以下操作除特殊說明外都在三個節點上操作,
注意:操作前務必使三臺虛擬機可以互相免密通信!
一、安裝Scala軟體包
使用xftp將軟體包上傳至三臺虛擬機的/usr/package檔案夾下
創建作業目錄
mkdir -p /usr/scala解壓縮
cd /usr/package
tar -zxvf scala-2.12.12.tgz -C /usr/scala配置環境變數
vi /etc/profile加入以下內容

保存后退出,使環境變數生效
source /etc/profile檢驗是否安裝成功
scala -version出現以下界面則為安裝成功

二、安裝Spark軟體包
使用xftp將軟體包上傳至三臺虛擬機的/usr/package檔案夾下
創建作業目錄
mkdir -p /usr/spark解壓縮
cd /usr/package
tar -zxvf spark-3.0.3-bin-hadoop2.7.tgz -C /usr/spark配置環境變數
vi /etc/profile加入以下內容

使環境變數生效
source /etc/profile三、修改組態檔,指定主節點
進入相應的目錄,并修改檔案的名字
cd /usr/spark/spark-3.0.3-bin-hadoop2.7/conf
mv spark-env.sh.template spark-env.sh追加以下內容
export SPARK_MASTER_IP=master
export SCALA_HOME=/usr/scala/scala-2.12.12
export JAVA_HOME=/usr/java/jdk1.8.0_221
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.2
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.2/etc/hadoop
配置spark的從節點,修改slaves檔案
mv slaves.template slaves
vi slaves將原有檔案的最后一行的localhost洗掉,追加以下內容

四、開啟集群環境, 查看集群狀態(只在master)
開啟hadoop集群
cd /usr/hadoop/hadoop-2.7.2/
sbin/start-dfs.sh
sbin/start-yarn.sh開啟spark集群
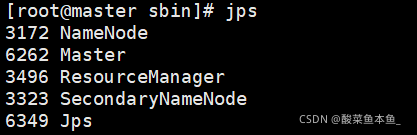
./sbin/start-all.sh查看master節點,出現Master行程則為成功
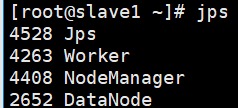
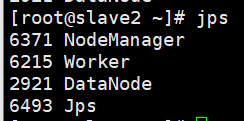
查看slave1和slave2節點,出現Worker行程則為成功
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352076.html
標籤:其他
上一篇:Docker的常用命令
下一篇:SSH快速入門