2021年全國行業職業技能競賽暨第四屆全國大學生大資料技能競賽——職教學生組線上選拔賽
目錄
2021年全國行業職業技能競賽暨第四屆全國大學生大資料技能競賽——職教學生組線上選拔賽
前言
資料
前提條件
題目一、基礎配置(30分)
題目二、Zookeeper搭建(30分)
題目三、Hadoop集群搭建( 80分)
題目四、Hive集群搭建(30分)
題目五、Spark搭建(30分)
前言
根據2021年全國行業職業技能競賽暨第四屆全國大學生大資料技能競賽——職教學生組線上選拔賽賽題整理,附上資料鏈接,如果有錯誤指出請提出改正,謝謝
資料
鏈接:https://pan.baidu.com/s/1Q2Z-roUoGSMkXNf1I4dThA
提取碼:yikm
前提條件
由于比賽中已經安裝有ntp和MySQL服務,我們現在虛擬機中安裝配置,
ntp在三臺機器上安裝(master,slave1,slave2)
MySQL可以只在slave2中安裝,將slave2作為資料庫存盤資料,使用client/thrift server的連接方式進行訪問,
安裝ntp:
yum install -y ntp
安裝完成:
安裝MySQL資料庫:
卸載系統自帶的Mariadb
rpm -qa|grep mariadb
rpm -e mariadb-libs-5.5.68-1.el7.x86_64 --nodeps
rpm -qa|grep mariadb
安裝MySQL:
解壓:
tar -xvf /usr/package277/mysql-5.7.25-1.el7.x86_64.rpm-bundle.tar 安裝:
安裝:
rpm -ivh mysql-community-common-5.7.25-1.el7.x86_64.rpm mysql-community-libs-5.7.25-1.el7.x86_64.rpm mysql-community-libs-compat-5.7.25-1.el7.x86_64.rpm mysql-community-client-5.7.25-1.el7.x86_64.rpm mysql-community-server-5.7.25-1.el7.x86_64.rpm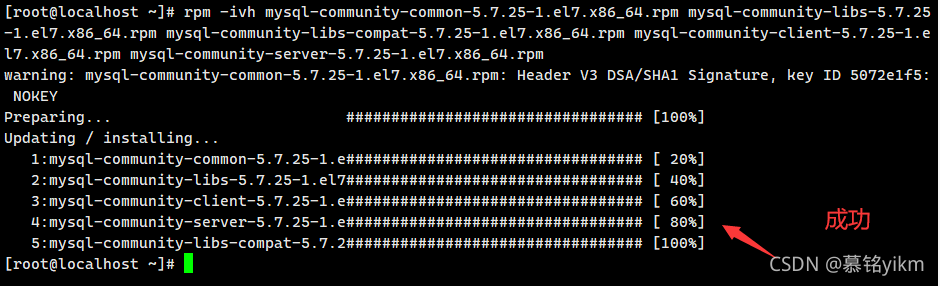
配置完畢!
題目一、基礎配置(30分)
1.比賽框架
本次比賽為分布式集群搭建,共三臺節點,其中master作為主節點,slave1、slave2為從節點;
2.比賽內容
- 基礎配置:修改主機名、主機映射、時區修改、時間同步、定時任務、免密訪問;
- JDK安裝:環境變數;
- Zookeeper部署:環境變數、組態檔zoo.cfg、myid;
- Hadoop部署:環境變數、組態檔修改、設定節點檔案、格式化、開啟集群;
- Hive部署:Mysql資料庫配置、服務器端配置、客戶端配置,
3.版本說明
| 內置安裝/依賴包(/usr/package277) | 已安裝服務 | 系統版本 |
| hadoop-2.7.7.tar.gz | ntp | CentOS Linux release 7.3.1611 (Core) |
| zookeeper-3.4.14.tar.gz | mysql-community-server | |
| apache-hive-2.3.4-bin.tar.gz | ||
| jdk-8u211-linux-x64.tar.gz | ||
| mysql-connector-java-5.1.47-bin.jar |
core-site.xml引數配置詳情
官方檔案:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/core-default.xml
core-default.xml與core-site.xml的功能是一樣的,如果在core-site.xml里沒有配置的屬性,則會自動會獲取core-default.xml里的相同屬性的值
| 屬性 | 值 | 說明 |
| fs.default.name | hdfs://???? | 定義master的URI和埠 |
| hadoop.tmp.dir | /???? | 臨時檔案夾,指定后需將使用到的所有子級檔案夾都要手動創建出來,否則無法正常啟動服務, |
hdfs-site.xml引數配置詳情
| 屬性 | 值 | 說明 |
| dfs.replication | ??? | hdfs資料塊的復制份數,默認3,理論上份數越多跑數速度越快,但是需要的存盤空間也更多, |
| dfs.namenode.name.dir | file:/usr/hadoop/hadoop-2.7.3/hdfs/???? | NN所使用的元資料保存 |
| dfs.datanode.data.dir | file:/usr/hadoop/hadoop-2.7.3/hdfs/???? | 真正的datanode資料保存路徑,可以寫多塊硬碟,逗號分隔 |
yarn-site.xml引數配置詳情
| 屬性 | 值 | 說明 |
| yarn.resourcemanager.admin.address | ${yarn.resourcemanager.hostname}:18141 | ResourceManager 對管理員暴露的訪問地址,管理員通過該地址向RM發送管理命令等, |
| yarn.nodemanager.aux-services | mapreduce_shuffle | NodeManager上運行的附屬服務,需配置成mapreduce_shuffle,才可運行MapReduce程式 |
mapred-site.xml引數配置詳情
| 屬性 | 值 | 說明 |
| mapreduce.framework.name | yarn | 指定MR運行框架,默認為local |
基礎環境配置
前提說明
- 相關安裝包已經存放至環境/usr/package277/中
