^_^
1.配置本地hadoop
Hadoop2.7.5鏈接:https://pan.baidu.com/s/12ef3m0CV21NhjxO7lBH0Eg
提取碼:hhhh
將下載的hadoop包解壓到D盤下方便找
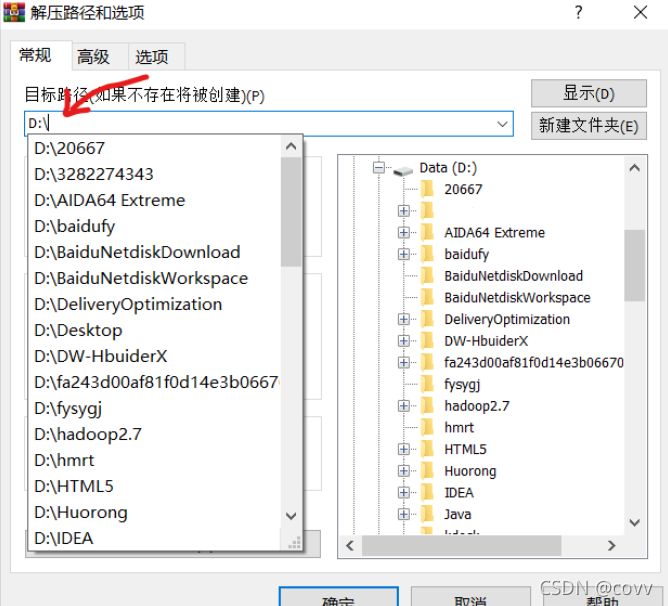
然后右擊此電腦點屬性→點擊右邊的高級系統設定→點擊環境變數→選到下面的Path,點編輯再點新建→進入hadoop包解壓過后的下一級bin目錄,把完整的路徑復制到里面
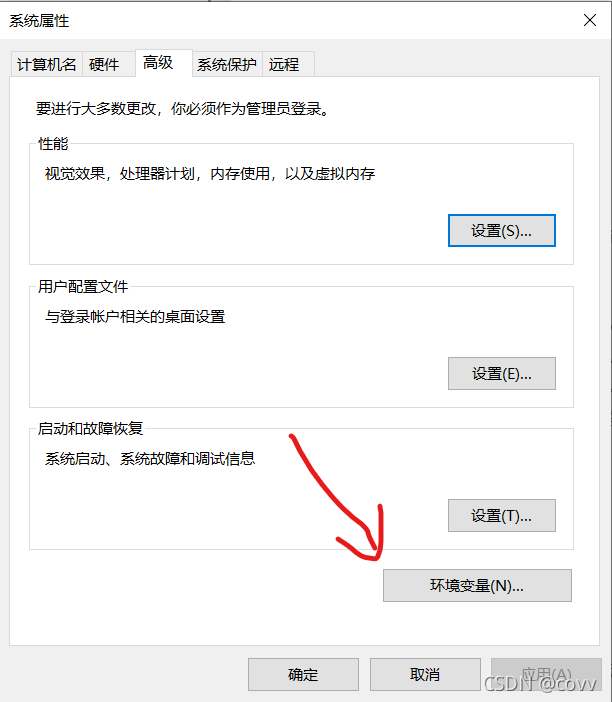
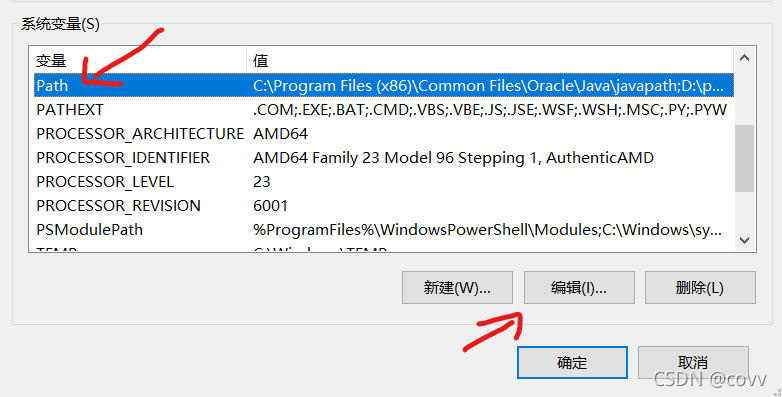

然后注銷一下機器 ,使檔案生效
然后可以win+R 打開命令列 輸入:hadoop -version 查看
2.配置Maven 阿里源
Maven3.6鏈接:https://pan.baidu.com/s/1_4MT6v2RZMiSccsUoMX_TQ
提取碼:hhhh
將下載的maven包解壓到D盤下方便找
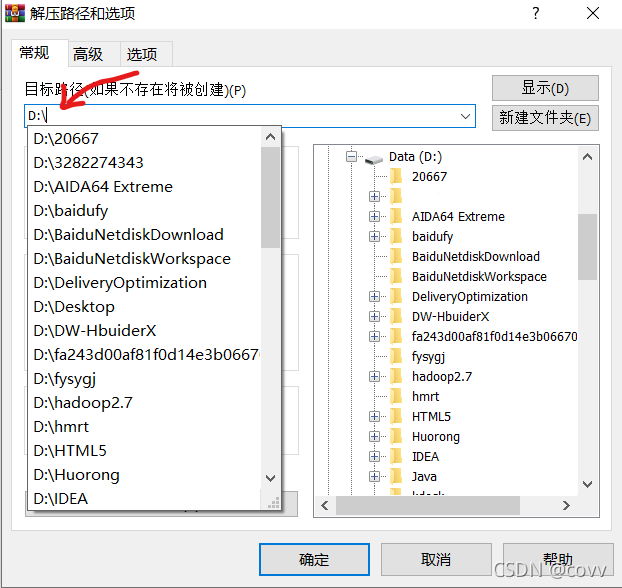
然后右擊此電腦點擊屬性→點擊右邊的高級系統設定→點擊環境變數→選到下面的Path,點編輯再點新建→進入maven包解壓過后的下一級bin目錄,把完整的路徑復制到里面
設定阿里云倉庫:進入到Maven目錄的conf目錄下,有一個settings.xml檔案,把下面這段代碼添加進去
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
安裝JDK1.8
如果已經安裝了可以跳過此步驟
機器原本就有jDK但是需要使用另一個JDK版本的安裝步驟:
第一步 把下載好的JDK包解壓到D盤目錄下,安裝JDK 選擇安裝目錄 安裝程序中會出現兩次 安裝提示 ,第一次是安裝 JDK ,第二次是安裝 jre ,建議兩個都安裝在同一個java檔案夾中的不同檔案夾中,
第二步 安裝完JDK后配置環境變數 計算機→屬性→高級系統設定→環境變數
