大佬們看過來,這是我要爬的東方財富網的爬蟲代碼放在pucharm中運行(是在網上找的)但是一直不行
import requests
import re
from multiprocessing import Pool
import json
import csv
import pandas as pd
import os
import time
# 設定檔案保存在D盤eastmoney檔案夾下
file_path = 'D:\\eastmoney'
if not os.path.exists(file_path):
os.mkdir(file_path)
os.chdir(file_path)
# 1 設定表格爬取時期
def set_table():
print('*' * 80)
print('\t\t\t\t東方財富網報表下載')
print('作者:高級農民工 2018.10.10')
print('--------------')
# 1 設定財務報表獲取時期
year = int(float(input('請輸入要查詢的年份(四位數2007-2018):\n')))
# int表示取整,里面加float是因為輸入的是str,直接int會報錯,float則不會
# https://stackoverflow.com/questions/1841565/valueerror-invalid-literal-for-int-with-base-10
while (year < 2007 or year > 2018):
year = int(float(input('年份數值輸入錯誤,請重新輸入:\n')))
quarter = int(float(input('請輸入小寫數字季度(1:1季報,2-年中報,3:3季報,4-年報):\n')))
while (quarter < 1 or quarter > 4):
quarter = int(float(input('季度數值輸入錯誤,請重新輸入:\n')))
# 轉換為所需的quarter 兩種方法,2表示兩位數,0表示不滿2位用0補充,
# http://www.runoob.com/python/att-string-format.html
quarter = '{:02d}'.format(quarter * 3)
# quarter = '%02d' %(int(month)*3)
# 確定季度所對應的最后一天是30還是31號
if (quarter == '06') or (quarter == '09'):
day = 30
else:
day = 31
date = '{}-{}-{}' .format(year, quarter, day)
# print('date:', date) # 測驗日期 ok
# 2 設定財務報表種類
tables = int(
input('請輸入查詢的報表種類對應的數字(1-業績報表;2-業績快報表:3-業績預告表;4-預約披露時間表;5-資產負債表;6-利潤表;7-現金流量表): \n'))
dict_tables = {1: '業績報表', 2: '業績快報表', 3: '業績預告表',
4: '預約披露時間表', 5: '資產負債表', 6: '利潤表', 7: '現金流量表'}
dict = {1: 'YJBB', 2: 'YJKB', 3: 'YJYG',
4: 'YYPL', 5: 'ZCFZB', 6: 'LRB', 7: 'XJLLB'}
category = dict[tables]
# js請求引數里的type,第1-4個表的前綴是'YJBB20_',后3個表是'CWBB_'
# 設定set_table()中的type、st、sr、filter引數
if tables == 1:
category_type = 'YJBB20_'
st = 'latestnoticedate'
sr = -1
filter = "(securitytypecode in ('058001001','058001002'))(reportdate=^%s^)" %(date)
elif tables == 2:
category_type = 'YJBB20_'
st = 'ldate'
sr = -1
filter = "(securitytypecode in ('058001001','058001002'))(rdate=^%s^)" %(date)
elif tables == 3:
category_type = 'YJBB20_'
st = 'ndate'
sr = -1
filter=" (IsLatest='T')(enddate=^2018-06-30^)"
elif tables == 4:
category_type = 'YJBB20_'
st = 'frdate'
sr = 1
filter = "(securitytypecode ='058001001')(reportdate=^%s^)" %(date)
else:
category_type = 'CWBB_'
st = 'noticedate'
sr = -1
filter = '(reportdate=^%s^)' % (date)
category_type = category_type + category
# print(category_type)
# 設定set_table()中的filter引數
yield{
'date':date,
'category':dict_tables[tables],
'category_type':category_type,
'st':st,
'sr':sr,
'filter':filter
}
# 2 設定表格爬取起始頁數
def page_choose(page_all):
# 選擇爬取頁數范圍
start_page = int(input('請輸入下載起始頁數:\n'))
nums = input('請輸入要下載的頁數,(若需下載全部則按回車):\n')
print('*' * 80)
# 判斷輸入的是數值還是回車空格
if nums.isdigit():
end_page = start_page + int(nums)
elif nums == '':
end_page = int(page_all.group(1))
else:
print('頁數輸入錯誤')
# 回傳所需的起始頁數,供后續程式呼叫
yield{
'start_page': start_page,
'end_page': end_page
}
# 3 表格正式爬取
def get_table(date, category_type,st,sr,filter,page):
# 引數設定
params = {
# 'type': 'CWBB_LRB',
'type': category_type, # 表格型別
'token': '70f12f2f4f091e459a279469fe49eca5',
'st': st,
'sr': sr,
'p': page,
'ps': 50, # 每頁顯示多少條資訊
'js': 'var LFtlXDqn={pages:(tp),data: (x)}',
'filter': filter,
# 'rt': 51294261 可不用
}
url = 'http://dcfm.eastmoney.com/em_mutisvcexpandinterface/api/js/get?'
