文章目錄
- Kubernetes 入門教程詳解(一)
- 一、 Kubernetes 概述
- 1. K8S 發展歷史由來
- 2.K8S官網
- 2.K8S 是什么
- 3. K8s 優勢及特點
- 3.1 K8S優勢
- 3.2 K8S 特點
- 4. K8s 集群架構與組件
- 4.1 K8s 集群架構
- 4.2 K8s 核心組件詳細說明
- 5. K8s 核心概念
- 5.1 Master 集群控制節點
- 5.2 Node 作業負載節點
- 5.3 Pod kubernetes的最小控制單元
- 5.4 Controller 控制器Pod
- 5.4.1 復制控制器(Replication Controller,RC)--- 確保預期的Pod副本數量
- 5.4.2 副本集(Replica Set,RS)--- 確保預期的Pod副本數量
- 5.4.3 HPA
- 5.4.4 StatefulSet ---為了解決有狀態服務的問題
- 5.4.5 部署(Deployment)
- 5.4.6 Job、Cron Job 負責批處理任務
- 5.5 服務發現(Service)
- 5.6 Lable 標簽
- 5.7 Ingress
- 5.8 NameSpace 命名空間
- 6.K8S 的網路通訊方式
- 6.1 同一個Pod 內的多個容器之間通訊:localhost
- 6.2 各個Pod之間的通訊:Overlay Network
- 6.3 Pod 與Service 之間的通訊:各節點的Iptables(LVS轉發)
- 6.4 通訊總結
- 7.K8s里面的三張網路
- 二、總結
Kubernetes 入門教程詳解(一)
一、 Kubernetes 概述
1. K8S 發展歷史由來
-
它前生是 谷歌的Borg 系統,后經過Go 語言重寫,在 2014 年開源了 Kubernetes 專案,并捐獻給CNCF 基金會開源,即
Kubernetes, -
它之所以簡稱 ‘k8s’,因為
Kubernetes中間有 8個字母 -
2.K8S官網
- kubernetes的github地址:
https://github.com/kubernetes/kubernetes
- kubernetes官方站點:
- 英文官方網址:
https://kubernetes.io/ - z中文官方網站:
https://kubernetes.io/zh/ - 英文官方檔案:
https://kubernetes.io/docs/
- 英文官方網址:
2.K8S 是什么
-
Kubernetes是一個可移植的、可擴展的開源平臺,用于管理容器化的作業負載和服務,可促進宣告式配置和自動化, Kubernetes 擁有一個龐大且快速增長的生態系統,Kubernetes 的服務、支持和工具廣泛可用, -
Kubernetes這個名字源于希臘語,意為“舵手”或“飛行員” -
官網:https://kubernetes.io/
-
GitHub:https://github.com/kubernetes/kubernetes
-
具有
輕量級、消耗資源小、開源、彈性伸縮、負載均衡(IPVS)的特點
3. K8s 優勢及特點
3.1 K8S優勢
- 自動裝箱,水平擴展,自我修復
- 服務發現和負載均衡
- 自動發布和回滾
- 集中化配置管理和密鑰管理
- 存盤編排
- 批處理:提供一次性任務,定時任務;滿足批量資料處理和分析的場景
3.2 K8S 特點
