Do Deep Neural Networks Learn Facial Action Units When Doing Expression Recognition?閱讀筆記
- 前言
- Abstract
- Introduction
- Related Work
- Our Approach
- Network Architecture
- Network Training
- Experiments and Analysis
- Performance on Toronto Face Database (TFD)
- Performance on the Extended Cohn-Kanade Dataset (CK+)
- Visualization of higher-level neurons
- Finding Correspondences Between Filter Activations and the Ground Truth Facial Action Units (FAUs)
- Conclusions
前言
這是第一次寫博客(本人還只是個入門小白),主要是自己學習看文章時做的小筆記吧,方便以后自己回顧和整理,如有理解錯誤的地方,還請指出,文章有少量內容有所省略,如果想要深入學習本篇論文,最好的方法還是去閱讀原文,本文只是一個簡單的輔助,
簡單說一些這篇論文的學習重點:理解CNN在做表情識別時究竟提取了什么樣的高級特征,學會可視化的理論及其方法,
這兒給出論文地址:Do Deep Neural Networks Learn Facial Action Units When Doing Expression Recognition?
Abstract
盡管近年來,卷積神經網路(CNN)被選為基于外觀的分類器,但研究卷積神經網路(cnn)能在多大程度上提高公認的表情識別資料集上的性能的作業相對較少,更重要的是,研究卷積神經網路實際上學習了什么, 在這項作業中,我們不僅展示了CNN可以實作較強的性能,而且我們還引入了一種方法來破譯哪些面部區域影響了CNN的預測, 首先,我們在面部表情資料上訓練一個zero-bias CNN,據我們所知,在兩個表情識別資料集上取得了最先進的性能: 擴展的Cohn-Kanade (CK+)資料集 和 多倫多面部資料集(TFD) ,然后,我們通過 可視化空間模式 來定性分析網路,大致操作就是最大限度地激發了卷積層中的不同神經元,并通過可視化結果展示了它們與 面部動作單元(FAUs) 的相似性,最后,我們使用CK+資料集提供的FAU labels來驗證我們在濾波器可視化中觀察到的FAU確實與受試者的面部運動一致,
總結來說,該文章證明了CNN可用于表情識別的任務,并且可以取得不錯的結果,同時,對深層的卷積特征進行可視化可以發現網路提取到的高級特征與FAU有著對應關系,
Introduction
面部表情為人類向他人傳達自己的情緒狀態提供了一種自然而簡潔的方式,因此,設計準確的面部表情識別演算法對人工智能互動計算機系統的發展至關重要,在這一領域的廣泛研究發現,只有一小部磁區域會隨著人類表情的變化而變化,這些區域位于受試者的眼睛、鼻子和嘴巴周圍,在1中,Paul Ekman提出了 面部動作編碼系統(FACS) ,該系統列舉了這些區域,并描述了每個面部表情如何被描述為多個動作單元(AUs)的組合,每個動作單元對應于面部的特定肌肉群,然而,事實證明,讓電腦準確地學習面部傳達情感的部位并非易事,
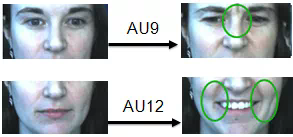
面部運動編碼系統 (FACS,Facial Action Coding System)從人臉解剖學的角度,定義了44個面部動作單元(Action Unit,簡稱AU)用于描述人臉區域區域的肌肉運動,如下圖所示,AU9表示“皺鼻”,AU12表示“嘴角拉伸”,面部動作單元能夠客觀、精確、細粒度地描述人臉表情,各種動作單元之間可以自由組合,對應不同的表情,如“AU4(降低眉毛)+AU5(上眼瞼上升)+AU24(嘴唇相互按壓)”這一組合對應“憤怒”這一情緒狀態,
