y ( i ) ? h ( x ( i ) ) ) 2 Loss(y^{(i)},h(x^{(i)}))=(y^{(i)}-h(x^{(i)}))^2 Loss(y(i),h(x(i)))=(y(i)?h(x(i)))2 |
| 絕對損失函式 | L o s s ( y ( i ) , h ( x ( i ) ) ) = ∣ y ( i ) ? h ( x ( i ) ) ∣ Loss(y^{(i)},h(x^{(i)}))=\mid y^{(i)}-h(x^{(i)})\mid Loss(y(i),h(x(i)))=∣y(i)?h(x(i))∣ |
| 對數損失函式/對數似然損失函式 | L o s s ( y ( i ) , P ( y ( i ) ∣ x i ) ) = ? l o g P ( ( y ( i ) ∣ x ( i ) ) ) Loss(y^{(i)},P(y^{(i)}\mid x_i))=-logP((y^{(i)}\mid x^{(i)})) Loss(y(i),P(y(i)∣xi?))=?logP((y(i)∣x(i))) |
代價函式: 度量對所有樣本集預測值的平均誤差,常用的代價函式包括均方誤差、均方根誤差、平均絕對誤差等
代價函式常常采用均方誤差 MSE \text{MSE} MSE: MSE = 1 m ∑ i = 1 m ( y ( i ) ? y ( i ) ^ ) 2 \text{MSE}={1 \over m}\sum_{i=1}^m(y^{(i)}-\hat {y^{(i)}})^2 MSE=m1?∑i=1m?(y(i)?y(i)^?)2,為方便計算,常定義為: J ( w ) = 1 2 m ∑ i = 1 m ( y ( i ) ? y ( i ) ^ ) 2 J({\bf w})={1 \over 2m}\sum_{i=1}^m(y^{(i)}-\hat {y^{(i)}})^2 J(w)=2m1?∑i=1m?(y(i)?y(i)^?)2
目標:要找到一組 w ( w 0 , w 1 , w 2 , . . . , w n ) {\bf w}(w_0,w_1,w_2,...,w_n) w(w0?,w1?,w2?,...,wn?),使得 MSE \text{MSE} MSE 具有最小值: m i n w ( 1 m ∑ i = 1 m ( y ( i ) ? y ( i ) ^ ) 2 ) min_{w}({1 \over m}\sum_{i=1}^m(y^{(i)}-\hat {y^{(i)}})^2) minw?(m1?∑i=1m?(y(i)?y(i)^?)2),那么,該如何尋找這一組 w {\bf w} w 呢?
1.最小二乘法(LSM)
很顯然,代價函式 J ( w ) = 1 2 m ∑ i = 1 m ( y ( i ) ^ ? y ( i ) ) 2 J({\bf w})={1 \over 2m}\sum_{i=1}^m(\hat {y^{(i)}}-y^{(i)})^2 J(w)=2m1?∑i=1m?(y(i)^??y(i))2 是一個二次函式,即它是一個凸函式,具有最小值
以二維
w
(
w
0
,
w
1
)
{\bf w}(w_0,w_1)
w(w0?,w1?) 為例,由不同的
(
w
0
,
w
1
)
(w_0,w_1)
(w0?,w1?) 可以得到不同的代價值,且代價函式可以找到最小值,如圖所示:
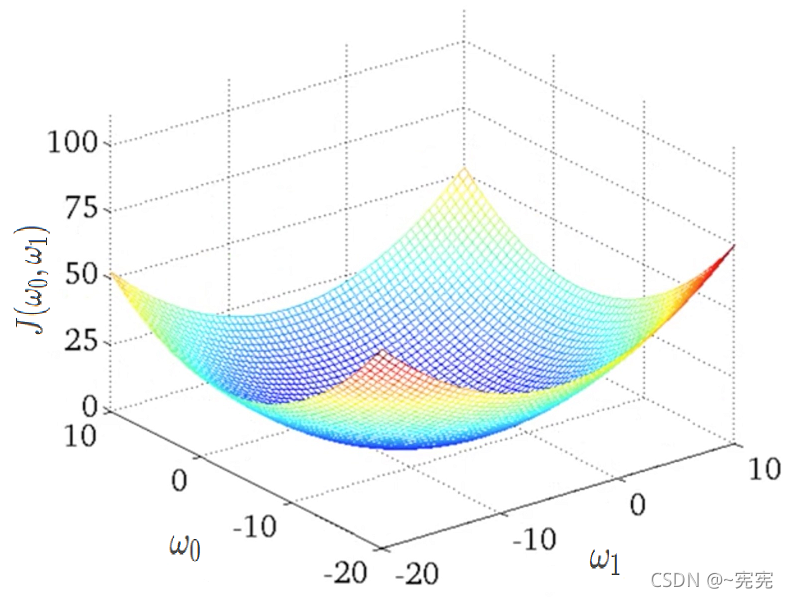
如果想要找到最小值,我們只需對代價函式求偏導,并令偏導數為
0
0
0(最小值點),對凸函式來說是可以找到決議解的:
令
?
