全域敏感度,區域敏感度和平滑敏感度到底有什么區別?【差分隱私】
- 寫在前面的話
- 噪聲校準
- 全域敏感度:
- 區域敏感度
- 平滑敏感度
- 噪聲分布范圍
- 自己的理解
寫在前面的話
關于敏感度相關的知識,我認為這是差分隱私的重中之重,這也是我個人的筆記,如果又不正確的地方歡迎指正,謝謝大家,大家不想看長篇大論可以直接點目錄里面(自己的理解),
噪聲校準
全域敏感度:

全域敏感度度量在修改一個元組時查詢結果的最大變化,它只與查詢函式相關,并且獨立于資料集本身,對于一些函式,如和、計數和最大值,全域靈敏度很容易計算,例如,計數的全域敏感性為1,因為對于任何兩個相鄰的資料集,只有一個元組被更改,而對于直方圖查詢的全域敏感性為2,對于其他一些函式,如計算kmeans簇的最大直徑和計數子圖,全域靈敏度可能難以計算或無界,例如,中值函式可以具有很高的全域靈敏度,以f(D)=中位數(x1、x2,……、xn)為例,其中xi是[0、M]中的一個實數,假設n是一個奇數,并且x1,x2,……,xn被排序,因此,f(D)=xm,其中m=(n+1)/2 ,考慮以下極端情況,
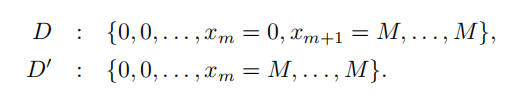
我們有f(D)=0和f(D0)=M,因此,這個函式的全域靈敏度是M,它可以任意大,另一個例子,三角形計數查詢的全域敏感性是無界的,因為三角形計數的變化取決于圖的大小,注入以實作差異隱私的噪聲可以根據查詢函式的全域靈敏度進行校準,即的最大的量,當資料集中只修改了一條記錄時,請更改為查詢結果,對于全域靈敏度較小的函式,只需要添加少量的噪聲,以掩蓋在更改一條記錄時對查詢結果的影響,然而,當全域靈敏度較大時,需要向輸出添加大量的噪聲,以確保隱私保證,從而導致資料效用較差,針對不同的問題,提出了兩種噪聲機制,即拉普拉斯機制和指數機制,
區域敏感度
當全域靈敏度較大時,必須向輸出中添加大量的噪聲,以實作差分隱私,這可能會嚴重損害資料效用,為了解決這個問題,Nissim等人提出了區域靈敏度的思想,

區域敏感度不僅與查詢函式f有關,而且還與給定的資料集d有關,根據定義3,GSf=maxD(LSf(D)),由于噪聲的大小與靈敏度成正比,噪聲的區域靈敏度要小得多,不幸的是,區域靈敏度不能滿足差分隱私的要求,因為噪聲大小本身可能會揭示資料庫資訊,例如,考慮一個資料庫,其中的值在0和M>0之間,以及兩個相鄰的資料庫D(0、0、0、0、0、M、M)和D0(0、0、0、0、M、M、M),設f為中值函式,然后,f(D)=0和f(D0)=0,以及相應的區域靈敏度為LSf(D)=0和LSf(D0)=M,相應地,如果噪聲分別根據0和M進行校準,以計算A(D)和A(D0),那么它們很容易被對手區分,如果采用區域靈敏度,演算法A不是(?,δ)差異私有的,為了彌合差距,提出了一個區域靈敏度的光滑上界來確定所添加的噪聲的大小,
平滑敏感度

當β=0,S(D)成為常數GSf,以滿足定義5中的要求,全域靈敏度是LSf上一個簡單但可能松散的上界,當β>0時,全域靈敏度是LSf的一個保守上界,LSf可能有多個平滑邊界,并且平滑靈敏度是符合定義5的最小邊界,再次,以中位數函式為例,我們構造了一個函式a(k)(D),它計算當最多k個條目被修改時敏感度的變化,

為了計算A(k)(D),我們需要計算LSf(D0)的最大值,其中D0和D多相差多達k個元組,回想一下,D被排序了,f(D)=xm和LSf(D)=max{xm?xm?1、xm+1?xm},因此,我們已經有了
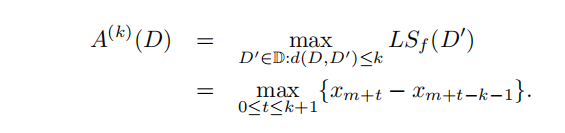
然后,中值函式的光滑靈敏度可以通過
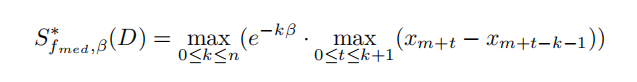
一般來說,計算圖中三角形數等函式的光滑靈敏度是非平凡的,甚至是np難問題,因此,當光滑靈敏度難以計算時,就使用光滑上界來代替光滑靈敏度,接下來,我們將展示如何使用β平滑靈敏度(或上界)來校準?-差異隱私的噪聲,對資料集D上的查詢f回傳A(D)=f(D)+Z,其中Z是從一個分布中抽取的隨機變數,如果Z~Lap(GSf/?),A(D)提供了?-的差異隱私,在?-的差異隱私中,添加的噪聲的大小應該盡可能小,以保持資料效用,并且應該獨立于資料庫,以進行強大的隱私保護,根據全域靈敏度校準的噪聲獨立于資料庫D,但其大小可能太大,無法使查詢結果不可用,根據區域靈敏度校準的噪聲依賴于D,使其失效,導致差異隱私,為了解決這個挑戰,Nissim等人,建議使用根據區域靈敏度的平滑上界(更優選的是平滑靈敏度)進行校準的噪聲,其基本思想是添加與Sf(D)α成正比的噪聲,即A(D)=f(D)+Sf(D)α·Z,其中Sf是f區域靈敏度的β平滑上界,Z是一個具有概率密度函式h的隨機變數,Nissim等人指出,h必須允許(α,β),以實作基于平滑靈敏度的差異隱私,
噪聲分布范圍