以往的面部表情識別作業可以分為兩大類: 基于AU/基于規則的方法 和 基于外觀的方法 ,基于AU的方法將明確檢測個體AU的存在,然后根據《Emotional facial action coding system》中最初由Friesen和Ekman提出的組合對一個人的情緒進行分類,不幸的是,每個AU探測器都需要精心的手工設計來確保良好的性能,另一方面,基于外貌的方法根據人的一般面部形狀和紋理來模擬人的表情,
在過去的幾年中,卷積神經網路(CNNs)作為一種基于外觀的分類器的興起,極大地促進了計算機視覺中許多成熟的問題的發展,像物體識別、物體檢測和人臉識別這樣的任務在幾個公認的資料集測驗中都有了巨大的性能提升,不幸的是,其他任務,如面部表情識別,并沒有獲得同樣程度的性能提升,關于CNN能在公認的表情識別資料庫上提供多大的幫助,目前還沒有做什么作業,
在本文中,我們尋求以下問題的答案: CNN能否提高表情識別資料集/基線的性能,以及它們學習了什么? 我們建議在已建立的面部表情資料集上訓練CNN,然后通過可視化網路中的各個過濾器來分析它們學習到的內容,在這項作業中,我們應用了Zeiler和Fergus和Springenberg等人提出的 可視化技術 ,其中網路中的單個神經元被激發,并使用一個 反卷積網路 在像素空間中顯示它們相應的空間模式,當我們將這些有區別的空間模式可視化時,我們發現許多濾波器是由面部對應的面部動作單元(FAUs)激發的,圖1顯示了這些空間模式的子集,

圖1 在擴展Cohn-Kanade (CK+)資料集上訓練的網路的第三個卷積層中激活五個選定濾波器的面部區域的可視化,每一行對應于conv3層中的一個濾波器,我們顯示前5張影像的空間模式,
因此,本文的主要貢獻如下:(即本文重點研究內容,以下內容都是圍繞這兩點)
- 我們發現CNN經過表情識別訓練后的識別任務學習特征與Ekman提出的FAUs強烈對應,我們首先通過可視化在我們的網路的卷積層中最大程度激發不同濾波器的空間模式來證明這一結果,然后使用ground truth FAU標簽來驗證在過濾器可視化中觀察到的FAU與受試者的面部運動一致,
- 我們還表明,我們的CNN模型基于最初提出的作業,據我們所知,可以在擴展的Cohn-Kanade (CK+)資料集和Toronto Face dataset (TFD)上實作最先進的性能,
Related Work
在大多數面部表情識別系統中,主機器與傳統的機器學習管道非常匹配,更具體地說,人臉影像被傳遞給分類器,該分類器試圖將其分類為幾個(通常為7)表情類之一:憤怒,2、厭惡,3、恐懼,4、中性的,5、快樂,6、難過的時候,和7、驚喜,在大多數情況下,在傳遞給分類器之前,人臉影像被預處理并交給特征提取器,直到最近,大多數基于外觀的表情識別技術都依賴于手工特征,特別是Gabor小波、Haar特征和LBP特征,以使不同表情類的表示更具甄別性,
一段時間以來,基于手工制作特征的系統能夠在公認的表情識別資料集上取得令人印象深刻的結果,如日本女性面部表情(JAFFE)資料庫,擴展的Cohn-Kanade (CK+)資料集和Multi-PIE資料集,然而,最近深度神經網路的成功使得許多研究人員開始探索從資料中學習的特征表示,毫不奇怪,幾乎所有的方法都使用了某種形式的無監督的前訓練/學習來初始化模型,我們假設,這可能是因為標簽資料的缺乏,使作者無法訓練一個沒有嚴重過擬合的完全監督模型,