- 對應ntp和mysql已安裝,可直接對其進行操作和配置
1.修改主機名,便于識別節點;
2.工具包已保存在環境中;
3.修改hosts檔案,添加集群節點映射,按照給出的節點IP和對應的主機名進行設定;
4.要求各節點時區修改為中國時區( 中國標準時間CST+8)
5.安裝ntp服務,要求主節點master為本地時鐘源,從節點設定定時任務同步本地時間;
6.集群中資料傳輸需要節點之間免密訪問,要求設定主節點之間到從節點的免密訪問;
7.Hadoop技識訓于Java語言,要求本地源下載對應安裝包進行安裝配置,注意安裝路徑要求,無需更改檔案名,注意添加環境變數,
本環境用于為基礎設定部分,用于后續的集群搭建,
考核條件如下:
1. 按照左側虛擬機名稱修改對應主機名(分別為master、slave1、slave2,使用hostnamectl命令)(2分)
操作環境: master、slave1、slave2
hostnamectl set-hostname master
hostnamectl set-hostname slave1
hostnamectl set-hostname slave2
bash
2. 修改云主機host檔案添加左側master、slave1、slave2三個節點IP與主機名映射(使用內網IP)(2分)
操作環境: master、slave1、slave2
vim /etc/hosts
添加ip+主機名:
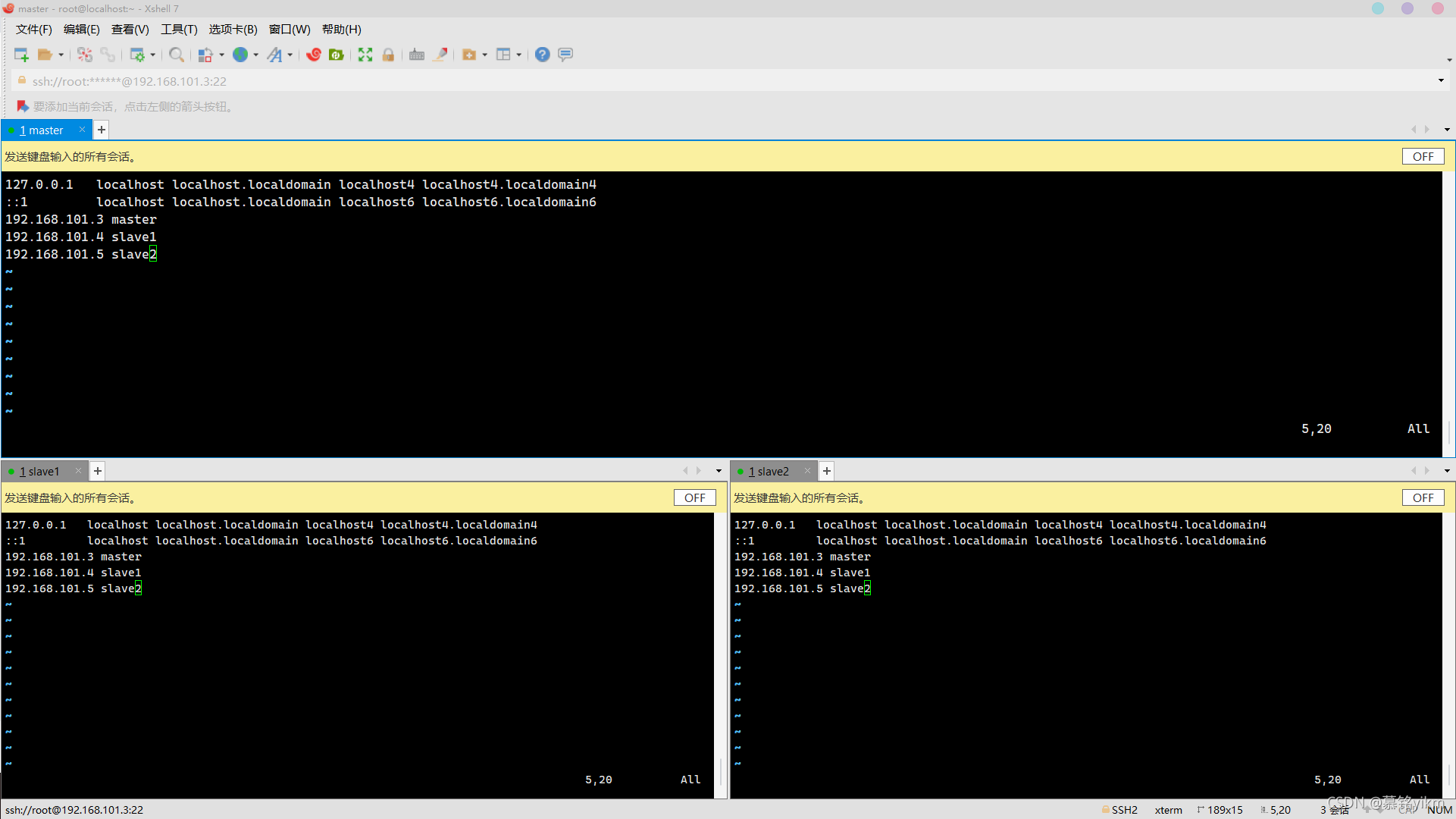
:wq保存退出
ping測驗:(ctrl+c停止)
ping slave1
ping slave2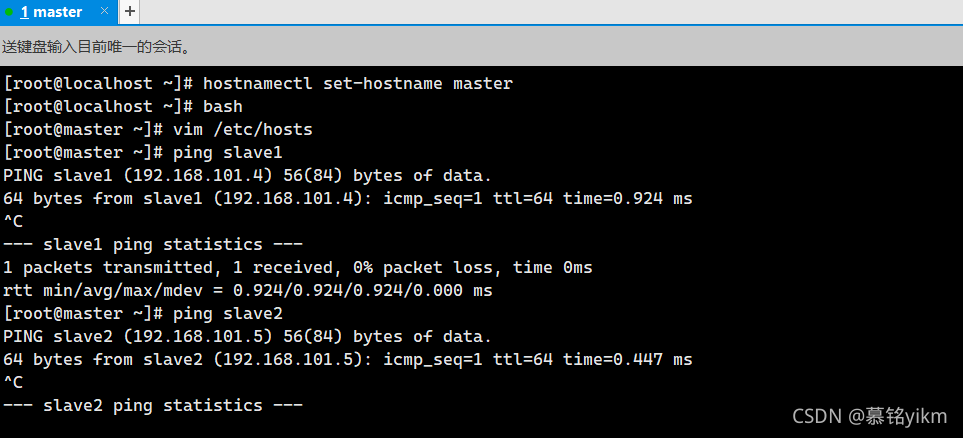
3. 時區更改為上海時間(CST+0800時區)(2分)
操作環境: master、slave1、slave2
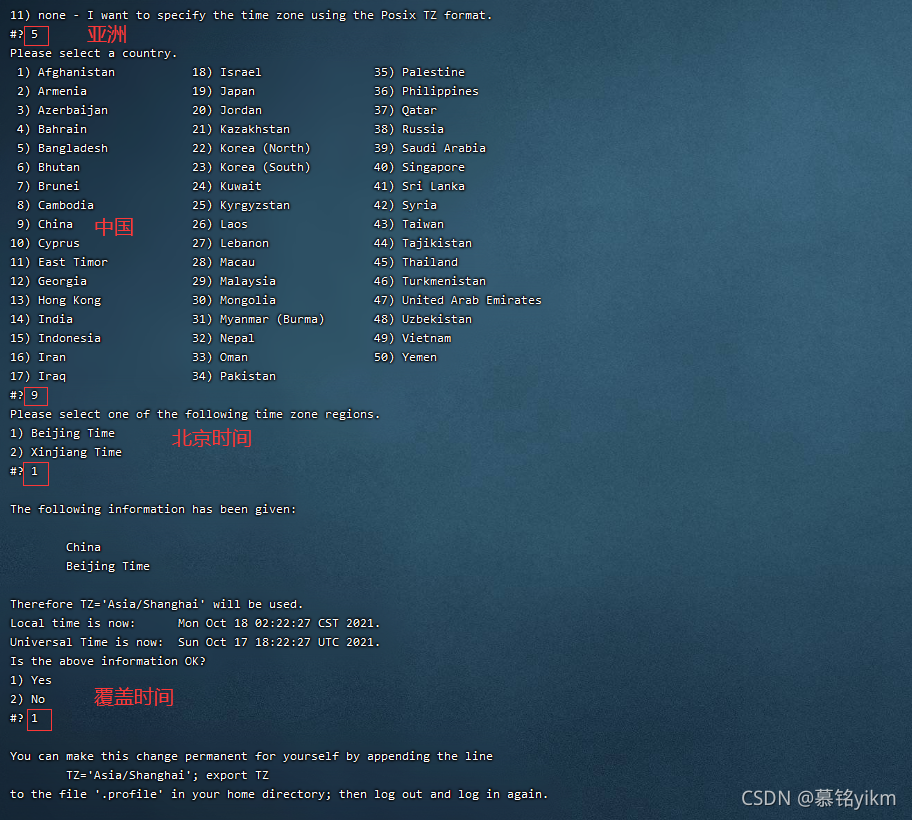
tzselect
依次輸入
5
9
1
1
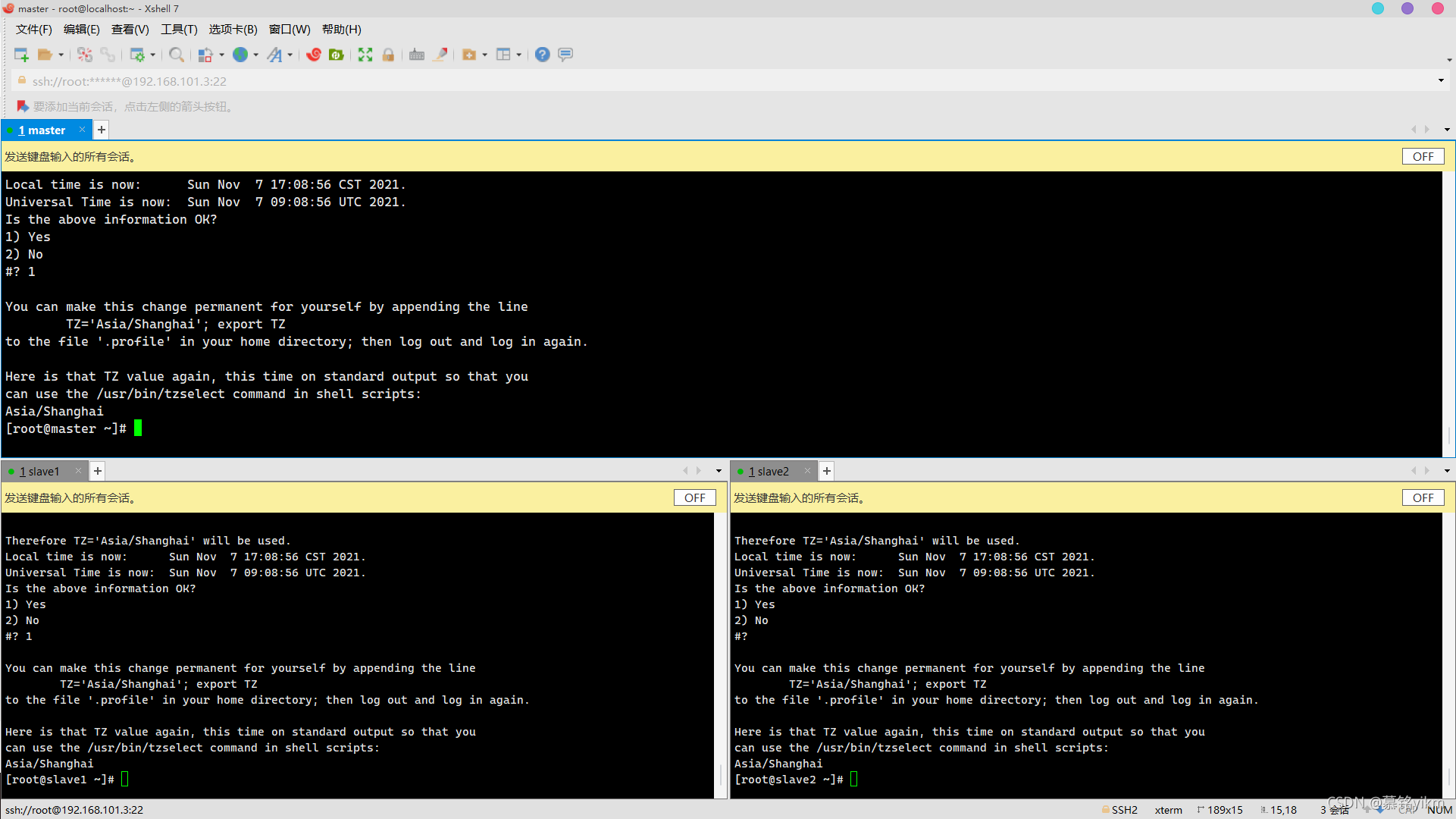
修改環境變數:
vim /etc/profile加入:
TZ='Asia/Shanghai'; export TZ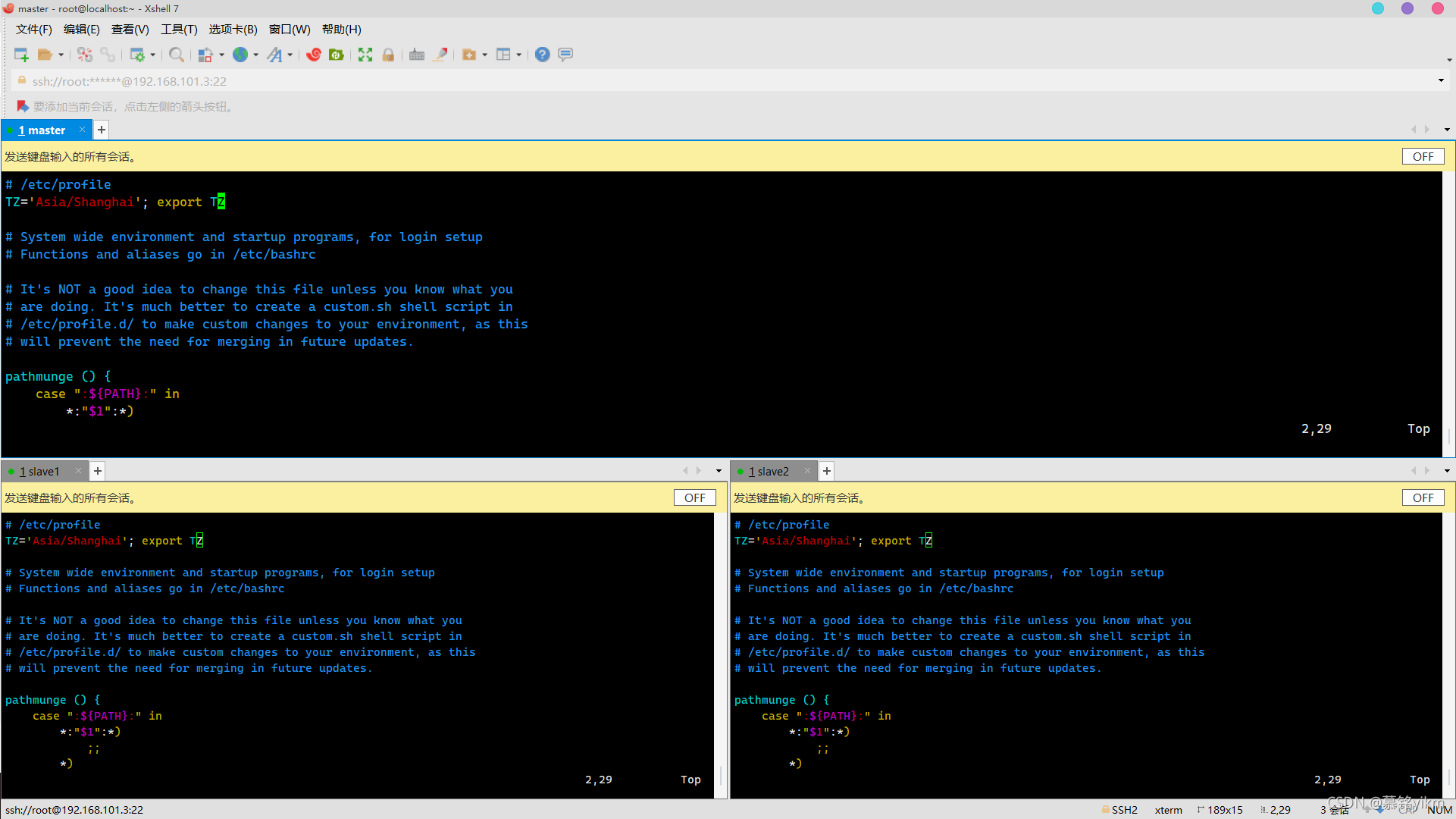
生效環境變數:
source /etc/profile查看時間:
date
在ntp同步之前關閉防火墻和selinux安全機制
操作環境: master、slave1、slave2
關閉防火墻:
systemctl stop firewalld
systemctl status firewalld
systemctl disable firewalld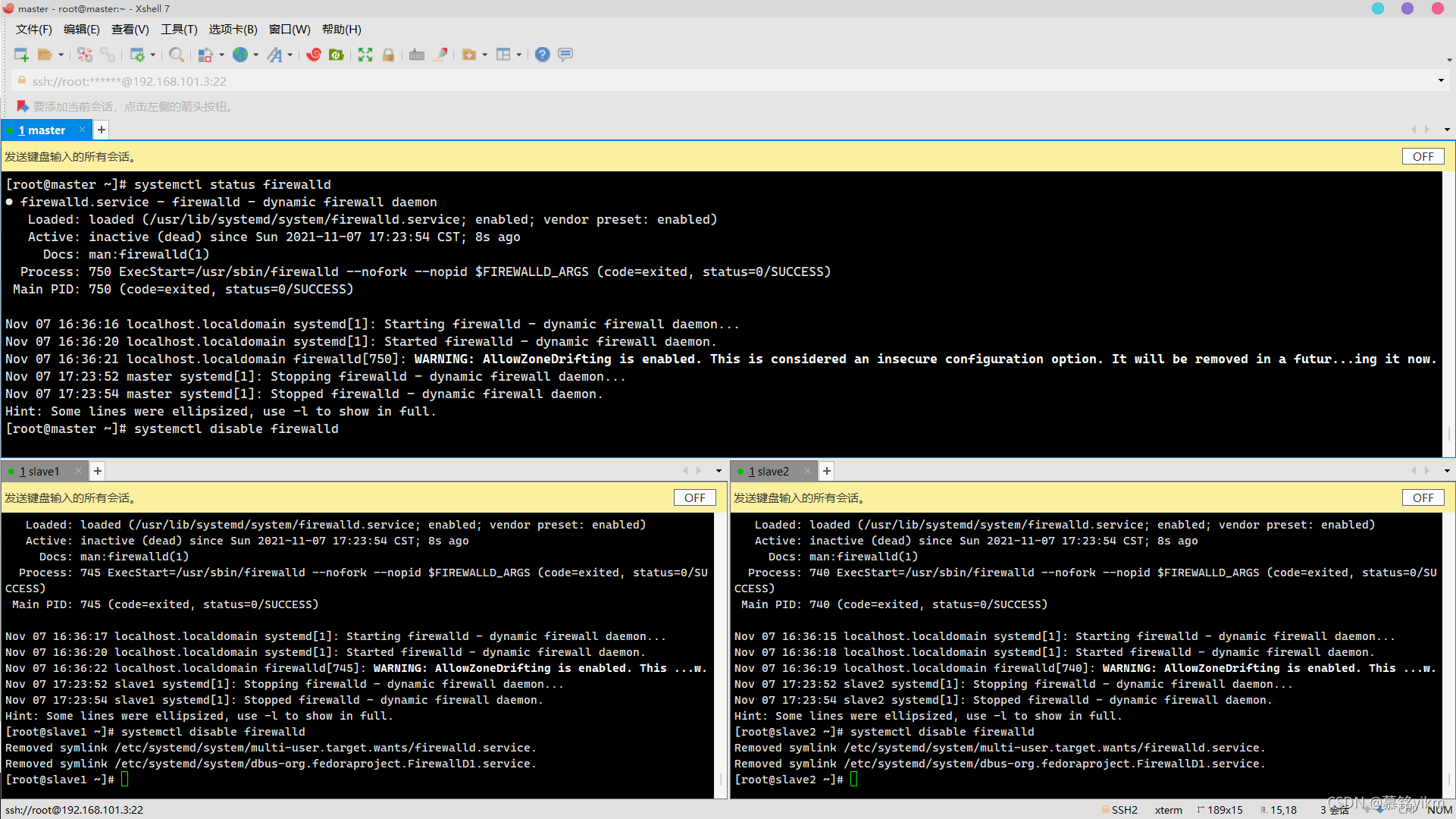
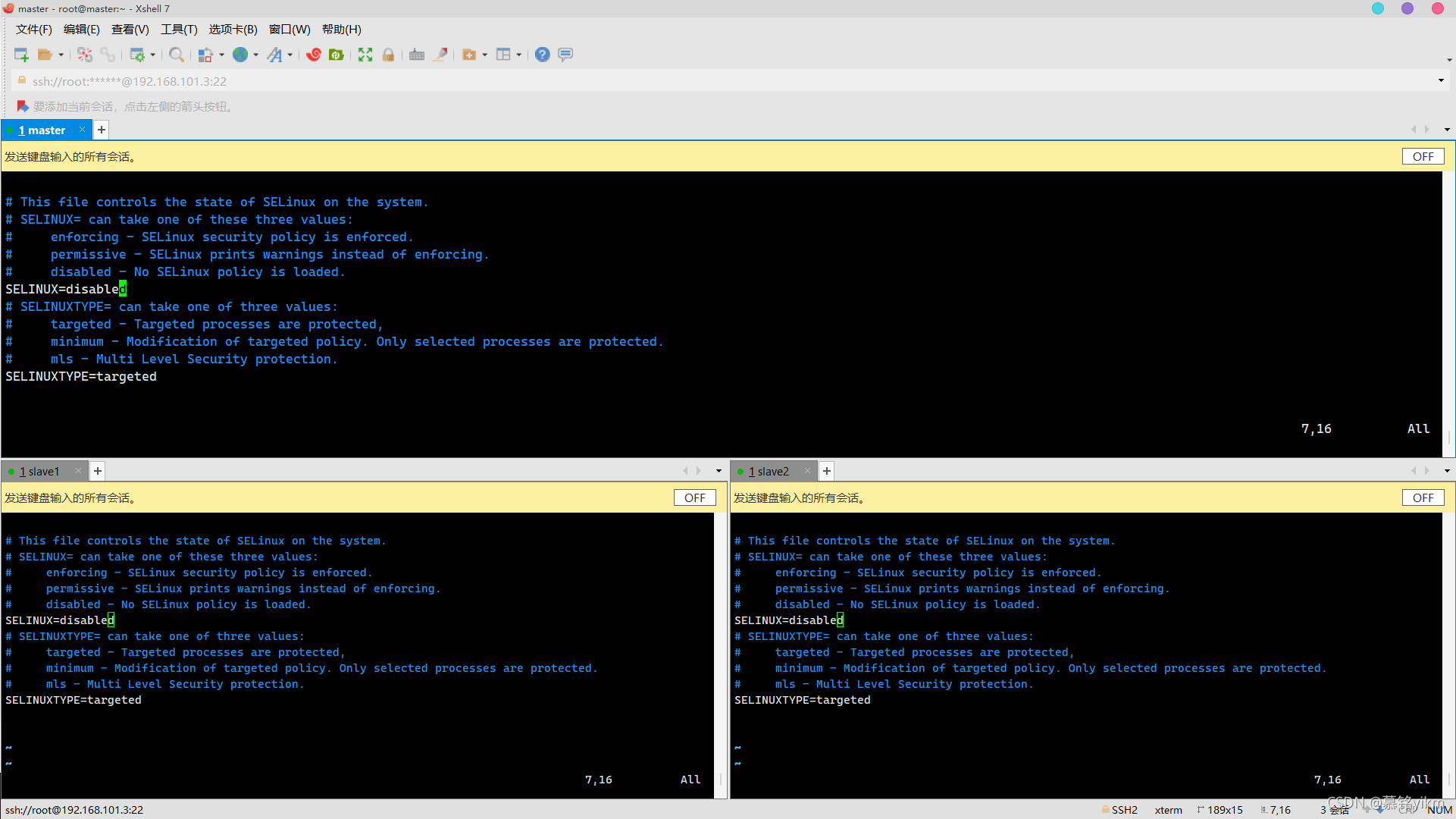
關閉selinux安全機制:
vim /etc/sysconfig/selinux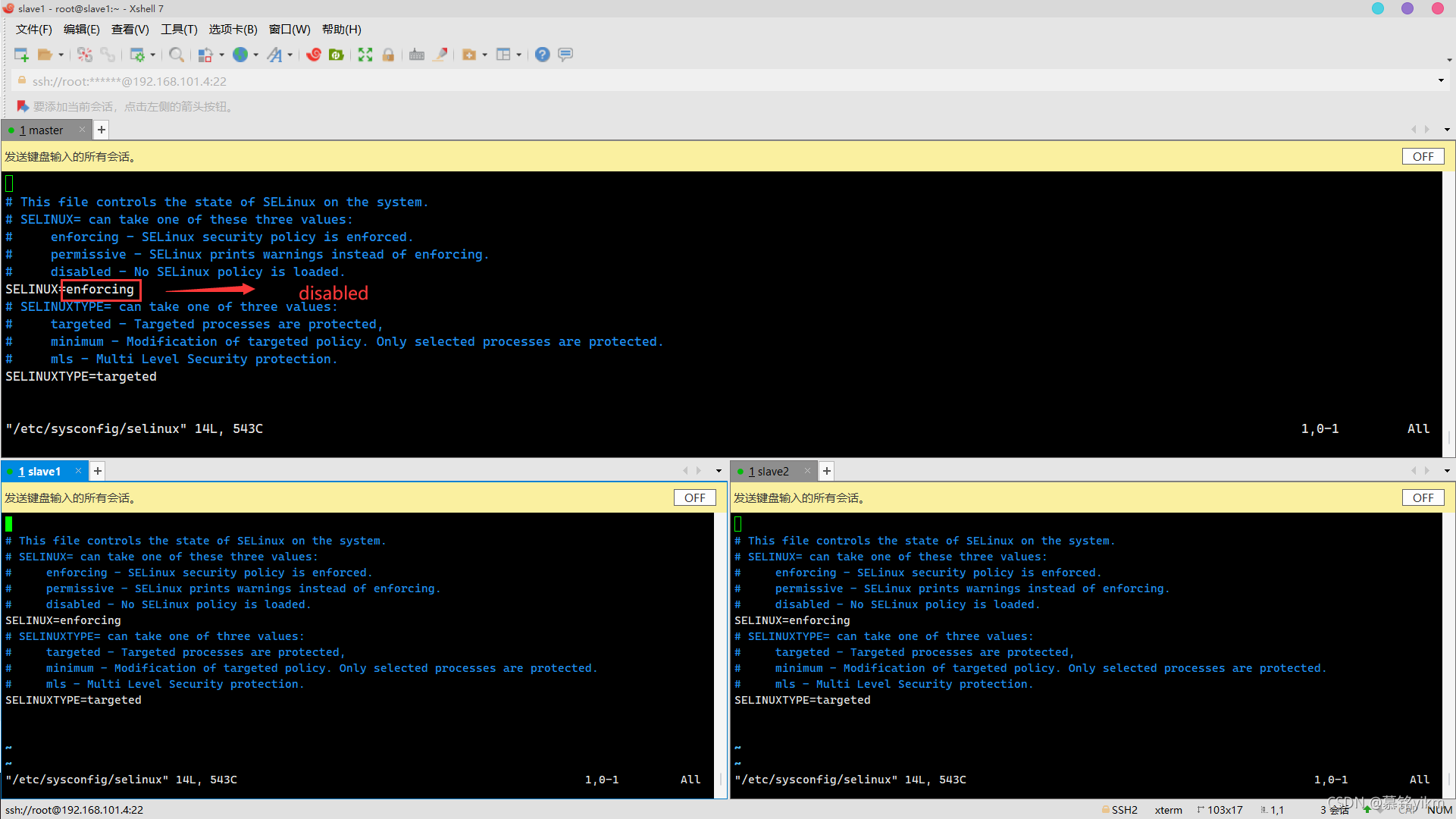
4. 環境已經安裝NTP,修改master節點NTP配置,設定master為本地時間服務器,屏蔽默認server,服務器層級設為10(2分)
操作環境: master
echo "server 127.127.1.0
fudge 127.127.1.0 stratum 10" >> /etc/ntp.conf 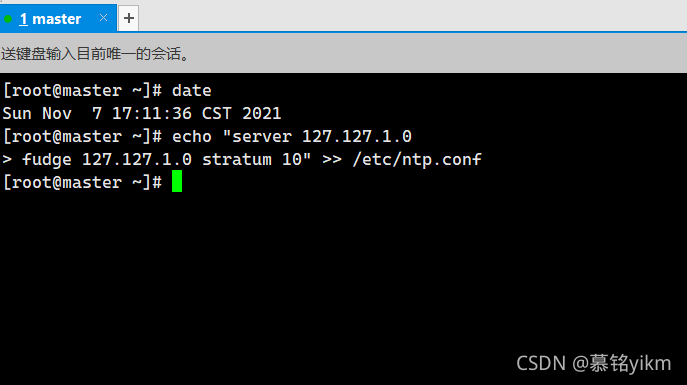
5. 開啟NTP服務(2分)
操作環境: master
/bin/systemctl restart ntpd.service 
6. 添加定時任務--在早十-晚五時間段內每隔半個小時同步一次本地服務器時間(24小時制、使用用戶root任務調度crontab,服務器地址使用主機名)(2分)
操作環境: slave1、slave2
ntp同步master
ntpdate master
crontab -e
*/30 10-17 * * * usr/sbin/ntpdate master 查看任務:
查看任務:
crontab -l
7. master節點生成公鑰檔案id_rsa.pub(數字簽名RSA,用戶root,主機名master)(2分)
操作環境: master
ssh-keygen
三次回車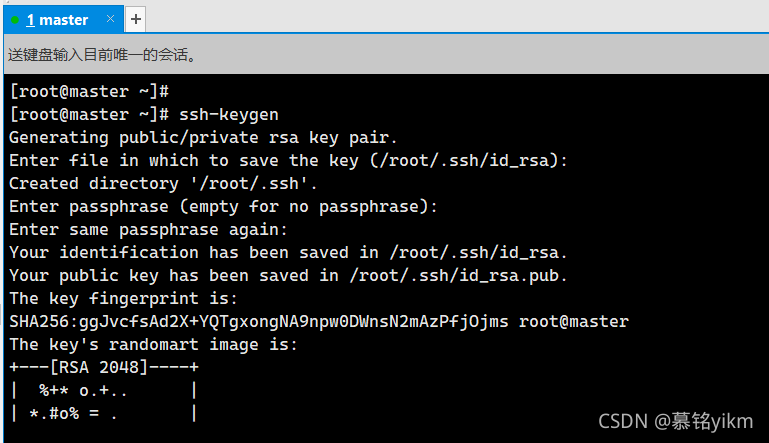
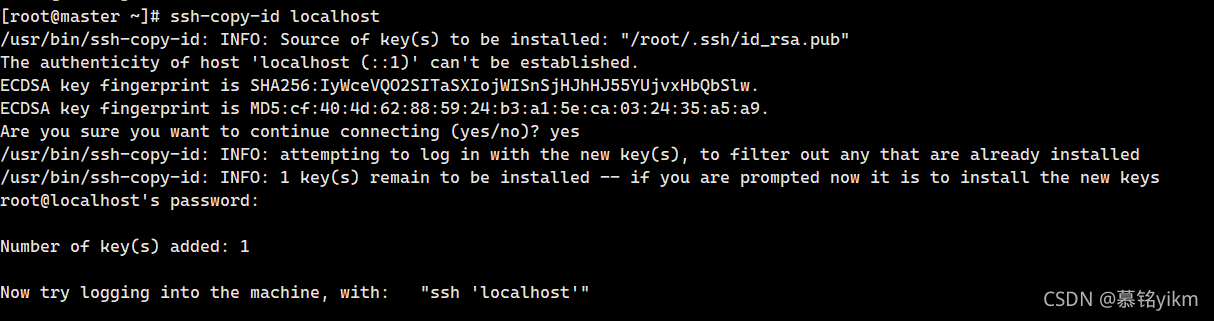
8. 建?master?身使?root?戶ssh訪問localhost免密登錄(2分)
操作環境: master
ssh-copy-id localhost輸入yes和密碼
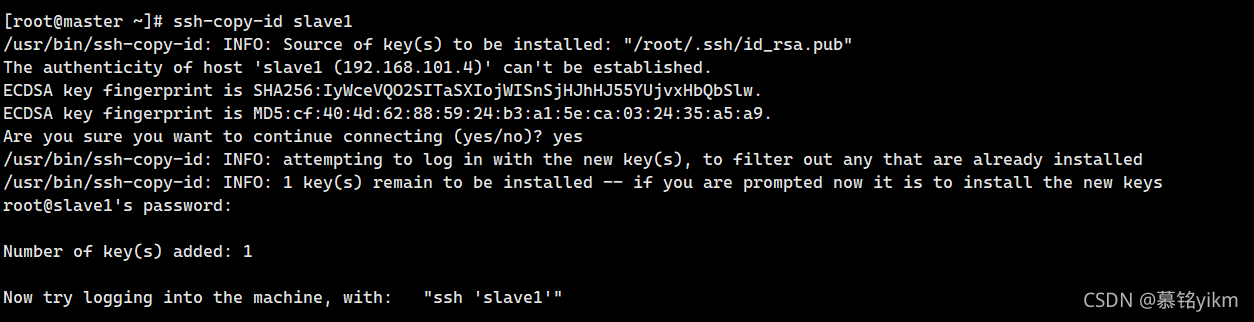
9. 建?master使?root?戶到slave1的ssh免密登錄訪問(2分)
操作環境: master
ssh-copy-id slave1輸入yes和密碼:
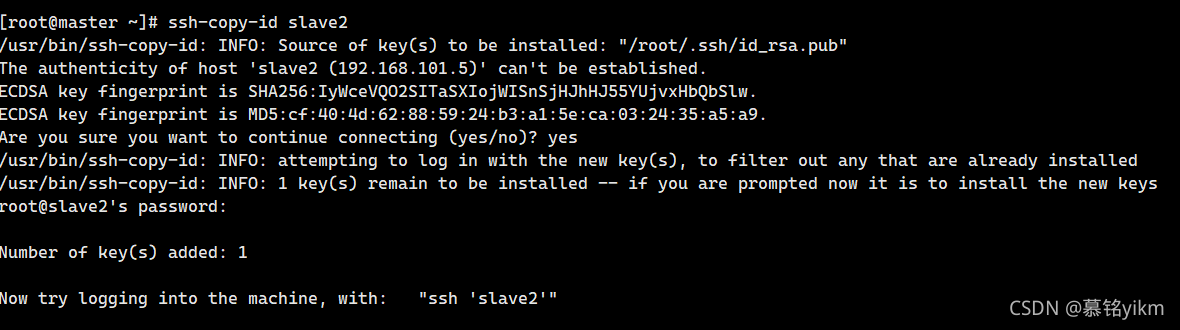
10. 建?master使?root?戶到slave2的ssh免密登錄訪問(2分)
操作環境: master
ssh-copy-id slave2輸入yes和密碼:
ssh測驗:
ssh slave1
exit
ssh slave2
exit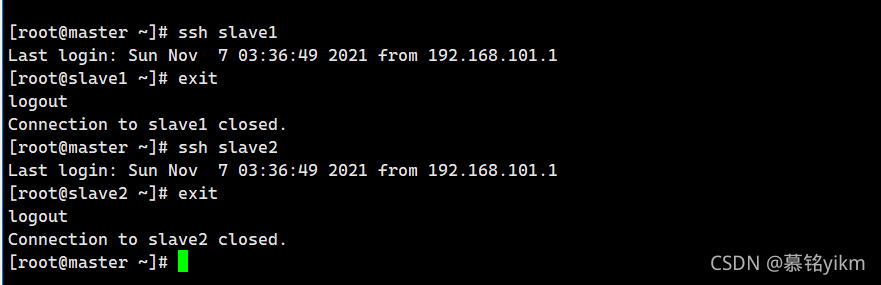
11. 將jdk安裝包解壓到/usr/java目錄(安裝包存放于/usr/package277/,路徑自行創建,解壓后檔案夾為默認名稱,其他安裝同理)(5分)
操作環境: master、slave1、slave2
mkdir /usr/java