# print(url)
response = requests.get(url, params=params).text
# print(response)
# 確定頁數
pat = re.compile('var.*?{pages:(\d+),data:.*?')
page_all = re.search(pat, response)
print(page_all.group(1)) # ok
# 提取{},json.loads出錯
# pattern = re.compile('var.*?data: \[(.*)]}', re.S)
# 提取出list,可以使用json.dumps和json.loads
pattern = re.compile('var.*?data: (.*)}', re.S)
items = re.search(pattern, response)
# 等價于
# items = re.findall(pattern,response)
# print(items[0])
data = items.group(1)
data = json.loads(data)
# data = json.dumps(data,ensure_ascii=False)
return page_all, data,page
# 寫入表頭
# 方法1 借助csv包,最常用
def write_header(data,category):
with open('{}.csv' .format(category), 'a', encoding='utf_8_sig', newline='') as f:
headers = list(data[0].keys())
# print(headers) # 測驗 ok
writer = csv.writer(f)
writer.writerow(headers)
def write_table(data,page,category):
print('\n正在下載第 %s 頁表格' % page)
# 寫入檔案方法1
for d in data:
with open('{}.csv' .format(category), 'a', encoding='utf_8_sig', newline='') as f:
w = csv.writer(f)
w.writerow(d.values())
def main(date, category_type,st,sr,filter,page):
func = get_table(date, category_type,st,sr,filter,page)
data = func[1]
page = func[2]
write_table(data,page,category)
if __name__ == '__main__':
# 獲取總頁數,確定起始爬取頁數
for i in set_table():
date = i.get('date')
category = i.get('category')
category_type = i.get('category_type')
st = i.get('st')
sr = i.get('sr')
filter = i.get('filter')
constant = get_table(date,category_type,st,sr,filter, 1)
page_all = constant[0]
for i in page_choose(page_all):
start_page = i.get('start_page')
end_page = i.get('end_page')
# 寫入表頭
write_header(constant[1],category)
start_time = time.time() # 下載開始時間
# 爬取表格主程式
for page in range(start_page, end_page):
main(date,category_type,st,sr,filter, page)
end_time = time.time() - start_time # 結束時間
print('下載完成')
print('下載用時: {:.1f} s' .format(end_time))
但是一直會出現這個問題
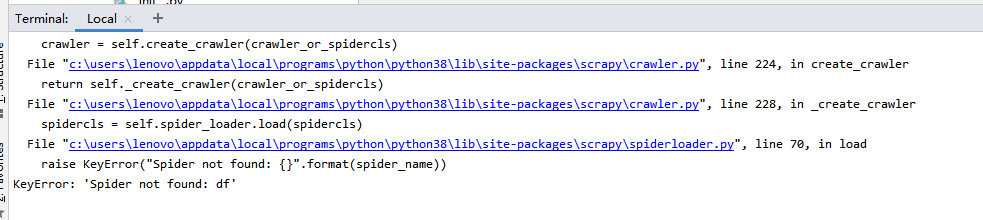
uj5u.com熱心網友回復:
頂頂!!!!爬蟲名字是dfuj5u.com熱心網友回復:
有沒有大佬,定感激不盡!!!!uj5u.com熱心網友回復:
為啥我運行你的代碼就沒有問題,沒有報錯轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/34907.html
上一篇:關于sha256的演算法問題