1. 語音識別的輸出類別:
1)phoneme:輸出為發音,比較簡單,因為語音跟發音是一一對應的,但是需要一個詞匯表,表示發音跟word的對應,
2)Grapheme:字母或者token
3)word:短語,V會很大
4)morpheme:代表含義的最小單位
5)byte:utf-8,適用于任何語言

2. 輸入特征:(具體的處理可以看下圖,以MFCC為例子,如果不經過DCT,就是目前用的最普遍的fliter bank output)
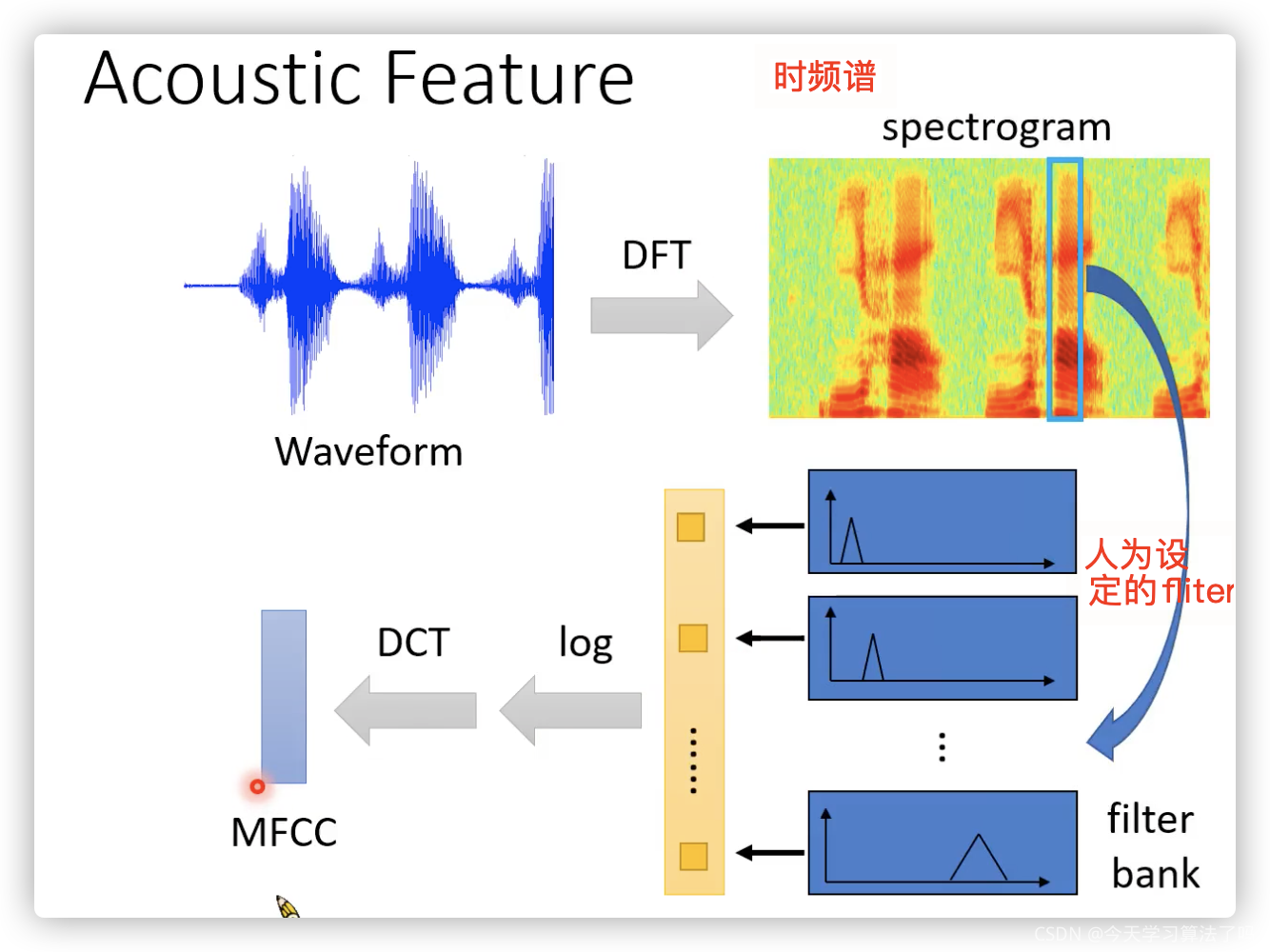
