我正在嘗試從 Crunchbase 中抓取新聞和信號選項卡,但沒有任何樂趣。
在查閱了 Stackoverflow 上的先前執行緒后,我一直在使用此代碼,該代碼適用于所有其他選項卡(以 duolingo 為例):
website2 = "https://www.crunchbase.com/organization/duolingo/signals_and_news"
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:66.0) Gecko/20100101 Firefox/66.0", "Accept": "text/html,application/xhtml xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Language": "en-US,en;q=0.5", "Accept-Encoding": "gzip, deflate", "DNT": "1", "Connection": "close", "Upgrade-Insecure-Requests": "1"}
response2 = requests.get(website2, headers=headers)
print(response2.content)
我懷疑這與 Crunchbase 如何編碼新聞部分有關,這可能需要調整我的標題,但我不確定我需要做什么。
如果有人可以提供幫助,我將不勝感激。非常感謝!
uj5u.com熱心網友回復:
似乎新聞文章是由 javascript 在后臺動態生成的。
如果您在加載頁面時查看您的網路檢查器,您可以看到正在發出的請求:
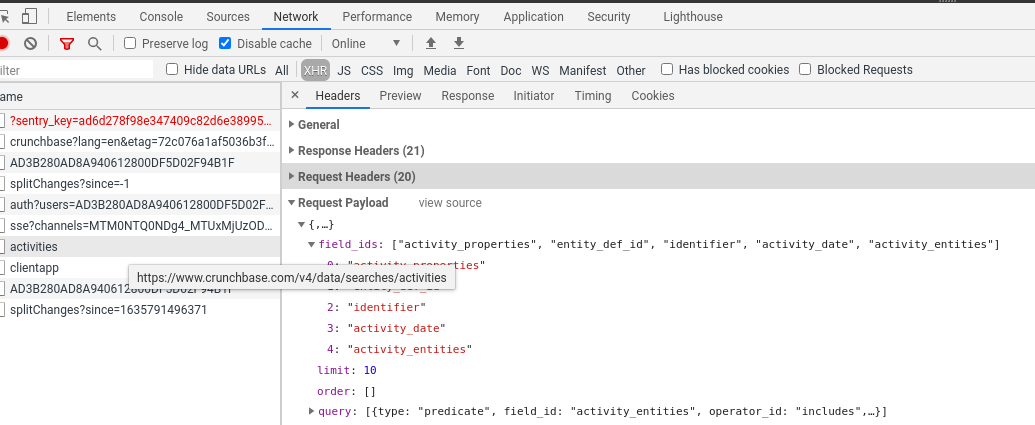
您可以看到它回傳新聞文章的 JSON 資料:
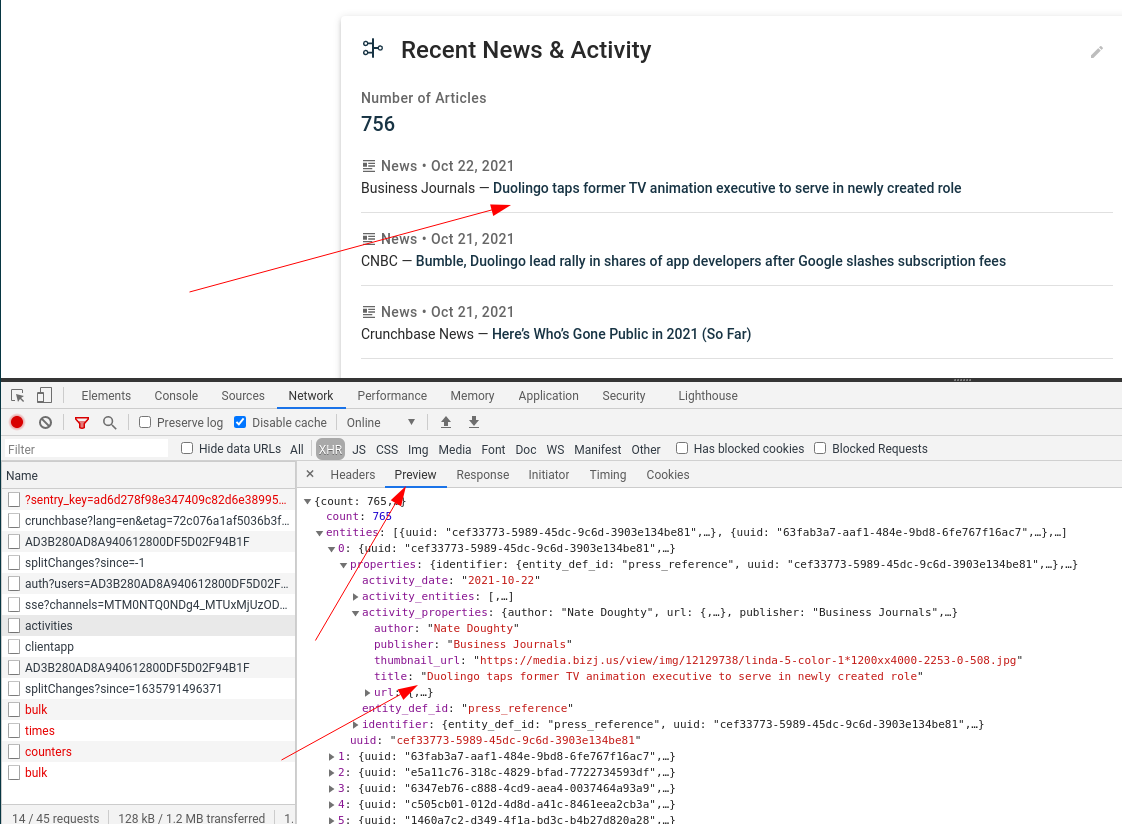
你必須在你的爬蟲代碼中復制這個請求:
import requests
headers = {
'accept': 'application/json, text/plain, */*',
'x-requested-with': 'XMLHttpRequest',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) QtWebEngine/5.15.2 Chrome/87.0.4280.144 Safari/537.36',
'content-type': 'application/json',
'accept-language': 'en-US,en;q=0.9',
}
data = {'field_ids': ['activity_properties',
'entity_def_id',
'identifier',
'activity_date',
'activity_entities'],
'limit': 10,
'order': [],
'query': [{'field_id': 'activity_entities',
'operator_id': 'includes',
'type': 'predicate',
# this value is company page id, can be found in the html of original url
'values': ['c999a7f8-6a98-144a-e29f-05fb6df60f73']}]}
response = crequests.post('https://www.crunchbase.com/v4/data/searches/activities', headers=headers, data=data)
有關使用此方法的逆向工程網站的更多資訊,請參閱我的完整博客文章:https : //scrapecrow.com/reverse-engineering-intro.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/349831.html