tar -zxvf /usr/package277/jdk-8u221-linux-x64.tar.gz -C /usr/java/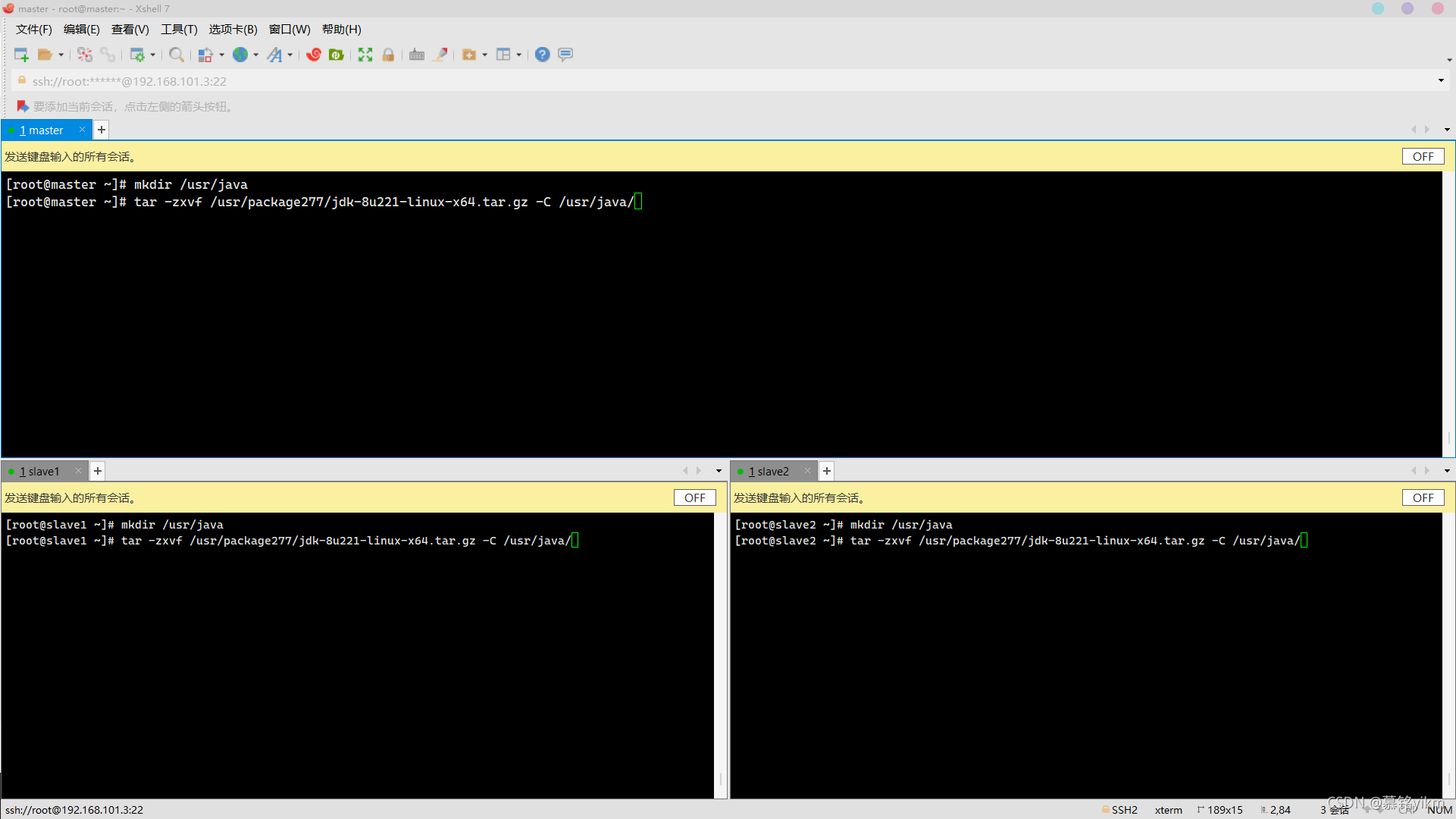 解壓完畢:
解壓完畢:
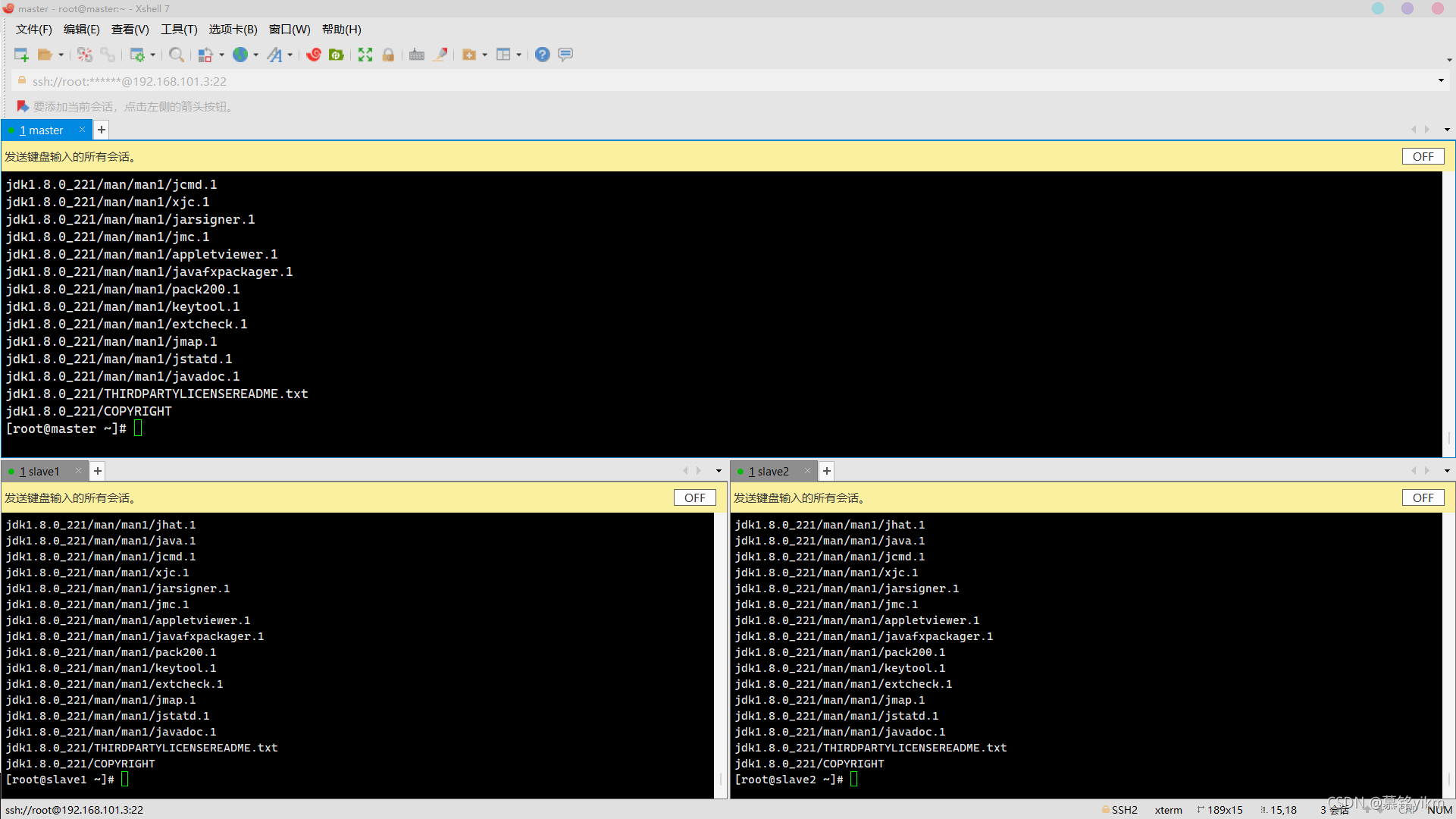
12. 檔案/etc/profile中配置系統環境變數JAVA_HOME,同時將JDK安裝路徑中bin目錄加入PATH系統變數,注意生效變數,查看JDK版本(5分)
操作環境: master、slave1、slave2
vim /etc/profile添加以下內容:
#java
export JAVA_HOME=/usr/java/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
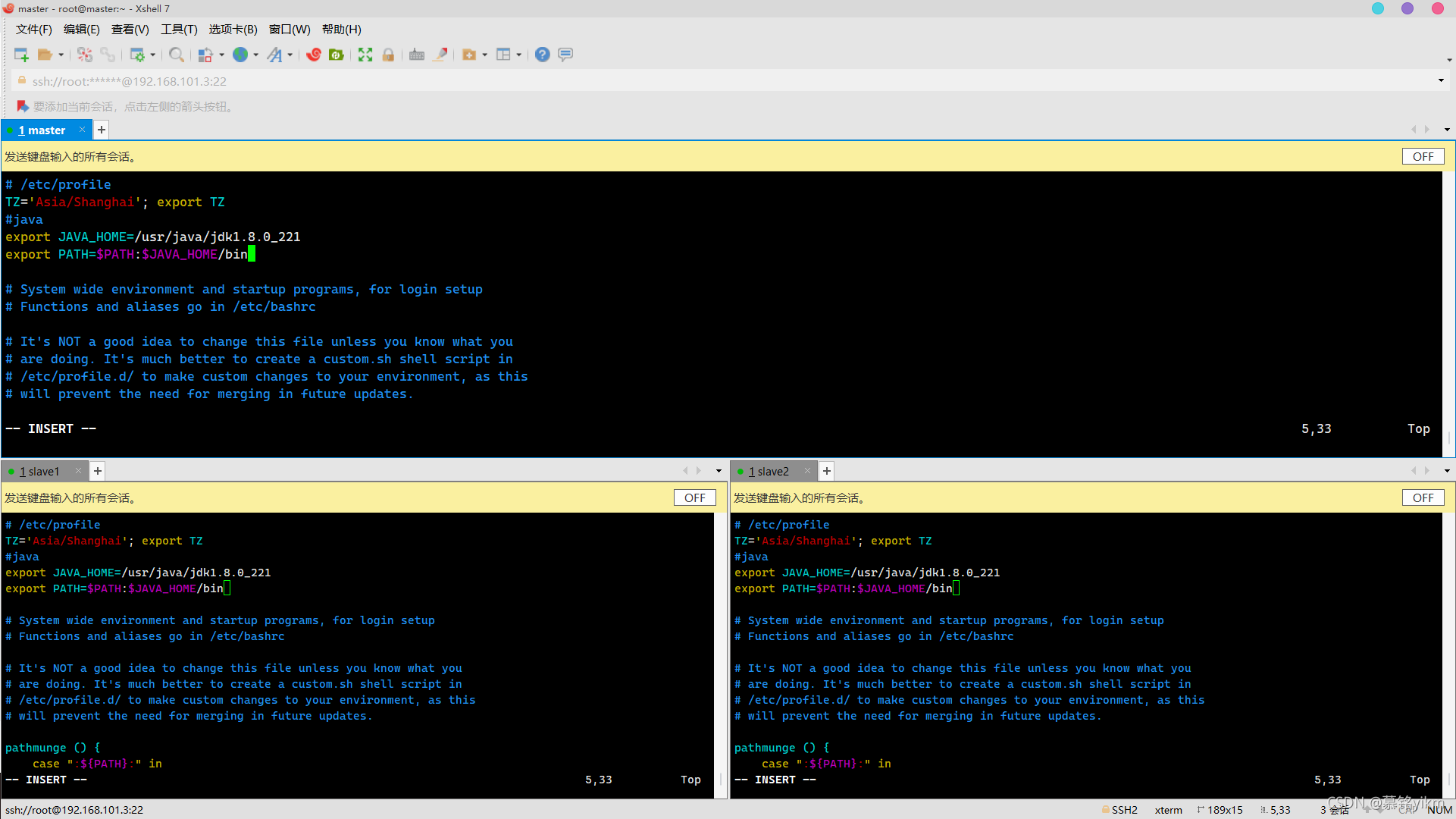
生效環境變數:
source /etc/profile查看版本:
java -version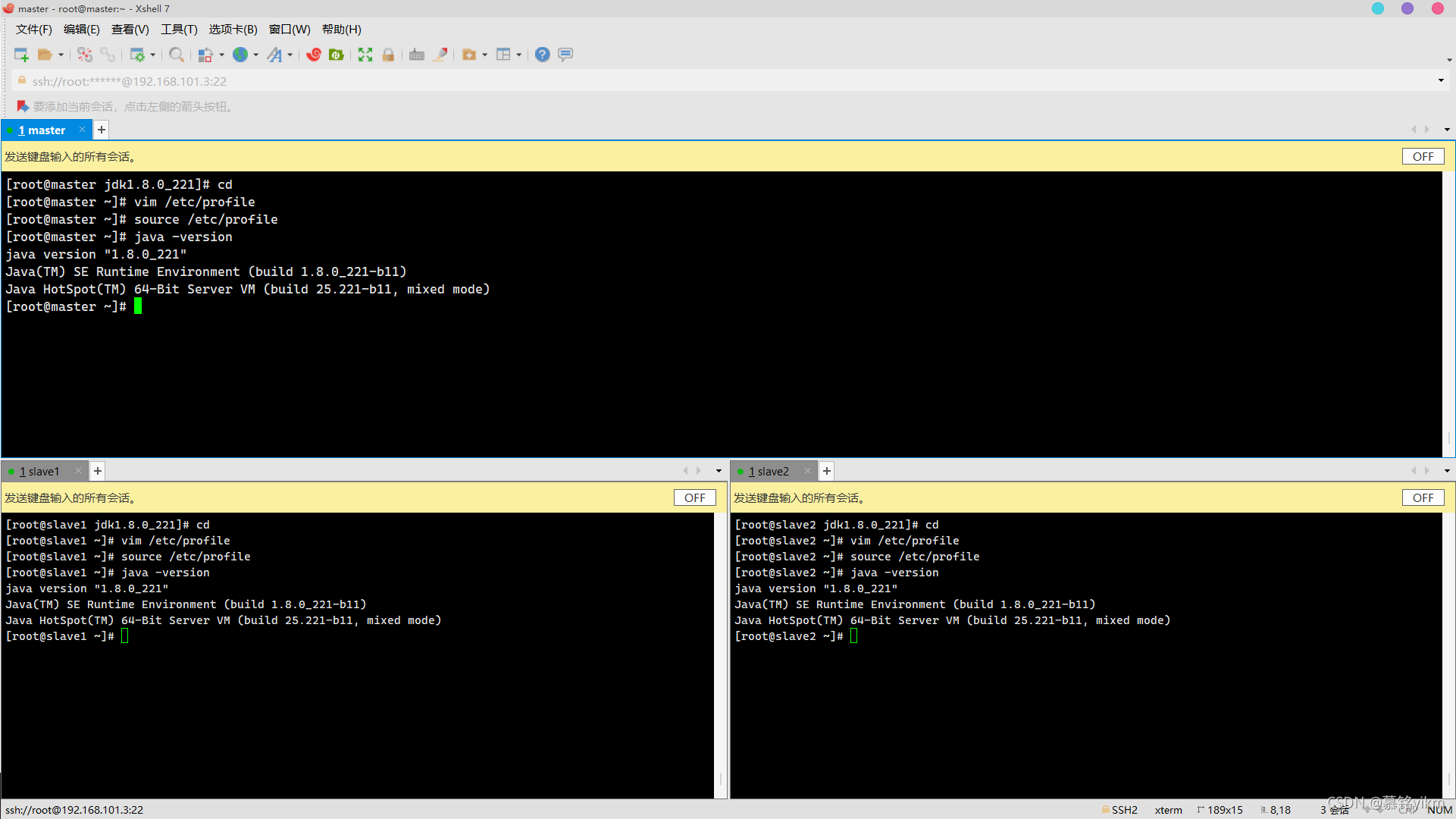
版本不同解決方案:
(鈴音大佬整理)
java安裝后版本不一樣怎么辦
題目二、Zookeeper搭建(30分)
Zookeeper是一個分布式服務框架,是Apache Hadoop 的一個子專案,它主要是用來解決分布式應用中經常遇到的一些資料管理問題,如:統一命名服務、狀態同步服務、集群管理、分布式應用配置項的管理等,
預裝的組態檔zoo_sample.cfg下面默認有五個屬性,分別是:
1.tickTime
心跳間隔,單位是毫秒,系統默認是2000毫秒,也就是間隔兩秒心跳一次,
tickTime的意義:客戶端與服務器或者服務器與服務器之間維持心跳,也就是每個tickTime時間就會發送一次心跳,通過心跳不僅能夠用來監聽機器的作業狀態,還可以通過心跳來控制Flower跟Leader的通信時間,默認情況下FL的會話時常是心跳間隔的兩倍,
2.initLimit
集群中的follower服務器(F)與leader服務器(L)之間初始連接時能容忍的最多心跳數(tickTime的數量),
3.syncLimit
集群中flower服務器(F)跟leader(L)服務器之間的請求和答應最多能容忍的心跳數,
4.clientPort
客戶端連接的介面,客戶端連接zookeeper服務器的埠,zookeeper會監聽這個埠,接收客戶端的請求訪問,埠默認是2181,
5.dataDir
該屬性對應的目錄是用來存放myid資訊跟一些版本,日志,跟服務器唯一的ID資訊等,
在集群Zookeeper服務在啟動的時候,會回去讀取zoo.cfg這個檔案,從這個檔案中找到這個屬性然后獲取它的值也就是dataDir 的路徑,它會從這個路徑下面讀取myid這個檔案,從這個檔案中獲取要啟動的當前服務器的地址,
集群資訊的配置:
在組態檔中,配置集群資訊是存在一定的格式:service.N =YYY: A:B
N:代表服務器編號(準確對應對應服務器中myid里面的值)
YYY:服務器地址
A:表示 Flower 跟 Leader的通信埠,簡稱服務端內部通信的埠(默認2888)
B:表示是選舉埠(默認是3888)
例如:server.1=master:2888:3888
組態檔參考
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
# 配置資料存盤路徑
????
# 配置日志檔案路徑
????
# 配置集群串列
server.1=????
server.2=????
server.3=????Zookeeper集群環境搭建(30分)
Zookeeper是一個分布式服務框架,是Apache Hadoop 的一個子專案,它主要是用來解決分布式應用中經常遇到的一些資料管理問題,如:統一命名服務、狀態同步服務、集群管理、分布式應用配置項的管理等,
預裝的組態檔zoo_sample.cfg下面默認有五個屬性,分別是:
1.tickTime
心跳間隔,單位是毫秒,系統默認是2000毫秒,也就是間隔兩秒心跳一次,
tickTime的意義:客戶端與服務器或者服務器與服務器之間維持心跳,也就是每個tickTime時間就會發送一次心跳,通過心跳不僅能夠用來監聽機器的作業狀態,還可以通過心跳來控制Flower跟Leader的通信時間,默認情況下FL的會話時常是心跳間隔的兩倍,
2.initLimit
集群中的follower服務器(F)與leader服務器(L)之間初始連接時能容忍的最多心跳數(tickTime的數量),
3.syncLimit
集群中flower服務器(F)跟leader(L)服務器之間的請求和答應最多能容忍的心跳數,
4.clientPort
客戶端連接的介面,客戶端連接zookeeper服務器的埠,zookeeper會監聽這個埠,接收客戶端的請求訪問,埠默認是2181,
5.dataDir
該屬性對應的目錄是用來存放myid資訊跟一些版本,日志,跟服務器唯一的ID資訊等,
在集群Zookeeper服務在啟動的時候,會回去讀取zoo.cfg這個檔案,從這個檔案中找到這個屬性然后獲取它的值也就是dataDir 的路徑,它會從這個路徑下面讀取myid這個檔案,從這個檔案中獲取要啟動的當前服務器的地址,
集群資訊的配置:
在組態檔中,配置集群資訊是存在一定的格式:service.N =YYY: A:B
N:代表服務器編號(準確對應對應服務器中myid里面的值)
YYY:服務器地址
A:表示 Flower 跟 Leader的通信埠,簡稱服務端內部通信的埠(默認2888)
B:表示是選舉埠(默認是3888)
例如:server.1=master:2888:3888
組態檔參考
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
# 配置資料存盤路徑
????
# 配置日志檔案路徑
????
# 配置集群串列
server.1=????
server.2=????
