摘要:2021云棲大會云原生企業級資料湖專場,阿里云智能高級產品專家李冰為我們帶來《資料湖構建與計算》的分享,

本文主要從資料的入湖和管理、引擎的選擇展開分享了資料湖方案降本增效的特性,
一、面臨的挑戰
- 資料如何入湖和管理
- 引擎如何選擇
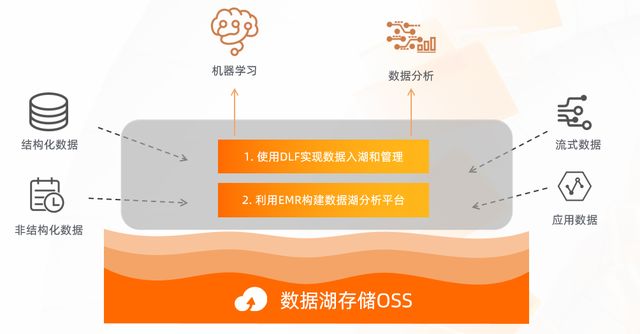
我們在前面的分享當中了解到了OSS將作為資料湖計算當中的中心化的存盤,其實資料湖計算本質上就是輸入來自各種云上的資料源,經過一系列的轉化運算,最終能夠支持上層計算的 BI 和 AI 的分析,那在整個資料湖的構建當中,其實我們需要考慮兩個問題,一個是各種各樣的資料,如何流入到 OSS 的存盤當中,流入以后需要做怎樣的管理和規劃;第二個就是為了支持上層的業務,如何選擇計算引擎,接下來我們帶著這兩個問題開始今天的分享,
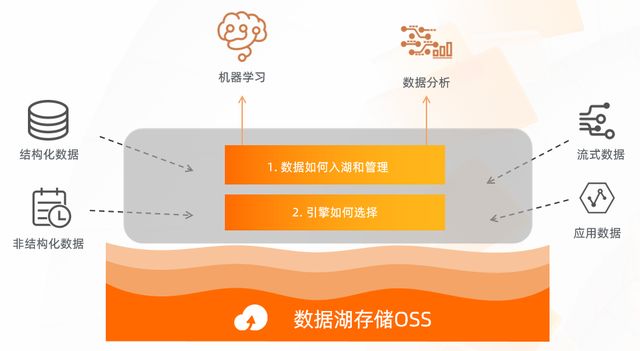
二、資料湖的構建
如何進行資料湖構建與管理
如何搭建資料湖
- 存盤配置
- 開通 OSS 存盤
- 配置存盤
- 元資料配置
- 元資料服務搭建
- 創建元資料
- 遷移元資料
- 資料遷移
- 實時資料/全量資料入湖
- 資料清洗
- 更新元資料
- 安全管理
- 資料權限配置
- 資料審計
- 資料計算與分析
- 互動式分析
- 資料倉庫
- 實時分析
- 可視化報表分析
- 機器學習
需要解決的問題:
- 元資料服務搭建復雜,維護成本較高
- 實時資料入湖,開發周期長,運維成本高,需要構建流計算任務SparkStreaming/Flink 對資料進行清理
- 多個計算引擎,需要配置多套元資料,且需要考慮元資料同步,同步的準確性,實時性等問題
- 湖上的不同計算引擎使用了不同的權限體系,同一個資源的權限需要在多個引擎多次配置,配置和維護成本高
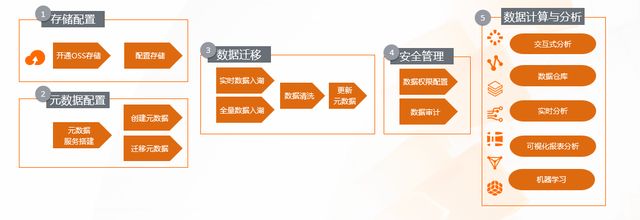
首先我們來看資料湖的構建,如果我們沒有一個標準的云產品,我們在云上怎么樣去搭建資料湖呢?我拆解了一下,大概需要五部分,
首先要選擇一個存盤,我們開通了 OSS 服務以后,選擇一個 burket,然后做一些基本的配置,第二步就是資料已經存到 OSS 以后,如何管理資料的元資料,這里面可能會涉及到目錄的編排、scheme 的設計等,這一步其實是非常重要的,因為它會關系到后面的運算,在資料湖計算當中,存盤是統一,計算是支持多類計算引擎的,所以我們在設計元資料的時候,需要考慮如何讓它被所有的計算引擎去消費;當計算引擎對資料做了變更以后,元資料怎么樣做到同步,保持一致性,元資料設計完以后,我們就需要考慮重頭戲--資料的遷移,我們知道資料通常分為兩大部分,一個是原始的歷史資料怎么全量到云上,這部分我們會通過一些工具,一次性的把它匯入到 OSS 當中;還有一個需要去考慮的就是增量資料怎么樣能夠實時的入湖,入湖以后選擇什么樣的格式?這些資料進入資料湖以后,是否需要修改,修改的話對上面的引擎有沒有影響?資料變了以后,對元資料怎么樣把這個訊息帶過去?以上是我們在做資料遷移時需要考慮和解決的問題,
然后就是安全,我們知道資料湖雖然是開放的,但是訪問權限是有限制的,不能所有用戶都可以訪問這些資料,所以我們要有一個統一的權限規劃,這里面我們需要考慮的問題是,這個權限是否可以被所有的引擎所讀到和了解?如果我用了五種引擎,每一種引擎都設定他自己的權限和配置,這樣對于使用和運維其實都是非常大的一個困擾,