- 可移植: 支持公有云,私有云,混合云,多重云(multi-cloud)
- 可擴展: 可根據業務流量情況快速擴展kubernetes集群的節點數量,
- 自愈: 自動發布,自動重啟,自動復制,自動擴展
- 行程協同:利用復合應用保證應用和容器一對一的模型,
4. K8s 集群架構與組件
4.1 K8s 集群架構
-
集群架構
Kubernetes集群包含有節點代理`kubelet`和`Master組件`(APIs, scheduler, etc),一切都基于分布式的存盤系統, 一個kubernetes集群主要是由 控制節點(master)、作業節點(node)構成,每個節點上都會安裝不同的組件, 下面這張圖是Kubernetes的架構圖, -
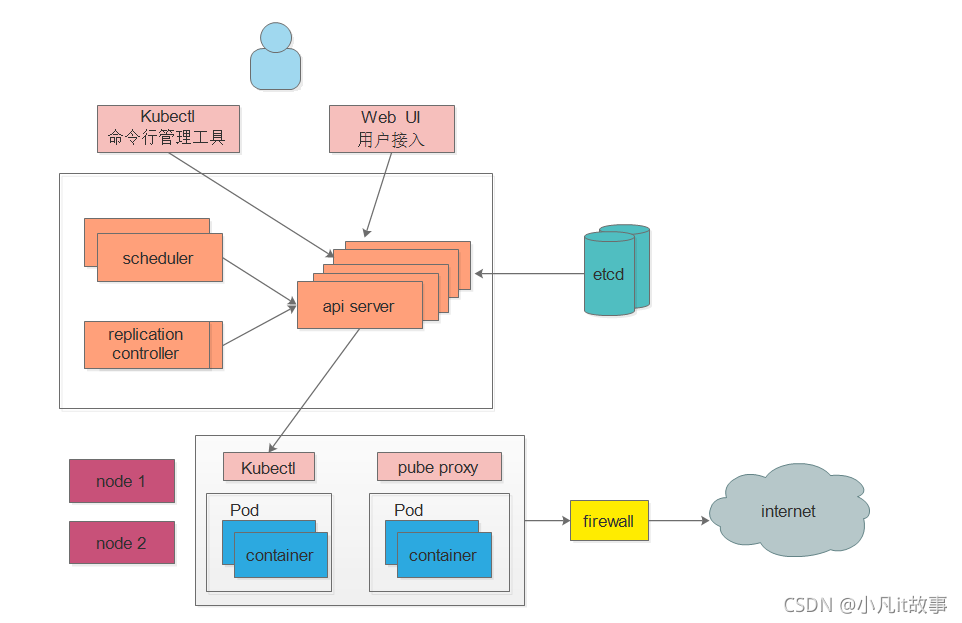
控制節點:
ApiServer : 資源操作的唯一入口,接收用戶輸入的命令,提供認證、授權、API注冊和發現等機制
Scheduler : 負責集群資源調度,按照預定的調度策略將Pod調度到相應的node節點上
ControllerManager : 負責維護集群的狀態,比如程式部署安排、故障檢測、自動擴展、滾動更新等
Etcd :負責存盤集群中各種資源物件的資訊(默認的資料庫,自己可以配置修改的,比如配mysql)
作業節點Node:
Kubelet : 負責維護容器的生命周期,即通過控制docker,來創建、更新、銷毀容器
KubeProxy : 負責提供集群內部的服務發現和負載均衡
Docker : 負責節點上容器的各種操作
# 大致作業原理
kubectl 和web UI接入我們master節點后,scheduler調度器將任務交給api server, 通過api server 把任務寫入 etcd 存盤服務器,然后交給node節點執行
控制器,它們就是維護我們的副本的數目的或者叫做我們的期望值的,一旦它的副本數不滿足我們的期望值,replication controller就會將它改寫成 我們的期望值(創建或洗掉Pod數)
# 以安裝nginx服務說明K8S組件呼叫關系:
首先要明確,一旦kubernetes環境啟動之后,master和node都會將自身的資訊存盤到etcd資料庫中
1. 一個nginx服務的安裝請求會首先被發送到master節點的apiServer組件
2. apiServer組件會呼叫scheduler組件來決定到底應該把這個服務安裝到哪個node節點上
在此時,Scheduler調度器會從etcd中讀取各個node節點的資訊,然后按照一定的演算法進行選擇,并將結果告知apiServer,分發給那個node
3. apiServer呼叫controller-manager(控制器)去調度Node節點安裝nginx服務
4. kubelet接收到指令后,會通知docker,然后由docker來啟動一個nginx的pod
pod是kubernetes的最小操作單元,容器必須跑在pod中,此時nginx服務就已經跑起來了,
5. 一個nginx服務就運行了,如果需要訪問nginx,就需要通過kube-proxy來對pod產生訪問的代理
4.2 K8s 核心組件詳細說明
-
核心組件說明