J
(
w
0
,
w
1
)
?
w
0
=
1
m
∑
i
=
1
m
(
w
0
+
w
1
x
(
i
)
?
y
(
i
)
)
=
0
令 \ \frac{\partial J(w_0,w_1)}{\partial w_0}={1 \over m}\sum_{i=1}^m(w_0+w_1x^{(i)}-y^{(i)})=0
令 ?w0??J(w0?,w1?)?=m1?i=1∑m?(w0?+w1?x(i)?y(i))=0
令 ? J ( w 0 , w 1 ) ? w 1 = 1 m ∑ i = 1 m x ( i ) ( w 0 + w 1 x ( i ) ? y ( i ) ) = 0 令 \ \frac{\partial J(w_0,w_1)}{\partial w_1}={1 \over m}\sum_{i=1}^mx^{(i)}(w_0+w_1x^{(i)}-y^{(i)})=0 令 ?w1??J(w0?,w1?)?=m1?i=1∑m?x(i)(w0?+w1?x(i)?y(i))=0
解 得 : w 0 = 1 m ∑ i = 1 m ( y ( i ) ? w 1 x ( i ) ) , w 1 = ∑ i = 1 m y ( i ) ( x ( i ) ? x  ̄ ) ∑ i = 1 n ( x ( i ) ) 2 ? 1 m ( ∑ i = 1 m x ( i ) ) 2 解得:w_0={1 \over m}\sum_{i=1}^m(y^{(i)}-w_1x^{(i)}),w_1={\sum_{i=1}^my^{(i)}(x^{(i)}-\overline{x}) \over \sum_{i=1}^n(x^{(i)})^2-{1 \over m}(\sum_{i=1}^mx^{(i)})^2} 解得:w0?=m1?i=1∑m?(y(i)?w1?x(i)),w1?=∑i=1n?(x(i))2?m1?(∑i=1m?x(i))2∑i=1m?y(i)(x(i)?x)?
2.梯度下降
梯度: 它是一個矢量,對一元函式來說,梯度就是函式的導數;對多元函式來說,多元函式 f ( x ) f(x) f(x) 在某一點處的梯度表示 f ( x ) f(x) f(x) 在該點處的最大方向導數,其方向為具有最大增長率的方向,那么梯度的反方向就是函式值下降率最大的方向
梯度下降的目標仍然是希望找到代價函式 J ( w 0 , w 1 , . . . , w n ) J(w_0,w_1,...,w_n) J(w0?,w1?,...,wn?) 的最小值,比 LSM \text{LSM} LSM 更好的是,梯度下降法可以應用于更一般的函式,而不只是凸函式
利用梯度下降,我們可以在代價函式的某一點處開始,根據梯度的反方向,逐漸修改
(
w
0
,
w
1
,
.
.
.
,
w
n
)
(w_0,w_1,...,w_n)
(w0?,w1?,...,wn?),來使代價函式值逐漸減小
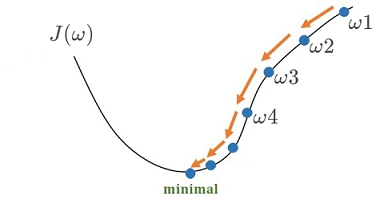
梯度下降的數學定義:
w = ( w 0 , w 1 , . . . , w n ) w=(w_0,w_1,...,w_n) w=(w0?,w1?,...,wn?),里面第 i i i 個元素用 w i w_i wi? 來表示,則:
w i = w i ? α ? ? w i J ( w 0 , w 1 , . . . , w n ) , for i=0 to i=n ? 不斷重復,直到收斂 \underbrace{{w_i}=w_i-\alpha\frac{\partial }{\partial w_i}J(w_0,w_1,...,w_n),\text{for i=0 to i=n}}_{\rm \text{不斷重復,直到收斂}} 不斷重復,直到收斂 wi?=wi??α?wi???J(w0?,w1?,...,wn?),for i=0 to i=n??
-
w
i
{w_i}
wi?:表示對
w
w
w 中的第
i
i
i 個自變數進行更新,在一個回圈內,所有對
w
i
w_i
wi? 的更新必須是同步的
注: w i w_i wi? 值不是立刻更新,而是當計算完所有 w i w_i wi? 的更新值后再同時統一賦值,或者說計算和更新的程序都是同步的 - α \alpha α:表示學習率,它反映了每次更新 w i w_i wi? 值的跨度率
- ? ? w i J ( w 0 , w 1 , . . . , w n ) \frac{\partial }{\partial w_i}J(w_0,w_1,...,w_n) ?wi???J(w0?,w1?,...,wn?):表示代價函式對 w w w 中的 w i w_i wi? 進行偏微分
- α ? ? w i J ( w 0 , w 1 , . . . , w n ) \alpha\frac{\partial }{\partial w_i}J(w_0,w_1,...,w_n) α?wi???J(w0?,w1?,...,wn?):表示每次更新的步長
- 因為梯度下降需要確定在代價函式中的某一個點處開始執行,因此需要給定一初始值,通常取 w 0 , w 1 , . . . , w n = 0 w_0,w_1,...,w_n=0 w0?,w1?,...,wn?=0 開始
上述公式表明:
- 如果代價函式對 w i w_i wi? 的偏微分小于零,表示沿著 w i w_i wi? 的正方向會使代價函式變小,因此我們可以選擇增大 w i w_i wi? 的值,具體增大 ? α ? ? w i J ( w 0 , w 1 , . . . , w n ) -\alpha\frac{\partial }{\partial w_i}J(w_0,w_1,...,w_n) ?α?wi???J(w0?,w1?,...,wn?);
- 如果代價函式對 ω i \omega_i ωi? 的偏微分大于零,表示沿著 ω i \omega_i ωi? 的正方向會使代價函式變大,因此我們可以選擇減小 w i w_i wi? 的值,具體減小 α ? ? w i J ( w 0 , w 1 , . . . , w n ) \alpha\frac{\partial }{\partial w_i}J(w_0,w_1,...,w_n) α?wi???J(w0?,w1?,...,wn?)
