系列文章目錄
近紅外光譜分析技術屬于交叉領域,需要化學、計算機科學、生物科學等多領域的合作,為此,在(北郵郵電大學楊輝華老師團隊)指導下,近期準備開源傳統的PLS,SVM,ANN,RF等經典算和SG,MSC,一階導,二階導等預處理以及GA等波長選擇演算法以及CNN、AE等最新深度學習演算法,以幫助其他專業的更容易建立具有良好預測能力和魯棒性的近紅外光譜模型,
文章目錄
- 系列文章目錄
- 前言
- 一、資料來源
- 二、代碼解讀
- 1.讀取資料并顯示光譜曲線
- 2.劃分訓練集和測驗集
- 3.PCA降維并顯示
- 4.建立校正模型(資料擬合)
- 5.模型評估(使用R2、RMSE、MSE指標)
- 6.繪制擬合差異曲線圖
- 總結
前言
NIRS是介于可見光和中紅外光之間的電磁波,其波長范圍為(1100~2526 nm, 由于近紅外光譜區與有機分子中含氫基團(OH、NH、CH、SH)振動的合頻和 各級倍頻的吸收區一致,通過掃描樣品的近紅外光譜,可以得到樣品中有機分子含氫 基團的特征資訊,常被作為獲取樣本資訊的一種有效的載體, 基于NIRS的檢測方法具有方便、高效、準確、成本低、可現場檢測、不 破壞樣品等優勢,被廣泛應用于各類檢測領域,但 近紅外光譜存在譜帶寬、重疊較嚴重、吸收信號弱、資訊決議復雜等問題,與常用的 化學分析方法不同,僅能作為一種間接測量方法,無法直接分析出被測樣本的含量或 類別,它依賴于化學計量學方法,在樣品待測驗性值與近紅外光譜資料之間建立一個 關聯模型(或稱校正模型,Calibration Model) ,再通過模型對未知樣品的近紅外光譜 進行預測來得到各性質成分的預測值,現有近紅外建模方法主要為經典建模 (預處理+波長篩選進行特征降維和突出,再通過pls、svm演算法進行建模)以及深度學習方法(端到端的建模,對預處理、波長選擇等依賴性很低)本篇主要講述基于基于PCA和PLS的近紅外光譜建模方法,
一、資料來源
使用開源玉米資料集,共80個樣本,下載地址
圖片如下:
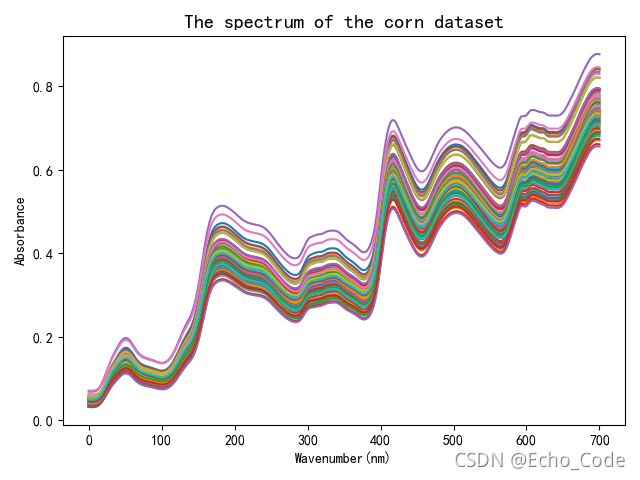
二、代碼解讀
1.讀取資料并顯示光譜曲線
#載入資料
data_path = './/data//m5.csv' #資料
label_path = './/data//label.csv' #標簽(反射率)
data = np.loadtxt(open(data_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
label = np.loadtxt(open(label_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
# 繪制原始后圖片
plt.figure(500)
x_col = np.linspace(0,len(data[0,:]),len(data[0,:])) #陣列逆序
y_col = np.transpose(data)
plt.plot(x_col, y_col)
plt.xlabel("Wavenumber(nm)")
plt.ylabel("Absorbance")
plt.title("The spectrum of the corn dataset",fontweight= "semibold",fontsize='x-large')
plt.savefig('.//Result//MSC.png')
plt.show()
2.劃分訓練集和測驗集
#隨機劃分資料集
x_data = np.array(data)
y_data = np.array(label[:,2])
test_ratio = 0.2
X_train,X_test,y_train,y_test = train_test_split(x_data,y_data,test_size=test_ratio,shuffle=True,random_state=2)
3.PCA降維并顯示
#載入資料
#PCA降維到10個維度,測驗該資料最好
pca=PCA(n_components=10) #只保留2個特征
pca.fit(X_train)
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)
