一.用beautifulsoup決議出來的html為什么跟網頁f12的elements不一樣
這是獲取網頁的代碼:
這是網頁的elements:

這是spyder的console,截的不全不過選中的跟網頁的是同一段:
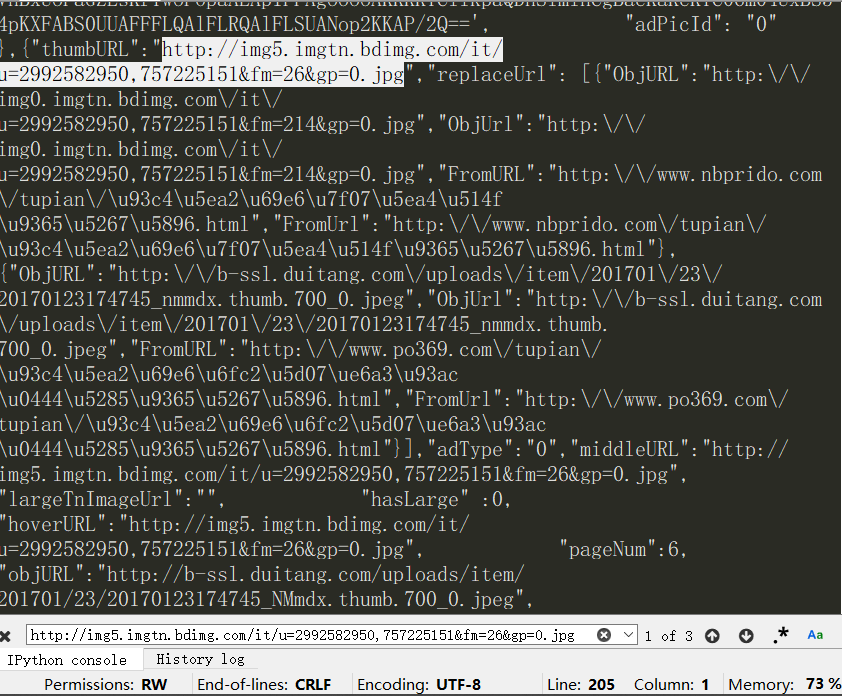
二.平常variable explorer這個視窗內也同時會有html為名的變數但是現在沒有是扎回事

三.下面兩種獲取網頁代碼的方式有什么差異:

雖然感覺問題挺弱智的,但還是求教!
uj5u.com熱心網友回復:
問題3:功能上差不多,但是現在requests 3.x做的更好,自動做了字符集匹配
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/34924.html
上一篇:python爬蟲被反爬蟲擋了