server.3=????考核條件如下:
1. 將zookeeper安裝包解壓到指定路徑/usr/zookeeper(安裝包存放于/usr/package277/)(3分)
操作環境: master、slave1、slave2
mkdir /usr/zookeeper
tar -zxvf /usr/package277/zookeeper-3.4.14.tar.gz -C /usr/zookeeper/ 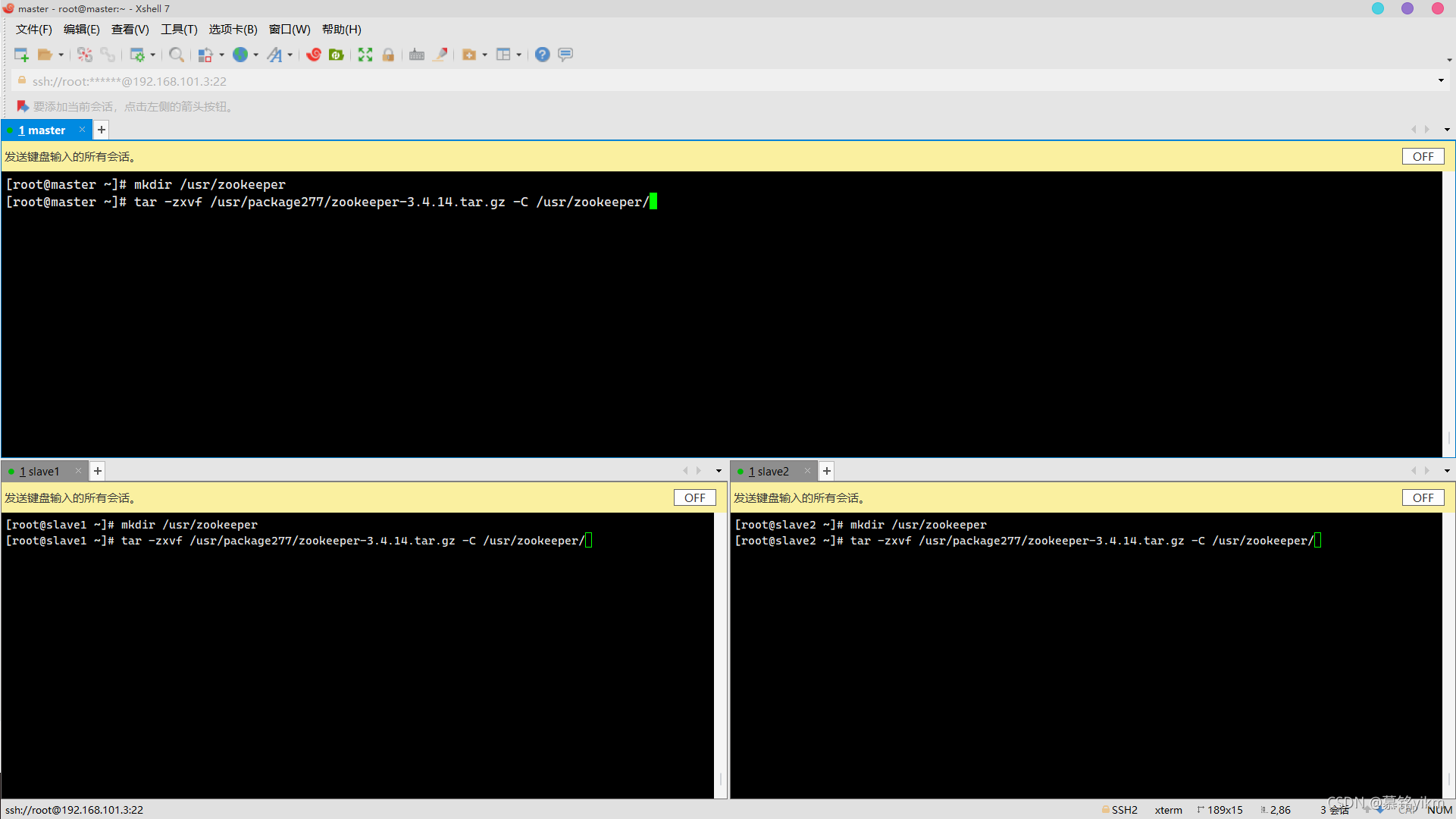
2. 檔案/etc/profile中配置系統變數ZOOKEEPER_HOME,同時將Zookeeper安裝路徑中bin目錄加入PATH系統變數,注意生效變數(3分)
操作環境: master、slave1、slave2
vim /etc/profile
加入:
#zookeeper
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.14
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source /etc/profile 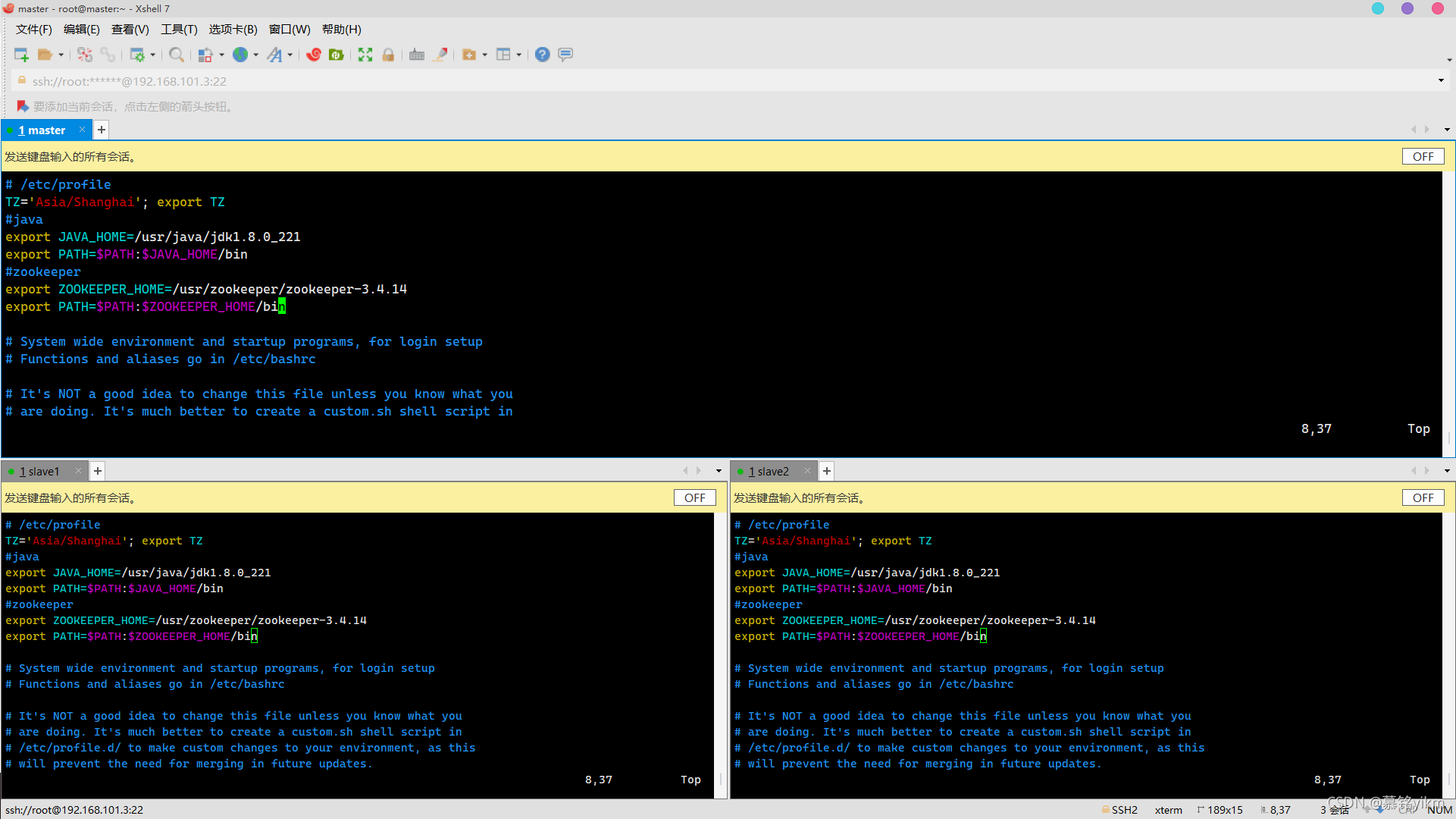
3. Zookeeper的默認組態檔為Zookeeper安裝路徑下conf/zoo_sample.cfg,將其修改為zoo.cfg(3分)
操作環境: master、slave1、slave2
cd /usr/zookeeper/zookeeper-3.4.14/conf/
ll
mv zoo_sample.cfg zoo.cfg
ll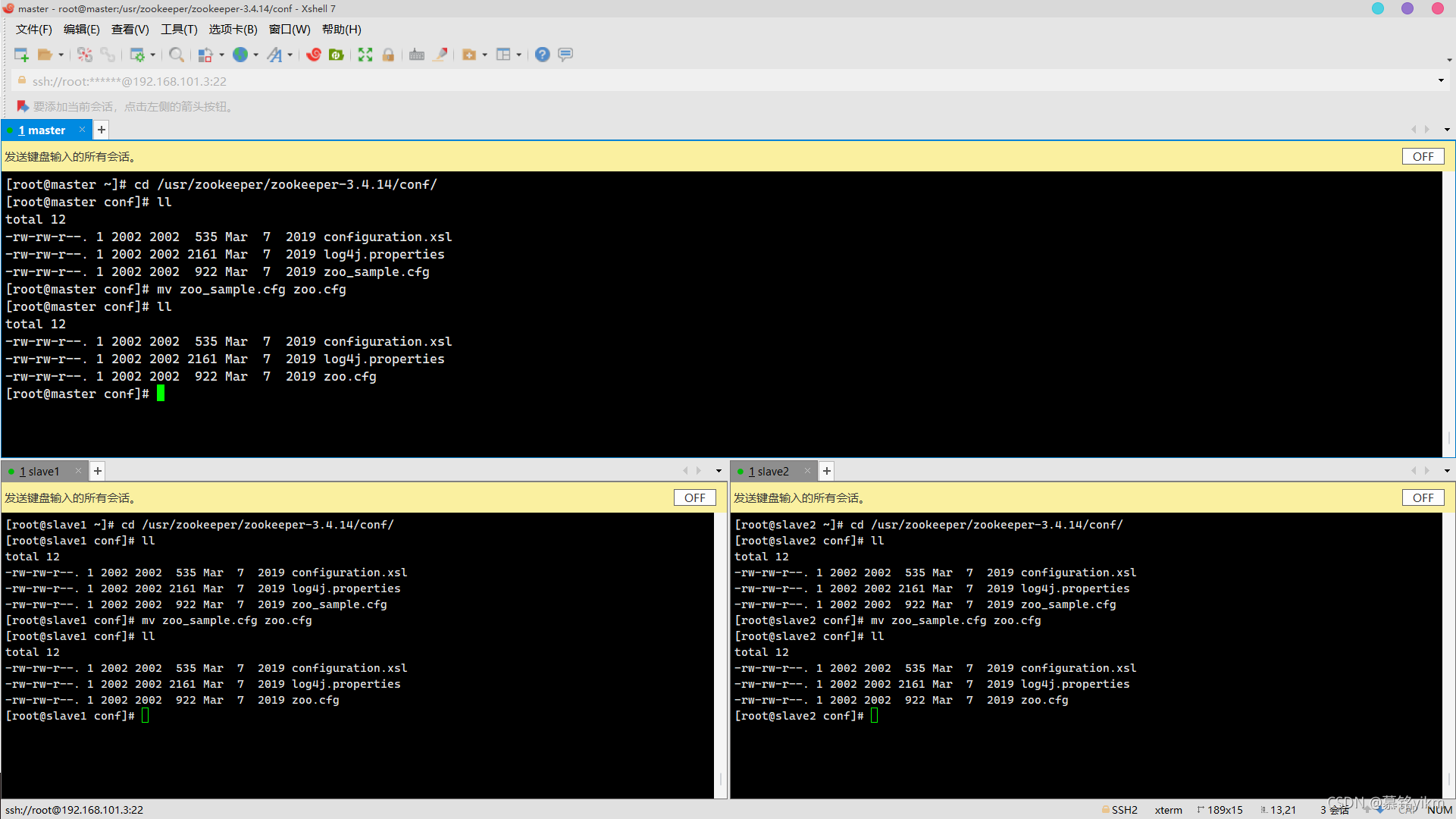 4. 設定資料存盤路徑(dataDir)為/usr/zookeeper/zookeeper-3.4.14/zkdata(3分)
4. 設定資料存盤路徑(dataDir)為/usr/zookeeper/zookeeper-3.4.14/zkdata(3分)
操作環境: master、slave1、slave2
5. 設定日志檔案路徑(dataLogDir)為/usr/zookeeper/zookeeper-3.4.14/zkdatalog(3分)
操作環境: master、slave1、slave2
6. 設定集群串列(要求master為1號服務器,slave1為2號服務器,slave2為3號服務器)(3分)
操作環境: master、slave1、slave2
4,5,6:
vim /etc/profile
修改:
dataDir=/usr/zookeeper/zookeeper-3.4.14/zkdata
加入:
dataLogDir=/usr/zookeeper/zookeeper-3.4.14/zkdatalog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888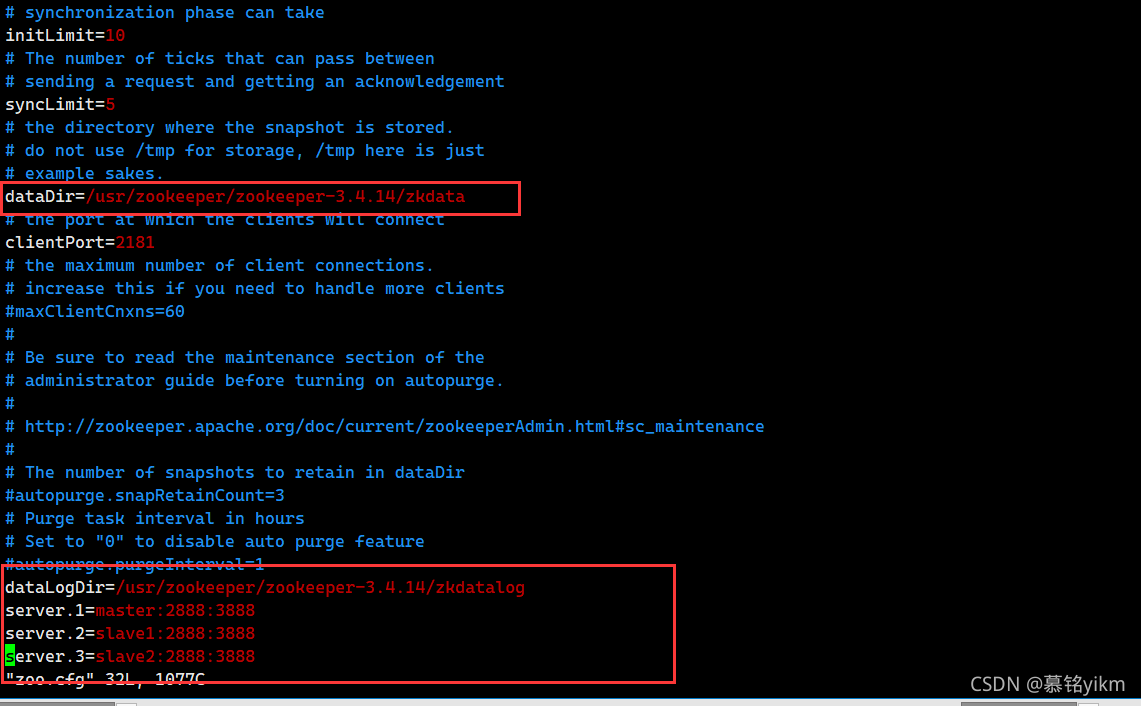 7. 創建所需資料存盤檔案夾、日志存盤檔案夾(3分)
7. 創建所需資料存盤檔案夾、日志存盤檔案夾(3分)
操作環境: master、slave1、slave2
cd /usr/zookeeper/zookeeper-3.4.14/
mkdir zkdata zkdatalog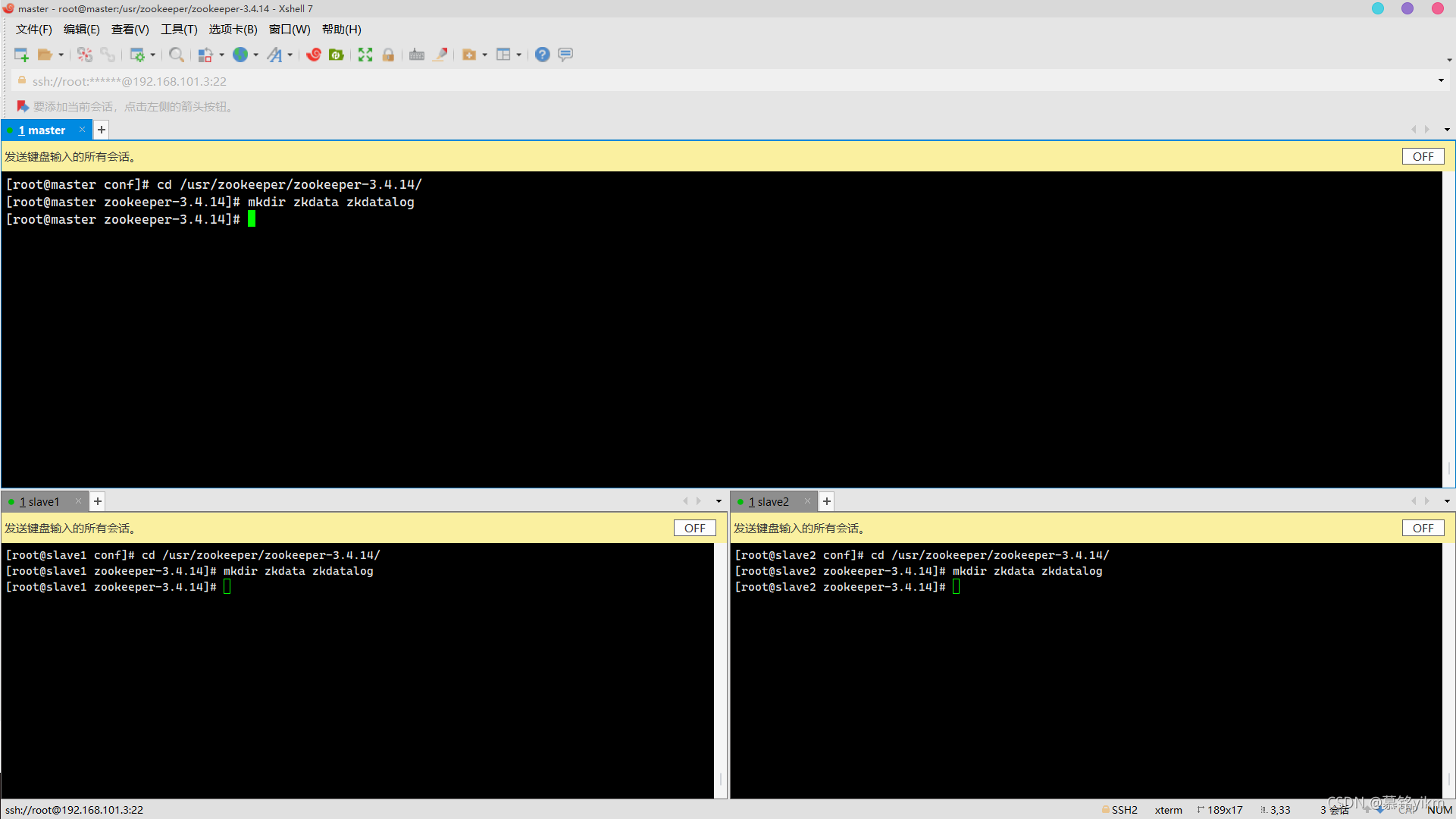 8. 資料存盤路徑下創建myid,寫入對應的標識主機服務器序號(3分)
8. 資料存盤路徑下創建myid,寫入對應的標識主機服務器序號(3分)
操作環境: master、slave1、slave2
cd zkdata
echo "1" >>myid (master上)
echo "2" >>myid (slave1上)
echo "3" >>myid (slave2上)
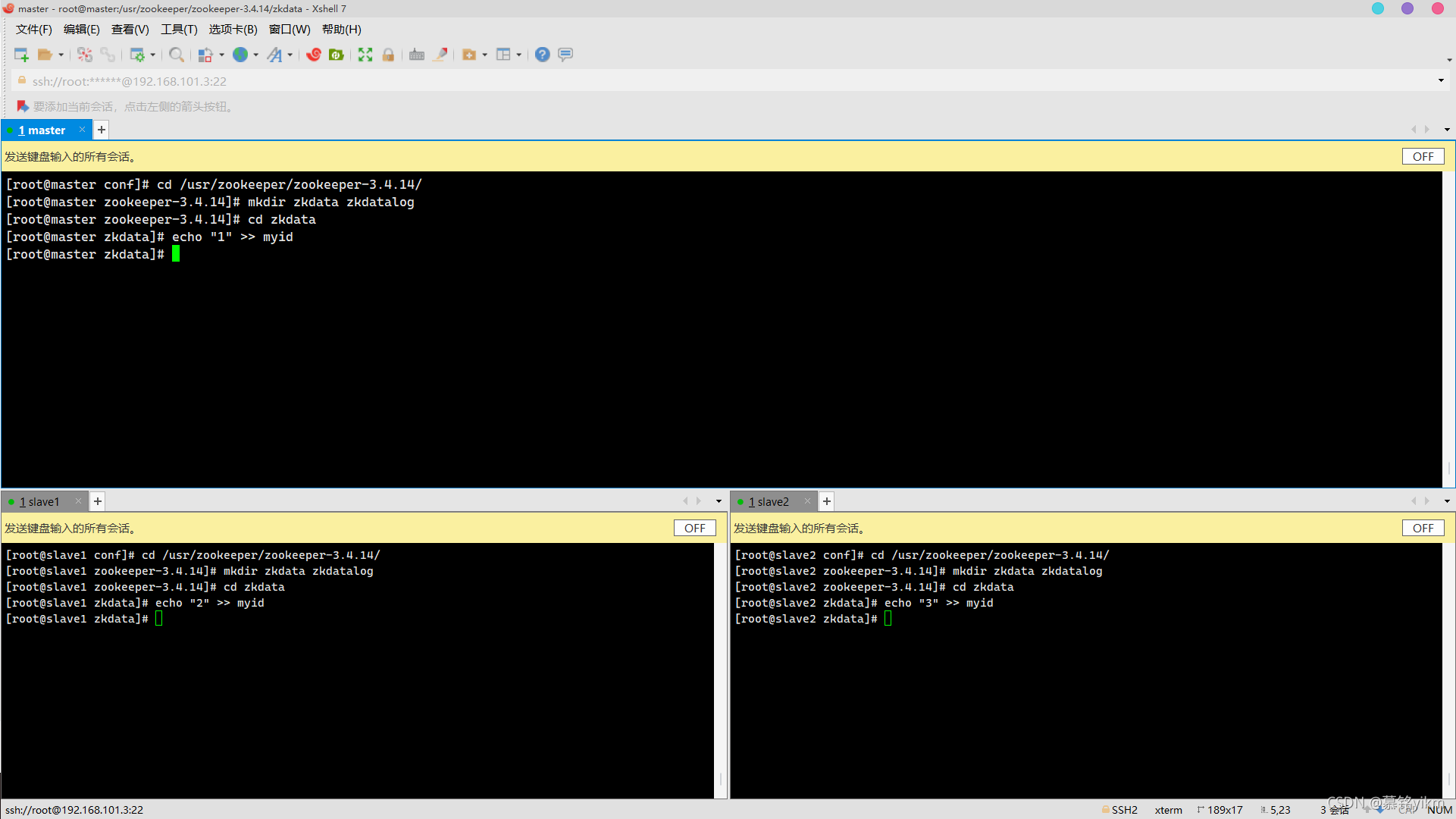
9. 啟動服務,查看行程QuorumPeerMain是否存在(3分)
操作環境: master、slave1、slave2
cd ..