在《Facial expression recognition via a boosted deep belief network》中,作者訓練了一個多層增強深度置信網路(BDBN),并在CK+和JAFFE資料集上取得了最先進的精度,同時,在《Disentangling factors of variation for facial expression recognition》中,作者使用卷積收縮自動編碼器(CAE)作為他們的底層無監督模型,然后,他們執行了一種被稱為收縮判別分析(CDA)的半監督編碼功能,以從非監督表示中分離出判別運算式特征,
一些基于無監督深度學習的研究也試圖分析FAU和學習特征表示之間的關系,在[15,16]中,作者學習了一種以K-means為低級特征的基于patch的濾波器組,然后利用這些特征選擇對應于特定FAU接受域的接受域,并將其傳遞給多層受限玻爾茲曼機器(RBMs)進行分類,使用影像特征和表達標簽之間的互資訊準則選擇FAU接受域,Susskind等人的早期研究表明,第一層的特征是經過訓練生成面部表情影像的深度信念網路,似乎學習了對臉部部分敏感的濾波器,我們進行了類似的分析,除了我們使用CNN作為我們的基礎模型,我們可視化的空間模式,刺激網路中的高級神經元,
(中間有省略)
相比之下,我們的作業是對單一影像的表情識別,并將重點分析網路學習到的特征,因此,我們不僅將證明CNN對現有表情分類基線的有效性,而且我們還將定性地表明,該網路能夠學習人臉影像中對應于面部動作單元(FAUs)的空間模式,(此段是本文作者所做研究重點,且與上述其他相關研究有所不同)
Our Approach
Network Architecture
在本文的所有實驗中,我們使用了一個經典的前饋卷積神經網路,我們使用的網路,如圖2所示,由3個卷積層組成,分別帶有64、128和256個濾波器,濾波器大小為5x5,然后是ReLU(整流線性單元)激活函式,最大池化層放置在前兩個卷積層之后,而 象限池化層2 應用在第三個卷積層之后,象限池化層之后是一個包含300個隱藏單元的全連接層,最后是一個用于分類的softmax層,softmax層包含6-8個輸出,對應于訓練集中表情的數量,
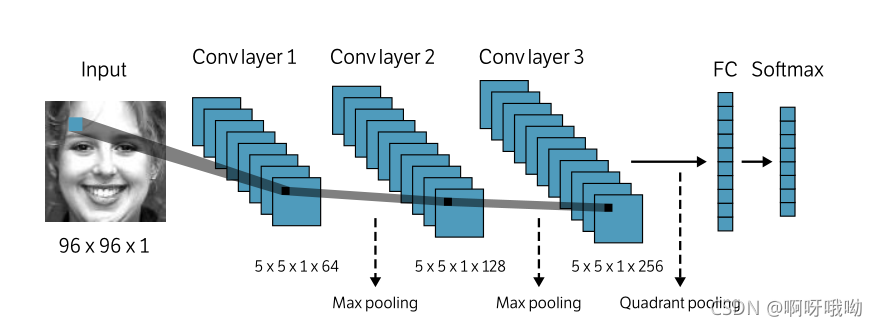
圖2 網路架構——我們的網路由3個卷積層組成,分別包含64、128和256個濾波器,每個濾波器的尺寸為5x5,然后是ReLU(整流線性單元)激活函式,我們在前兩個卷積層之后添加2x2最大池化層,在第三個卷積層之后添加象限池化層,3個卷積層之后是一個包含300個隱藏單位的全連接層和一個softmax層,
象限池化層——其實是一種非常簡單的池化形式,具體來說,我們將特征圖劃分為四個大小相等的象限,并計算它們在每個象限中的總和,這將產生每個象限的簡化(K維)表示,用于分類的共有4K個特征,
Network Training
在訓練我們的網路時,我們從頭開始使用隨機梯度下降進行訓練, batch size為64 , momentum設定為0.9 , weight decay為1e-5 ,我們使用 0.01的恒定學習率,并且不使用任何形式的退火,每個層的引數都是隨機初始化的,通過繪制一個具有零均值和標準差的高斯分布( σ = k N F A N ? I N \sigma = \dfrac{k}{N_{FAN-IN}} σ=NFAN?IN?k?),其中 N F A N ? I N N_{FAN-IN} NFAN?IN? 是每層的輸入連接數, k k k 從范圍 [ 0.2 , 1.2 ] [0.2,1.2] [0.2,1.2] 上均勻取值,
我們還使用 dropout 和各種形式的 資料增強 來規范我們的網路和對抗過擬合,我們將dropout應用到全連接層,其概率為 0.5 (即每個神經元的輸出設定為0,其概率為0.5) ,對于資料增強,我們對每個輸入影像進行 隨機變換,其中包括:平移、水平翻轉、旋轉、縮放和像素強度增強 ,
Experiments and Analysis
