目錄
- 背景介紹
- 雙向解碼
- 基本思路
- 數學描述
- 模型實作
- 訓練方案
- 雙向束搜索
- 代碼參考
- 思考分析
- 文章小結
在文章《玩轉Keras之seq2seq自動生成標題》中我們已經基本探討過seq2seq,并且給出了參考的Keras實作,
本文則將這個seq2seq再往前推一步,引入雙向的解碼機制,它在一定程度上能提高生成文本的質量(尤其是生成較長文本時),本文所介紹的雙向解碼機制參考自《Synchronous Bidirectional Neural Machine Translation》,最后筆者也是用Keras實作的,
背景介紹
研究過seq2seq的讀者都知道,常見的seq2seq的解碼程序是從左往右逐字(詞)生成的,即根據encoder的結果先生成第一個字;然后根據encoder的結果以及已經生成的第一個字,來去生成第二個字;再根據encoder的結果和前兩個字,來生成第三個詞;依此類推,總的來說,就是在建模如下概率分解
\[p(Y|X)=p(y_1|X)p(y_2|X,y_1)p(y_3|X,y_1,y_2)\quad(1) \]當然,也可以從右往左生成,也就是先生成倒數第一個字,再生成倒數第二個字、倒數第三個字,等等,問題是,不管從哪個方向生成,都會有方向性傾斜的問題,比如,從左往右生成的話,前幾個字的生成準確率肯定會比后幾個字要高,反之亦然,在《Synchronous Bidirectional Neural Machine Translation》給出了如下的在機器翻譯任務上的統計結果:
| Model | The first 4 tokens | The last 4 tokens |
|---|---|---|
| L2R | 40.21% | 35.10% |
| R2L | 35.67% | 39.47% |
L2R和R2L分別是指從左往右和從右往左的解碼生成,從表中我們可以看到,如果從左往右解碼,那么前四個token的準確率有40%左右,但是最后4個token的準確率只有35%;反過來也差不多,這就反映了解碼的不對稱性,
為了消除這種不對稱性,《Synchronous Bidirectional Neural Machine Translation》提出了一個雙向解碼機制,它維護兩個方向的解碼器,然后通過Attention來進一步對齊生成,
雙向解碼
雖然本文參考自《Synchronous Bidirectional Neural Machine Translation》,但我沒有完全精讀原文,我只是憑自己的直覺粗讀了原文,大致理解了原理之后自己實作的模型,所以并不保證跟原文完全一致,此外,這篇論文并不是第一篇做雙向解碼生成的論文,但它是我看到的雙向解碼的第一篇論文,所以我就只實作了它,并沒有跟其他相關論文進行對比,
基本思路
既然叫雙向“解碼”,那么改動就只是在decoder那里,而不涉及到encoder,所以下面的介紹中也只側重描述decoder部分,還有,要注意的是雙向解碼只是一個策略,而下面只是一種參考實作,并不是標準的、唯一的,這就好比我們說的seq2seq也只是序列到序列生成模型的泛指,具體encoder和decoder怎么設計,有很多可調整的地方,
首先,給出一個簡單的示意動圖(Seq2Seq的雙向解碼機制圖示),來演示雙向解碼機制的設計和互動程序:
如圖所示,雙向解碼基本上可以看成是兩個不同方向的解碼模塊共存,為了便于描述,我們將上方稱為L2R模塊,而下方稱為R2L模塊,開始情況下,大家都輸入一個起始標記(上圖中的S),然后L2R模塊負責預測第一個字,而R2L模塊負責預測最后一個字;接著,將第一個字(以及歷史資訊)傳入到L2R模塊中,來預測第二個字,為了預測第二個字,除了用到L2R模塊本身的編碼外,還用到R2L模塊已有的編碼結果;反之,將最后一個字(以及歷史資訊)傳入到R2L模塊,再加上L2R模塊已有的編碼資訊,來預測倒數第二個字;依此類推,直到出現了結束標記(上圖中的E),數學描述
換句話說,每個模塊預測每一個字時,除了用到模塊內部的資訊外,還用到另一模塊已經編碼好的資訊序列,而這個“用”是通過Attention來實作的,用公式來說,假設當前情況下L2R模塊要預測第nn個字,以及R2L模塊要預測倒數第nn個字,假設經過若干層編碼后,得到的R2L向量序列(對應圖中左上方的第二行)為:
\[H^{(l2r)}=[h^{(l2r)}_1,h^{(l2r)}_2,…,h^{(l2r)}_n] \quad(2) \]而R2L的向量序列(對應圖中左下方的倒數第二行)為:
\[H^{(r2l)}=[h^{(r2l)}_1,h^{(r2l)}_2,…,h^{(r2l)}_n] \quad(3) \]如果是單向解碼的話,我們會用\(h^{(l2r)}_n\)作為特征來預測第n個字,或者用\(h^{(r2l)}_n\)作為特征來預測倒數第n個字,
在雙向解碼機制下,我們以\(h^{(l2r)}_n\)為query,然后以\(H^{(r2l)}\)為key和value來做一個Attention,用Attention的輸出作為特征來預測第n個字,這樣在預測第n個字的時候,就可以提前“感知”到后面的字了;同樣地,我們以\(h^{(r2l)}_n\)為query,然后以\(H^{(l2r)}\)為key和value來做一個Attention,用Attention的輸出作為特征來預測倒數第n個字,這樣在預測倒數第n個字的時候,就可以提前“感知”到前面的字了,上面示意圖中,上面兩層和下面兩層之間的互動,就是指Attention,在下面的代碼中,用到的是最普通的乘性Attention(參考《〈Attention is All You Need〉淺讀(簡介+代碼)》),
模型實作
上面就是雙向解碼的基本原理和做法,可以感覺到,這樣一來,seq2seq的decoder也變得對稱起來了,這是一個很漂亮的特點,當然,為了完全實作這個模型,還需要思考一些問題:
-
怎么訓練?