滑動和膨脹特性保證了在滑動和膨脹條件下噪聲分布變化不大,α和β的值是基于h的?(滑移偏移)和λ(膨脹偏移)的上界,如果hofZ(α,β)允許,資料庫訪問機制A(D)=f(D)+Sf(D)α·Z是(?,δ)差異隱私,
可容許分布有三個族:柯西、拉普拉斯和高斯[68],柯西可許分布產生了δ=0的“純”?-差異隱私,拉普拉斯和高斯可許分布可以產生不同α和β值的δ>0產生近似差分隱私,
自己的理解

中值查詢:
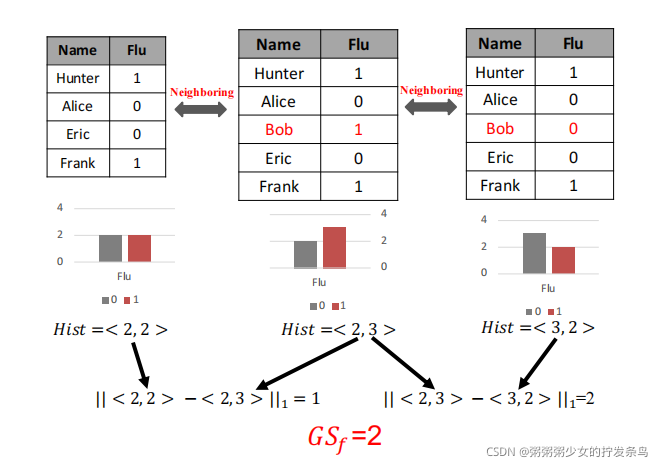
全域敏感度:考慮最極端的情況,不管你的資料怎么分布,只看查詢,當有一條記錄改變對查詢結果造成的最大影響就是10,因為數字的范圍就是0到10,我先假設中值為0,然后改個10,不可能有比這更大的改變了,
區域敏感度:查詢也看,資料也看,上面這個圖的區域敏感度就是1,從形式化定義來看,區域敏感度是依賴于給定的資料集的,在給定的資料集中變一條記錄找最大影響,這個影響大小就是區域敏感度,看上去好像完美無缺,實際已經都不能算差分隱私了,為什么?因為資料集不可能永遠不變,每次改變,區域敏感度是不是要變,那么是不是體現出了資料分布的差異,關于中值查詢關于區域敏感度的例子前面提到了,我這里就不贅述了,直接見圖: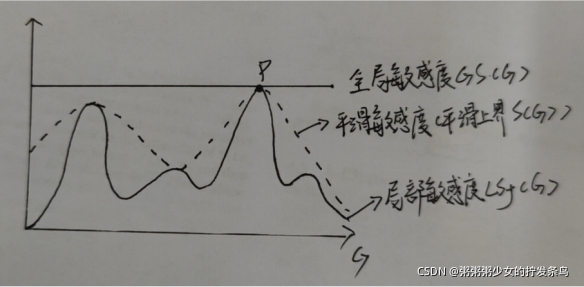
你看,這里的G作為資料集,在橫坐標上變化,區域敏感度也在變化,說區域敏感度最大就是全域敏感度我不敢茍同,只能說全域敏感度是區域敏感度的上界(其實也一樣),看你怎么理解了,并且不要認為區域敏感度就一定要在區域去找,從全域也可以出發,我在看社會網路中就加入這樣的誤區,認為區域視圖才有區域敏感度,全域也是,只要圖是給定的就可以算區域敏感度,
平滑敏感度:還是上面那個圖,找到一個平滑上界函式,不同的函式會導致上界不同,全域敏感度作為區域敏感度較為松弛的上界,平滑敏感度是較為保守的上界,我的理解是預測未來,資料集的變化從當前來看是一條資料條目變化,但是在后面的變化中可能相對于第一個資料集有多條記錄變化,所以平滑上界考慮的是改變多條記錄的最大敏感度,再乘以一個平滑上界函式,這個函式的目的在于做一個懲罰,這個函式一定小于1,最終就得到了上面這個圖,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350830.html
標籤:其他
上一篇:系統安全性之認證技術