資料湖構建 Data Lake Formation
- 元資料管理
- 統一元資料管理,對接多種計算引擎
- 兼容開源生態API
- 自動生成元資料,降低使用成本
- 提供一鍵式元資料遷移方案
- 訪問控制
- 集中資料訪問權限控制,多引擎統一集中式賦權
- 資料訪問日志審計,統計資料訪問資訊
- 資料入湖
- 支持多種資料源入湖,MySQL、Polardb、SLS、OTS、Kafka等
- 離線/實時入湖,支持Delta/Hudi等多種資料湖格式
- 資料探索
- 支持便捷的資料探查能力,快速對湖內(OSS)資料進行探索與分析
- 支持 Spark SQL 語法
基于前面的這些問題,在阿里云上,我們提供了這樣一個產品幫助大家來完成資料湖的構建,這個產品叫 Data Lake Formation,簡稱 DLF,DLF 主要提供了四個能力,首先是資料的入湖,我們知道資料源是多種多樣的,所以 DLF 資料入湖的這個功能,也是支持了阿里云上很多比較通用和標準的資料源,比如 MySQL,SLS、 Kafka 等等,針對入湖,用戶可以選擇不同的入湖方式,離線還是實時、資料以什么格式進入?包括在入湖的程序當中,是否加入一些簡單的計算,對這些資料做一些清理?或者加入一些自定義 UDF,以上這些能力在 DLF 當中都是支持的,然后資料進入以后,元資料的部分,我們對外會提供了一個統一的元資料介面,這個介面是可以被阿里云上的大部分引擎去消費的,包括 EMR、Databricks、PAI、 MaxCompute、Hologres 等等,并且這個元資料是支持一鍵同步的,比如我在 RDS 里面有一份元資料,轉化成資料湖的方案以后,庫表資訊可以通過一鍵的方式同步到 DLF 當中,第三點就是權限的配置,用戶只需要設定一次,比如某一個用戶,對某一份資料有怎樣的讀取權限,設定好之后就可以被上面所有的引擎所共用,在這基礎之上,DLF 還提供一個叫資料探索的能力,這個是一個開箱即用的功能,用戶資料進入到資料湖以后,可以通過它做一個快速的驗證,可以輸入標準的 Spark SQL 語法,然后就可以查詢出結果是不是用戶所需要的,來驗證這個資料的正確性,

三、資料湖的計算
阿里云 EMR 開源大資料平臺
說完了前面的資料湖構建以后,下一部分就是計算,其實在阿里云上,我們有一個產品叫 EMR,與其說 EMR 是一個產品,不如說它更像是一個開源大資料平臺,在這個平臺上,我們提供非常多的 Hadoop 開源生態引擎,用戶幾乎可以在這里面找到所有能夠滿足業務場景的引擎,首先 EMR 是構建在云原生的基礎資源之上的,它是構建在 ECS 之上的,如果你有 ACK 的容器服務,也可以部署在容器上,然后存盤的話,可以存到 OSS 上,然后有一個基礎的管控平臺,在這個平臺上,會給用戶提供一些運維部署、資源管理、彈性伸縮等等這樣的能力,最終目的就是幫助用戶更簡單,更容易的去運維大資料集群,然后 EMR 的引擎部分,一共提供了幾十種不同的豐富的引擎,這里面羅列了幾個比較代表性的,用戶可以根據不同的業務需求去選擇,值得一提的是,所有的引擎都可以作為資料湖的引擎,可以去消費 OSS 資料,把 OSS 作為它的最終存盤,同時它可以對接到 DLF 上面,用戶做完了元資料的配置、權限的配置后,就可以很方便的在 EMR 上去切換不同的引擎,這樣可以達到元資料的統一和資料的統一,
主要解決兩大問題
- 降低成本
- 硬體成本
- 改造和使用成本