- 如果代價函式對 w i w_i wi? 的偏微分等于零,則修正項為零,則不需要修改 w i w_i wi? 的值
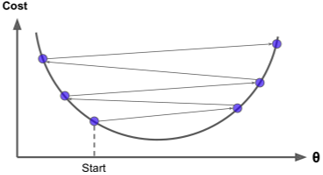
- 現在我們討論學習率
α
\alpha
α:如果
α
\alpha
α 太高可能導致無法找到合適解(左圖),如果
α
\alpha
α 太低可能導致學習速度過于緩慢(右圖)
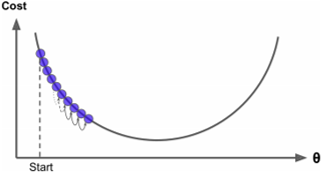
梯度下降法具有三種模式,即批量梯度下降、隨機梯度下降和小批量梯度下降
2.1 批量梯度下降(BGD)
批量梯度下降在計算代價函式的梯度時,考慮了所有的訓練樣本,代價函式:
J
(
w
)
=
1
2
m
∑
j
=
1
m
(
y
(
j
)
^
?
y
(
j
)
)
2
J({\bf w})={1 \over 2m}\sum_{j=1}^m(\hat {y^{(j)}}-y^{(j)})^2
J(w)=2m1?∑j=1m?(y(j)^??y(j))2,
m
m
m 為樣本個數,因此
w
i
w_i
wi? 為:
w
i
=
w
i
?
α
1
m
∑
j
=
1
m
x
i
(
j
)
(
y
(
j
)
^
?
y
(
j
)
)
=
w
i
?
α
1
m
∑
j
=
1
m
x
i
(
j
)
(
?
w
,
x
?
?
y
(
j
)
)
{w_i}=w_i-\alpha{1 \over m}\sum_{j=1}^mx^{(j)}_i\left(\hat {y^{(j)}}-y^{(j)}\right)=w_i-\alpha{1 \over m}\sum_{j=1}^mx^{(j)}_i\left(\langle {\bf w},{\bf x}\rangle-y^{(j)}\right)
wi?=wi??αm1?j=1∑m?xi(j)?(y(j)^??y(j))=wi??αm1?j=1∑m?xi(j)?(?w,x??y(j))
特點:
- 計算梯度的每一步都基于完整訓練集
- 訓練集規模龐大時演算法速度很慢
- 特征數量多時,比標準方程快得多
- 適合樣本數規模適中,特征規模很大的資料集
2.2 隨機梯度下降(SGD)
隨機梯度下降每一次更新
ω
\omega
ω 時,隨機選擇一個訓練樣本來計算代價函式的梯度,設選擇了第
j
j
j 個訓練樣本:
w
i
=
w
i
?
α
1
m
x
i
(
j
)
(
y
(
j
)
^
?
y
(
j
)
)
=
w
i
?
α
x
i
(
j
)
(
?
w
,
x
?
?
y
(
j
)
)
{w_i}=w_i-\alpha{1 \over m}x^{(j)}_i\left(\hat {y^{(j)}}-y^{(j)}\right)=w_i-\alpha x^{(j)}_i\left(\langle {\bf w},{\bf x}\rangle-y^{(j)}\right)
wi?=wi??αm1?xi(j)?(y(j)^??y(j))=wi??αxi(j)?(?w,x??y(j))
特點:
- 計算速度更快
- 成本函式的下降變得不規則,但總體是下降的
- 最侄訓接近最小值(還會反彈)
批量梯度下降(左圖),隨機梯度下降(右圖):
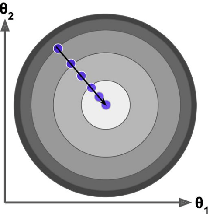
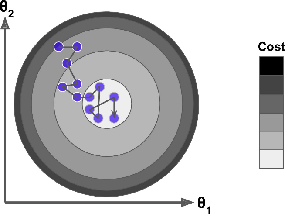
2.3 小批量隨機梯度下降(MBGD)
小批量梯度下降結合了(一)(二)各自的優點,既不使用所有樣本,也不使用單個樣本,而是隨機選擇小批量樣本
每次計算代價函式時使用
b
b
b 個樣本,其中
k
k
k 表示第
k
(
k
<
m
)
k(k<m)
k(k<m) 個樣本:
w
i
=
w
i
?
α
1
b
∑
j
=
1
b
x
i
(
k
)
(
y
(
k
)
^
?
y
(
k
)
)
=
w
i
?
α
1
b
∑
j
=
1
b
x
i
(
k
)
(
?
w
,
x
?
?
y
(
k
)
)
{w_i}=w_i-\alpha{1 \over b}\sum_{j=1}^bx_i^{(k)}\left(\hat {y^{(k)}}-y^{(k)}\right)=w_i-\alpha{1 \over b}\sum_{j=1}^bx_i^{(k)}\left(\langle {\bf w},{\bf x}\rangle-y^{(k)}\right)
wi?=wi??αb1?j=1∑b?xi(k)?(y(k)^??y(k))=wi??αb1?j=1∑b?xi(k)?(?w,x??y(k))
- b = 1 b=1 b=1(隨機梯度下降,SGD)
- b = m b=m b=m(批量梯度下降,BGD)
- b = batch_size b=\text{\tt batch\_size} b=batch_size,通常是 2 \tt 2 2 的指數倍,常見的有 32 , 64 , 128 \tt 32,64,128 32,64,128 等(小批量梯度下降,MBGD)
其性能介于隨機和批量之間,其中,選擇的批量數不能太小,這樣會導致每次計算量太小,不適合并行來最大利用計算資源,批量數也不能太大,這樣會導致記憶體消耗增加,浪費計算
梯度下降存在的缺陷:
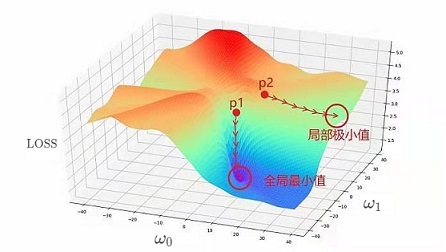
- 缺陷1:可能只找到區域最優解
解決方法:多次實驗,并隨機設定初始點(超引數),線性回歸的 MSE \text{MSE} MSE 代價函式只有一個最小值 - 缺陷2:對屬性尺度敏感,即在屬性尺度大的維度上下降得更快,尺度小的維度上下降緩慢
解決方法:屬性縮放
屬性縮放:
(一)歸一化(最大-最小規范化):
x
′
=
x
?
x
m
i
n
x
m
a
x
?
x
m
i
n
x'={x-x_{min} \over x_{max}-x_{min}}
x′=xmax??xmin?x?xmin??