bin/zkServer.sh start
jps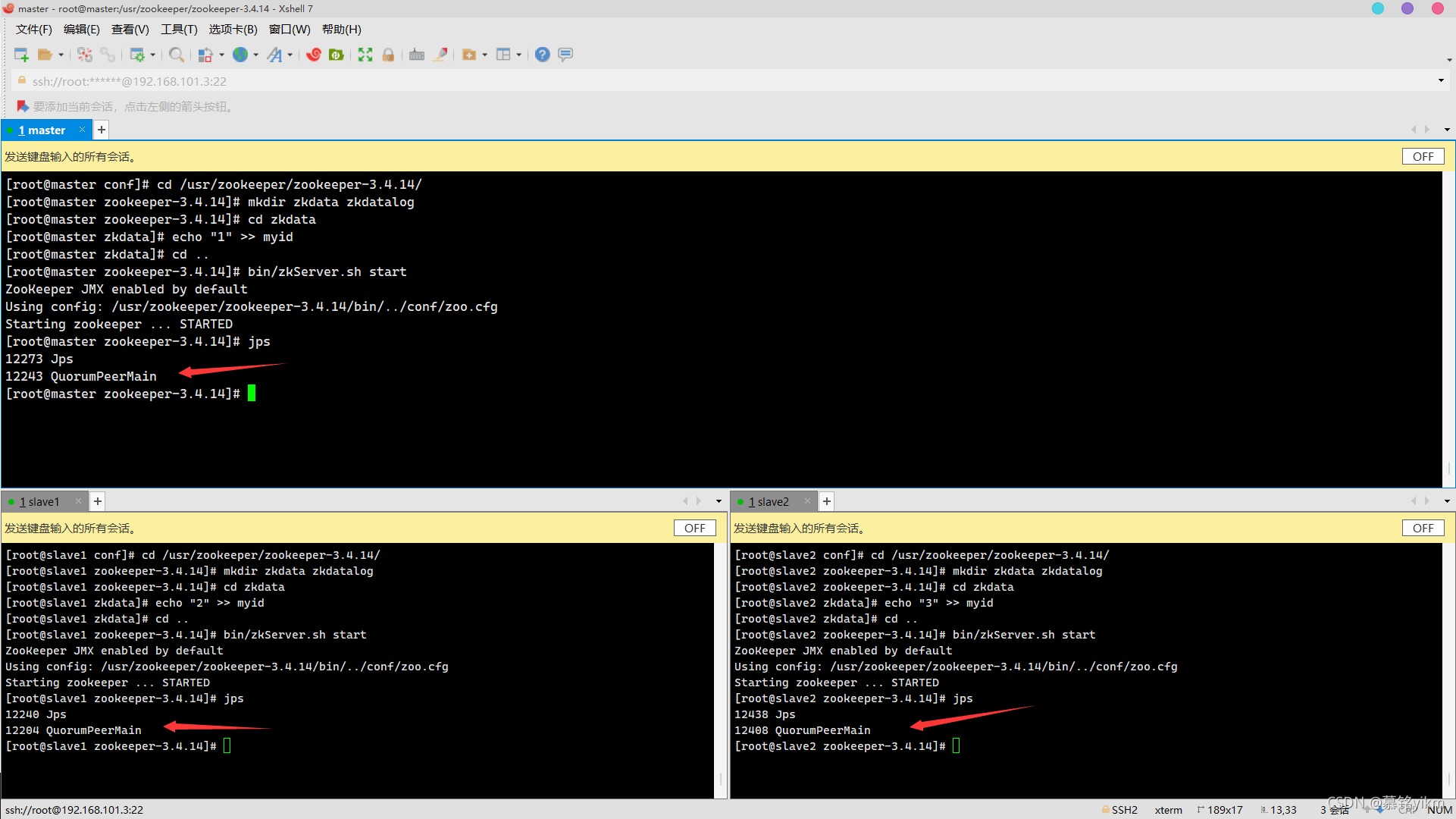 10. 查看各節點服務器角色是否正常(leader/follower)(3分)
10. 查看各節點服務器角色是否正常(leader/follower)(3分)
操作環境: master、slave1、slave2
bin/zkServer.sh status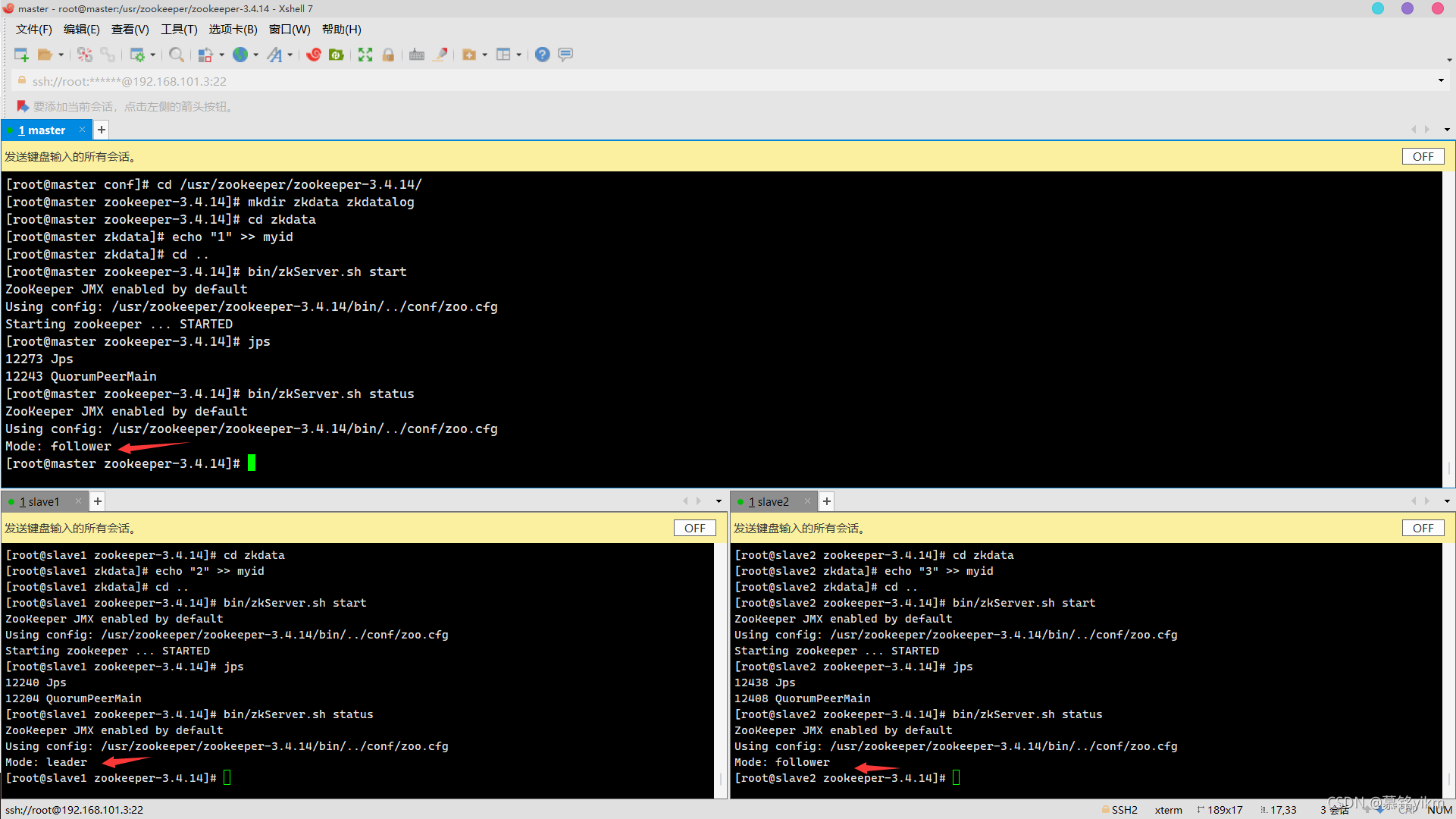
題目三、Hadoop集群搭建( 80分)
Hadoop是由Java語言撰寫的,在分布式服務器集群上存盤海量資料并運行分布式分析應用的開源框架,其核心部件是HDFS與MapReduce,
- HDFS是一個分布式檔案系統:引入存放檔案元資料資訊的服務器Namenode和實際存放資料的服務器Datanode,對資料進行分布式儲存和讀取,
- MapReduce是一個計算框架:MapReduce的核心思想是把計算任務分配給集群內的服務器里執行,通過對計算任務的拆分(Map計算/Reduce計算)再根據任務調度器(JobTracker)對任務進行分布式計算,
| 組態檔 | 配置物件 | 主要內容 |
| hadoop-env.sh | hadoop運行環境 | 用來定義Hadoop運行環境相關的配置資訊; |
| core-site.xml | 集群全域引數 | 定義系統級別的引數,包括HDFS URL、Hadoop臨時目錄等; |
| hdfs-site.xml | HDFS引數 | 定義名稱節點、資料節點的存放位置、文本副本的個數、檔案讀取權限等; |
| mapred-site.xml | MapReduce引數 | 包括JobHistory Server 和應用程式引數兩部分,如reduce任務的默認個數、任務所能夠使用記憶體的默認上下限等; |
| yarn-site.xml | 集群資源管理系統引數 | 配置ResourceManager ,nodeManager的通信埠,web監控埠等; |
Hadoop的配置類是由資源指定的,資源可以由一個String或Path來指定,資源以XML形式的資料表示,由一系列的鍵值對組成,資源可以用String或path命名(示例如下),
- String:指示hadoop在classpath中查找該資源;
- Path:指示hadoop在本地檔案系統中查找該資源,
<configuration>
<property>
<name>fs.default.name</name>
<value>????</value>
</property>
</configuration>常用屬性決議:
1.core-site.xml引數
| 配置引數 | 說明 |
| fs.default.name | 用于指定NameNode的地址 |
| hadoop.tmp.dir | Hadoop運行時產生檔案的臨時存盤目錄 |
2.hdfs-site.xml
| 配置引數 | 說明 |
| dfs.replication | 用于指定NameNode的地址 |
| dfs.namenode.name.dir | NameNode在本地檔案系統中持久存盤命名空間和事務日志的路徑 |
| dfs.datanode.data.dir | DataNode在本地檔案系統中存放塊的路徑 |
| dfs.permissions | 集群權限系統校驗 |
| dfs.datanode.use.datanode.hostname | datanode之間通過域名方式通信 |
注意:外域機器通信需要用外網IP,未配置hostname訪問會訪問例外,可以在Java api客戶端使用conf.set("fs.client.use.datanode.hostname","true");,
3.mapreduce-site.xml
| 配置引數 | 說明 |
| mapreduce.framework.name | 指定執行MapReduce作業的運行時框架,屬性值可以是local,classic或yarn, |
4.yarn-site.xml
| 配置引數 | 說明 |
| yarn.resourcemanager.admin.address | 用于指定RM管理界面的地址(主機:埠) |
| yarn.nodemanager.aux-services | mapreduce 獲取資料的方式,指定在進行mapreduce作業時,yarn使用mapreduce_shuffle混洗技術,這個混洗技術是hadoop的一個核心技術,非常重要, |
| yarn.nodemanager.auxservices.mapreduce.shuffle.class | 用于指定混洗技術對應的位元組碼檔案,值為org.apache.hadoop.mapred.ShuffleHandler |
Hadoop完全分布式集群搭建(80分)
Hadoop是由Java語言撰寫的,在分布式服務器集群上存盤海量資料并運行分布式分析應用的開源框架,其核心部件是HDFS與MapReduce,
- HDFS是一個分布式檔案系統:引入存放檔案元資料資訊的服務器Namenode和實際存放資料的服務器Datanode,對資料進行分布式儲存和讀取,
- MapReduce是一個計算框架:MapReduce的核心思想是把計算任務分配給集群內的服務器里執行,通過對計算任務的拆分(Map計算/Reduce計算)再根據任務調度器(JobTracker)對任務進行分布式計算,
| 組態檔 | 配置物件 | 主要內容 |
| hadoop-env.sh | hadoop運行環境 | 用來定義Hadoop運行環境相關的配置資訊; |
| core-site.xml | 集群全域引數 | 定義系統級別的引數,包括HDFS URL、Hadoop臨時目錄等; |
| hdfs-site.xml | HDFS引數 | 定義名稱節點、資料節點的存放位置、文本副本的個數、檔案讀取權限等; |
| mapred-site.xml | MapReduce引數 | 包括JobHistory Server 和應用程式引數兩部分,如reduce任務的默認個數、任務所能夠使用記憶體的默認上下限等; |
| yarn-site.xml | 集群資源管理系統引數 | 配置ResourceManager ,nodeManager的通信埠,web監控埠等; |
Hadoop的配置類是由資源指定的,資源可以由一個String或Path來指定,資源以XML形式的資料表示,由一系列的鍵值對組成,資源可以用String或path命名(示例如下),
- String:指示hadoop在classpath中查找該資源;
- Path:指示hadoop在本地檔案系統中查找該資源,
<configuration>
<property>
<name>fs.default.name</name>
<value>????</value>
</property>
</configuration>常用屬性決議:
1.core-site.xml引數
| 配置引數 | 說明 |
| fs.default.name | 用于指定NameNode的地址 |
| hadoop.tmp.dir | Hadoop運行時產生檔案的臨時存盤目錄 |
2.hdfs-site.xml
| 配置引數 | 說明 |
| dfs.replication | 用于指定NameNode的地址 |
| dfs.namenode.name.dir | NameNode在本地檔案系統中持久存盤命名空間和事務日志的路徑 |
| dfs.datanode.data.dir | DataNode在本地檔案系統中存放塊的路徑 |
| dfs.permissions | 集群權限系統校驗 |
| dfs.datanode.use.datanode.hostname | datanode之間通過域名方式通信 |
