k近鄰(k-Nearest Neighbor,kNN)演算法是一種常用的有監督學習演算法,可以完成分類與回歸的任務,其作業機制非常簡單:給定測驗樣本,基于某種距離度量找出訓練集中與其最靠近的 k k k個訓練樣本,然后基于這 k k k個“鄰居”的資訊來進行預測,通常,在分類任務中可使用“投票法”,即選擇這 k k k個樣本中出現最多的類別標記作為預測結果;在回歸任務中可使用“平均法”,即將這 k k k個樣本的實值輸出標記的平均值作為預測結果;還可基于距離遠近進行加權平均或加權投票,距離越近的樣本權重越大, k k k值的選擇、距離度量及分類決策規則是k近鄰法的三個基本要素,
與前面介紹的學習方法相比,k近鄰學習有一個明顯的不同之處:它似乎沒有顯式的訓練程序,事實上,它是“懶惰學習”(lazy learning)的著名代表,此類學習技術在訓練階段僅僅是把樣本保存起來,訓練時間開銷為零,待收到測驗樣本后再進行處理;相應的,那些在訓練階段就對樣本進行學習處理的方法,稱為“急切學習”(eager learning).,
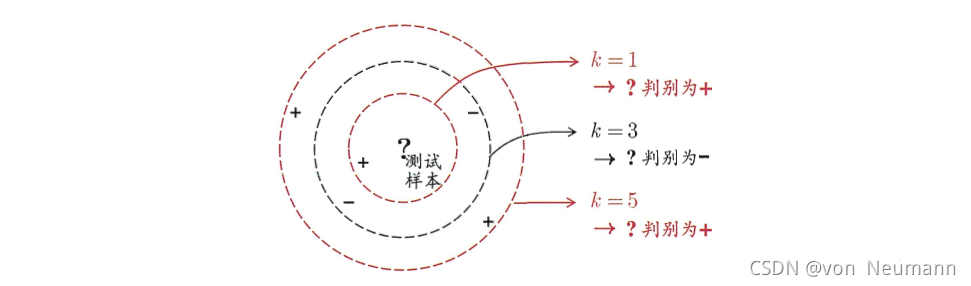
上給出了k近鄰分類器的一個示意圖,顯然,
k
k
k是一個超引數,當
k
k
k取不同值時,分類結果會有顯著不同,另一方面,若采用不同的距離計算方式,則找出的“近鄰”可能有顯著差別,從而也會導致分類結果有顯著不同,暫且假設距離計算是“恰當”的,即能夠恰當地找出
k
k
k個近鄰,我們來對“最近鄰分類器”(1NN,即k
k
k
k=1)在二分類問題上的性能做一個簡單的討論,
給定測驗樣本
x
x
x,若其最近鄰樣本為
y
y
y,則最近鄰分類器出錯的概率就是
x
x
x與
y
y
y類別標記不同的概率,即:
p
(
err
)
=
∑
c
∈
Y
p
(
c
∣
x
)
p
(
c
∣
y
)
p(\text{err})=\sum_{c\in Y}p(c|x)p(c|y)
p(err)=c∈Y∑?p(c∣x)p(c∣y)
假設樣本獨立同分布,且對任意
x
x
x和任意小正數
δ
\delta
δ,在
x
x
x附近
δ
\delta
δ距離范圍內總能找到一個訓練樣本;換言之,對任意測驗樣本,總能在任意近的范圍內找到上式中的訓練樣本
y
y
y.令
c
?
=
arg?max
?
c
∈
Y
p
(
c
∣
x
)
c^*=\argmax_{c\in Y}{p(c|x)}
c?=c∈Yargmax?p(c∣x)表示貝葉斯最優分類器的結果,有:
p
(
err
)
≤
2
×
(
1
?
p
(
c
?
∣
x
)
)
p(\text{err})\leq 2\times(1-p(c^*|x))
p(err)≤2×(1?p(c?∣x))
即最近鄰分類器雖簡單,但它的泛化錯誤率不超過貝葉斯最優分類器的錯誤率的兩倍,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352088.html
標籤:AI
上一篇:深入理解機器學習——集成學習(二):提升法Boosting與Adaboost演算法
下一篇:機器學習之貝葉斯分類器