將資料映射到 [ 0 , 1 ] [0,1] [0,1] 區間內,資料歸一化的目的是使得各特征對目標變數的影響一致,會將特征資料進行伸縮變化,所以資料歸一化是會改變特征資料分布的
(二)Z-Score 標準化:
x
′
=
x
?
μ
σ
x'={x-\mu \over \sigma}
x′=σx?μ?
其 中 σ 2 = 1 m ∑ i = 1 m ( x ( i ) ) 2 , μ = 1 m ∑ i = 1 m x ( i ) 其中 \ \sigma^2={1 \over m}\sum_{i=1}^m(x^{(i)})^2,\mu={1 \over m}\sum_{i=1}^mx^{(i)} 其中 σ2=m1?i=1∑m?(x(i))2,μ=m1?i=1∑m?x(i)
處理后的資料均值為 0 0 0,方差為 1 1 1,資料標準化為了不同特征之間具備可比性,經過標準化變換之后的特征資料分布沒有發生改變
3.正則化
當特征不足或者現有特征與樣本標簽的相關性不強時,模型容易出現欠擬合,通過挖掘組合特征等新的特征,往往能夠取得更好的效果
簡單模型的學習能力較差,通過增加模型的復雜度可以使模型擁有更強的擬合能力,如:在線性模型中添加高次項,使得線性模型變為曲線,又比如在神經網路模型中增加網路層數或神經元個數等,但模型過于復雜容易出現過擬合
而正則化就是是用來防止過擬合的,在經驗風險上加上與模型復雜度有關的正則化項或懲罰項,但當模型出現欠擬合現象時,則需要有針對性地減小正則化系數

線性回歸模型的兩種正則化項:
3.1 嶺回歸(Ridge Regression)—— L 2 L_2 L2?范數正則化
J ( w ) = 1 2 m ∑ i = 1 m ( ? w , x ? ? y ( i ) ) 2 + 1 2 λ ∑ j = 1 n w j 2 , ( λ > 0 ) J({\bf w})={1 \over 2m}\sum_{i=1}^m\left(\langle{\bf w},{\bf x}\rangle-y^{(i)}\right)^2+{1 \over 2}\lambda\sum_{j=1}^nw_j^2,(\lambda >0) J(w)=2m1?i=1∑m?(?w,x??y(i))2+21?λj=1∑n?wj2?,(λ>0)
w i w_i wi? 的取值越大,線性模型越復雜,其中 ∑ j = 1 n w j 2 \sum_{j=1}^nw_j^2 ∑j=1n?wj2? 正是度量了線性模型的復雜度,為使代價函式 J ( w ) J({\bf w}) J(w) 更小,應使 λ ∑ j = 1 n w j 2 \lambda\sum_{j=1}^nw_j^2 λ∑j=1n?wj2? 盡量小,使 w ( w 0 , w 1 , w 2 , . . . , w n ) {\bf w}(w_0,w_1,w_2,...,w_n) w(w0?,w1?,w2?,...,wn?) 中的元素盡量小(接近零)
? ? w i J ( w ) = 1 m ∑ j = 1 m x i ( j ) ( ? w , x ? ? y ( j ) ) + λ w i , ( λ > 0 ) \frac{\partial }{\partial w_i}J({\bf w})={1 \over m}\sum_{j=1}^mx^{(j)}_i\left(\langle {\bf w},{\bf x}\rangle-y^{(j)}\right)+\lambda w_i,(\lambda>0) ?wi???J(w)=m1?j=1∑m?xi(j)?(?w,x??y(j))+λwi?,(λ>0)
3.2 套索回歸(Lasso Regression)—— L 1 L_1 L1?范數正則化
J ( w ) = 1 2 m ∑ i = 1 m ( ? w , x ? ? y ( i ) ) 2 + λ ∑ j = 1 n ∣ w j ∣ , ( λ > 0 ) J({\bf w})={1 \over 2m}\sum_{i=1}^m\left(\langle {\bf w},{\bf x}\rangle-y^{(i)}\right)^2+\lambda\sum_{j=1}^n\mid w_j\mid,(\lambda >0) J(w)=2m1?i=1∑m?(?w,x??y(i))2+λj=1∑n?∣wj?∣,(λ>0)
在套索回歸中,通過 ∑ j = 1 n ∣ w j ∣ \sum_{j=1}^n\mid w_j\mid ∑j=1n?∣wj?∣ L 1 L_1 L1? 范數度量了線性模型的復雜度,為使代價函式 J ( w ) J({\bf w}) J(w) 更小,應使 λ ∑ j = 1 n ∣ w j ∣ \lambda\sum_{j=1}^n\mid w_j\mid λ∑j=1n?∣wj?∣ 盡量小,使 w ( w 0 , w 1 , w 2 , . . . , w n ) {\bf w}(w_0,w_1,w_2,...,w_n) w(w0?,w1?,w2?,...,wn?) 中的元素盡量小(接近零)
注: Lasso \text{Lasso} Lasso 回歸的代價函式 J ( w ) J({\bf w}) J(w) 不是連續可導的(帶絕對值),無法直接應用梯度下降
三、手動構建線性回歸模型
匯入所需的庫:
%matplotlib inline
import random # 用于隨機梯度下降、隨機初始化權重
import torch
1.制作人工資料集
首先,構造一個帶有噪聲的線性模型(人造資料集),我們使用線性模型引數 w = [ 2 ? 3.4 ] T {\bf w}=\left[\begin{matrix}2&-3.4\end{matrix}\right]^T w=[2??3.4?]T, b ( w 0 ) = 4.2 b(w_0)=4.2 b(w0?)=4.2 和噪聲項 ? \epsilon ? 生成資料集及其標簽: y = x w + b + ? {\bf y}={\bf xw}+b+? y=xw+b+?