我們在實驗中使用了兩個面部表情資料集:擴展的Cohn-Kanade資料庫(CK+) 和 多倫多面部資料集(TFD) ,CK+資料庫包含327個影像序列,每個影像序列被分配到7個表情標簽中的一個:憤怒、輕蔑、厭惡、恐懼、高興、悲傷和驚訝,為了公平比較,我們遵循前人的協議,將每個序列的第一幀作為中性幀,加上最后三幀表情幀,形成我們的資料集,這導致總共有1308個影像和8個類別(還有一個類別應為中性),然后,我們按照特定的方式將所有幀分割成10個獨立的子集,并進行 10折交叉驗證 ,
十折交叉驗證,英文名叫做10-fold cross-validation,用來測驗演算法準確性,是常用的測驗方法,將資料集分成十份,輪流將其中9份作為訓練資料,1份作為測驗資料,進行試驗,
每次試驗都會得出相應的正確率(或差錯率),10次的結果的正確率(或差錯率)的平均值作為對演算法精度的估計,一般還需要進行多次10折交叉驗證(例如10次10折交叉驗證),再求其均值,作為對演算法準確性的估計,
TFD是多個面部表情資料集的融合,它包含4178張圖片,標注了7種表情標簽中的一種:憤怒、厭惡、恐懼、快樂、中性、悲傷和驚訝,將標記好的樣本分成5折,每折包含一個訓練、驗證和測驗集,我們只使用每折的訓練集訓練所有的模型,并對每折的測驗集進行評估,并對結果進行平均,
在這兩個資料集中,影像是 灰度 的,大小為 96x96像素 ,在TFD資料集中,人臉已經被檢測并歸一化,因此所有受試者的眼睛之間的距離相同,具有相同的垂直坐標,同時,對于CK+資料集,我們只需檢測640x480影像中的人臉,并將其調整為96x96,我們使用的唯一其他預處理是 patch-
wise mean subtraction和scaling to unit variance,
Performance on Toronto Face Database (TFD)
首先,我們通過評估CNN在TFD資料集上的性能來分析CNN的識別能力,圖3顯示了從沒有其他正則化的隨機初始化以及具有dropout (D)、data augmented (a)或兩者兼有(AD)的CNN訓練zero-bias CNN時獲得的識別精度,我們還包括以前方法的識別精度,從圖3的結果中,有兩個主要的觀察結果:
- 不出意料,正則化顯著提高性能
- 資料增強比常規CNN提高性能(10.0%vs.3.5%)
此外,當同時使用dropout和資料增強時,我們的模型在TFD上的性能能夠超過以前的最先進的性能4.8%,
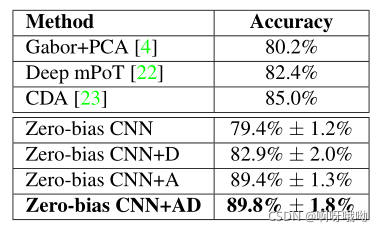
圖3 多倫多人臉資料集(TFD)的識別精度- 7 classes- A:資料增強,D: Dropout
Performance on the Extended Cohn-Kanade Dataset (CK+)
現在我們在CK+資料集上展示我們的結果,CK+資料集通常包含8個標簽(憤怒、輕蔑、厭惡、恐懼、快樂、中性、悲傷和驚訝),然而,許多研究忽略了被標記為中性或輕蔑的樣本,只對六種基本情緒進行評估,因此,為了確保公平比較,我們訓練了兩個單獨的模型,我們在圖4中給出了8個類別模型結果,在圖5中給出了6個類別模型結果,對于八類模型,我們進行了與TFD相同的研究,我們觀察到相當相似的結果,再一次,正則化在獲得良好性能方面發揮了重要作用,資料增強可以顯著提高性能(14.5%),如果結合dropout,則可提高14.6%,在八類和六類模型中,據我們所知,我們達到了CK+資料集的最先進的精度,
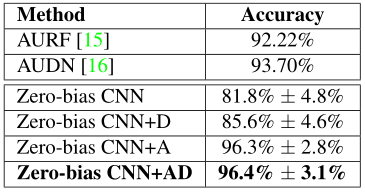
圖4 擴展Cohn-Kanade (CK+)資料集的識別精度- 8 classes- A:資料增強,D: Dropout
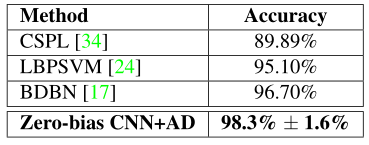
圖5 擴展Cohn-Kanade (CK+)資料集的識別精度- 6 classes- A:資料增強,D: Dropout