#控制器,它們就是維護我們的副本的數目的或者叫做我們的期望值的,一旦它的副本數不滿足我們的期望值,replication controller就會將它改寫成 我們的期望值 # api 一切服務的訪問入口,壓力很大,為了減輕壓力,每個請求下面就可以生成快取 # etcd 是 paxos 鍵值對采用go 語言撰寫的鍵值對 資料庫, etcd 的官方 將它 定位成一個 可信賴的分布式鍵值存盤服務器,它能夠為整個分布式集群存盤一些關鍵資料,協助分布式集群的正常運轉, 可信賴:本身可以完成集群化 分布式:擴容縮非常方便 正常運轉:保存我們的整個分布式集群的需要持久化的組態檔、配置資訊,一旦我們的集群死亡后,我們可以借助到etcd 里面的一些資訊,進行資料恢復 ectd 里面有2個版本,一個是 v2版,一個是v3版,v2版會將資料全部寫入 記憶體中,v3 版本會引入本地卷的持久化操作(關機以后并不會造成資料損壞) 推薦使用kubernetes 集群中etcd v3, V1.11包含之前自帶的的etcd是不支持V3的, ETCD 鍵值資料庫 是基于HTTP,進行的C/S開發的, 他有 這些組件 Raft:存盤我們的讀寫資訊的(所有的資訊都存在這里) WAL:預寫日志:為了防止Raft里面的資訊出現損壞,還有WAL預寫日志 (如果想對里面的資料進行更改,需要先生成一個日志,WAL先存一下,并且會定時的對這些日志進行完整的備份[完整+臨時備份]) Entry: Snapshot:日志備份{完整備份+增量備份} # node 節點:安裝 kubelet 、kube proxy、 container(Docker) 在Node節點上實作Pod網路代理,維護網路規則和四層負載均衡作業, kubelet:會跟我們的CRI(C 容器;R 運行環境; I 介面)---這里就是我們的Dokcer表現形式 ,它會和我們的Docker進行互動,操作Docker去創建對應的容器[就是Kubelet維持我們Pod的生命周期] Kube proxy:相當于SVC,可以進行負載操作,也就意味著如何實作Pod與Pod之間如何訪問,包括負載均衡,它的默認操作時firewall,操作防火墻,實作對Pod的映射,(新版本中還支持IPVS 實作負載均衡) # 總結這些節點 api server:所有服務訪問統一入口 CrontrollerManager:維持副本期望數 Scheduler:負責介紹任務,選擇合適的節點進行分配任務, etcd:鍵值對資料庫,存盤K8S集群所有重要資訊(持久化) kubelet:直接跟容器引擎互動實作容器 的 生命周期管理 kube-proxy:負責寫入規則至iptables(firewall)、ipvs(負載均衡) 實作服務映射訪問的 -
其它組件介紹
#CoreDNS : 可以為集群中的svc 創建一個域名IP的對應關系決議 #Dashboard: 給k8s提供一個B/S 結構訪問體系 #Ingress controller: 官方實作了四層代理,Ingress 可以實作七層代理 #Federation: 提供一個可以跨越集群中心多k8s 統一管理功能 #Prometheus: 提供k8s 集群的監控能力 #ELK: 提供k8s 集群日志 統一 分析接入平臺
5. K8s 核心概念
5.1 Master 集群控制節點
- 每個集群至少一個master節點負責集群的管理
5.2 Node 作業負載節點
- 由masster 分配容器到這些node節點上,然后node 節點上的docker 負責容器運行
5.3 Pod kubernetes的最小控制單元
-
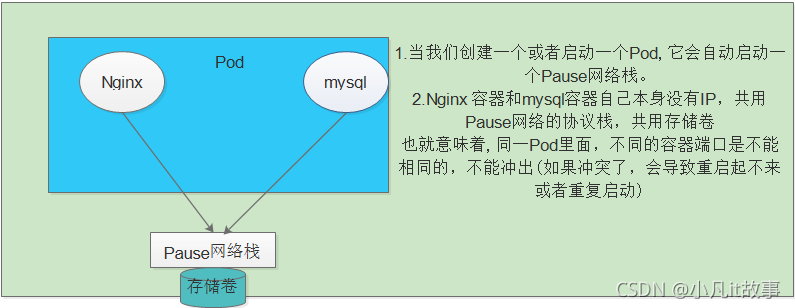