-
怎么預測?
訓練方案
跟普通的seq2seq一樣,基本的訓練方案就是用所謂的Teacher-Forcing的方式來進行訓練,即L2R方向在預測第n個字的時候,假設前n?1個字都是準確知道的,而R2L方向在預測倒數第n個字的時候,假設倒數第n?1,n?2,…,1個字都是準確知道的,最終的loss是兩個方向的逐字交叉熵的平均,
不過這樣的訓練方案實在是無可奈何之舉,后面我們會分析它資訊泄漏的弊端,
雙向束搜索
現在討論預測程序,
如果是常規的單向解碼的seq2seq,我們會使用beam search(束搜索)的演算法,給出概率盡可能大的序列,所謂beam search,指的是依次逐字解碼,每次只保留概率最大的topk條“臨時路徑”,直到出現結束標記為止,
到了雙向解碼這里,情況變得復雜了一些,我們依然用beam search的思路,但是同時快取兩個方向的topk結果,也就是說,L2R和R2L兩個方向各存topk條臨時路徑,此外,由于雙向解碼時,L2R的解碼是要參考R2L已有的解碼結果的,所以當我們要預測下一個字時,除了要列舉概率最高的topk個字、列舉topk條L2R的臨時路徑外,還要列舉topk條R2L的臨時路徑,所以一共要計算topk3那么多個組合,而計算完成后,采用了一種最簡單的思路:對每種“字 - L2R臨時路徑”的得分在“R2L臨時路徑”這一維度上做了平均,使得的分數變回topk2個,作為每種“字 - L2R臨時路徑”的得分,再從這topk2個組合中,選出分數最高的topk個,而R2L這邊的解碼,則要進行反向的、相同的處理,最后,如果L2R和R2L兩個方向都解碼出了完成的句子,那么就選擇概率(得分)最高的那個,
這樣的整個程序,我們稱之為“雙向束搜索(雙向beam search)”,如果讀者自己比較熟悉單向的beam search,甚至自己都寫過beam search的話,上述程序其實不難理解(看看代碼就更容易懂了),它算是單向beam search自然延伸,當然,如果對beam search本身不了解的話,看上述搜索的程序應該是云里霧里的,所以想要弄清楚原理的讀者,應該要從常規的單向beam search出發,先把它弄懂了,然后再看上述解碼程序的描述,最后再看看下面給出的參考代碼,就容易弄懂了,
代碼參考
下面是筆者給出了雙向解碼的參考實作,整體還是跟之前的《玩轉Keras之seq2seq自動生成標題》一致,只是解碼端從雙向換成單向了:
https://github.com/bojone/seq2seq/blob/master/seq2seq_bidecoder.py
注:測驗環境還是跟之前差不多,大概是Python 2.7 + Keras 2.2.4 + Tensorflow 1.8,用Python 3.x或者其他環境的朋友,如果你們能自己改,那就做相應的改動,如果你們自己不會改,那也請你們別來問我了,我實在沒有空也沒有義務幫你們跑通每一個環境,本文只討論seq2seq技術相關的內容可否?
在這個實作里,我覺得有必要解釋一下起始標記和結束標記的事情,在之前的單向解碼的例子中,筆者是用2作為起始標記,用3作為結束標記,到了雙向解碼這里,一個很自然的問題就是:L2R和R2L兩個方向是不是應該要用兩套起始和結束標記呢?
其實這個應該沒有什么標準答案,我覺得不管是共用一套還是維護兩套起止標記,結果可能都差不多,至于我在上面的參考代碼中,使用的方案有點另類,但我認為比較符合直覺,具體是:依然是只用一套,但是在L2R方向中,用2作為起始標記、3作為結束標記,而在R2L方向中,用3作為起始標記、2作為結束標記,
思考分析
最后,我們進一步思考一下這種雙向解碼方案,盡管將解碼程序對稱化是一個很漂亮的特點,但也不代表它完全沒有問題了,將它思考得更深入一些,有助于我們更好地理解和使用它,
- 改進生成的原因
一個有意思的問題是:看上去雙向解碼確實能提高句子首尾的生成質量,但會不會同時降低中間部分的生成質量?