def synthetic_data(w, b, num_examples):
"""生成 y = xw + b + 噪聲"""
X = torch.normal(0, 1, (num_examples, len(w))) # 生成服從 μ=0,σ=1 正態分布的隨機值
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
print('features:', features[0:10], '\n','labels:', labels[0:10]) # 查看生成的結果
分析呼叫 features, labels = synthetic_data(true_w, true_b, 1000):
傳入引數: w = [ 2 ? 3.4 ] , b ( w 0 ) = 4.2 {\bf w}=\left[\begin{matrix}2&-3.4\end{matrix}\right],b(w_0)=4.2 w=[2??3.4?],b(w0?)=4.2, n u m _ e x a m p l e s = 1000 ( 樣 本 數 ) {\tt num\_examples=1000}(樣本數) num_examples=1000(樣本數)
-
X = torch.normal(0, 1, (num_examples, len(w)))生成了服從 μ = 0 , σ = 1 \mu=0,\sigma=1 μ=0,σ=1 正態分布的隨機值張量,作為樣本的輸入:
X = [ x 1 ( 1 ) x 2 ( 1 ) x 1 ( 2 ) x 2 ( 2 ) ? ? x 1 ( 1000 ) x 2 ( 1000 ) ] 1000 × 2 , n u m _ e x a m p l e s = 1000 , l e n ( w ) = 2 {\bf X} =\left[\begin{matrix}x_1^{(1)}&x_2^{(1)}\\x_1^{(2)}&x_2^{(2)}\\\vdots&\vdots\\x_1^{(1000)}&x_2^{(1000)}\end{matrix}\right]_{1000×2},{\tt num\_examples=1000},{\tt len(w)=2} X=???????x1(1)?x1(2)??x1(1000)??x2(1)?x2(2)??x2(1000)?????????1000×2?,num_examples=1000,len(w)=2 -
y = torch.matmul(X, w) + b形成與 X X X 具有線性關系的因變數 y {\bf y} y,作為樣本的輸出,即:
y = ? X , w ? + b = [ x 1 ( 1 ) x 2 ( 1 ) x 1 ( 2 ) x 2 ( 2 ) ? ? x 1 ( 1000 ) x 2 ( 1000 ) ] [ 2 ? 3.4 ] + b = [ 2 x 1 ( 1 ) ? 3.4 x 2 ( 1 ) + b 2 x 1 ( 2 ) ? 3.4 x 2 ( 2 ) + b ? 2 x 1 ( 1000 ) ? 3.4 x 2 ( 1000 ) + b ] 1000 × 1 = [ y ( 1 ) y ( 2 ) ? y ( 1000 ) ] 1000 × 1 {\bf y} =\langle{\bf X},{\bf w}\rangle+b =\left[\begin{matrix}x_1^{(1)}&x_2^{(1)}\\x_1^{(2)}&x_2^{(2)}\\\vdots&\vdots\\x_1^{(1000)}&x_2^{(1000)}\end{matrix}\right]\left[\begin{matrix}2\\-3.4\end{matrix}\right]+b =\left[\begin{matrix}2x_1^{(1)}-3.4x_2^{(1)}+b\\2x_1^{(2)}-3.4x_2^{(2)}+b\\\vdots\\2x_1^{(1000)}-3.4x_2^{(1000)}+b\end{matrix}\right]_{1000×1}=\left[\begin{matrix}y^{(1)}\\y^{(2)}\\\vdots\\y^{(1000)}\end{matrix}\right]_{1000×1} y=?X,w?+b=???????x1(1)?x1(2)??x1(1000)??x2(1)?x2(2)??x2(1000)?????????[2?3.4?]+b=???????2x1(1)??3.4x2(1)?+b2x1(2)??3.4x2(2)?+b?2x1(1000)??3.4x2(1000)?+b????????1000×1?=??????y(1)y(2)?y(1000)???????1000×1?