**自主式pod **
Pod是在K8s集群中運行部署應用或服務的最小單元(原子單元),它是可以支持多容器的, 只要我們定義了一個Pod,它就會自動啟動一個容器---pause的網路堆疊,也就意味著同一個Pod 容器間的埠不能沖突 一個Pod里封裝了很多個容器,他們共用一個pause,共用存盤卷 -
5.4 Controller 控制器Pod
-
控制器,通過它來實作對pod的管理,比如啟動pod、停止pod、伸縮pod的數量等等
-
K8S內核提供了眾多的pod控制器,常用的有:
Deployment 部署(暴露在最外面的) DaemonSet 要求每一個運行節點都啟動一個 ReplicaSet StatefulSet Job Cronjob
5.4.1 復制控制器(Replication Controller,RC)— 確保預期的Pod副本數量
-
RC 控制器
Replication Control1er 用來確保容器應用的副本數始終保持在用戶定義的副本數,即如果有容器例外退出,會自動創建新的Pod 來替代;而如果例外多出來的容器也會自動回收,在新版本的Kubernetes 中建議使用ReplicaSet來取代 ReplicationControl1e
5.4.2 副本集(Replica Set,RS)— 確保預期的Pod副本數量
-
RS副本集
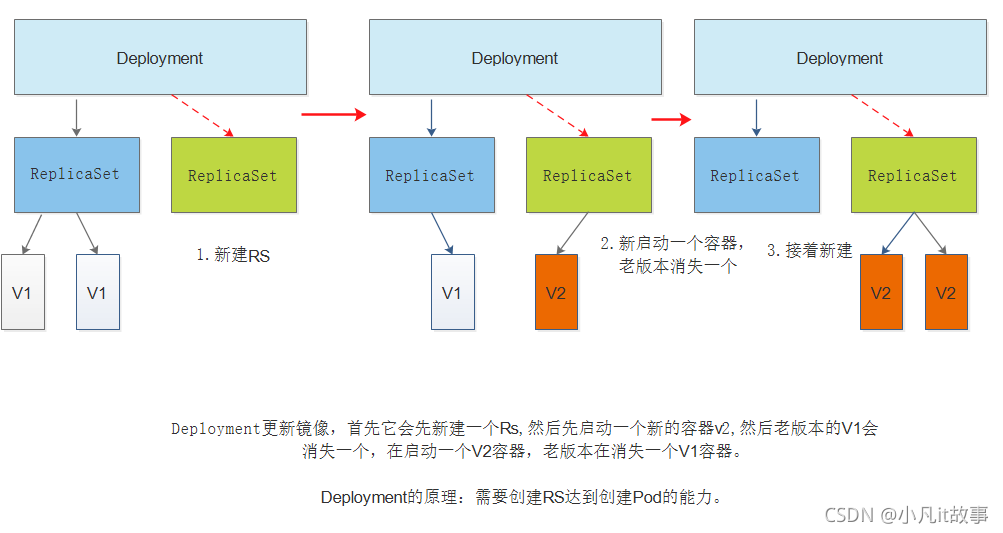
ReplicaSet跟Replication Controller沒有本質的不同,只是名字不一樣,并且ReplicaSet支持集合式的selector 雖然ReplicaSet可以獨立使用,但一般還是建議使用 Deployment來自動管理ReplicaSet ,這樣就無需擔心跟其他機制的不兼容問題(比如 ReplicaSet不支持rolling update {滾動更新}但 Deployment支持) -
5.4.3 HPA
-
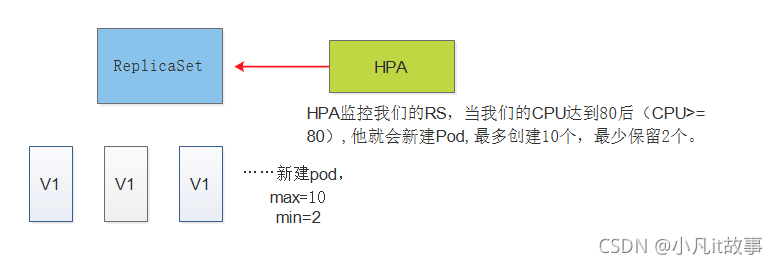
HPA
HPA監控我們的RS,當我們的CPU達到80后(CPU>=80),他就會新建Pod,最多創建10個,最少保留2個, 如果高于80,就創建,小于80不在創建, -
5.4.4 StatefulSet —為了解決有狀態服務的問題
-
StatefulSet
StatefulSet是為了解決有狀態服務的問題(對應 Deployments 和 ReplicaSets是為無狀態服務而設計), 其應用場景包括: 1.穩定的持久化存盤,即 Pod重新調度后還是能訪問到相同的持久化資料,基于PVC來實作 2.穩定的網路標志,即 Pod重新調度后其 PodName和 HostName不變,基于 Headless Service(即沒有Cluster IP的Service )來實作 3.有序部署,有序擴展,即 Pod是有順序的,在部署或者擴展的時候要依據定義的順序依次依次進行(即從О到N-1,在下一個Pod運行之前所有之前的 Pod必須都是Running 和 Ready狀態),基于init containers來實作 4.有序收縮,有序洗掉(即從N-1到0>
5.4.5 部署(Deployment)
-
Deployment
DaemonSet確保全部(或者一些)Node 上運行一個Pod 的副本,當有Node加入集群時,也會為他們新增一個Pod ,當有Node從集群移除時,這些 Pod 也會被回收,洗掉 DaemonSet將會洗掉它創建的所有Pod 運行集群存盤daemon,例如在每個Node 上運行glusterd、cepho. 在每個Node上運行日志收集daemon,例如fluentd、logstash, 在每個Node上運行監控daemon,例如Prometheus Node Exporter