注意:外域機器通信需要用外網IP,未配置hostname訪問會訪問例外,可以在Java api客戶端使用
conf.set("fs.client.use.datanode.hostname","true");,3.mapreduce-site.xml
| 配置引數 | 說明 |
| mapreduce.framework.name | 指定執行MapReduce作業的運行時框架,屬性值可以是local,classic或yarn, |
4.yarn-site.xml
| 配置引數 | 說明 |
| yarn.resourcemanager.admin.address | 用于指定RM管理界面的地址(主機:埠) |
| yarn.nodemanager.aux-services | mapreduce 獲取資料的方式,指定在進行mapreduce作業時,yarn使用mapreduce_shuffle混洗技術,這個混洗技術是hadoop的一個核心技術,非常重要, |
| yarn.nodemanager.auxservices.mapreduce.shuffle.class | 用于指定混洗技術對應的位元組碼檔案,值為org.apache.hadoop.mapred.ShuffleHandler |
考核條件如下:
1. 將Hadoop安裝包解壓到指定路徑/usr/hadoop(安裝包存放于/usr/package277/)(5分)
操作環境: master、slave1、slave2
mkdir /usr/hadoop
tar -zxvf /usr/package277/hadoop-2.7.7.tar.gz -C /usr/hadoop/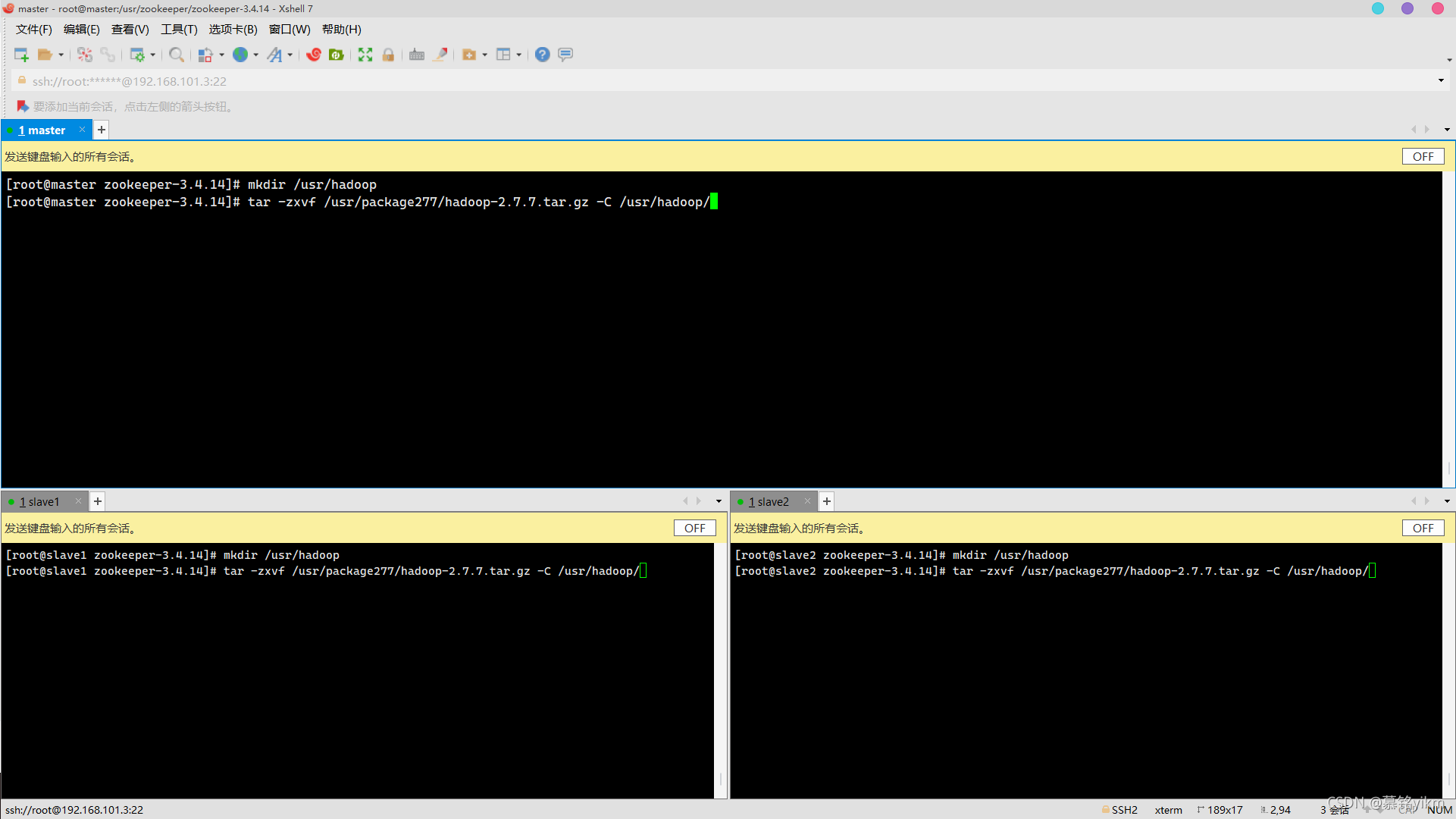
2. 檔案/etc/profile中配置環境變數HADOOP_HOME,將Hadoop安裝路徑中bin目錄和sbin目錄加入PATH系統變數,注意生效變數(5分)
操作環境: master、slave1、slave2
vim /etc/profile
加入:
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.7
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile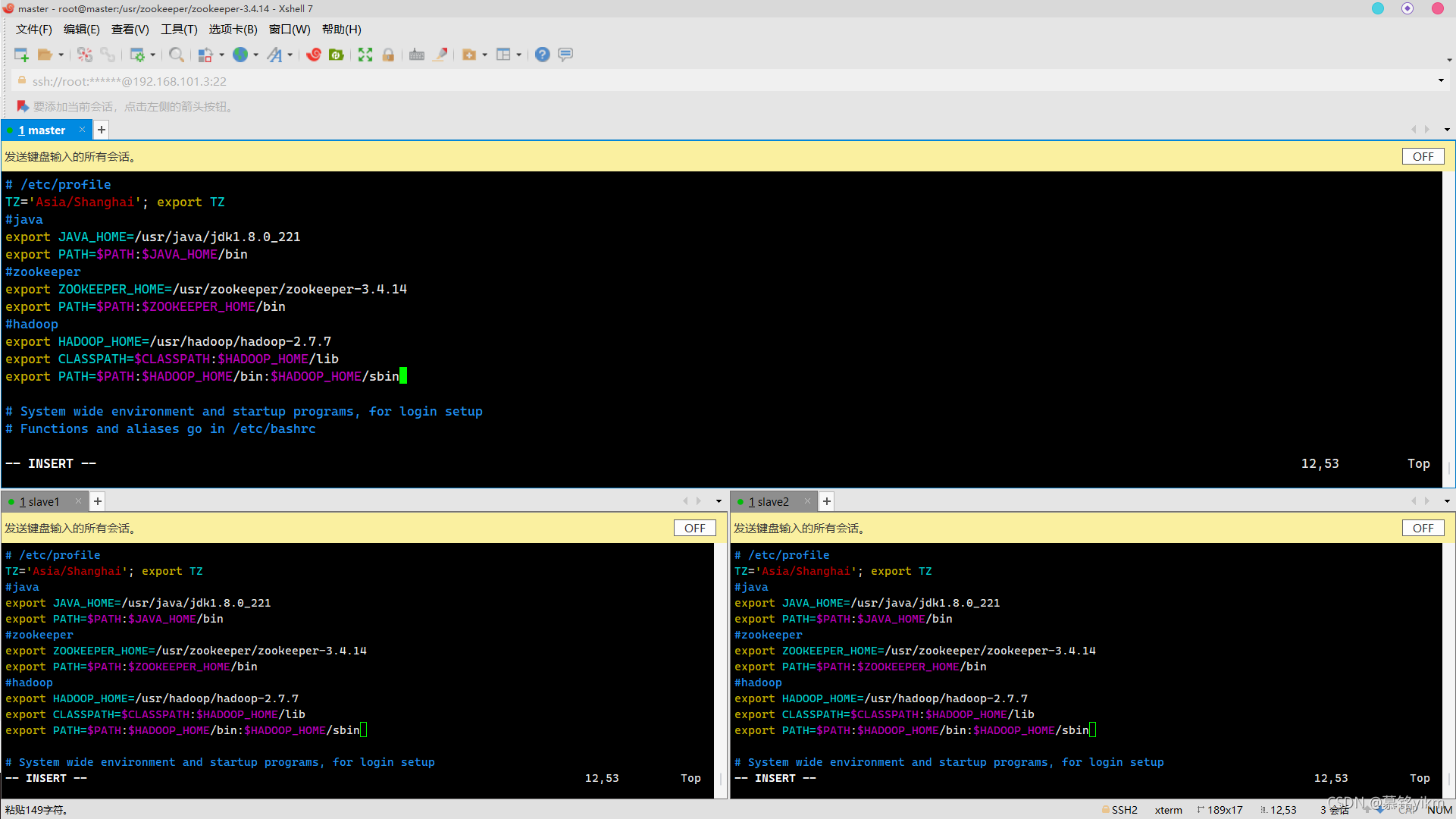
3. 配置Hadoop運行環境JAVA_HOME(5分)
操作環境: master、slave1、slave2
進入目錄(以下操作都在此目錄進行):
cd /usr/hadoop/hadoop-2.7.7/etc/hadoop/
pwd
修改hadoop-env.sh
echo "export JAVA_HOME=/usr/java/jdk1.8.0_221" >> hadoop-env.sh4. 設定全域引數,指定HDFS上NameNode地址為master,埠默認為9000(5分)
操作環境: master、slave1、slave2
5. 指定臨時存盤目錄為本地/root/hadoopData/tmp(要求為絕對路徑,下同)(5分)
操作環境: master、slave1、slave2
4,5:
vim core-site.xml加入:
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoopData/tmp</value>
</property>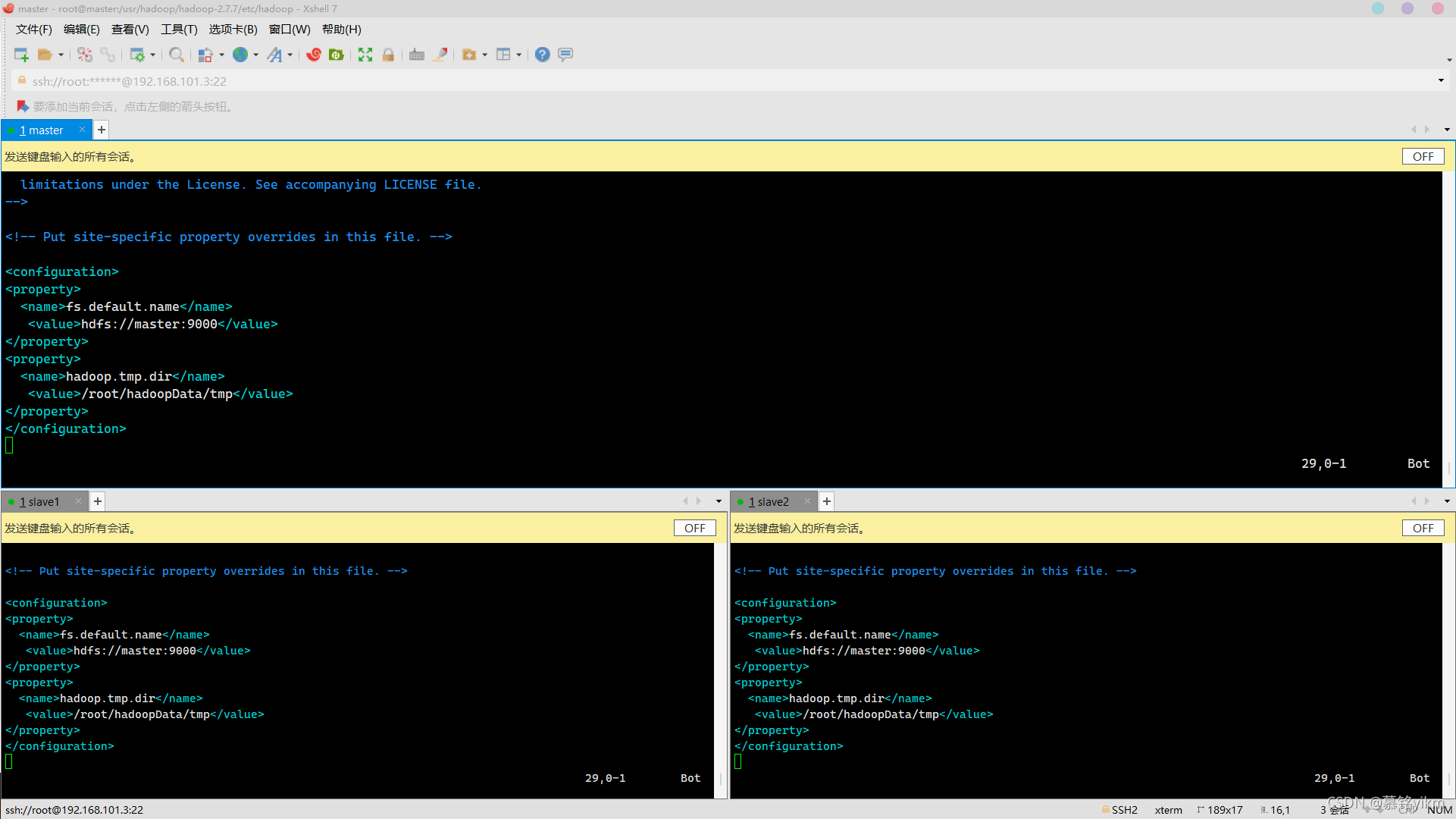
6. 設定HDFS引數,指定備份文本數量為2(5分)
操作環境: master、slave1、slave2
7. 設定HDFS引數,指定NN存放元資料資訊路徑為本地/root/hadoopData/name;指定DN存放元資料資訊路徑為本地/root/hadoopData/data(要求為絕對路徑)(5分)
操作環境: master、slave1、slave2
8. 設定HDFS引數,關閉hadoop集群權限校驗(安全配置),允許其他用戶連接集群;指定datanode之間通過域名方式進行通信(5分)
操作環境: master、slave1、slave2
6,7,8:
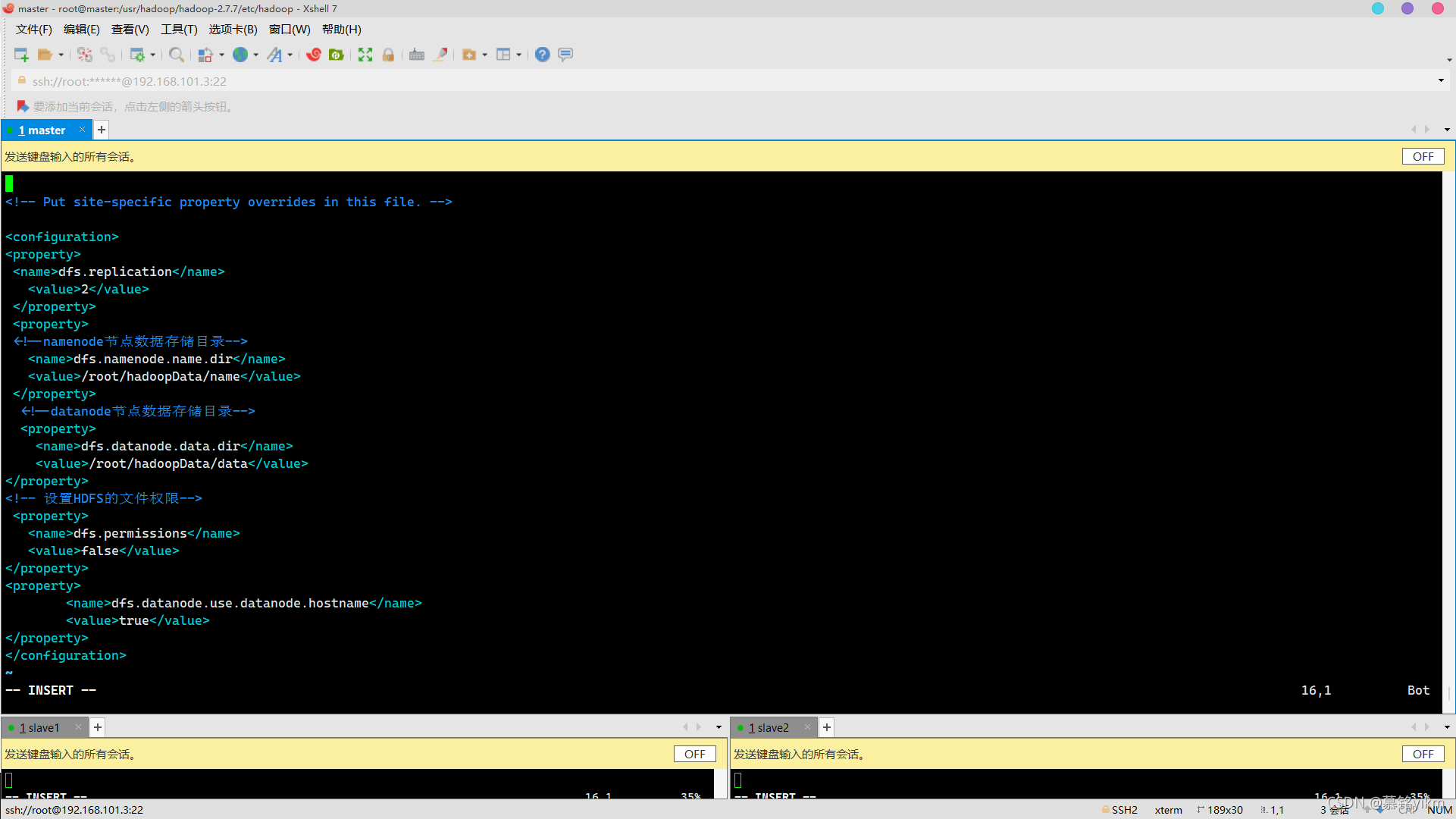
vim hdfs-site.xml加入:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!--namenode節點資料存盤目錄-->
<name>dfs.namenode.name.dir</name>
<value>/root/hadoopData/name</value>
</property>
<!--datanode節點資料存盤目錄-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoopData/data</value>
</property>
<!-- 設定HDFS的檔案權限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>
 9. 設定YARN運行環境JAVA_HOME引數(5分)
9. 設定YARN運行環境JAVA_HOME引數(5分)
操作環境: master、slave1、slave2
echo "export JAVA_HOME=/usr/java/jdk1.8.0_221" >> yarn-env.sh
10. 設定YARN核心引數,指定ResourceManager行程所在主機為master,埠為18141;指定mapreduce 獲取資料的方式為mapreduce_shuffle(5分)
操作環境: master、slave1、slave2
vim yarn-site.xml加入:
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.shuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>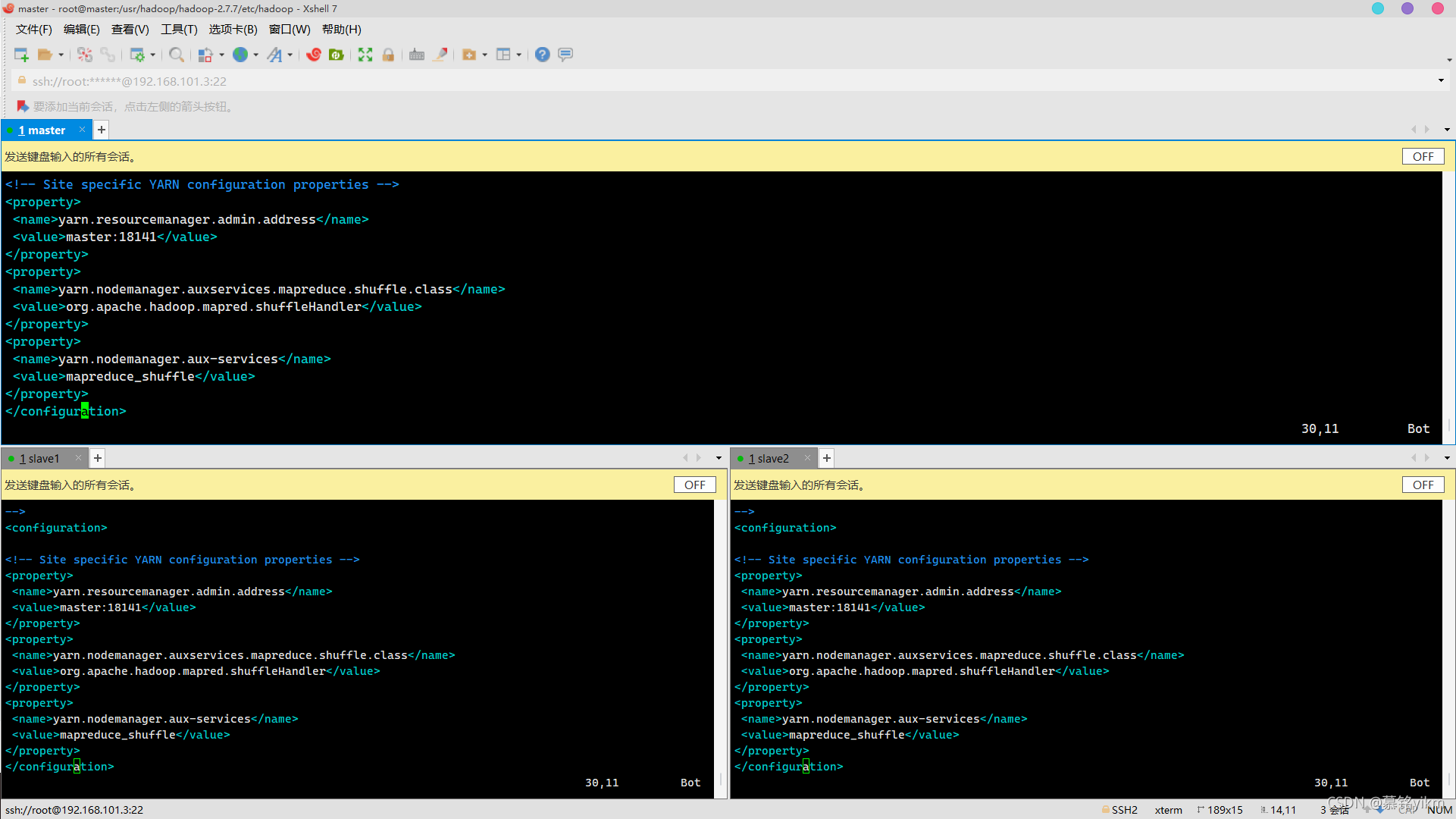
11. 設定計算框架引數,指定MR運行在yarn上(5分)
操作環境: master、slave1、slave2
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
加入:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
12. 設定節點檔案,要求master為主節點; slave1、slave2為子節點(5分)
操作環境: master、slave1、slave2
echo "master" >> mastervim slaves修改localhost為:
slave1
slave213. 對檔案系統進行格式化(5分)
操作環境: master
cd /usr/hadoop/hadoop-2.7.7/
hadoop namenode -format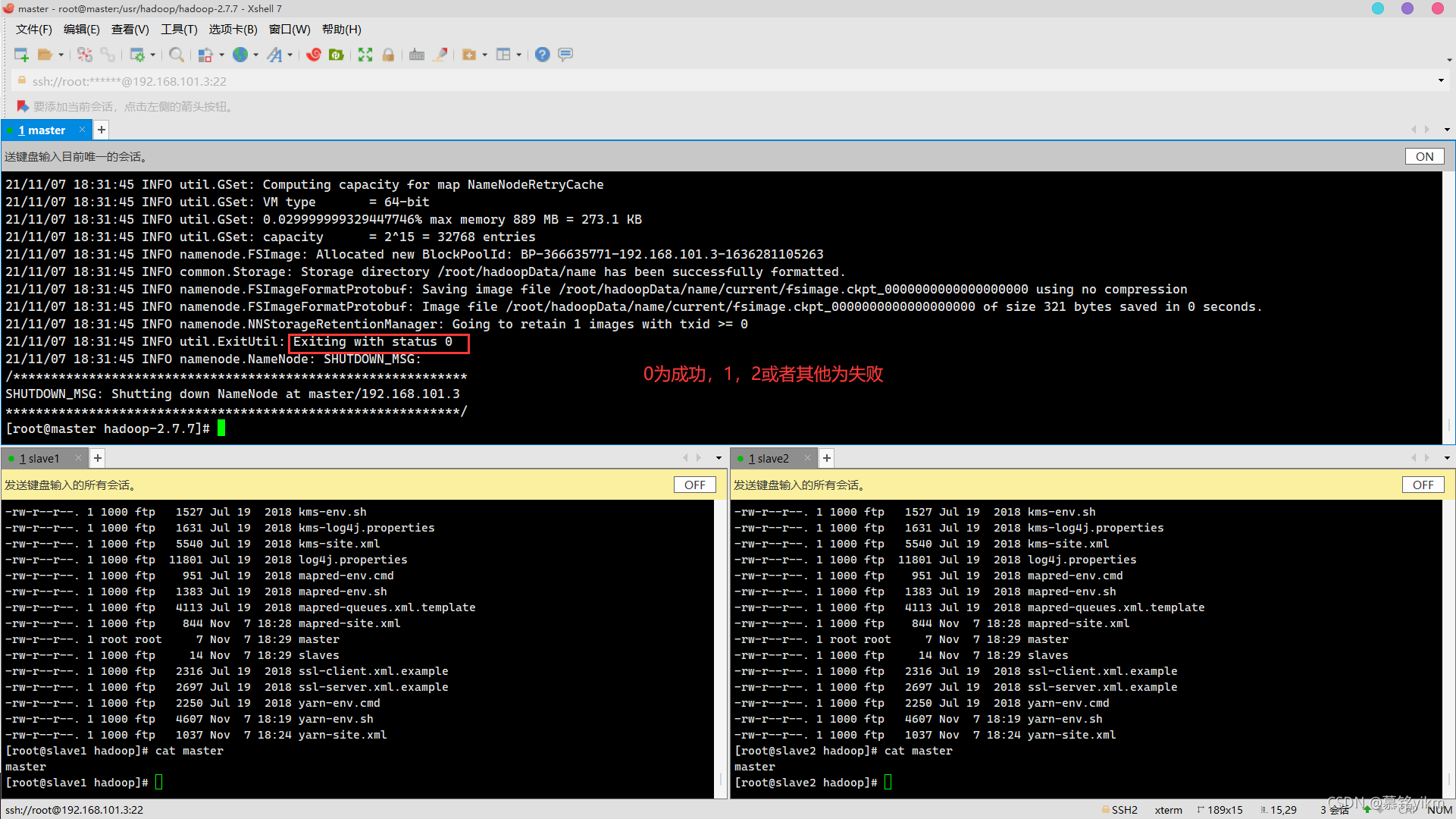
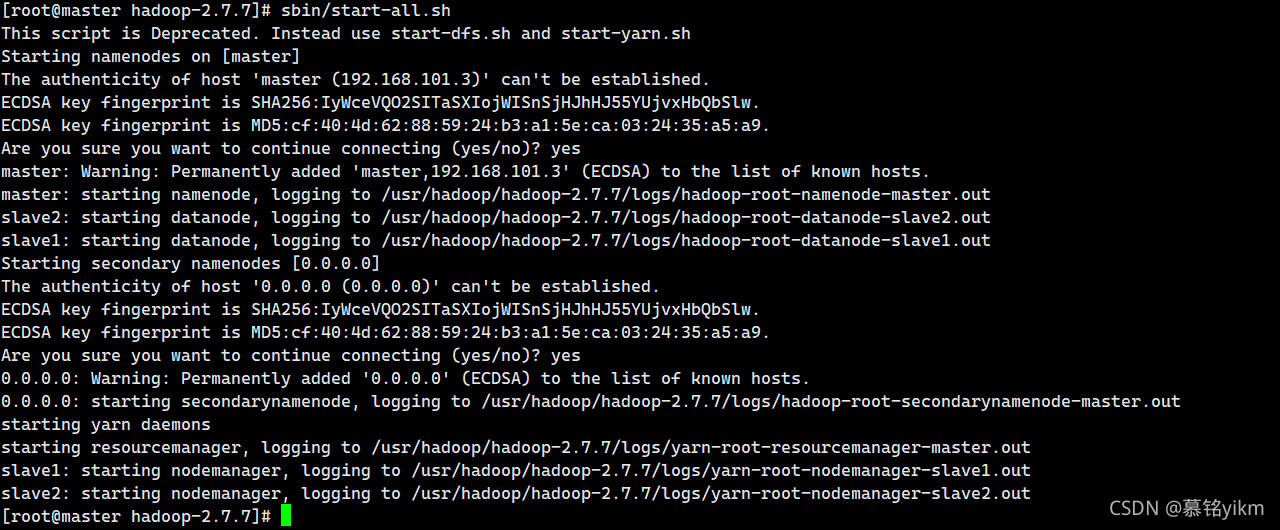
14. 啟動Hadoop集群查看各節點服務(5分)
操作環境: master、slave1、slave2
sbin/start-all.sh輸入yes
15. 查看集群運行狀態是否正常(10分)
操作環境: master
jps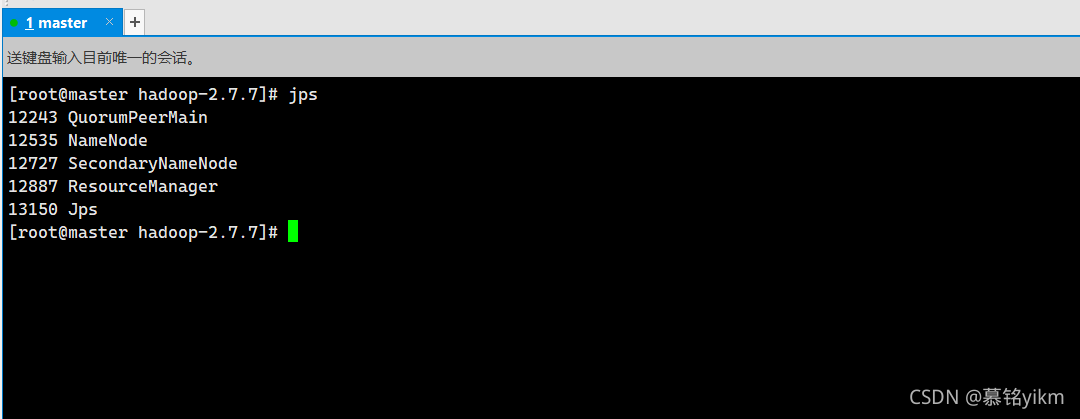 進入瀏覽器輸入:
進入瀏覽器輸入:
master:50070
(windows記得做ip映射,在"C:\Windows\System32\drivers\etc\hosts"處修改)
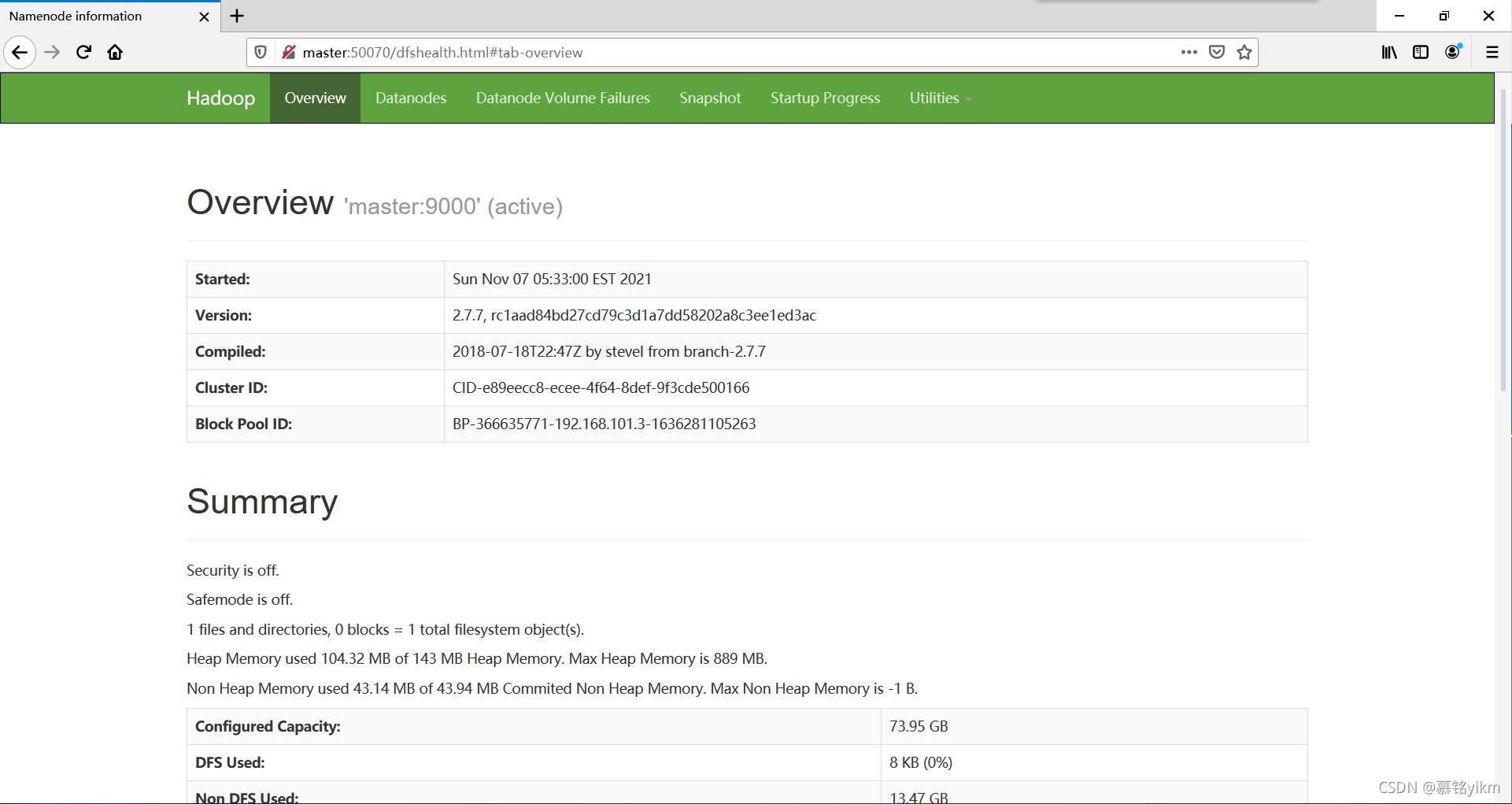
成功!