注意:回傳的是 s h a p e = ( 1000 ) \tt shape=(1000) shape=(1000) 的張量,需要進行 r e s h a p e ( ? 1 , 1 ) \tt reshape(-1, 1) reshape(?1,1) -
y += torch.normal(0, 0.01, y.shape)分別為 y {\bf y} y 中的每一項加入了 μ = 0 , σ = 0.01 \mu=0,\sigma=0.01 μ=0,σ=0.01 的高斯白噪聲
查看前十個資料集,每個樣本包含一個二維
f
e
a
t
u
r
e
s
\tt features
features:
x
(
x
1
,
x
2
)
{\bf x(x_1,x_2)}
x(x1?,x2?) 和一個輸出值
l
a
b
e
l
s
\tt labels
labels:

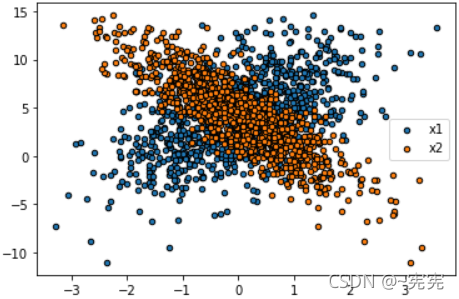
# 繪制散點圖,進一步觀察資料集,散點大小為 20,邊界為黑色邊界
plt.scatter(features[:, 0], labels, label = 'x1', s=20, edgecolor="black")
plt.scatter(features[:, 1], labels, label = 'x2', s=20, edgecolor="black")
"""
注意,有些版本需要從計算圖上分離出來,并將tensor轉換為numpy陣列,才能繪圖
plt.scatter(features[:, 0].detach().numpy(), labels.detach().numpy(), label = 'x1')
plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), label = 'x2')
"""
plt.legend()
2.實作小批量隨機抽樣
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i:min(i + batch_size, num_examples)])
print('indices[{:},{:}]'.format(i, i + batch_size))
yield features[batch_indices], labels[batch_indices]
batch_size = 10 # 定義批量數大小
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
batch_size = 10 定義批量數大小為
10
10
10,則可以以
10
10
10 個樣本為一組,分成
100
100
100 組,再隨機抽樣
分析呼叫 data_iter(batch_size, features, labels):
傳入引數 b a t c h _ s i z e = 10 \tt batch\_size=10 batch_size=10,即每次小批量梯度下降的批量數為 10 10 10, f e a t u r e s : ( 1000 , 2 ) \tt features:(1000,2) features:(1000,2), l a b e l s : ( 1000 , 1 ) \tt labels:(1000,1) labels:(1000,1)
num_examples = len(features)統計樣本數,樣本數為 1000 1000 1000indices = list(range(num_examples))生成從 0 0 0 到 999 999 999 的順序整數串列random.shuffle(indices)將陣列indices順序隨機打亂for i in range(0, num_examples, batch_size):從 0 0 0 到 999 999 999 每隔 10 10 10 步取一個 i i i- 在
batch_indices = torch.tensor(indices[i:min(i + batch_size, num_examples)])中:
indices[i:i + batch_size]表示每次從亂序陣列中取 10 10 10 個作為一個小批量;
min(i + batch_size, num_examples)是為了防止取數時超出亂序陣列的右邊界(這里似乎沒必要);
torch.tensor將每次得到的 10 10 10 個亂數作為張量,如: t e n s o r ( [ 96 , 731 , 147 , 654 , 2 , 341 , 455 , 214 , 203 , 81 ] ) \tt tensor([96, 731, 147, 654, 2, 341, 455, 214, 203, 81]) tensor([96,731,147,654,2,341,455,214,203,81]) features[batch_indices], labels[batch_indices],用張量在features和labels中可以分別取到 10 10 10 個樣本yield是 Python 的迭代器,是一種函式的回傳值,每當函式運行到yield關鍵字時,都會回傳一組資料,保留函式運行節點并退出函式運行,在下次呼叫時,將從上一保留的節點繼續運行函式,可以多次呼叫該函式,得到不同的回傳值

利用 for 回圈,會多次呼叫 data_iter() 函式,根據迭代器依次回傳
100
100
100 組小批量樣本,每個小批量為
10
10
10,這里僅展示一組
3.初始化模型
def linreg(X, w, b):
"""線性回歸模型"""
return torch.matmul(X, w) + b
# 給定模型的超引數(初始值)
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
4.定義損失函式和優化演算法
損失函式:
def squared_loss(y_hat, y):
"""使用均方誤差損失函式"""
return (y_hat - y.reshape(y_hat.shape))**2 / 2
引數: y _ h a t \tt y\_hat y_hat、 y \tt y y 分別代表預測值 y ^ \hat y y^? 和真實值 y y y
y.reshape(y_hat.shape):雖然 y ^ \hat y y^? 和 y y y 可能都只是一個元素,但為了統一起見,將 y y y 統一形狀- 這里不進行求和,即不考慮 1 m ∑ i = 1 m {1 \over m}\sum_{i=1}^m m1?∑i=1m?
優化演算法:
def sgd(params, lr):
"""小批量隨機梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad
param.grad.zero_()
引數: p a r a m s \tt params params 代表一個包含 w {\bf w} w 和 b b b 的串列(即需要更新的引數), l r \tt lr lr 代表學習率
for param in params:這里的運算將不放入計算圖param -= lr * param.grad即代表 w i = w i ? ? ? w i J ( w 1 , w 2 , b ) w_i = w_i-\frac{\partial }{\partial w_i}J(w_1,w_2,b) wi?=wi???wi???J(w1?,w2?,b)param.grad.zero_()梯度清零,這樣下一次計算梯度的時候就不會和上一次計算相關了
5.訓練程序
lr = 0.03 # 學習率為 0.03
num_epochs = 3 # 訓練次數為 3
net = linreg # net 參考 linreg
loss = squared_loss # loss 參考 squared_loss
for epoch in range(num_epochs): # 訓練輪次
for X, y in data_iter(batch_size, features, labels): # 當所有樣本走完一次后,作為一次訓練完成
l = loss(net(X, w, b), y) # 計算小批量的損失
(l.sum() / batch_size).backward() # 計算梯度
sgd([w, b], lr) # 梯度下降,更新引數
with torch.no_grad():
train_l = loss(net(features, w, b), labels) # 每個 epoch 列印一次損失值
print('epoch {:}, loss {:f}'.format(epoch + 1, float(train_l.mean())))

主函式解釋:
net(X, w, b) 回傳值為:
r
e
t
u
r
n
=
[
x
1
(
1
)
x
2
(
1
)
x
1
(
2
)
x
2
(
2
)
?