- 運維成本
- 提高效率
- 性能
- 資源利用率
- 可擴展性
我們自己構建大資料平臺的時候,其實比較關心的核心的兩個問題,一個是成本,還有一個就是效率,這個也是 EMR 主要去解決的兩個問題,這里面的成本其實包括三個方面,硬體的成本、軟體的成本,還有后期運維的成本,相信這些是大家在線下去構建自己的大資料平臺當中,一定會遇到的非常頭疼和急需面對的問題,另外與它相對應的效率,我們希望能夠最大限度的去提高資源的利用率,同時希望集群是具有靈活性和可擴展性的,接下來我們看一下 EMR 是怎么樣去解決這兩個問題的,
全新容器化部署EMR on ACK
- 節省成本
- 復用已有 ACK 集群的空閑資源
- 大資料和在線應用程式共享集群資源,削峰填谷
- 簡化運維
- 一套運維體系,一套集群管理
- 提升效率
- 利用 ACK/ECI 的資源快速交付能力,資源獲取時間更短;
- 結合自研 Remote Shuffle Service,Spark 內核及資源調度優化,滿足生產級業務需求
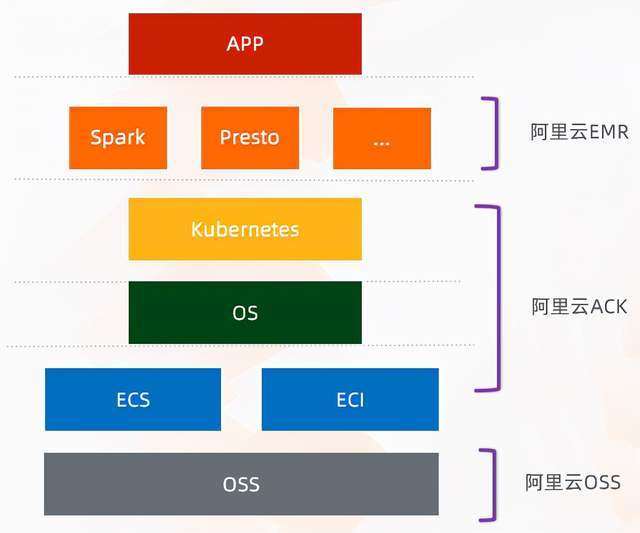
首先,EMR 在今年推出了一個新的特性,就是容器化的部署方案,之前傳統的 EMR 都是部署在 ECS 上的,現在 EMR 可以部署在 ACK 上,這里的 ACK 其實是一個已有的 ACK 集群,隨著大資料生態的發展,Kubernetes 這個技術也越來越成熟,很多用戶會把自己在線的業務,甚至是一些在線的作業去跑在 ACK 集群上,但是在線的業務有一個特點,它使用的時間通常在白天,這樣就造成了晚上這部分計算資源的空閑,相比較大資料而言,很多是為了支持報表類的業務,所以它使用資源的高峰期大多在晚上,如果能夠把大資料作業和在線作業跑在一套系統里面,對用戶來說就達到了削峰填谷、資源重復利用的能力,同時從運維的角度,只需要運維一套 ACK 的集群,這樣就可以統一運維體系,降低運維成本,從 EMR 這一側的引擎來說,從開源上大資料跑在 ACK 上,其實還是一個相對初期的階段,可能它有一些特性在企業級的應用上是沒辦法支持的,基于這一點,EMR 也做了很多引擎上的優化,包括提供了這種 Remote Shuffle 的能力,它主要是為了解決在 ACK 上的掛盤問題,另外在調度上面也做了很多深入的優化,能夠滿足用戶大資料量的企業級的查詢分析需求,
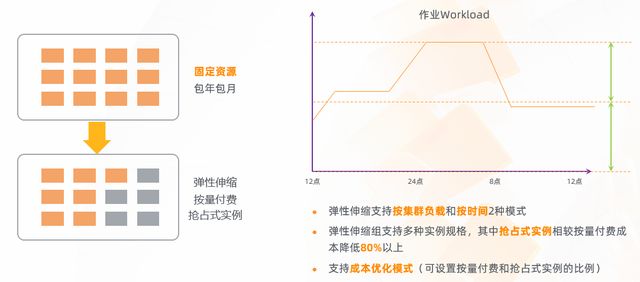
彈性伸縮
EMR 集群:固定資源 -> 固定資源 + 彈性動態資源
和線下的 IDC 集群相比,云上最顯著的一個特性就是動態和可擴展性,為了最大限度的發揮這部分的價值, EMR 提供了集群級別的彈性伸縮,簡單來說就是比如原先有一個集群,這個集群是固定的,假設有100臺節點,7×24小時去跑,但其實在這100臺節點當中,可能大部分時間只用了里面50%的能力,這個時候會把集群做一個拆分,一部分只保留固定的計算資源,其他的高峰期則用一個彈性的資源去彌補,這樣就可以從硬體資源的使用上面去壓縮成本,另外在 EMR 里面,對于彈性資源的部分是支持成本優化模式的,在 ECS 里面它有一種實力叫挑戰式的實力,這種實力它的收費方式會比按量付費更便宜,這樣就可以進一步的壓縮計算的成本,真正做到按需創建機器資源,用戶去談這部分資源的時候,也可以按照自己的集群的負載或者是時間段去靈活的控制,
引擎優化
Spark
- 支持Spark 3.1.2,相對社區版Spark 2,性能提升3倍以上