Visualization of higher-level neurons
現在,有了具有高識別度的模型,我們將分析神經網路在進行分類時識別出識別能力最強的面部區域,為此,我們采用了Zeiler和Fergus在3中提出的 可視化技術 ,
對于每個資料集,我們考慮第三卷積層, 對于每個濾波器,我們選擇分割的訓練集中產生最強的回應值的 N N N 張影像 ,然后, 我們將最強的神經元設定為原高激活值,將所有其他激活設定為零,并使用 反卷積網路 在像素空間中重建該區域 ,在我們的實驗中,我們選擇了 N = 10 N=10 N=10 張訓練影像,
這兒簡單說一下可視化的大致程序,我們影像通過多個卷積層提取到了高級特征,然后我們在特征圖中選擇激活值最高的一個通道,其他通道全部置零,然后激活值最高的通道的最高激活值區域保留,其余同樣置零,將新的特征圖送入反卷積網路中,便可以得到重新構建的可視化結果,借此便可以觀察理解每層的CNN究竟學習到了什么特征,
反卷積網路可以說是卷積網路的“逆程序”,但兩者并不是完全“可逆的”關系,反卷積網路大致要經過:反池化——激活——反卷積這樣一個程序,
我們使用Springenberg等人提出的一種名為“Guided Backpropagation”的技術來進一步完善我們的重建,“Guided backpropagation”的目的是改善重構的空間模式,不僅依賴于反卷積程序中上層信號給出的屏蔽激活,而且還結合了在前向傳播程序中那些激活被抑制的資訊,因此,每一層在反卷積階段的輸出被屏蔽兩次:
- 被反卷積層的ReLU屏蔽一次
- 被該層的卷積層的ReLU在前向傳播中生成的屏蔽再次屏蔽一次
首先,我們將分析在Toronto Face Dataset (TFD)中發現的模式,在圖6中,我們在第三卷積層中選擇256個濾波器中的10個,對于每個濾波器,我們給出訓練集中前10名影像的空間模式,從這些影像中,讀者可以看到,有幾個濾波器似乎對與幾個面部動作單元對齊的區域非常敏感,例如:AU12:唇角拉緊器(第1行),AU4:下眉器(第4行),AU15:唇角壓下器(第9行),

圖6 空間模式的可視化,激活我們在多倫多人臉資料集(TFD)上訓練的網路的conv3層中選定的10個濾波器,每一行對應于conv3層中的一個過濾器,我們展示了獲得最大幅值回應的前10張圖片,注意,空間模式似乎與一些面部動作單元相對應,
接下來,我們顯示在CK+資料集中發現的模式,在圖7中,我們再次在第三卷積層中選擇256個濾波器中的10個,對于每個濾波器,我們給出訓練集中排名前10的影像的空間模式,讀者會注意到,CK+區分空間模式的定義非常清晰,并與面部動作單元(如AU12:唇角拉起器(第2、6和9行),AU9:鼻子皺起器(第3行)和AU27:嘴伸展(第8行)非常一致,

圖7 在Cohn-Kanade (CK+)資料集上訓練的我們的網路的conv3層中激活10個選定濾波器的空間模式可視化,每一行對應于conv3層中的一個濾波器,再一次,我們展示了獲得最大幅值回應的前10張圖片,注意,這些空間模式似乎與一些面部動作單元有非常清晰的對應關系,
Finding Correspondences Between Filter Activations and the Ground Truth Facial Action Units (FAUs)
除了分類標簽(憤怒,厭惡等),CK+資料集還包含標簽表示每個影像序列中存在哪些FAU,利用這些標簽,我們現在提出了一個初步實驗,以驗證CNN學習到的濾波器激活/空間模式確實與影像中受試者顯示的真實FAU匹配,我們的實驗旨在回答以下問題:在一個包含FAUj樣本集中,對于一個特定的濾波器,樣品的最強烈激活值與不含FAUj的樣本集中的最強烈激活值具有最大的不同,那個FAU是否與最大激發濾波器 i i i 的視覺空間模式準確對應?