題目四、Hive集群搭建(30分)
1.比賽框架
本次比賽為分布式集群搭建,共三臺節點,其中master作為主節點,slave1、slave2為從節點;
2.比賽內容
- 基礎配置:修改主機名、主機映射、時區修改、時間同步、定時任務、免密訪問;
- JDK安裝:環境變數;
- Zookeeper部署:環境變數、組態檔zoo.cfg、myid;
- Hadoop部署:環境變數、組態檔修改、設定節點檔案、格式化、開啟集群;
- Hive部署:Mysql資料庫配置、服務器端配置、客戶端配置,
3.版本說明
| 內置安裝/依賴包(/usr/package277) | 已安裝服務 | 系統版本 |
| hadoop-2.7.7.tar.gz | ntp | CentOS Linux release 7.3.1611 (Core) |
| zookeeper-3.4.14.tar.gz | mysql-community-server | |
| apache-hive-2.3.4-bin.tar.gz | ||
| jdk-8u211-linux-x64.tar.gz | ||
| mysql-connector-java-5.1.47-bin.jar |
4.資料倉庫架構說明
集群中使用遠程模式,使用外部資料庫MySQL用于存盤元資料,使用client/thrift server的連接方式進行訪問,其中slave2作為mysql資料庫,slave1作為hive服務器端,master作為hive客戶端,
安裝資料庫(5分)
前提說明
- 相關安裝包已經存放至環境/usr/package277/中
- 對應ntp和mysql已安裝,可直接對其進行操作和配置
1.環境中已經安裝mysql-community-server,注意mysql5.7默認安裝后為root用戶隨機生成一個密碼;
- 直接查看密碼:grep "temporary password" /var/log/mysqld.log
- 登入資料庫:mysql -uroot -p
- 輸入隨機密碼即可登錄
2.根據要求設定密碼,注意對應的安全策略修改;
- 設定密碼強度為低級:set global validate_password_policy=????;
- 設定密碼長度:set global validate_password_length=????;
- 修改本地密碼:alter user 'root'@'localhost' identified by '????';
3.根據要求滿足任意主機節點root的遠程訪問權限(否則后續hive無法連接mysql);
- GRANT ALL PRIVILEGES ON *.* TO '????'@'%' IDENTIFIED BY '????' WITH GRANT OPTION;
4.注意重繪權限;
- flush privileges;
5.參考命令
- 啟動mysql服務:systemctl start mysqld.service
- 關閉mysql服務:systemctl stop mysqld.service
- 查看mysql服務:systemctl status mysqld.service
考核條件如下:
1. 環境中已經安裝mysql-community-server,關閉mysql開機自啟服務(1分)
操作環境: slave2
systemctl disable mysqld.service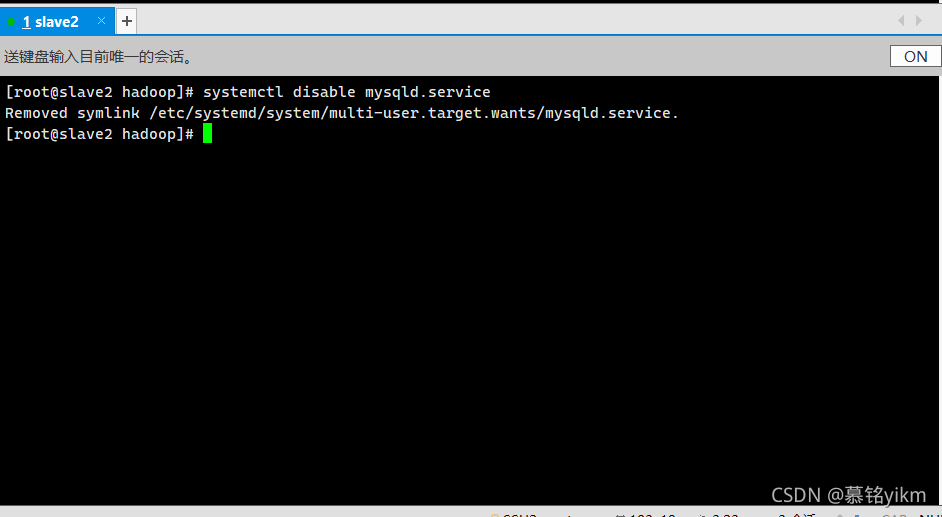
2. 開啟MySQL服務(1分)
操作環境: slave2
systemctl start mysqld.service3. 判斷mysqld.log日志下是否生成初臨時密碼(1分)
操作環境: slave2
grep "temporary password" /var/log/mysqld.log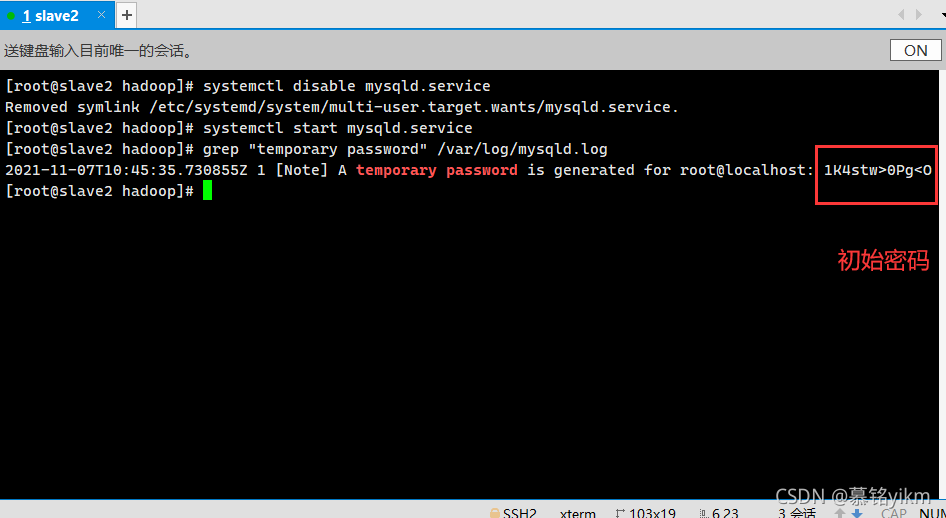
4. 設定mysql資料庫本地root用戶密碼為123456(2分)
操作環境: slave2
mysql -uroot -p- 輸入初始密碼即可登錄
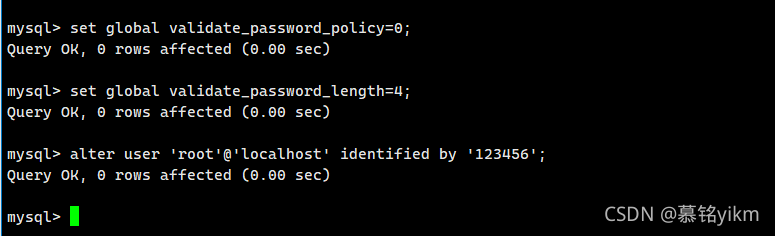
set global validate_password_policy=0;
set global validate_password_length=4;
alter user 'root'@'localhost' identified by '123456';
 遠程訪問權限:
遠程訪問權限:
\q 退出
以新密碼登陸 MySQL:
mysql -uroot -p
123456
create user 'root'@'%' identified by '123456';
grant all privileges on *.* to 'root'@'%' with grant option;
flush privileges;
\q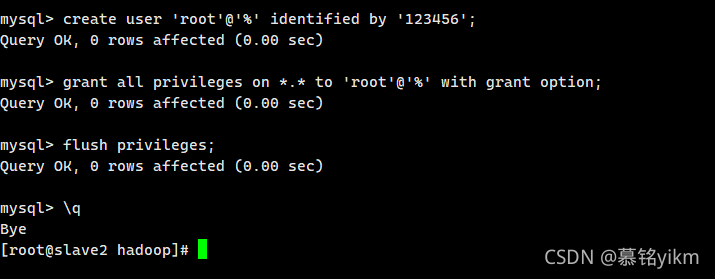
Hive基礎環境配置(9分)
Hive是基于Hadoop的一個資料倉庫工具,用來進行資料提取、轉化、加載,這是一種可以存盤、查詢和分析存盤在Hadoop中的大規模資料的機制,Hive資料倉庫工具能將結構化的資料檔案映射為一張資料庫表,并提供SQL查詢功能,能將SQL陳述句轉變成MapReduce任務來執行,
1.講指定版本的Hive安裝包解壓到指定路徑,添加系統并生效;
2.修改Hive運行環境
# 配置Hadoop安裝路徑
export HADOOP_HOME=????
# 配置Hive組態檔存放路徑為conf
export HIVE_CONF_DIR=????
# 配置Hive運行資源庫路徑為lib
export HIVE_AUX_JARS_PATH=????3.由于客戶端需要和Hadoop通信,為避免jline版本沖突問題,將Hive中lib/jline-2.12.jar拷貝到Hadoop中,保留高版本.
考核條件如下:
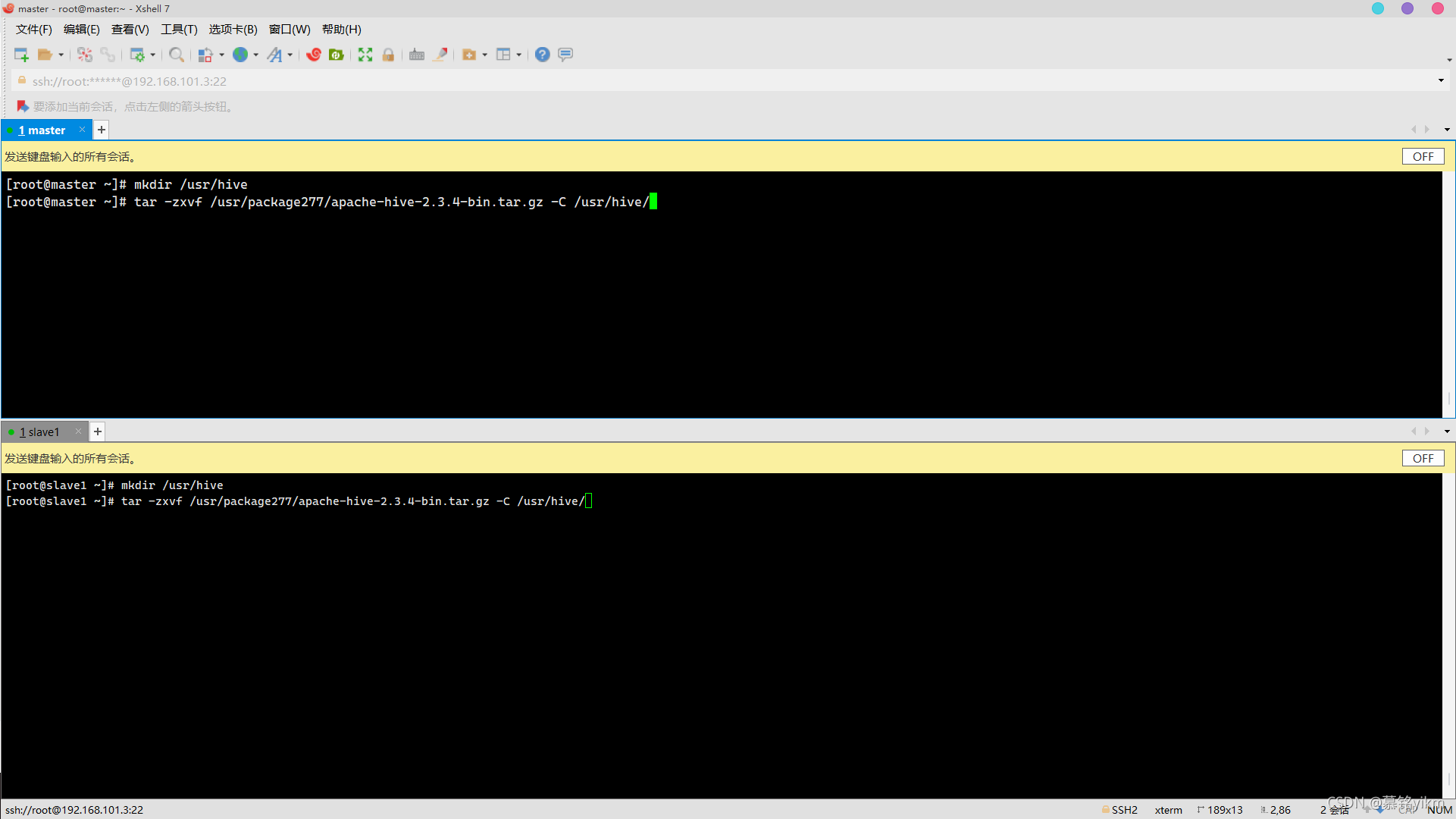
1. 將Hive安裝包解壓到指定路徑/usr/hive(安裝包存放于/usr/package277/(1分)
操作環境: master、slave1
mkdir /usr/hive
tar -zxvf /usr/package277/apache-hive-2.3.4-bin.tar.gz -C /usr/hive/
2. 檔案/etc/profile中配置環境變數HIVE_HOME,將Hive安裝路徑中的bin目錄加入PATH系統變數,注意生效變數(2分)
操作環境: master、slave1
vim /etc/profile
加入:
#hive
export HIVE_HOME=/usr/hive/apache-hive-2.3.4-bin
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile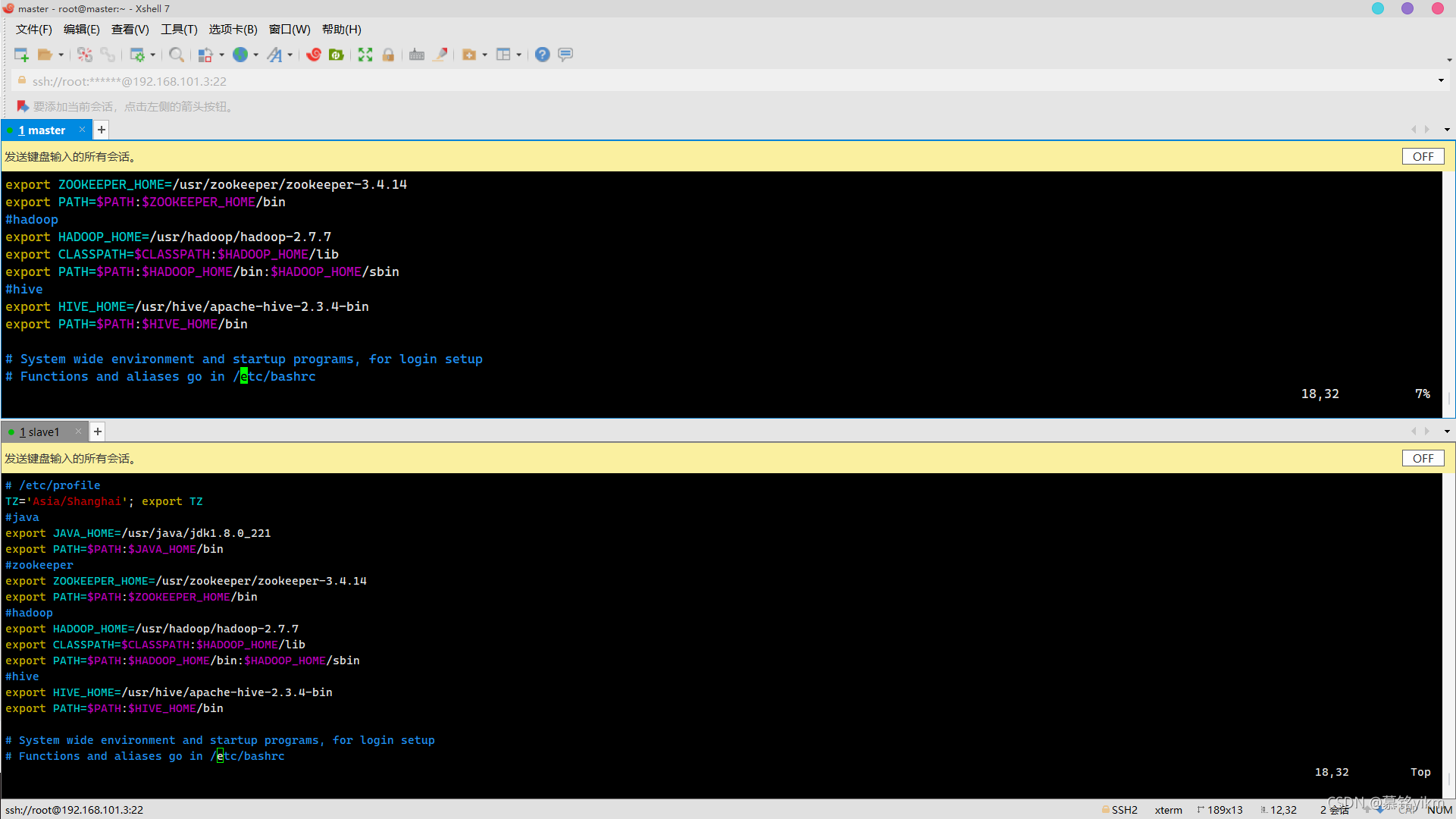
3. 修改HIVE運行環境,配置Hadoop安裝路徑HADOOP_HOME(2分)
操作環境: master、slave1
4. 修改HIVE運行環境,配置Hive組態檔存放路徑HIVE_CONF_DIR(1分)
操作環境: master、slave1
5. 修改HIVE運行環境,配置Hive運行資源庫路徑HIVE_AUX_JARS_PATH(1分)
操作環境: master、slave1
3,4,5:
cd /usr/hive/apache-hive-2.3.4-bin/conf/
mv hive-env.sh.template hive-env.sh
echo "export HADOOP_HOME=/usr/hadoop/hadoop-2.7.7
export HIVE_CONF_DIR=/usr/hive/apache-hive-2.3.4-bin/conf
export HIVE_AUX_JARS_PATH=/usr/hive/apache-hive-2.3.4-bin/lib" >> hive-env.sh
6. 解決jline的版本沖突,將$HIVE_HOME/lib/jline-2.12.jar同步至$HADOOP_HOME/share/hadoop/yarn/lib/下(2分)
操作環境: master,slave1
cp /usr/hive/apache-hive-2.3.4-bin/lib/jline-2.12.jar /usr/hadoop/hadoop-2.7.7/share/hadoop/yarn/lib/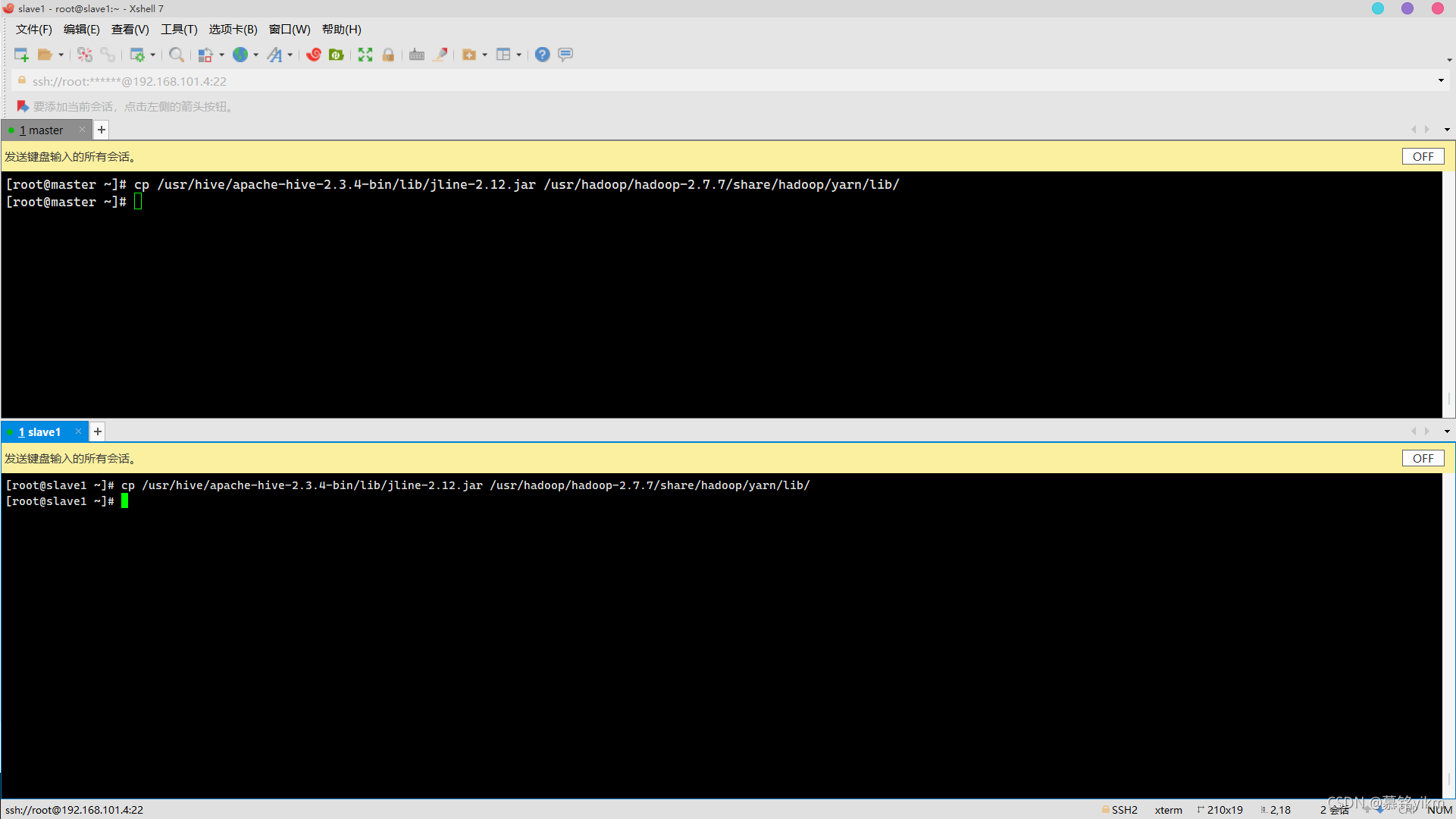
配置HIVE元資料至MySQL(8分)
1.slave1作為服務器端需要和Mysql通信,所以服務端需要將Mysql的依賴包放在Hive的lib目錄下,
mysql-connector-java是MySQL的JDBC驅動包,用JDBC連接MySQL資料庫時必須使用該jar包,
2.組態檔參考:
<configuration>
<!-- Hive產生的元資料存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>????</value>
</property>
<!-- 資料庫連接driver,即MySQL驅動-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>????</value>
</property>
<!-- 資料庫連接JDBC的URL地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://????:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!-- MySQL資料庫用戶名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>????</value>
</property>
<!-- MySQL資料庫密碼-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>????</value>
</property>
</configuration>考核條件如下:
1. 驅動JDBC拷貝至hive安裝目錄對應lib下(依賴包存放于/usr/package277/)( 1分)
操作環境: slave1
cp /usr/package277/mysql-connector-java-5.1.47-bin.jar /usr/hive/apache-hive-2.3.4-bin/lib/2. 配置元資料資料存盤位置為/user/hive_remote/warehouse(1分)
操作環境: slave1
3. 配置資料庫連接為MySQL(1分)
操作環境: slave1
4. 配置連接JDBC的URL地址主機名及默認埠號3306,資料庫為hive,如不存在自行創建,ssl連接方式為false(1分)
操作環境: slave1
5. 配置資料庫連接用戶(2分)
操作環境: slave1
6. 配置資料庫連接密碼(2分)
操作環境: slave1
2,3,4,5,6:
vim hive-site.xml
插入:
<configuration>
<!--Hive產生的元資料存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!--資料庫連接JDBC的URL地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://slave2:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!--資料庫連接driver,即MySQL驅動-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--MySQL資料庫用戶名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--MySQL資料庫密碼-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateALL</name>
<value>true</value>
</property>
</configuration>配置HIVE客戶端(4分)
1.master作為客戶端,可進入終端進行操作;
2.關閉本地模式;
3.將hive.metastore.uris指向metastore服務器URL;
4.組態檔參考:
<configuration>
<!-- Hive產生的元資料存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>????</value>
</property>
<!--- 使用本地服務連接Hive,默認為true-->
<property>
<name>hive.metastore.local</name>
<value>????</value>
</property>
<!-- 連接服務器-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://????</value>
</property>
</configuration>考核條件如下:
1. 配置元資料存盤位置為/user/hive_remote/warehouse(1分)
操作環境: master
2. 關閉本地metastore模式(1分)
操作環境: master
3. 配置指向metastore服務的主機為slave1,埠為9083(2分)
操作環境: master
1,2,3:
vim hive-site.xml插入:
<configuration>
<!--Hive產生的元資料存放位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!---使用本地服務連接Hive,默認為true-->
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!--連接服務器-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://slave1:9083</value>
</property>
</configuration>啟動Hive(4分)
1.服務器端初始化資料庫,并啟動metastore服務;
2.客戶端開啟Hive client,即可根據創建相關資料操作,
考核條件如下:
1. 服務器端初始化資料庫,啟動metastore服務(2分)
操作環境: slave1
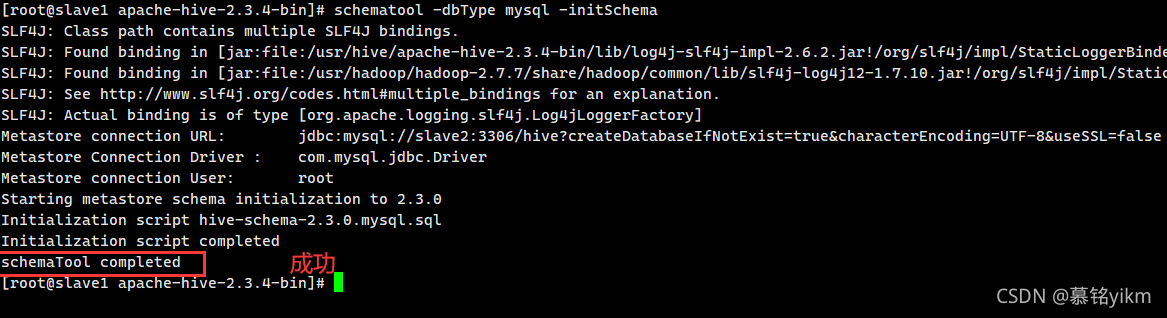
schematool -dbType mysql -initSchema
2. 客戶端開啟進入hive,創建hive資料庫(2分)
操作環境: master
bin/hive --service metastore &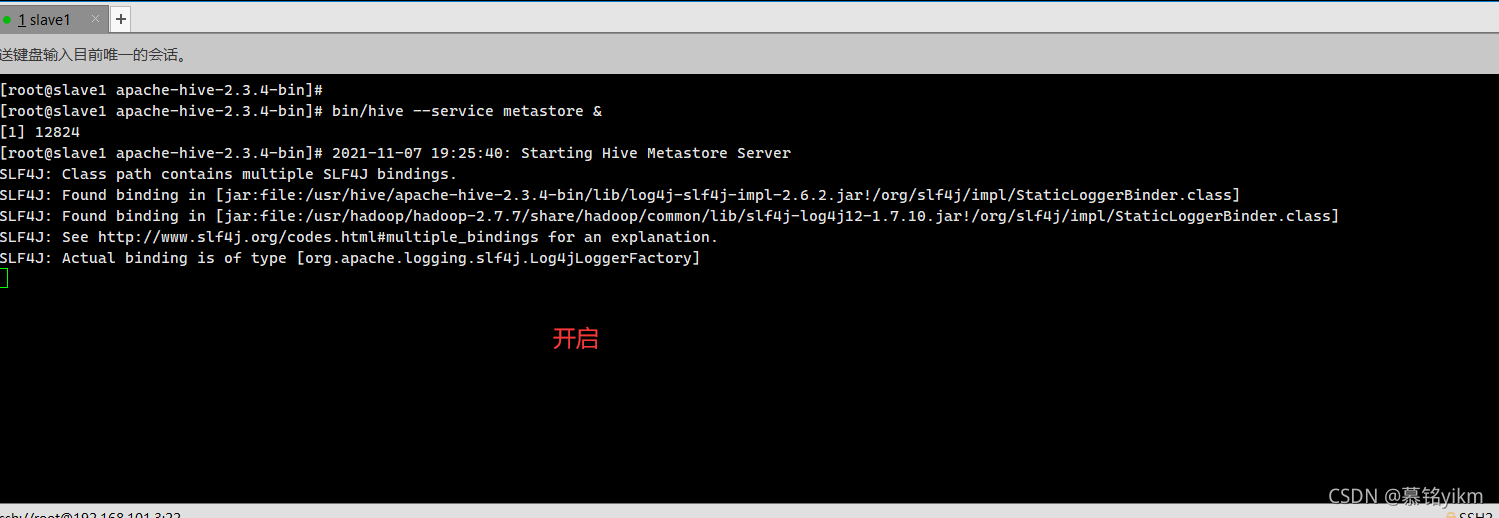
bin/hive
create database hive;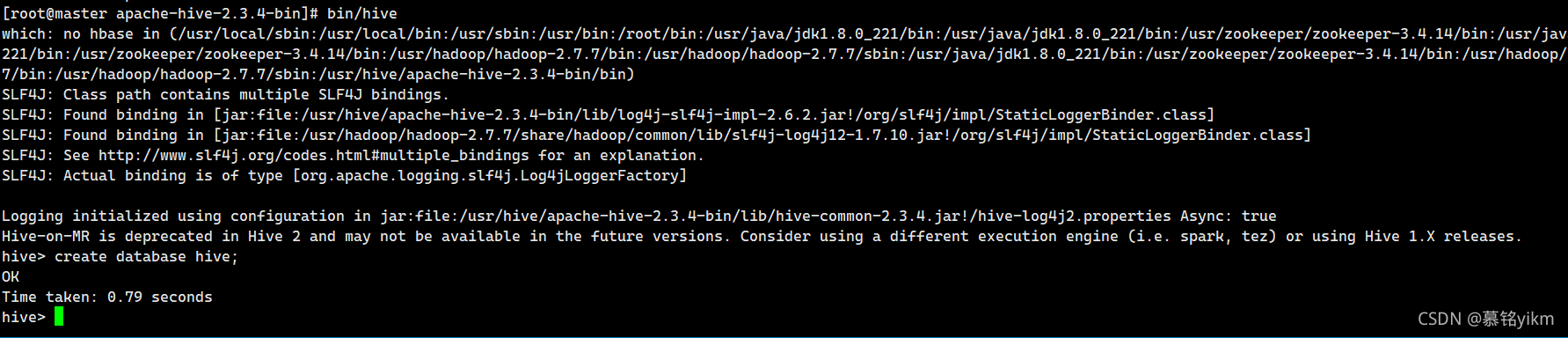
成功!