第三步 系統變數→新建 JAVA_HOME 變數 , 變數值填寫jdk的安裝目錄 : D:\Java\jdk1.8.0
第五步 系統變數→尋找 Path 變數→編輯→新建 %JAVA_HOME%\bin
機器沒有JDK,需要安裝JDK:
第一步 : 把下載好的JDK包解壓到D盤目錄下,安裝JDK 選擇安裝目錄 安裝程序中會出現兩次 安裝提示 ,第一次是安裝 JDK ,第二次是安裝 jre ,建議兩個都安裝在同一個java檔案夾中的不同檔案夾中,
第二步: 安裝完JDK后配置環境變數 計算機→屬性→高級系統設定→環境變數
第三步 : 系統變數→新建 JAVA_HOME 變數 , 變數值填寫jdk的安裝目錄 : D:\Java\jdk1.8.0
第四步: 系統變數→尋找 Path 變數→編輯→新建 %JAVA_HOME%\bin
再新建一個 變數值填: %JAVA_HOME%\jre\bin
第五步: 系統變數→新建 CLASSPATH 變數
變數值填寫 .;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar(注意最前面有一點)
win+R 打開CMD命令列 輸入java -version 若顯示版本資訊則安裝成功
開始寫MR程式
第一步:打開IDEA→New Project→ 選擇Maven→ 看到上面有一個Project SDK 在這里可以選擇JDK版本 我們選擇1.8→點擊下面的Next
第二步:設定一下Maven專案的名字 ,Name 那一欄填寫 MyMRCode→ Finsh
第三步:Maven專案創建后會創建一個 pom.xml 檔案,然后把下面的代碼插入到的標簽內(使用的hadoop是什么版本就把下面的版本號修改一下,比如我使用的是2.7.5,就把標簽里的內容修改成2.7.5):
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
然后它會自己下載所需要的資源包,等待下面的進度條加載完就可以進一步寫MR程式了!