?
x
1
(
10
)
x
2
(
10
)
]
[
w
1
w
2
]
+
b
=
[
w
1
x
1
(
1
)
+
w
2
x
2
(
1
)
+
b
w
1
x
1
(
2
)
+
w
2
x
2
(
2
)
+
b
?
w
1
x
1
(
10
)
+
w
2
x
2
(
10
)
+
b
]
=
[
y
^
(
1
)
y
^
(
2
)
?
y
^
(
10
)
]
{\tt return} =\left[\begin{matrix}x_1^{(1)}&x_2^{(1)}\\x_1^{(2)}&x_2^{(2)}\\\vdots&\vdots\\x_1^{(10)}&x_2^{(10)}\end{matrix}\right] \left[\begin{matrix}w_1\\w_2\end{matrix}\right]+b =\left[\begin{matrix}w_1x_1^{(1)}+w_2x_2^{(1)}+b\\w_1x_1^{(2)}+w_2x_2^{(2)}+b\\\vdots\\w_1x_1^{(10)}+w_2x_2^{(10)}+b\end{matrix}\right] =\left[\begin{matrix}\hat y^{(1)}\\\hat y^{(2)}\\\vdots\\\hat y^{(10)}\end{matrix}\right]
return=???????x1(1)?x1(2)??x1(10)??x2(1)?x2(2)??x2(10)?????????[w1?w2??]+b=???????w1?x1(1)?+w2?x2(1)?+bw1?x1(2)?+w2?x2(2)?+b?w1?x1(10)?+w2?x2(10)?+b????????=??????y^?(1)y^?(2)?y^?(10)???????
l = loss(net(X, w, b), y) 的回傳值為:
r
e
t
u
r
n
=
1
2
(
[
y
^
(
1
)
y
^
(
2
)
?
y
^
(
10
)
]
?
[
y
(
1
)
y
(
2
)
?
y
(
10
)
]
)
2
=
[
l
o
s
s
(
1
)
l
o
s
s
(
2
)
?
l
o
s
s
(
10
)
]
{\tt return} ={1 \over 2}\left(\left[\begin{matrix}\hat y^{(1)}\\\hat y^{(2)}\\\vdots\\\hat y^{(10)}\end{matrix}\right]- \left[\begin{matrix}y^{(1)}\\y^{(2)}\\\vdots\\y^{(10)}\end{matrix}\right]\right)^2 =\left[\begin{matrix}loss^{(1)}\\loss^{(2)}\\\vdots\\loss^{(10)}\end{matrix}\right]
return=21?????????????y^?(1)y^?(2)?y^?(10)??????????????y(1)y(2)?y(10)?????????????2=??????loss(1)loss(2)?loss(10)???????
由于 J ( w ) = 1 2 × 10 ∑ j = 1 10 ( y ( j ) ^ ? y ( j ) ) 2 J({\bf w})={1 \over 2×10}\sum_{j=1}^{10}(\hat {y^{(j)}}-y^{(j)})^2 J(w)=2×101?∑j=110?(y(j)^??y(j))2,而這里是樣本各自的損失,因此下一步需要先求和,除以 b a t c h _ s i z e \tt batch\_size batch_size,再求梯度
(l.sum() / batch_size).backward() 進行的操作是:
J
(
w
)
=
(
[
l
o
s
s
(
1
)
l
o
s
s
(
2
)
?
l
o
s
s
(
10
)
]
.
s
u
m
(
)
)
1
b
a
t
c
h
_
s
i
z
e
=
1
2
×
10
∑
j
=
1
10
(
y
(
j
)
^
?
y
(
j
)
)
2
J({\bf w})=\left(\left[\begin{matrix}loss^{(1)}\\loss^{(2)}\\\vdots\\loss^{(10)}\end{matrix}\right]{\tt .sum()}\right){1 \over {\tt batch\_size}}={1 \over 2×10}\sum_{j=1}^{10}(\hat {y^{(j)}}-y^{(j)})^2
J(w)=????????????loss(1)loss(2)?loss(10)???????.sum()??????batch_size1?=2×101?j=1∑10?(y(j)^??y(j))2
J ( w ) . b a c k w a r d ( ) ?? ? ?? ? J ( w ) ? w i = [ ? J ( w ) ? w 1 ? J ( w ) ? w 2 ? J ( w ) ? b ] J({\bf w}){\tt .backward()}\implies\frac{\partial J({\bf w})}{\partial w_i} =\left[\begin{matrix}\frac{\partial J({\bf w})}{\partial w_1}\\\frac{\partial J({\bf w})}{\partial w_2}\\\frac{\partial J({\bf w})}{\partial b}\end{matrix}\right] J(w).backward()??wi??J(w)?=?????w1??J(w)??w2??J(w)??b?J(w)??????
sgd([w, b], lr) 則實作了引數的更新
訓練效果:
print('w的估計誤差: {:}'.format(true_w - w.reshape(true_w.shape)))
print('b的估計誤差: {:}'.format(true_b - b))

發現
w
1
w_1
w1?、
w
2
w_2
w2? 誤差分別為
?
