前言
利用Python實作抓取知乎熱點話題,廢話不多說,
讓我們愉快地開始吧~
開發工具
Python版本: 3.6.4
相關模塊:
requests模塊;
re模塊;
pandas模塊;
lxml模塊;
random模塊;
以及一些Python自帶的模塊,
環境搭建
安裝Python并添加到環境變數,pip安裝需要的相關模塊即可,
思路分析
本文以爬取知乎熱點話題《如何看待網傳騰訊實習生向騰訊高層提出建議頒布拒絕陪酒相關條令?》為例
目標網址
https://www.zhihu.com/question/478781972
網頁分析
經過查看網頁源代碼等方式,確定該網頁回答內容為動態加載的,需要進入瀏覽器的開發者工具進行抓包,進入Noetwork→XHR,用滑鼠在網頁向下拉取,得到我們需要的資料包
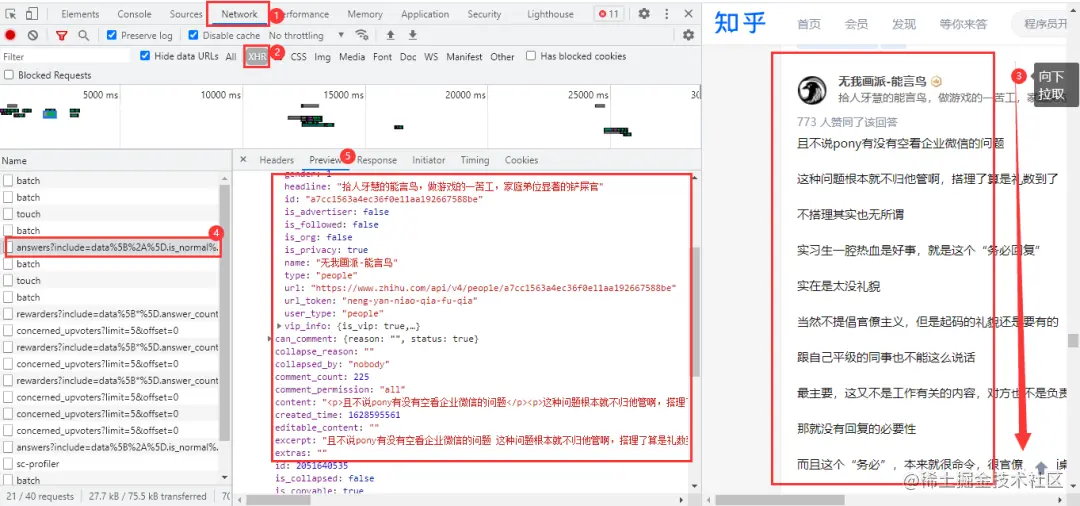
得到的準確的URL
https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=0&platform=desktop&sort_by=default
https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=5&platform=desktop&sort_by=default
URL有很多不必要的引數,大家可以在瀏覽器中自行刪減,兩條URL的區別在于后面的offset引數,首條URL的offset引數為0,第二條為5,offset是以公差為5遞增;網頁資料格式為json格式,
代碼實作
import requests\
import pandas as pd\
import re\
import time\
import random\
\
df = pd.DataFrame()\
headers = {\
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'\
}\
for page in range(0, 1360, 5):\
url = f'https://www.zhihu.com/api/v4/questions/478781972/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset={page}&platform=desktop&sort_by=default'\
response = requests.get(url=url, headers=headers).json()\
data = response['data']\
for list_ in data:\
name = list_['author']['name'] # 知乎作者\
id_ = list_['author']['id'] # 作者id\
created_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(list_['created_time'] )) # 回答時間\
voteup_count = list_['voteup_count'] # 贊同數\
comment_count = list_['comment_count'] # 底下評論數\
content = list_['content'] # 回答內容\
content = ''.join(re.findall("[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]", content)) # 正則運算式提取\
print(name, id_, created_time, comment_count, content, sep='|')\
dataFrame = pd.DataFrame(\
{'知乎作者': [name], '作者id': [id_], '回答時間': [created_time], '贊同數': [voteup_count], '底下評論數': [comment_count],\
'回答內容': [content]})\
df = pd.concat([df, dataFrame])\
time.sleep(random.uniform(2, 3))\
df.to_csv('知憾訓答.csv', encoding='utf-8', index=False)\
print(df.shape)
效果展示
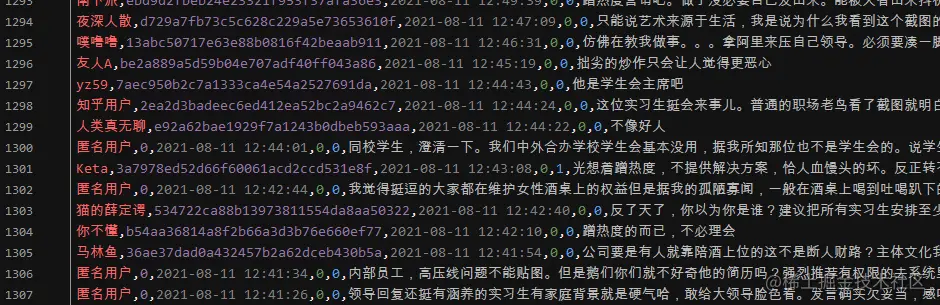
————————————————————————————————————————————
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352194.html
標籤:其他