給定 M M M 幅影像(X)及其對應的FAU標簽(Y)的訓練集,F?i(X) 為濾波器在 ? ? ? 層對樣本 X X X 的激活,由于我們正在研究網路中的第三層卷積層,因此我們設定 ? = 3 ?= 3 ?=3,然后,對于圖7中顯示的10個過濾器,我們分別執行以下操作:
- 我們考慮一個特定的FAUj,并將包含FAUj的樣本x放在集合S中,其中: S = { x m ∣ j ∈ y m } , ? m ∈ { 1 , ? ? , M } ? . \ S= \{x_m\mid j\in y_m\},\forall m\in\{1,\cdots,M\}\,. S={xm?∣j∈ym?},?m∈{1,?,M}.
- 然后,我們建立一個含有FAUj的樣本集的最大激活值柱狀圖: Q i j ( x ) = P ( F 3 i ( x ) ∣ S ) , ? ( x , y ) ∈ ( X , Y ) ? . \ Q_{ij}(x)=P(F_{3i}(x)\mid S),\forall (x,y)\in(X,Y) \,. Qij?(x)=P(F3i?(x)∣S),?(x,y)∈(X,Y).
- 然后,類似地,我們在不包含FAUj的樣本集的最大激活上構建一個分布: R i j ( x ) = P ( F 3 i ( x ) ∣ S c ) , ? ( x , y ) ∈ ( X , Y ) ? . \ R_{ij}(x)=P(F_{3i}(x)\mid S^c),\forall (x,y)\in(X,Y) \,. Rij?(x)=P(F3i?(x)∣Sc),?(x,y)∈(X,Y).
- 我們計算 Q i j ( x ) Q_{ij}(x) Qij?(x)和 R i j ( x ) R_{ij}(x) Rij?(x)之間的KL發散度, D K L ( Q i j ∣ ∣ R i j ) D_{KL}(Q_{ij}\mid\mid R_{ij}) DKL?(Qij?∣∣Rij?),并對所有其他FAU重復這個程序,
這兒簡單描述一下是如何尋找兩者間聯系的:首先我們正對一種特定的FAUj,然后把整個訓練集 X X X 分為兩部分,一部分是包含FAUj標簽的集合 S S S,另一部分是不包含FAUj標簽的集合 S c S^c Sc ,我們分別把兩個集合送入網路,那么再爭對第三層中某個濾波器 i i i ,我們分別可以得到 x x x 個特征圖,每個樣本對應一個最大激活 F ( x ) F(x) F(x) ,那么便轉化得到兩個個最大激活值的分布,最后使用KL散度計算這兩個分布的差異性,便可以這個FAUj對于濾波器 i i i 的回應/影響是不是很大,(圖8便是最后爭對不同濾波器和不同FAU得到的結果)
圖8顯示了為圖7中顯示的10個濾波器中的每個FAU計算的KL散度的柱狀圖,對于每個濾波器,KL散度值最大的FAU用紅色表示,其對應的名稱見圖9,從這些結果中,我們可以看到,在大多數情況下,圖9中列出的FAU與圖7中顯示的面部區域相匹配,這意味著,似乎強烈影響這些特定濾波器的激活的樣本,實際上是那些擁有相應濾波器可視化顯示的FAU的樣本,因此,我們表明,當給予一個相對“松散”的監督信號(即情緒型別:憤怒、高興、悲傷等)時,神經網路中的某些神經元會隱式地學習檢測人臉影像中的特定FAU,
