Hadoop的檔案可以在這里下載:Apache Hadoopb
本次配置的Hadoop環境為hadoop-2.7.7 | jdk配置的環境為jdk-1.8.0_141
一、jdk環境搭配
1.搭配Hadoop環境要先搭配jdk環境,否則無法運行和查看,在/root/wenjian中rz上傳jdk檔案
[root@master wenjian]# rz 
2.將jdk檔案解壓到/root目錄下
[root@master wenjian]# tar -zxvf jdk-8u141-linux-x64.tar.gz -C /root/3.回到/root下進行修改名稱為jdk(因為名字太長了到后面記的太麻煩)
[root@master ~]# mv jdk1.8.0_141/ jdk4.進入/root下的用戶變數
[root@master ~]# vim /root/.bash_profile 5.變數jdk環境和路徑,wq保存退出
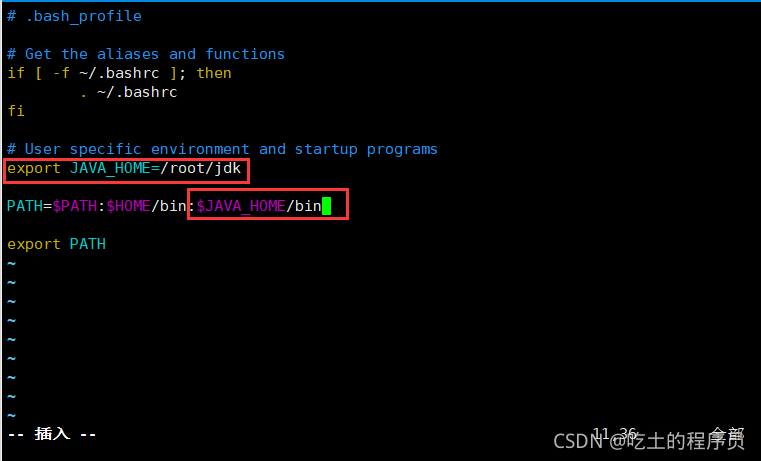
重新開啟一下用戶變數
[root@master ~]# source /root/.bash_profile 二、開始搭配Hadoop環境
1.進入/root/wenjian,解壓hadoop檔案到/root目錄下
[root@master wenjian]# tar -zxvf hadoop-2.7.7.tar.gz -C /root/2.進入/root目錄下修改hadoop名稱
[root@master ~]# mv hadoop-2.7.7/ hadoop3.進入hadoop檔案下的組態檔/etc/hadoop里面
[root@master ~]# cd hadoop/etc/hadoop/4.復制組態檔下的檔案(保留源檔案)
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml5.在core-site.xml中添加資料,將第四行的master修改為自己的主機名或者ip,wq保存退出(注意:如果主機名沒有映射的話就修改為ip,不然不成功)
[root@master hadoop]# vim core-site.xml <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/hadoop/tmp</value>
</property>
</configuration>???????6.在hdfs-site.xml中插添加資料,將第四行的master修改為自己的主機名或者ip,wq保存退出
[root@master hadoop]# vim hdfs-site.xml<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoop/tmp/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop/tmp/data</value>
</property>
</configuration>7.在yarn-site.xml中添加資料,將第四行的master修改為自己的主機名或者ip,wq保存退出
[root@master hadoop]# vim yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8.在剛剛復制過的mapred-site.xml中添加資料
[root@master hadoop]# vim mapred-site.xml修改第八行和倒數第三行的master修改為自己的主機名或ip
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>9.在hadoop-env.sh中添加上jdk路徑
[root@master hadoop]# vim hadoop-env.sh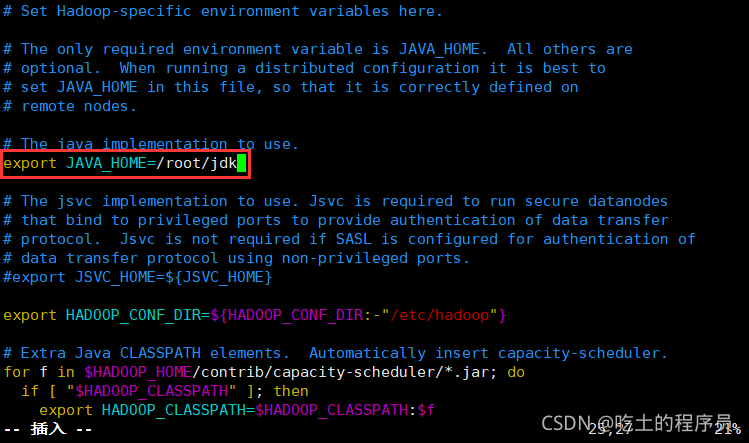
10.在用戶下添加hadoop環境變數
[root@master hadoop]# vim /root/.bash_profile 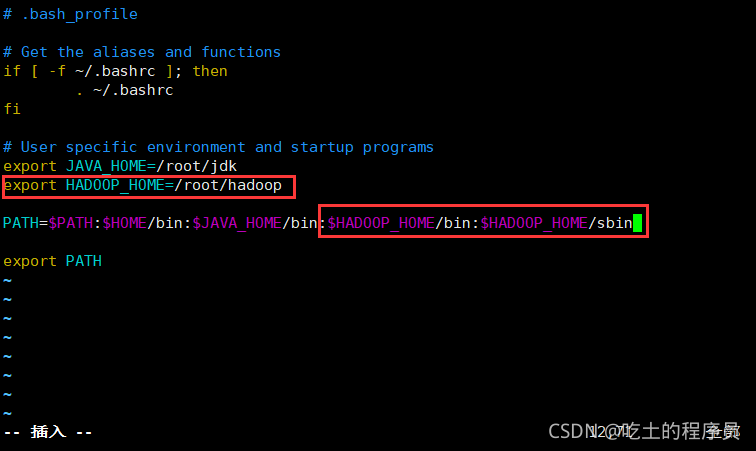 重新生成一下環境變數(重新生成在哪個目錄下都可以,因為重新生成針對的是絕對路徑)
重新生成一下環境變數(重新生成在哪個目錄下都可以,因為重新生成針對的是絕對路徑)
[root@master hadoop]# source /root/.bash_profile11.進入hadoop的bin目錄下初始化hadoop
[root@master hadoop]# cd /root/hadoop/bin/執行初始化命令(列印出日志檔案和出現兩排*號就成功初始化了)
[root@master bin]# hdfs namenode -format12.開啟hadoop服務,并通過jps查看hadoop服務(中間出現yes和no的時候一律選擇yes)
[root@master bin]# start-all.sh 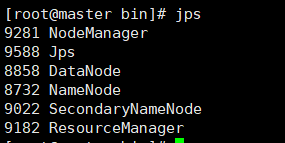
出現六個服務就代表Hadoop服務開啟成功了,如果關閉的話可以輸入stop-all.sh關閉Hadoop服務!
可以日常關注一下,會經常出一些用的上的東西,可以直接在主頁搜取!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/353309.html
標籤:其他
上一篇:linux腳本自動安裝jdk、hadoop、zookeeper,單機版
下一篇:K線型別識別—單K線之陽線