題目五、Spark搭建(30分)
Spark 是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,這些有用的不同之處使 Spark 在某些作業負載方面表現得更加優越,換句話說,Spark 啟用了記憶體分布資料集,除了能夠提供互動式查詢外,它還可以優化迭代作業負載,
Spark 是在 Scala 語言中實作的,它將 Scala 用作其應用程式框架,與 Hadoop 不同,Spark 和 Scala 能夠緊密集成,其中的 Scala 可以像操作本地集合物件一樣輕松地操作分布式資料集,
Scala安裝(6分)
使用Scala語言來實作Spark,Scala(Scalable Language)是一種多范式的編程語言,其設計的初衷是要集成面向物件編程和函式式編程的各種特性,
Scala運行于Java平臺(java虛擬機上),并兼容現有的Java程式,
面向物件(將物件當作引數傳來傳去) + 面向函式(方法,可以將函式當作引數傳來傳去)
考核條件如下:
1. 將Scala安裝包解壓到指定路徑/usr/scala(安裝包存放于/usr/package277/)(3分)
操作環境: master、slave1、slave2
mkdir /usr/scala
tar -zxvf /usr/package277/scala-2.10.3.tgz -C /usr/scala/2. 檔案/etc/profile中配置環境變數SCALA_HOME,將Scala安裝路徑中的bin目錄加入PATH系統變數,注意生效變數(3分)
操作環境: master、slave1、slave2
vim /etc/profile
加入:
#scala
export SCALA_HOME=/usr/scala/scala-2.10.3
export PATH=$PATH:$SCALA_HOME/bin
source /etc/profile
scala -version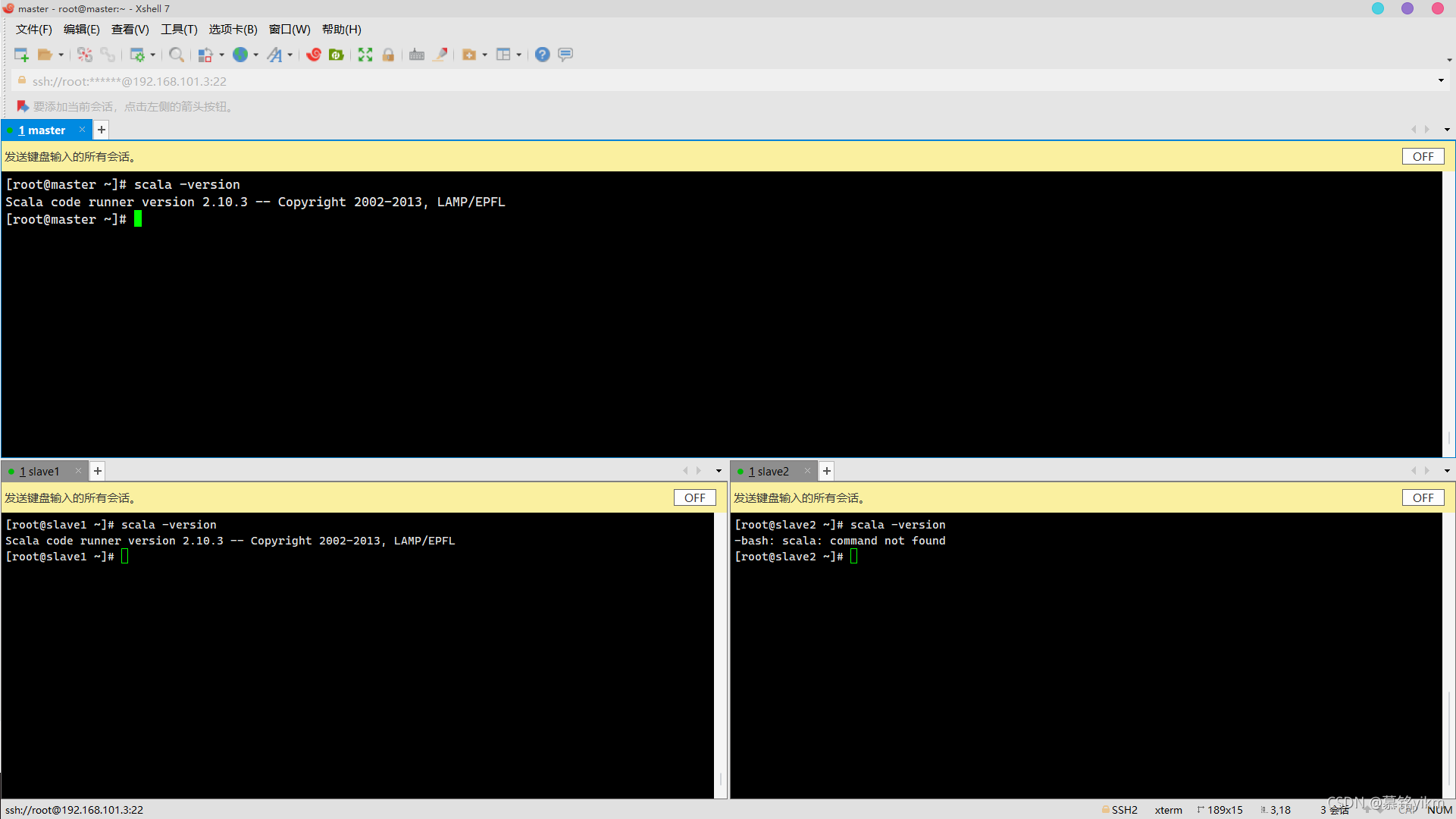
Spark集群搭建(24分)
Spark是Hadoop的子專案, 環境中將Spark安裝到基于Linux的系統中,
相關配置變數如下:
- JAVA_HOME:Java安裝目錄
- SCALA_HOME:Scala安裝目錄
- HADOOP_HOME:Hadoop安裝目錄
- HADOOP_CONF_DIR:Hadoop集群的組態檔的目錄
- SPARK_MASTER_IP:Spark集群的Master節點的ip地址
- SPARK_WORKER_MEMORY:每個worker節點能夠最大分配給exectors的記憶體大小
考核條件如下:
1. 將Spark安裝包解壓到指定路徑/usr/spark/spark-2.4.3-bin-hadoop2.7(安裝包存放于/usr/package277/)(3分)
操作環境: master、slave1、slave2
mkdir /usr/spark
tar -zxvf /usr/package277/spark-2.3.4-bin-hadoop2.7.tgz -C /usr/spark/2. 檔案/etc/profile中配置環境變數SPARK_HOME,將Spark安裝路徑中的bin目錄加入PATH系統變數,注意生效變數(3分)
操作環境: master、slave1、slave2
vim /etc/profile
加入:
#spark
export SPARK_HOME=/usr/spark/spark-2.3.4-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile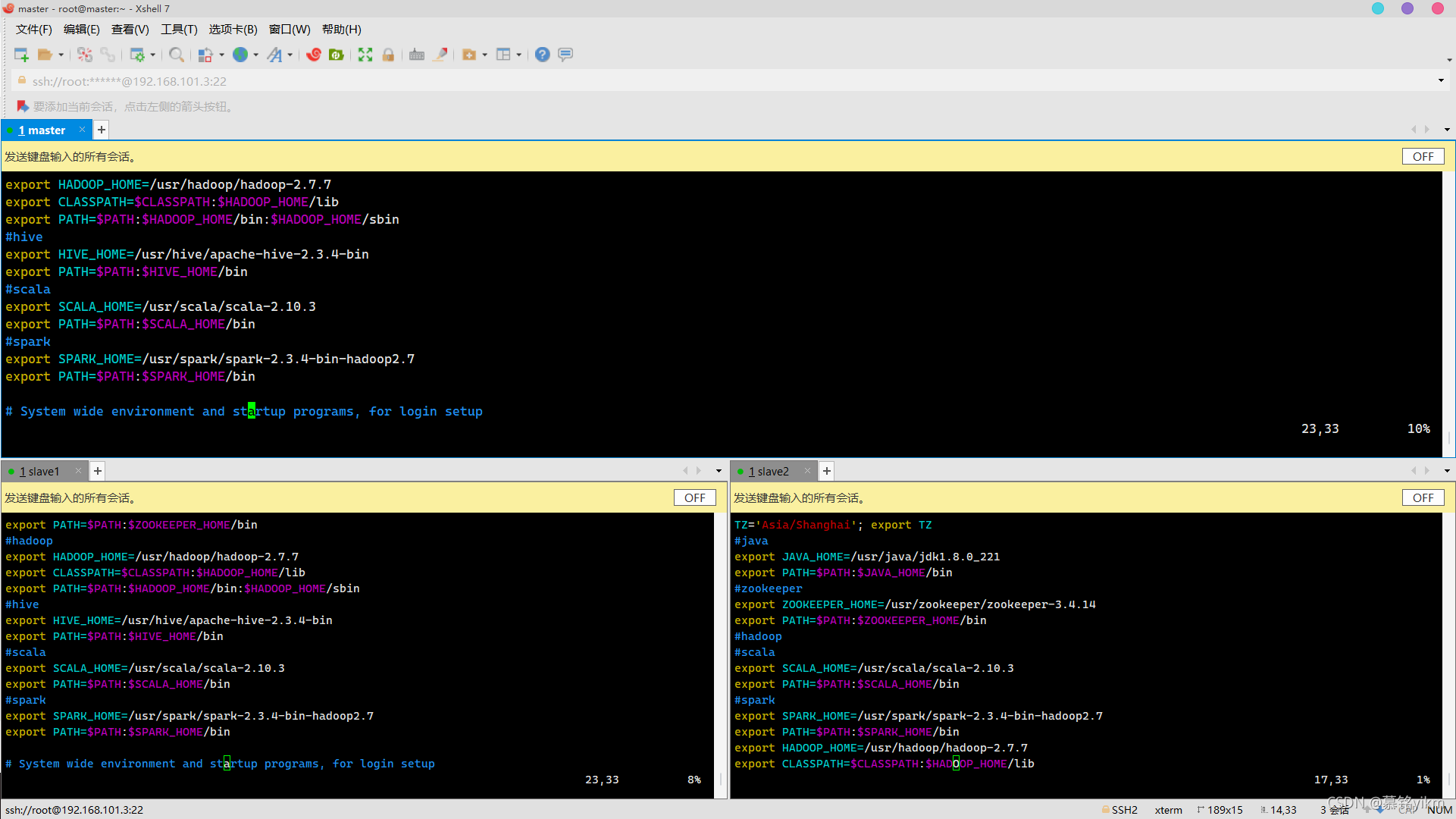 3. 修改組態檔spark-env.sh,設定主機節點為master(3分)
3. 修改組態檔spark-env.sh,設定主機節點為master(3分)
操作環境: master、slave1、slave2
4. 修改組態檔spark-env.sh,設定scala安裝路徑、java安裝路徑(3分)
操作環境: master、slave1、slave2
5. 修改組態檔spark-env.sh,設定節點記憶體為8g( 3分)
操作環境: master、slave1、slave2
6. 修改組態檔spark-env.sh,設定hadoop安裝目錄、hadoop集群的組態檔的目錄(3分)
操作環境: master、slave1、slave2
3,4,5,6:
cd /usr/spark/spark-2.3.4-bin-hadoop2.7/conf
mv spark-env.sh.template spark-env.sh
echo "export SPARK_MASTER_IP=master
export SCALA_HOME=/usr/scala/scala-2.10.3
export SPARK_WORKER_MEMORY=8g
export JAVA_HOME=/usr/java/jdk1.8.0_221
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.7/etc/hadoop" >> spark-env.sh7. 修改slaves檔案,添加spark從節點slave1、slave2(3分)
操作環境: master、slave1、slave2
mv slaves.template slaves
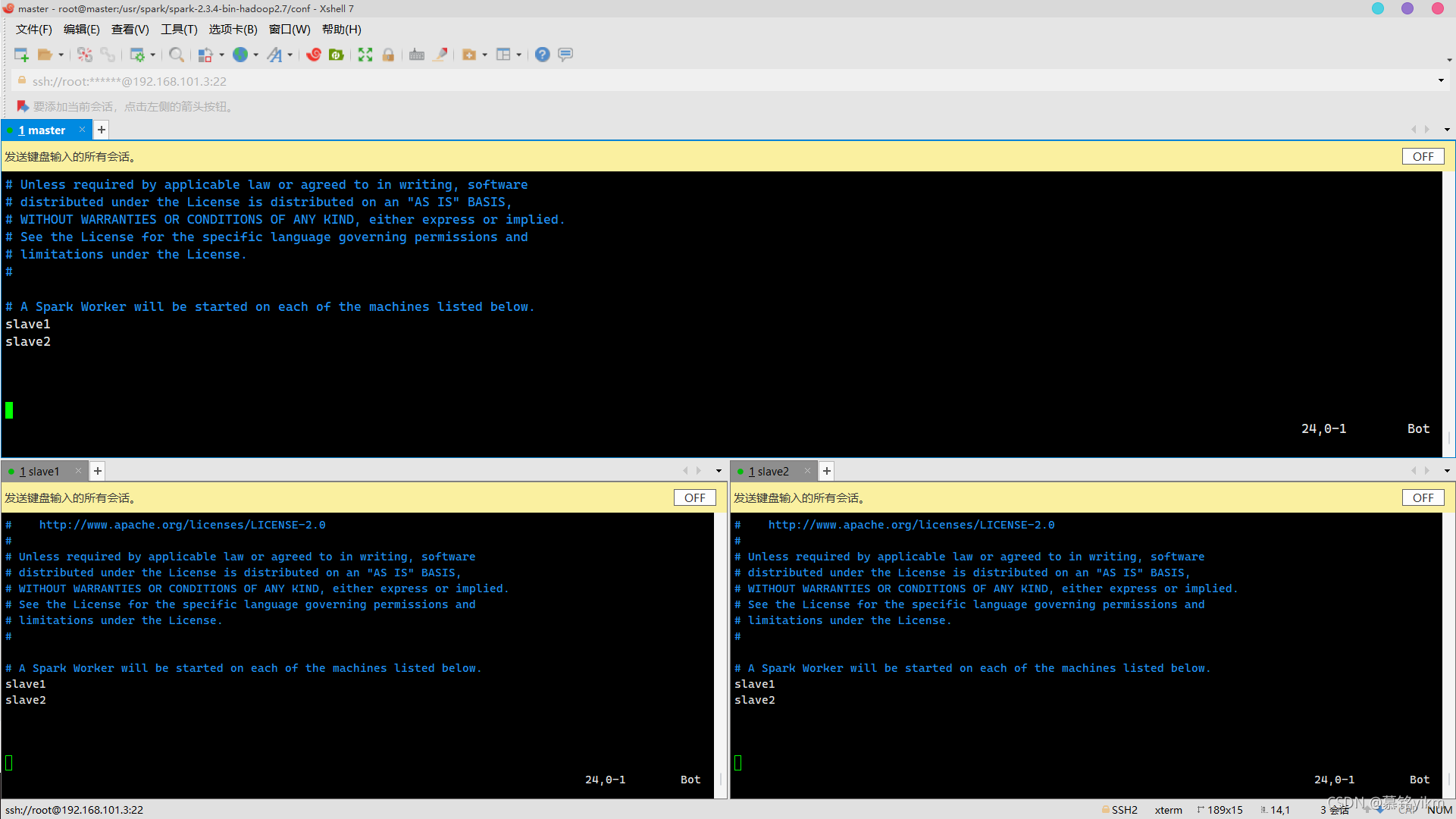
vim slaves修改localhost為slave1,slave2
8. 開啟集群,查看各節點行程(主節點行程為Master,子節點行程為Worker)(3分)
操作環境: master、slave1、slave2
在master上:
cd /usr/spark/spark-2.3.4-bin-hadoop2.7/
sbin/start-all.sh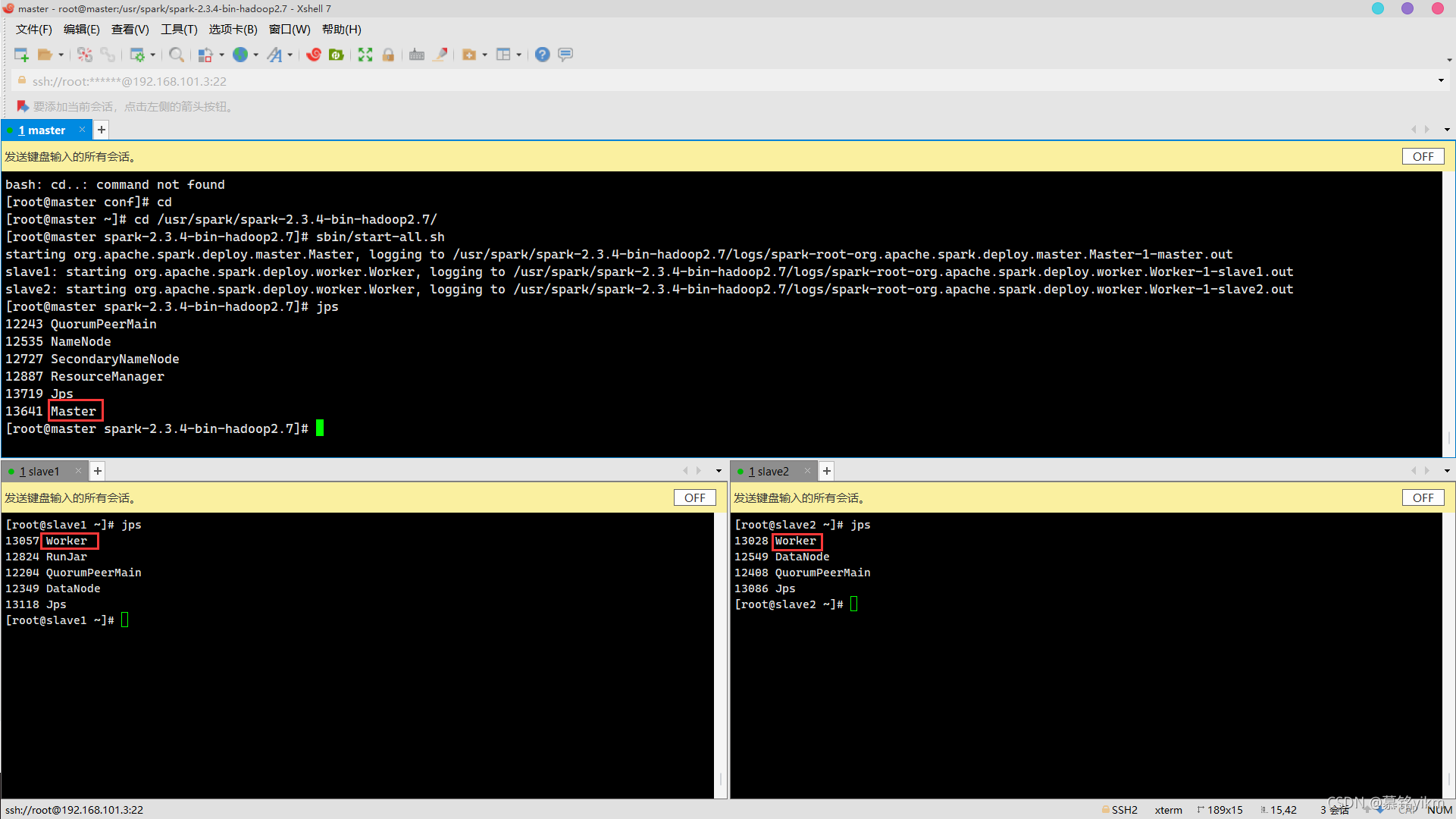
完成!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352159.html
標籤:其他
上一篇:安裝Hadoop