3. 那確定了輸入以及輸出,接下來介紹中間的模型,
1)以下的模型都是seq-to-seq模型架構的:
??encoder:
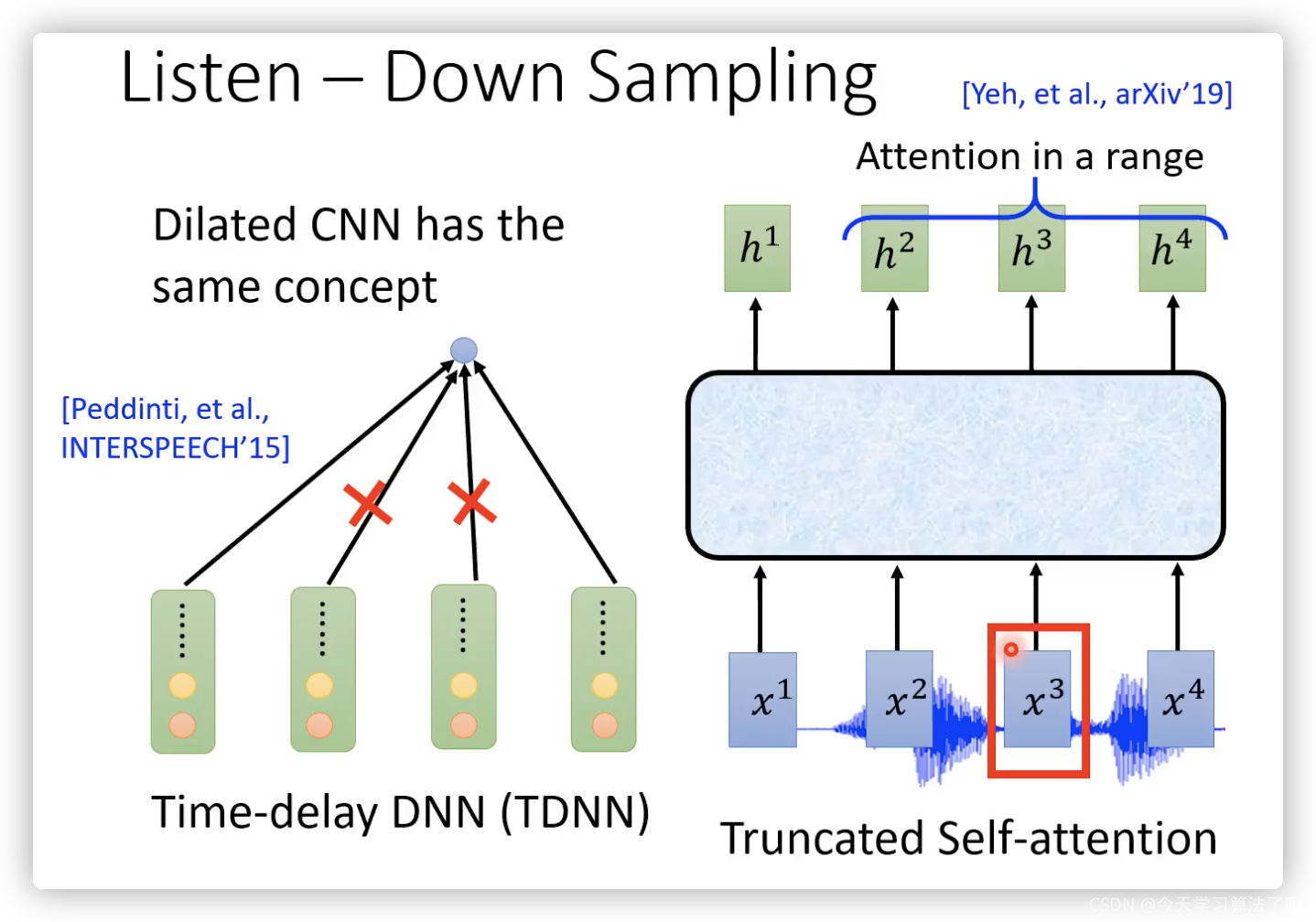
因為語音feature太長了,所以通常要使用down-sampling: 比如下面兩個圖分別是RNN、CNN和self-attention的模型圖,這樣輸出的hidden就會減少為原來的一半,(這樣做還有一個依據,相鄰的語音vector其實是比較相近的,因為每次只移動了10ms)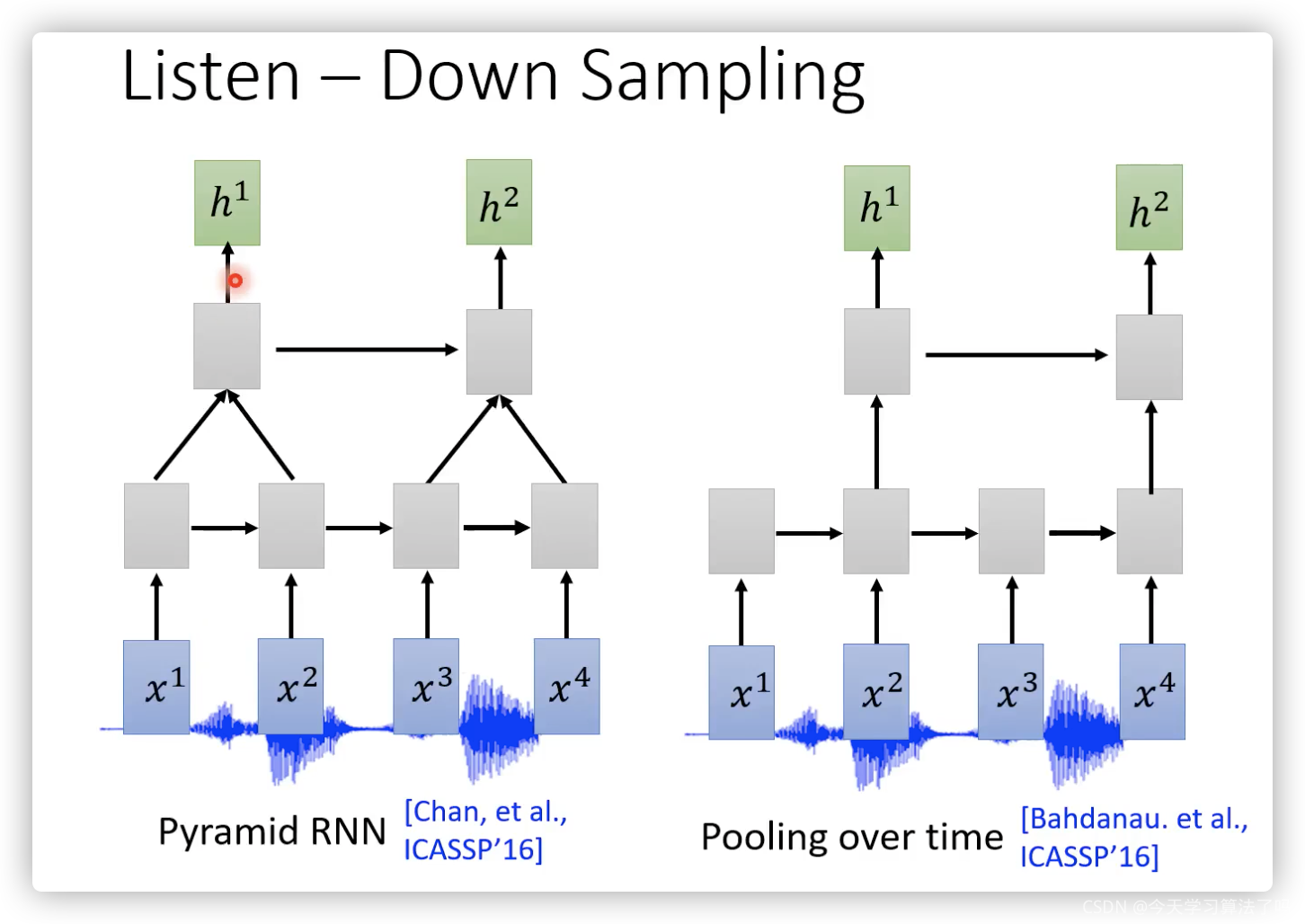