5.4.6 Job、Cron Job 負責批處理任務
-
Job、Cron Job
Job 負責批處理任務,即僅執行一次的任務,它保證批處理任務的一個或多個Pod 成功結束 Cron Job管理基于時間的 Job,即: 在給定時間點只運行一次 周期性地在給定時間點運行
5.5 服務發現(Service)
-
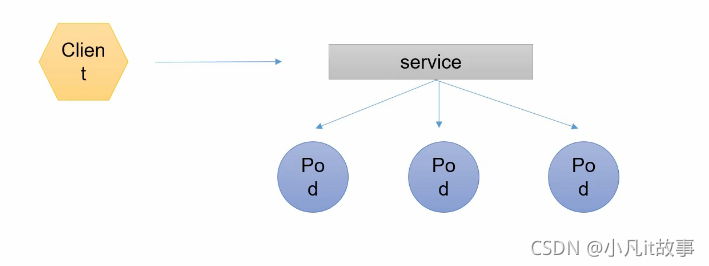
pod 對外服務的統一入口,可以維護同一類的多個Pod
在K8S里,雖然每個POD都會被分一個單獨的IP地址,但這個IP地址會隨著POD的銷毀而消失,Service 就是來解決這個問題的核心概念 一個service 可以看作一組提供相同服務的Pod的對外訪問介面 Service 作用于哪些Pod 是通過標簽選擇器來定義的 一個 Service 在 Kubernetes 中是一個 REST 物件,和 Pod 類似, 像所有的 REST 物件一樣, Service 定義可以基于 POST 方式,請求 apiserver 創建新的實體, -
5.6 Lable 標簽
-
標簽,用于對Pod進行分類,同一類POD會擁有相同的標簽
-
附加到某個資源上,用于關聯物件、查詢和篩選
給資源打上標簽后,可以使用標簽選擇器過濾指定的標簽 標簽選擇器目前有2個:一個是基于 等值關系(等于、不等于) 一個是 基于集合關系(屬于、不屬于、存在) 許多資源支持內嵌標簽選擇器 欄位 matchLabels matchExpressions 一個合法的標簽應該是 字母和數字、下劃線、虛線"-"、點"." 開頭和結尾必須是字母或數字的形式組成,標簽值最多63個字符
5.7 Ingress
-
Ingress是授權入站連接到達集群服務的規則集合,
-
在K8S集群里,作業在應用層,對外暴露介面,
-
可以調動不同業務域,不同URL訪問路徑的業務流量
你可以給Ingress配置提供外部可訪問的URL、負載均衡、SSL、基于名稱的虛擬主機等,用戶通過POST Ingress資源到API server的方式來請求ingress, Ingress controller負責實作Ingress,通常使用負載平衡器,它還可以配置邊界路由和其他前端,這有助于以HA方式處理流量,
5.8 NameSpace 命名空間
-
用來隔離pod 的運行環境
隨著專案怎多,人員增加,集群規模的擴大,需要一種能夠隔離K8S內各種"資源",都應該有自己的"名稱", Kubernetes可以使用Namespaces(命名空間)創建多個虛擬集群, Namespace為名稱提供了一個范圍,資源的Names在Namespace中具有唯一性, 不同名稱空間的內部"資源" ,名稱可以相同,相同名稱空間內的同種 "資源","名稱"不能相同 合理的使用K8S的名稱空間,使得集群管理員能夠更好的對付交付 到K8S里的服務進行分類管理和瀏覽 K8S里默認存在的名稱空間有 default、kube-system、kube-public 查詢k8s 里特定"資源" 要帶上相應 的名稱空間
6.K8S 的網路通訊方式
- K8S 的網路模型 假定了所有POD都在一個可以直接連通的扁平的網路空間(扁平化:所有的POD都可以通過對方的IP互相訪問),在這里GCE(Google Compute Engine) 里面是現成的網路模型.