當然,理論上這是有可能的,但實際測驗時不是很嚴重,一方面,seq2seq架構的資訊編碼和解碼能力還是很強的,所以不會輕易損失資訊;另一方面,我們自己去評估一個句子的質量的時候,往往會重點關注首尾部分,如果首尾部分都很合理,而中間部分不至于太糟糕的話,那么我們都認為它是一個合理的句子;反過來,如果首或尾不合理的話,我們會覺得這個句子很糟糕,這樣一來,把句子首尾的生成質量提高了,整體的生成質量也就提高了,
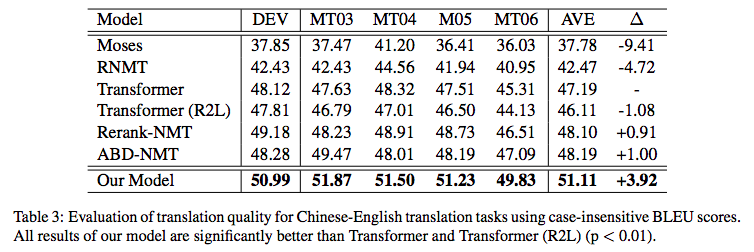
原論文中雙向解碼相對其它單向模型帶來的提升
- 對應不上概率模型
對于單向解碼,我們有清晰的概率解釋,即在估計條件概率p(Y|X)(也就是(1)),但是在雙向解碼的時候,我們發現壓根兒不知道怎么對應上一個概率模型,換句話說,我們感覺我們是在算概率,感覺效果也有了,卻不知道真正算得是啥,因為條件概率的條件依賴完全已經被打亂了,
當然,如果真的有實效的話,理論美感差點也無妨,我說的這一點只是理論審美的追求,大家見仁見智就好,
- 資訊提前泄漏
所謂資訊泄漏,指的是本來作為預測目標的標簽被用來做輸入了,從而導致訓練階段的loss虛低(或者準確率虛高),
由于在雙向解碼中,L2R端的解碼要去讀取R2L端已有的向量序列,而在訓練階段,為了預測R2L端的第n個字,是需要傳入前n?1個字的,這樣一來,越解碼到后面,資訊泄漏就越嚴重,如下圖所示:
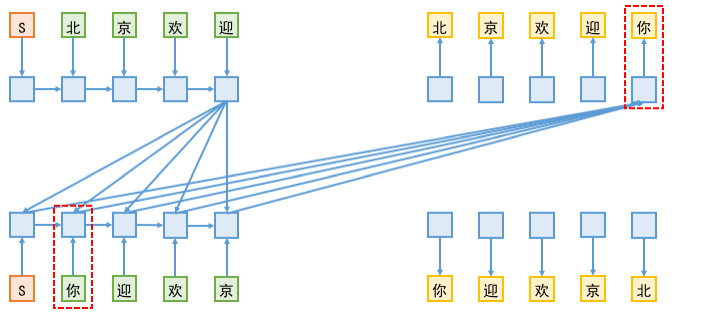
上圖為資訊泄漏示意圖,訓練階段,當L2R端在預測“你”的時候,事實上用到了傳入到R2L端的“你”標簽;反之,R2L端預測“北”字的時候,同樣存在這個問題,即用到了L2R的“北”字標簽,
資訊泄漏的一個表觀現象是:訓練到后期,雙向解碼中L2R和R2L兩個方向的交叉熵之和,比單獨訓練單向解碼模型時的單個交叉熵還要小,這并不是因為雙向解碼帶來多大的擬合提升,而正是資訊泄漏的體現,
既然訓練程序中把資訊泄漏了,那為什么這樣的模型還有用呢?我想,大概的原因在文章一開頭的表格中就給出了,還是剛才的例子,L2R端在預測最后一個字“你”的時候,會用到了R2L端所有的已知資訊;而R2L端是從右往左逐字解碼的,按照文章一開頭的表格的統計資料,我們不難想象到,對于R2L端來說,倒數第一個字的預測準確率應該是最高的,這樣一來,假設R2L的倒數第一個字真的能以很高的準確率預測成功的話,那資訊泄漏也變成不泄漏了———因為資訊泄漏是因為我們人為地傳入了標簽,但如果預測的結果本身就跟標簽一致,那泄漏也不再是泄漏了,
當然,原論文還提供了一個策略來緩解這個泄漏問題,大概做法是先用上述方式訓練一版模型,然后對于每個訓練樣本,用模型生成對應的預測結果(偽標簽),接著再去訓練模型,這一次訓練模型是傳入偽標簽來預測正確標簽,這樣就盡可能地保持了訓練和預測的一致性,
文章小結
本文介紹并實作了一種seq2seq的雙向解碼機制,它將整個解碼程序對稱化了,從而在一定程度上使得生成質量更高了,個人認為這種改進的嘗試還是有一定的價值的,尤其是對于追求形式美的讀者來說,所以就將其介紹一番,
除此之外,文章也分析了這種雙向解碼可能存在的問題,給出了筆者自己的看法,敬請各位讀者多多交流直角~
如果您需要參考本文,請參考:
蘇劍林. (Aug. 09, 2019). 《seq2seq之雙向解碼 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/6877
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350712.html
標籤:其他
上一篇:seq2seq之雙向解碼