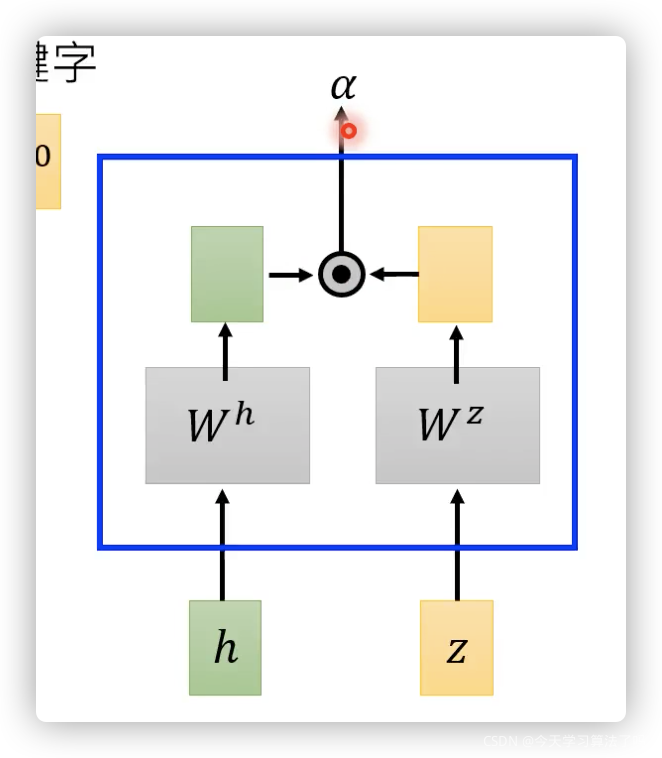
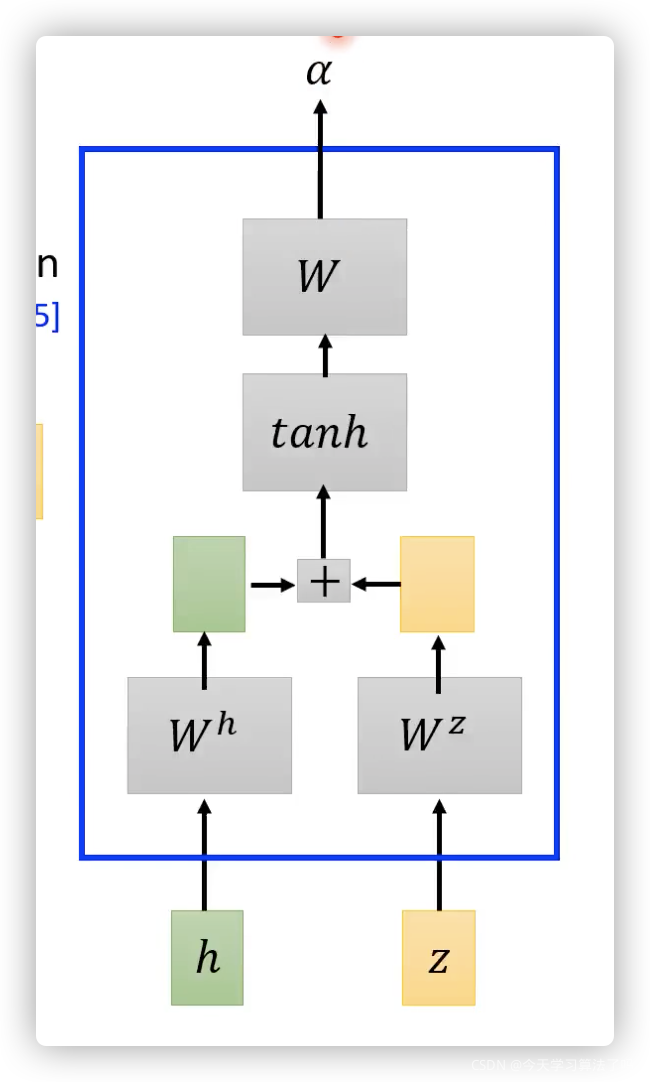
??attention:
其常見計算方式: 直接乘法、加法,在transformer面試時可能會問,為什么選擇乘法而不是加法計算相似度:雖然加法計算量小,但是求出來的只是中間結果(矩陣),還要再??矩陣才能得到標量,
??decoder:
常見的decoder 方法有:1)greedy decoding(可能找不到最好的)2)beam search方法(保留分數最高的兩個)3)我感覺如果是label已知,目前大多數訓練用的是teacher forcing,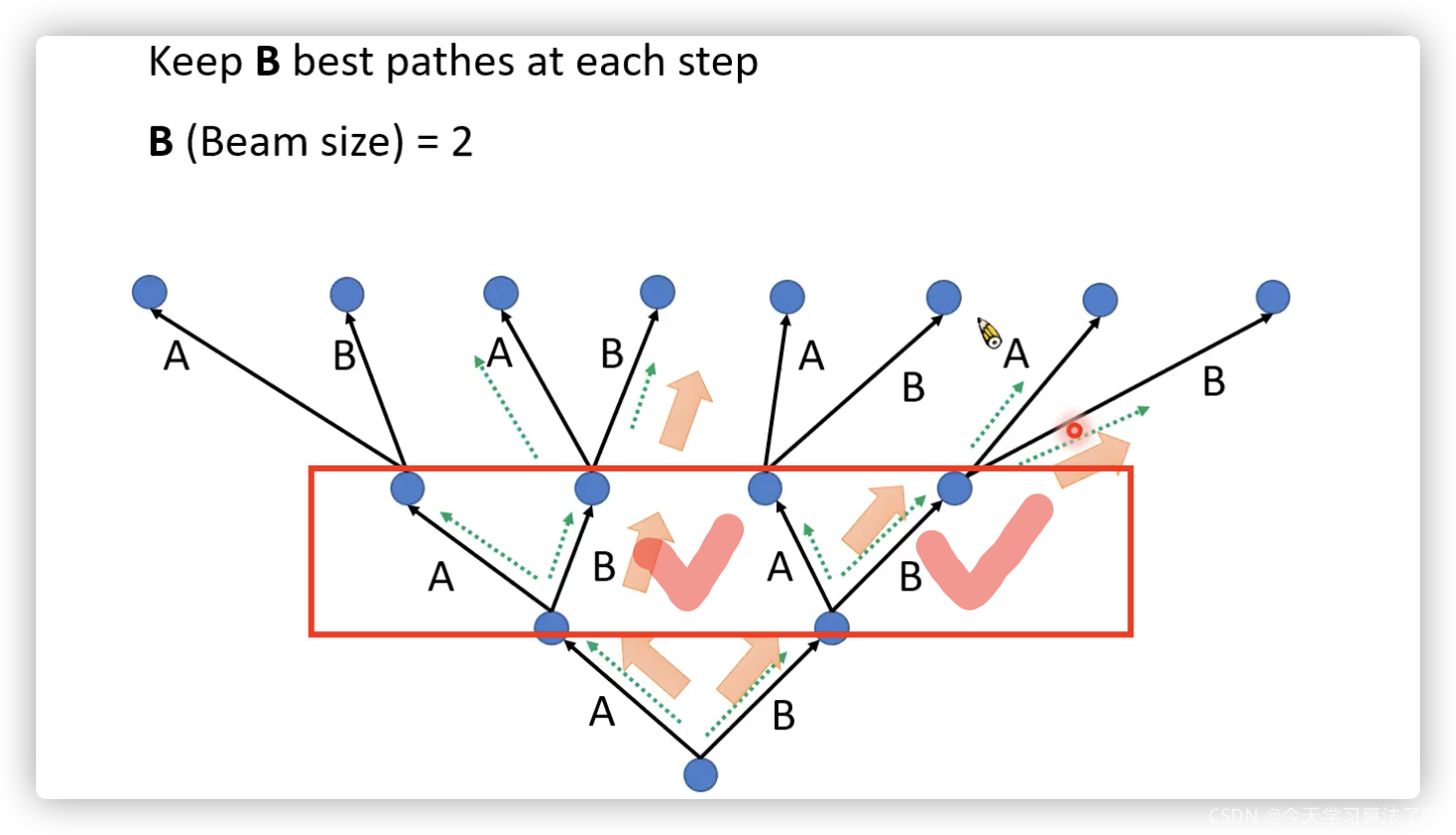
??損失函式:交叉上損失函式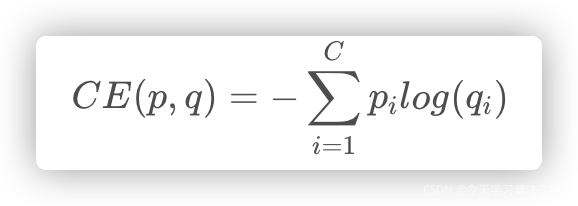
其中C為樣本數量,p是label(one-hot),q是預測的概率,其中q的計算公式(softmax)為:即現擴大差距,在進行歸一化,

因為p是one-hot,會使得最終預測的logits向量中目標類別zi的值會趨于無窮大,使得模型向預測正確與錯誤標簽的logit差值無限增大的方向學習,而過大的logit差值會使模型缺乏適應性,對它的預測過于自信,過擬合,所以有時候會使用label smothing(soft “one-hot”)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350753.html
標籤:其他
上一篇:(Python數字影像處理)彩色影像處理---色調和彩色校正以及直方圖均衡化
下一篇:影像處理筆記目錄