WordCount案例
然后在D盤的mr/input/目錄下新建一個word.txt檔案,并在里面寫一些單詞
Hello Hadoop
Hello Word
Hello MapReduce
? 在Maven專案的src檔案夾下新建一個package -> 在這個包下面新建一個WordCountMapper類
Map階段代碼實體:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* 這里就是mapper階段具體業務邏輯實作的方法 該方法的呼叫取決于讀取資料的組件有沒有給MR傳入資料
* 如果有資料傳入,每一個<k,v>對,map就會被呼叫一次
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// 拿到傳入進來的一行內容,把資料型別轉換為String
String line = value.toString();
// 將這行內容按照分隔符切割
String[] words = line.split(" ");
// 遍歷陣列,每出現一個單詞就標記一個陣列1 例如:<單詞,1>
for (String word : words) {
// 使用MR背景關系context,把Map階段處理的資料發送給Reduce階段作為輸入資料
context.write(new Text(word), new IntWritable(1));
//第一行 Hello Hadoop 發送出去的是<Hello,1><Hadoop,1>
}
}
}
? 在新建一個WordCountReducer 類
? 代碼實體:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text key, Iterable<IntWritable> value,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//定義一個計數器
int count = 0;
//遍歷一組迭代器,把每一個數量1累加起來就構成了單詞的總次數
//
for (IntWritable iw : value) {
count += iw.get();
}
context.write(key, new IntWritable(count));
}
}
? 再寫一個Runner類:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Runner {
public static void main(String[] args) throws Exception {
// 通過Job來封裝本次MR的相關資訊
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
// 指定MR Job jar包運行主類
wcjob.setJarByClass(Runner.class);
// 指定本次MR所有的Mapper Reducer類
wcjob.setMapperClass(WordCountMapper.class);
wcjob.setReducerClass(WordCountReducer.class);
// 設定我們的業務邏輯 Mapper類的輸出 key和 value的資料型別
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(IntWritable.class);
// 設定我們的業務邏輯 Reducer類的輸出 key和 value的資料型別
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(IntWritable.class);
// 指定要處理的資料所在的位置
FileInputFormat.setInputPaths(wcjob, "D:/mr/input/Word.txt");
// 指定處理完成之后的結果所保存的位置
FileOutputFormat.setOutputPath(wcjob, new Path("D:/mr/output"));
// 提交程式并且監控列印程式執行情況
boolean res = wcjob.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
最后再運行一下這個Runner程式!
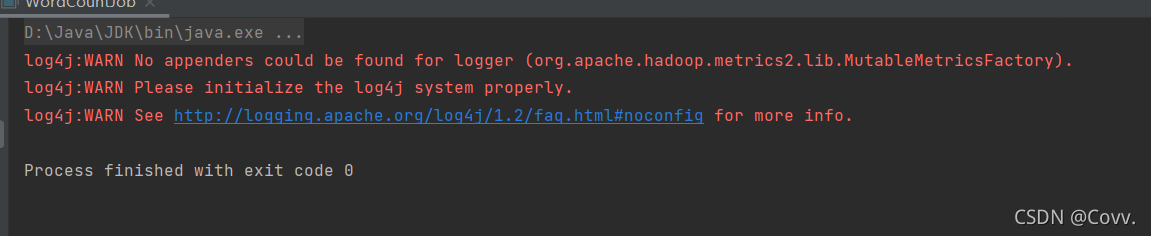
這里回傳的是0,則表示成功了!
然后在D盤的output目錄下可以查看生成的檔案.
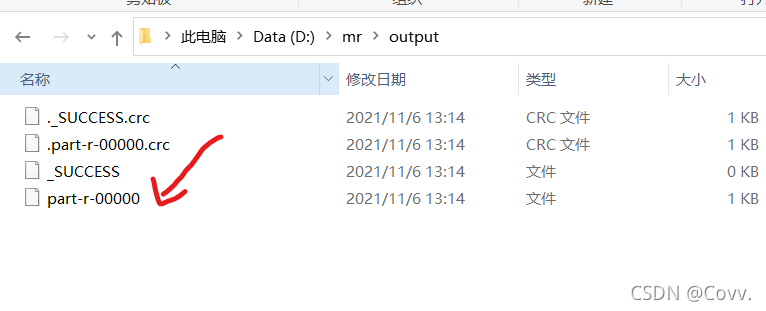
用記事本打開,就可以看到程式運行的結果!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/350861.html
標籤:其他
上一篇:分布式中間件之Kafka