# PCA降維后圖片繪制
plt.figure(100)
plt.scatter(X_train_reduction[:, 0], X_train_reduction[:, 1],marker='o')
plt.xlabel("Wavenumber(nm)")
plt.ylabel("Absorbance")
plt.title("The PCA for corn dataset",fontweight= "semibold",fontsize='large')
plt.savefig('.//Result//PCA.png')
plt.show()
PCA降維后的資料分布:
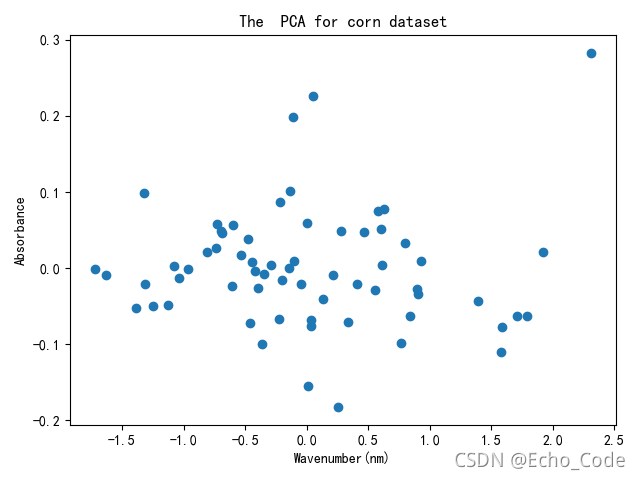
4.建立校正模型(資料擬合)
#pls預測
pls2 = PLSRegression(n_components=3)
pls2.fit(X_train_reduction, y_train)
train_pred = pls2.predict(X_train_reduction)
pred = pls2.predict(X_test_reduction)
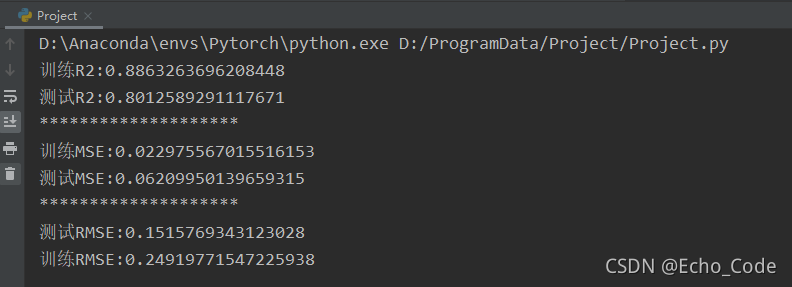
5.模型評估(使用R2、RMSE、MSE指標)
#計算R2
train_R2 = r2_score(train_pred,y_train)
R2 = r2_score(y_test,pred) #Y_true, Pred
print('訓練R2:{}'.format(train_R2))
print('測驗R2:{}'.format(R2))
#計算MSE
print('********************')
x_MSE = mean_squared_error(train_pred,y_train)
t_MSE = mean_squared_error(y_test,pred)
print('訓練MSE:{}'.format(x_MSE))
print('測驗MSE:{}'.format(t_MSE))
#計算RMSE
print('********************')
print('測驗RMSE:{}'.format(sqrt(x_MSE)))
print('訓練RMSE:{}'.format(sqrt(t_MSE)))
模型評估結果:
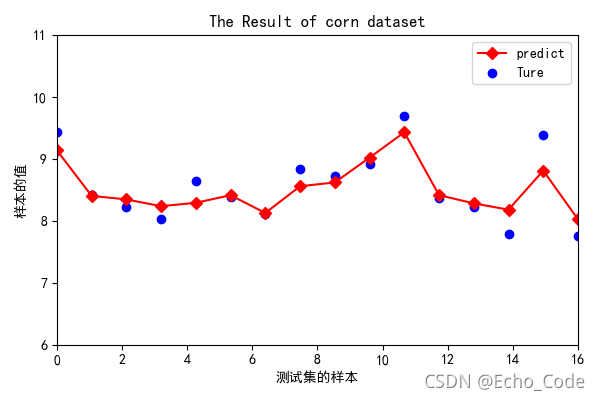
6.繪制擬合差異曲線圖
#繪制擬合圖片
plt.figure(figsize=(6,4))
x_col = np.linspace(0,16,16) #陣列逆序
# y = [0,10,20,30,40,50,60,70,80]
# x_col = X_test
y_test = np.transpose(y_test)
ax = plt.gca()
ax.set_xlim(0,16)
ax.set_ylim(6,11)
# plt.yticks(y)
plt.scatter(x_col, y_test,label='Ture', color='blue')
plt.plot(x_col, pred,label='predict', marker='D',color='red')
plt.legend(loc='best')
plt.xlabel("測驗集的樣本")
plt.ylabel("樣本的值")
plt.title("The Result of corn dataset",fontweight= "semibold",fontsize='large')
plt.savefig('.//Result//Reslut.png')
plt.show()
結果如圖:
總結
完整代碼可從獲得GitHub倉庫
代碼僅供學術使用,如需問題,聯系方式:QQ:1427950662,微信:Fu_siry
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/353246.html
標籤:AI
上一篇:【AI數學】用梯度下降演算法優化線性回歸方程(含代碼)
下一篇:pillow進行影像處理