0.0002
-0.0002
?0.0002、
0.0002
0.0002
0.0002,
b
b
b 的誤差為
0.0002
0.0002
0.0002,誤差較小
四、利用PyTorch函式簡潔實作線性回歸
1.PyTorch資料集處理模塊
匯入所需的庫:
import torch.utils as data # 包含一些資料處理的模塊
train_ids = data.TensorDataset(tuple) 將 資料data 和 標簽label 張量進行打包,打包后通過
DataLoader()函式獲取資料
d a t a = [ x 1 ( 1 ) x 2 ( 1 ) ? x n ( 1 ) x 1 ( 2 ) x 2 ( 2 ) ? x n ( 2 ) ? ? ? ? x 1 ( i ) x 2 ( i ) ? x n ( i ) ] i × n , l a b e l = [ y ( 1 ) y ( 2 ) ? y ( i ) ] {\tt data}= \left[\begin{matrix}x_1^{(1)}&x_2^{(1)}&\cdots&x_n^{(1)}\\ x_1^{(2)}&x_2^{(2)}&\cdots&x_n^{(2)}\\ \vdots&\vdots&\ddots&\vdots\\ x_1^{(i)}&x_2^{(i)}&\cdots&x_n^{(i)}\end{matrix}\right]_{i×n}, {\tt label}= \left[\begin{matrix}y^{(1)}\\y^{(2)}\\\vdots\\y^{(i)}\end{matrix}\right] data=???????x1(1)?x1(2)??x1(i)??x2(1)?x2(2)??x2(i)???????xn(1)?xn(2)??xn(i)?????????i×n?,label=??????y(1)y(2)?y(i)???????
在維度上, d a t a {\tt data} data 的樣本數 i i i 必須與 l a b e l {\tt label} label 的個數對應
data_iter = data.DataLoader(dataset=train_ids, batch_size, shuffle=False) 可以每次隨機讀取時取batch_size個小批量資料
得到的data_iter是一個物件,可以通過for...in...來進行訪問,且每個輪次訪問的結果都是隨機的
train_ids從TensorDataset()函式中回傳的物件
batch_size每次獲取資料樣本時的批量數
shuffle決定是否打亂資料集,default=False
next(iter(data_iter)) 訪問下一個批量
例如:
import torch.utils.data as data
import torch
train_data = torch.tensor([[1, 1, 1],
[2, 2, 2],
[3, 3, 3],
[4, 4, 4],
[5, 5, 5],
[6, 6, 6]])
train_label = torch.tensor([100, 200, 300, 400, 500, 600])
# 打包資料集
train_ids = data.TensorDataset(train_data, train_label)
# 回傳的物件可通過切片來查看
print(train_ids[0:3])
print('=' * 100)
# 也可回圈讀取資料
for train_data, train_label in train_ids:
print(train_data, train_label)
print('=' * 100)
# DataLoader 獲取資料
data_iter = data.DataLoader(dataset = train_ids, batch_size = 2, shuffle = True)
# 可以通過 for in 來遍歷 data_iter,并且每次訪問 data_iter 的結果都不一樣
print('第一次訪問:')
for x, y in data_iter:
print(x, y)
print('第二次訪問:')
for x, y in data_iter:
print(x, y)
print('=' * 100)
# 通過呼叫 next(iter()) 可以獲取下一個批量
for i in range(3):
print(next(iter(data_iter)))

2.實作流程
匯入所需的庫:
import numpy as np
import torch
import torch.utils as data # 包含一些資料處理的模塊
仍然以相同的方法生成一個人工資料集:
def synthetic_data(w, b, num_examples):
"""生成 y = xw + b + 噪聲"""
X = torch.normal(0, 1, (num_examples, len(w))) # 生成服從 μ=0,σ=1 正態分布的隨機值
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
通過 t o r c h . u t i l s . d a t a \tt torch.utils.data torch.utils.data 模塊處理資料集
def load_array(data_arrays, batch_size, shuffle=True):
"""構造一個PyTorch資料迭代器"""
dataset = data.TensorDataset(*data_arrays) # *data_arrays 解包
return data.DataLoader(dataset, batch_size, shuffle = shuffle)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
下面我們將使用 PyTorch 的神經網路 (Neural Network-NN) 庫: t o r c h . n n \tt torch.nn torch.nn,我們以后再著重介紹這個庫
# 匯入相關庫
import torch.nn as nn
# nn.Linear() 指的是線性層(全連接層),兩個引數分別是輸入節點個數和輸出節點個數
# 2個節點表示有兩個權重 w 和一個偏差 b,1個節點表示輸出一個值
# nn.Sequential() 是一個容器,可以將一系列操作進行打包,方便復用
net = nn.Sequential(nn.Linear(2, 1))
# 初始化模型引數,weight 表示權重,bias 表示偏差
# net[0] 表示容器中的第一個操作
net[0].weight.data.normal_(0, 0.01) # 使用正態分布 normal_() 原地替換
net[0].bias.data.fill_(0) # 用全零原地替換 fill_(0)
定義代價函式,使用均方誤差代價函式,定義優化演算法:
loss = nn.MSELoss() # 參考均方誤差代價函式
# 訓練器:隨機梯度下降,每次訓練樣本使用小批量,學習率為 0.03
# net.parameters() 獲取容器中的所有引數:w1、w2、b
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
開始訓練模型:
num_epochs = 3 # 訓練次數為 3
for epoch in range(num_epochs):
for X, y in data_iter: # 獲取小批量資料
l = loss(net(X), y) # 計算小批量的損失值
trainer.zero_grad() # 梯度清零
l.backward() # 損失函式反向傳播求導
trainer.step() # 更新所有引數:w1、w2、b
l = loss(net(features), labels) # 一次訓練結束,計算損失值
print('epoch {}, loss {:f}'.format(epoch + 1, l))

查看誤差:
w = net[0].weight.data
print('w的估計誤差:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('b的估計誤差:', true_b - b)
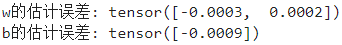
參考資料:
[1]Search 動手學深度學習課程
[2]機器學習-第二章:回歸.pdf,黃海廣
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/348542.html
標籤:AI