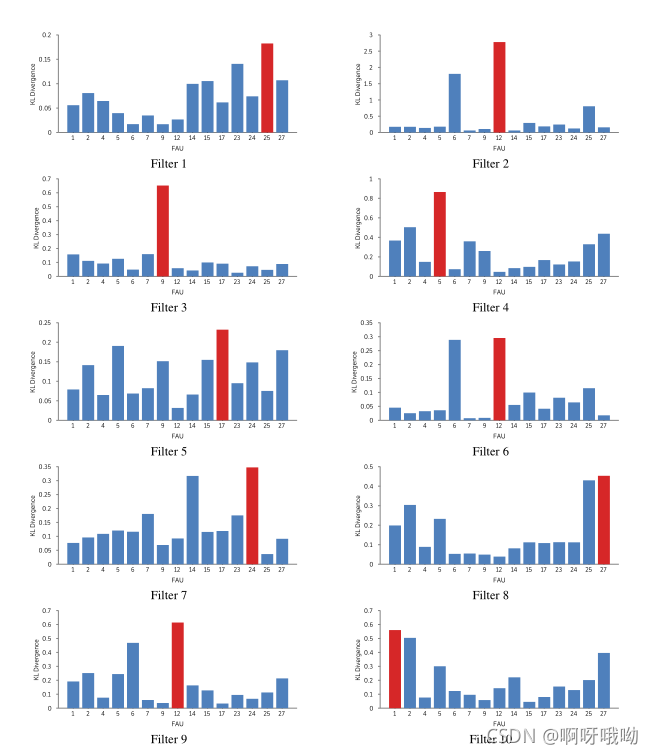
圖8 柱狀圖顯示哪些FAU導致CNN中特定濾波器的激活分布發生最強的變化,對于圖7中顯示的10個濾波器中的每一個,我們構建了包含特定FAUj的訓練樣本的激活和不包含FAUj的樣本的激活的直方圖,然后我們計算兩個分布之間的KL散度,并將它們繪制在上面的每個FAU上,KL發散度最大的FAU用紅色表示,對應的名稱見圖9,
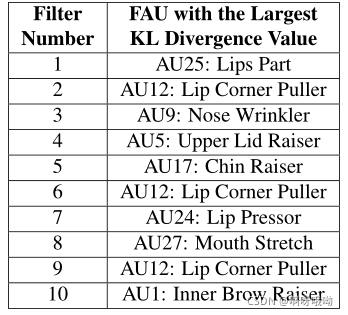
圖9 圖7所示的CK+可視化圖與激活分布的FAU對應KL發散值最高,每個濾波器計算的所有FAU的KL發散值如圖8所示,
最令人鼓舞的是,這些結果似乎證實了我們對CNN如何作為基于外觀的分類器作業的直覺,例如,濾波器2、6和9似乎對對應于FAU 12的模式非常敏感,這并不奇怪,因為FAU 12(唇角拉出器)幾乎總是與微笑聯系在一起,從圖7的可視化顯示,一個物件在微笑時經常展示他們的牙齒,一個非常獨特的外觀線索,同樣地,對于濾波器8來說,FAU 25(嘴唇部分)和FAU 27(嘴部伸展)的激活分布差異最大也就不足為奇了,因為濾波器的空間模式對應于另一個視覺上顯著的線索——驚訝臉的嘴部區域形成的“O”形,
Conclusions
在這項作業中,我們從定性和定量兩方面證明,經過訓練證明表情識別的CNN確實能夠模擬與FAUs強烈對應的高級特征,定性地說,我們通過可視化空間模式,展示了面部的哪些部分產生了最具甄別性的資訊,這些空間模式最大程度地激發了我們所學網路的卷積層中的不同濾波器,同時,定量地,我們使用CK+資料集中給出的FAU標簽,將可視化濾波器的數值激活與受試者的實際面部運動關聯起來,最后,我們演示了zero-bias CNN如何在擴展的Cohn-Kanade (CK+)資料集和多倫多人臉資料集(TFD)上實作最先進的識別精度,
面部動作編碼系統 (FACS) P . Ekman and W. V . Friesen. Facial action coding system.1977. ??
象限池化層 A. Coates, A. Y . Ng, and H. Lee. An analysis of single-layer networks in unsupervised feature learning. InInter-national conference on artificial intelligence and statistics, pages 215–223, 2011. ??
可視化技術 M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. InComputer Vision–ECCV 2014, pages 818–833. Springer, 2014. ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/352209.html
標籤:其他