- K8S假定這個網路模型已經存在,而在私有云里搭建K8S集群,就不能假定這個網路已經存在了,
- 所以,我們需要個網段假設,將不同節點上的Docker容器之間的互相訪問先打通,然后在運行Kubernetes
6.1 同一個Pod 內的多個容器之間通訊:localhost
- 同一個Pod 內部通訊,共享一個網路命名空間,共享一個linux協議堆疊
6.2 各個Pod之間的通訊:Overlay Network
-
不同機器,上面運行的Docker容器IP一定不能沖突,
-
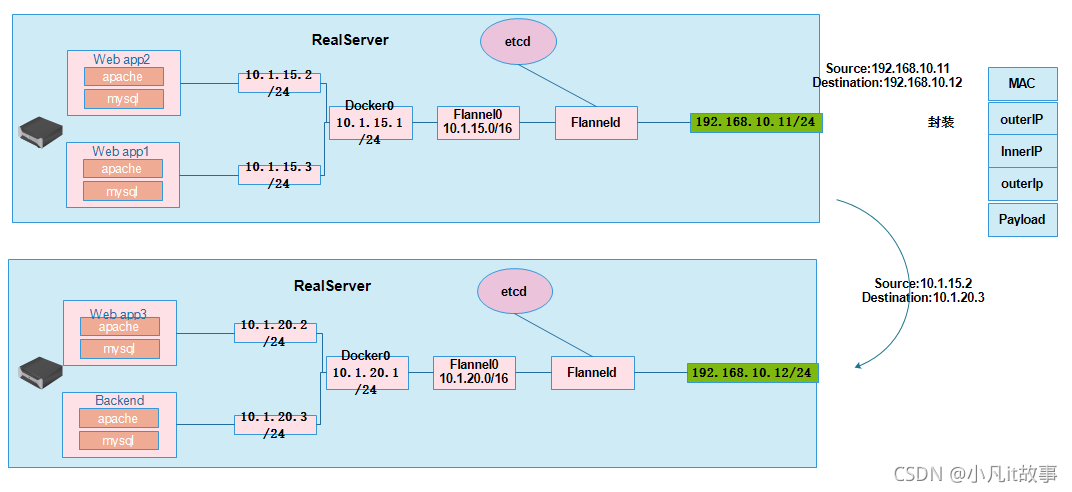
# 在k8s中,其實我們的谷歌沒有對自己的k8s做了很強定義,它允許我們通過CNI介面,去接入我們自己的想要達到的一個網路方案, # 其中Flannel 使我們在k8s里最常用的一種解決網路扁平化的一種方案,符合我們CNI介面, # Flannel是CoreOS團隊針對Kubernetes設計的一個網路規劃服務,簡單來說,它的功能是讓集群中的不同節點主機創建的 Docker容器都具有全集群唯一的虛擬IP地址,而且它還能在這些IP地址之間建立一個覆寫網路(Overlay Network),通過這個覆寫網路,將資料包原封不動地傳遞到目標容器內, # 不同物理機器上面運行的Docker 容器IP一定不能沖突,在Docker里面我們可以修改組態檔,修改網段,那么Flannel是怎么解決的, # 這里有2臺物理主機,運行了4個Pod,一臺物理機上運行了webapp2、webapp1 2個Pod ,另一臺物理主機上運行了 webapp3、Backend 2個接點,他們的網路架構是 Backend(前端接點)、webapp1、webapp2、webapp3,所有流量訪問到Backend上,它去經過自己的網關去處理,把什么樣的請求分配到什么樣的服務上, # 這樣就意味著,webapp2 和backend通訊,就需要跨主機通訊了,以及 webapp3 和backend通訊,就是2個同主機的不同Pod通訊了,2種不同的通信到底如何解決? # 首先在我們真實服務器上,我們會安裝一個Flanneld的守護行程,這個行程會監聽一個埠,這個埠用于后續監聽接受或轉發資料包 的一個埠,一旦這個Flanneld 行程啟動后,它會開啟一個 Flanneld 0 的網橋,網橋Flanneld 0 專門會手機網橋Docker0 轉發出來的資料報文,然后Docker0 會分發自己的IP到對應的pod上, # 如果是同一臺主機上 的兩個Pod 互相通信,它走的是Docker0網橋, # 如何跨主機,通過對方的IP直接到達? # 假設 webapp2 與Backend 通訊,源地址是10.1.15.2/24 目標地址是 10.1.20.3/24, 因為不是同一個網段,所以首先 webapp2 會發送 自己的網關Docker0 10.1.15.1/24,然后 Flannel0 10.1.15.0/16 