- 針對復雜分析場景優化,TPC-DS較社區版提速59%
- 在ACK場景下,優化了調度性能,較社區版K8S有4倍提升
Hive
- TPC-DS 特定 SQL 達到數倍性能提升,整體性能提升19%;
- 針對大表 Join 的性能優化
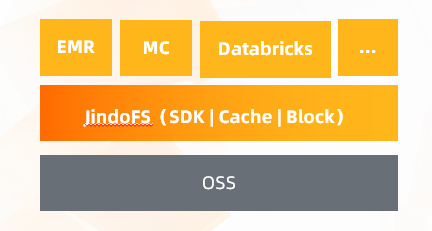
JindoFS
- OSS 訪問加速,提供標準的 HDFS 訪問介面,支持 EMR 所有引擎
- 冷熱資料自動分離,對計算層透明
- 對檔案的 ls/delete/rename 等操作,較開源方案性能數倍提升
傳統的大資料集群是跑在 Hadoop 生態下面的,它本身的存盤是 HDFS ,轉換到資料湖以后,當你的介質變成了不是本地的 OSS 時,需要引擎上面做很多支持,我列舉了幾個比較有代表性的,比如 Spark、Hive,在官方的 TPC-DS上面可以看到我們的成績是優于社區數倍的,另外值得一提的就是 JindoFS ,這個組件是 EMR 自研的一個組件,可以把它看做承上啟下的作用,對下面底層的話,它的資料還是存盤在 OSS 上面,對上層的引擎除了在介面上面的支持以外,更多的是對 OSS 的訪問做了一個加速,并且讓引擎能夠很透明的去使用 OSS,資料落進來以后可以做到自動的冷熱分離,并且我們和 OSS 團隊做了深度的優化,OSS 在做一些檔案級別的操作,尤其是小檔案的操作上面,性能都要比開源的方案或者甚至有的場景下會比 HDFS 的性能更好,
豐富的生態
- 更多開源組件
ClickHouse、StarRocks、EMR Studio(Notebook,AirFlow)、Spark 3.0 等
- 深度云產品集成
阿里云 DataWorks、阿里云容器服務(ACK)、云監控等
- 支持更多三方產品
Databricks、Cloudera、Confluent、神策等
EMR 更多的是一個開源的開放的大資料平臺,在這個平臺上面不僅有開源的產品,這部分的組件會根據市場情況逐步增加到平臺中,除此以外,作為阿里云上的一款產品,EMR 會和像 DataWorks、ACK、甚至還有云監控等產品做一個深度的集成,方便大家能充分利用阿里云上其他云產品的特性,除此之外,EMR 還會支持更多的第三方產品,比如 Databricks、Cloudera、Confluent、神策等來讓平臺有更好的擴展性和可集成性,
使用 EMR 降本增效
- 使用彈性伸縮,動態調整集群規模,按需購買 ECS 資源
- 利用已有 ACK 集群,大資料和在線應用共享計算資源
- EMR 計算引擎的優化,提高任務執行效率
- OSS 訪問利器 JindoFS,讓遷移更平滑
最后總結一下,其實 EMR 能夠達到降本增效主要是從硬體和軟體兩方面,硬體上讓計算更按需進行,不會有過多資源上的浪費;軟體上通過提升引擎的性能來做到加速,讓單位的計算的成本更低,
四、小結
回到最開始提到的問題,構建資料湖的時候,我們首先會使用 DLF 來完成資料的入湖和元資料的管理;通過 EMR 上豐富的引擎來構建計算平臺;然后利用 OSS 的存盤來發揮最大的價值,做資料的冷熱分層,從而使整體的資料湖方案能夠達到降本增效的目的,
原文鏈接
本文為阿里云原創內容,未經允許不得轉載,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350854.html
標籤:其他