上一節介紹的是LAS模型,標準的seq2seq model,因為decoder每一步其實考慮的是全部的encoder的輸出,所以沒辦法做到online的輸出,因此今天看的模型都是為了做online產生的,
先上一張李宏毅老師的模型總結圖:
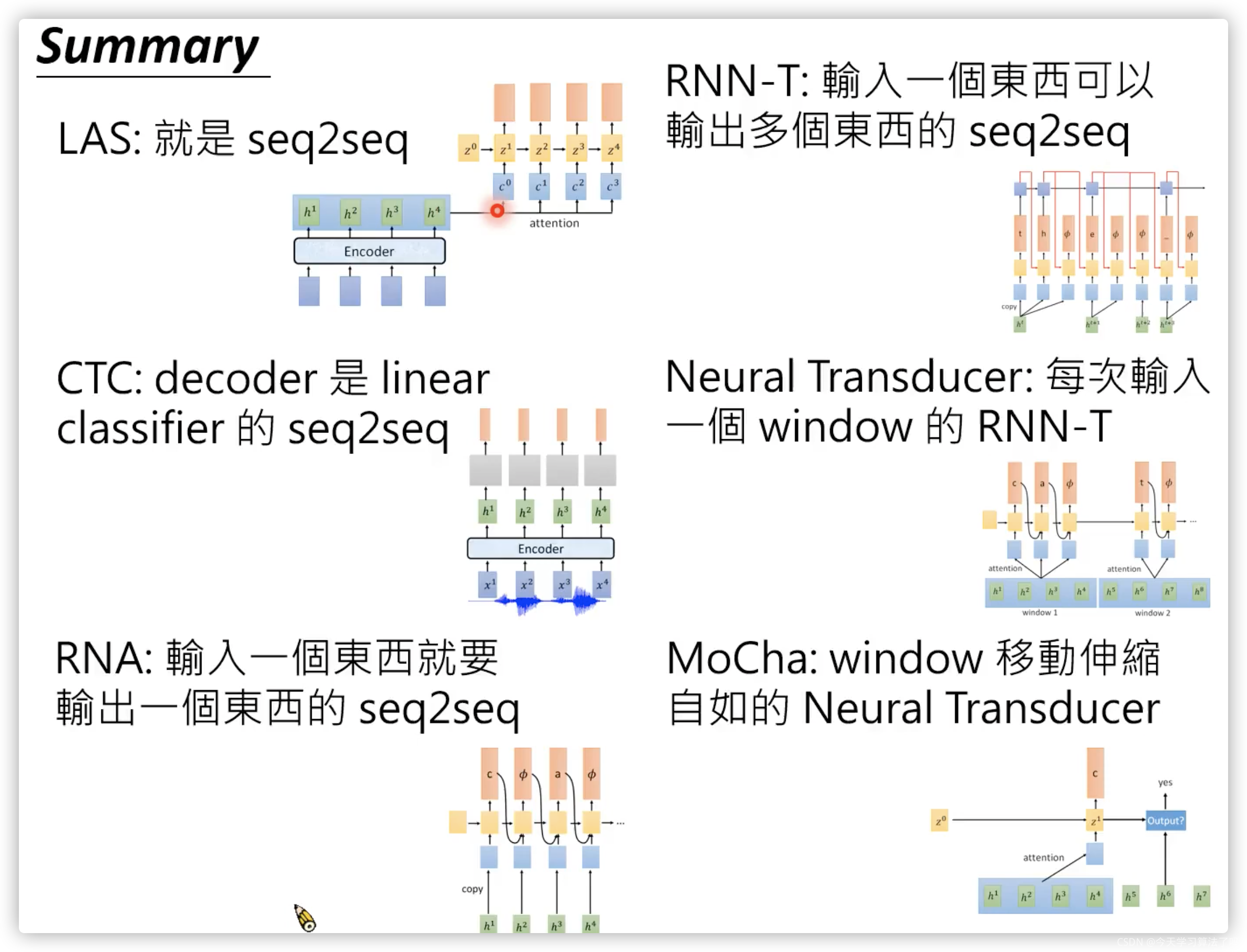
從上到下,從左到右其實是可以發現模型發展的一些規律的,
1. 語音的特點:因為語音的輸入vector個數很多,但不一定每一個都會產生輸出 ,所以采用的方法有:1)在vocab中增加,表示該語音輸入不對應任何輸出,這種方法在訓練的時候很麻煩,因為資料集中的label是沒有
的,而且通常輸入和輸出個數差距比較大,即
的個數會比較多,那么其所在的位置是很多樣的,而目前的模型確實是把所有可能都當成label去訓練(老師說有一種演算法,但是目前還沒有講到),2)既然一個輸入不一定對應,那我就輸入多個(window),只需要確保該window有輸出即可,所以問題變成怎么判斷該視窗有沒有輸出呢?MoCha模型,
第一種方法就是以輸入為主,輸出個數=輸入,label比較難產生,第二種以輸出為主,label確定,但是在模型中需要用網路判斷當前輸入是否為視窗,感覺Neural Transducer是位于兩種方法之間的,
2. 其次,一個音符可能會產生多個輸出,比如“th"只發一個音,所以要模型學會動態的輸出,看RNN-T模型結構,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352058.html
標籤:其他