接受docker0 的報文,然后發送給Flanneld行程,此時Flanneld行程會從 etcd 獲取路由,并寫入當前的主機路由,經過Flanneld封裝 后發送,Flanneld 封裝資料包 先mac封裝,然后 封裝 源IP 192.168.10.11 目的IP 192.168.10.12 ,接著封裝UDP協議,在封裝 源IP 10.1.15.2 目的IP 10.1.20.3,然后發送到 物理機 192.168.10.12 上面的Flannel0 ,Flanneld 行程會截取報文,然后會拆封,然后轉發到 Docker0,看到的是源地址是10.1.15.2/24 目標是 10.1.20.3的地址的資料包,然后發給Blackend -
ETCD 之 Flannel提供說明:
- 存盤管理 Flannel 可分配的 IP地址段資源(也就意味著Flannel 在啟動后,會向etcd 插入可以分配的網段,并記錄分配的pod地址,防止 已分配的網段再次被利用,造成地址沖突)
- 監控ETCD中每個Pod 的實際地址,并在記憶體中建立維護Pod節點路由表
6.3 Pod 與Service 之間的通訊:各節點的Iptables(LVS轉發)
- Pod 致Service 的網路:目前基于性能考慮,全部為iptables 維護和轉發
6.4 通訊總結
-
通在同一臺機器,由Docker0網橋直接轉發請求只Pod2,不需要進過Flannel
-
Podl至 Pod2:
- Podl與 Pod2不在同一臺主機,Pod的地址是與docker0在同一個網段的,但dockerO網段與宿主機網卡是兩個完全不同的IP網段,并且不同Node之間的通信只能通過宿主機的物理網卡進行,將Pod的IP和所在Node的IP關聯起來,通過這個關聯讓Pod可以互相訪問
- Pod1 與 Pod2在同一臺機器,由 Docker0網橋直接轉發請求至 Pod2,不需要經過 Flannel 演示
-
Pod 致Service 的網路:目前基于性能考慮,全部為iptables 維護和轉發
-
Pod 到外網: Pod 向外網發送請求,查找路由表,轉發資料包到 宿主機的網卡,宿主網卡完成路由選擇后,iptables執行Masqureade,把源IP 更改為宿主網卡的IP,然后想外網服務器發送請求,
-
外網發送Pod: service
7.K8s里面的三張網路
-
三種網路
-
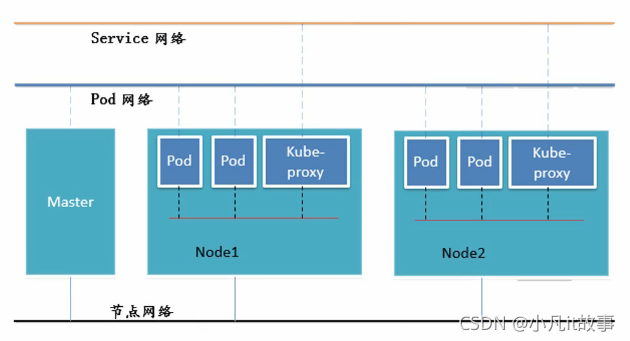
# 節點網路 就是我們真實的物理網卡 # Pod 和service 都是虛擬網路
二、總結
- K8S概念很是復雜,這里先簡單的介紹下k8s基礎概念,后續接著更新k8s 部署,已及更深參次的介紹k8s,初次里面涉及的概念,一定要搞清楚,偶爾面試會被問到
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352086.html
標籤:其他