卷友們,大家好 ~ 我是 Alex ,之前已經陸續輸出了 Hadoop三大核心組件 的 架構思想和原理 和 Hive架構設計和原理 ,每篇都受到了讀者小伙伴們的一致好評 ~ 感謝大家的支持,大家可能已經猜到了,按照發展趨勢,本篇將為大家介紹 關于 Spark 的架構設計和原理,希望大家受用!

引子
MapReduce 主要使用磁盤存盤計算程序中的資料,雖然可靠性比較高,但是性能卻較差 , 此外,MapReduce 只能使用 map 和 reduce 函式進行編程,雖然能夠完成各種大資料計算,但是編程比較復雜 , 而且受 map 和 reduce 編程模型相對簡單的影響,復雜的計算必須組合多個 MapReduce job 才能完成,編程難度進一步增加!
于是,在2009年,美國加州大學伯克利分校的AMP實驗室,一個可應用于大規模資料處理的統一分析引擎——Spark 應運而生 !
Spark 初識
Spark 在 MapReduce 的基礎上進行了改進,它主要使用記憶體進行中間計算資料存盤,加快了計算執行時間,在某些情況下性能可以提升百倍 ,
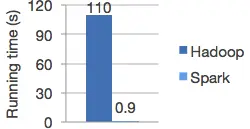
除了速度更快,Spark 和 MapReduce 相比,還有更簡單易用的編程模型 ,
Spark 的主要編程模型是 RDD,即彈性資料集 ,在 RDD 上定義了許多常見的大資料計算函式,利用這些函式可以用極少的代碼完成較為復雜的大資料計算 ,
例如我們在介紹 Hive 架構設計時談到的 WordCount 示例 , 使用 Scala 語言在 Spark 上撰寫 ,代碼只需三行 ,
val textFile = sc.textFile("hdfs://...")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
這個 demo 的代碼含義就不展開詳細介紹 ,首選,從 HDFS 讀取資料,構建一個 RDD textFile,然后在這個 RDD 上執行三個操作:一是將輸入資料的每一行文本用空格拆分單詞;二是將單詞進行轉換,比如:word ——> (word,1),生成 < Key , Value > 的結構;三是針對相同的 Key 進行統計,統計方式是對 Value 求和 ,最后,將 RDD counts 寫入 HDFS ,完成結果輸出 ,
Spark 編程模型
RDD 是 Spark 的核心概念,是彈性資料集(Resilient Distributed Datasets)的縮寫,RDD 既是 Spark 面向開發者的編程模型,又是 Spark 自身架構的核心元素,
我們先來認識一下作為 Spark 編程模型的RDD ,我們知道,大資料計算就是在大規模的資料集上進行一系列的資料計算處理,MapReduce 針對輸入資料,將計算程序分為兩個階段,一個 Map 階段,一個 Reduce 階段,可以理解成是面向程序的大資料計算,我們在用 MapReduce 編程的時候,思考的是,如何將計算邏輯用 Map 和 Reduce 兩個階段實作,map 和 reduce 函式的輸入和輸出是什么,這也是我們在學習 MapReduce 編程的時候一再強調的,
而 Spark 則直接針對資料進行編程,將大規模資料集合抽象成一個 RDD 物件,然后在這個 RDD 上進行各種計算處理,得到一個新的 RDD,繼續計算處理,直到得到最后的結果資料,所以 Spark 可以理解成是面向物件的大資料計算,我們在進行 Spark 編程的時候,思考的是一個 RDD 物件需要經過什么樣的操作,轉換成另一個 RDD 物件,思考的重心和落腳點都在 RDD 上,
所以在上面 WordCount 的代碼示例里,第 2 行代碼實際上進行了 3 次 RDD 轉換,每次轉換都得到一個新的 RDD,因為新的 RDD 可以繼續呼叫 RDD 的轉換函式,所以連續寫成一行代碼,事實上,可以分成 3 行
val rdd1 = textFile.flatMap(line => line.split(" "))
val rdd2 = rdd1.map(word => (word, 1))
val rdd3 = rdd2.reduceByKey(_ + _)
Spark 架構核心
RDD 上定義的函式分兩種,一種是轉換(transformation) 函式,這種函式的回傳值還是 RDD;另一種是 執行(action) 函式,這種函式不再回傳 RDD,
RDD 定義了很多轉換操作函式,比如有計算 map(func)、過濾 filter(func)、合并資料集 union(otherDataset)、根據 Key 聚合 reduceByKey(func, [numPartitions])、連接資料集 join(otherDataset, [numPartitions])、分組 groupByKey([numPartitions]) 等十幾個函式,
作為 Spark 架構核心元素的 RDD,跟 MapReduce 一樣,Spark 也是對大資料進行分片計算,Spark 分布式計算的資料分片、任務調度都是以 RDD 為單位展開的,每個 RDD 分片都會分配到一個執行行程去處理,
RDD 上的轉換操作又分成兩種,一種轉換操作產生的 RDD 不會出現新的分片,比如 map、filter 等,也就是說一個 RDD 資料分片,經過 map 或者 filter 轉換操作后,結果還在當前分片,就像你用 map 函式對每個資料加 1,得到的還是這樣一組資料,只是值不同,實際上,Spark 并不是按照代碼寫的操作順序去生成 RDD,比如 rdd2 = rdd1.map(func) 這樣的代碼并不會在物理上生成一個新的 RDD,物理上,Spark 只有在產生新的 RDD 分片時候,才會真的生成一個 RDD,Spark 的這種特性也被稱作 惰性計算,
另一種轉換操作產生的 RDD 則會產生新的分片,比如 reduceByKey,來自不同分片的相同 Key 必須聚合在一起進行操作,這樣就會產生新的 RDD 分片,
所以,大家只需要記住,Spark 應用程式代碼中的 RDD 和 Spark 執行程序中生成的物理 RDD 不是一一對應的,RDD 在 Spark 里面是一個非常靈活的概念,同時又非常重要,需要認真理解,
Spark 的計算階段
和 MapReduce 一樣,Spark 也遵循移動計算比移動資料更劃算 這一大資料計算基本原則,但是和 MapReduce 僵化的 Map 與 Reduce 分階段計算相比,Spark 的計算框架更加富有彈性和靈活性,進而有更好的運行性能 ,
Spark 會根據程式中的轉換函式生成計算任務執行計劃,這個執行計劃就是一個 DAG ,Spark 可以在一個作業中完成非常復雜的大資料計算 ,
所謂 DAG 也就是 有向無環圖,就是說不同階段的依賴關系是有向的,計算程序只能沿著依賴關系方向執行,被依賴的階段執行完成之前,依賴的階段不能開始執行,同時,這個依賴關系不能有環形依賴,否則就成為死回圈了,下面這張圖描述了一個典型的 Spark 運行 DAG 的不同階段,
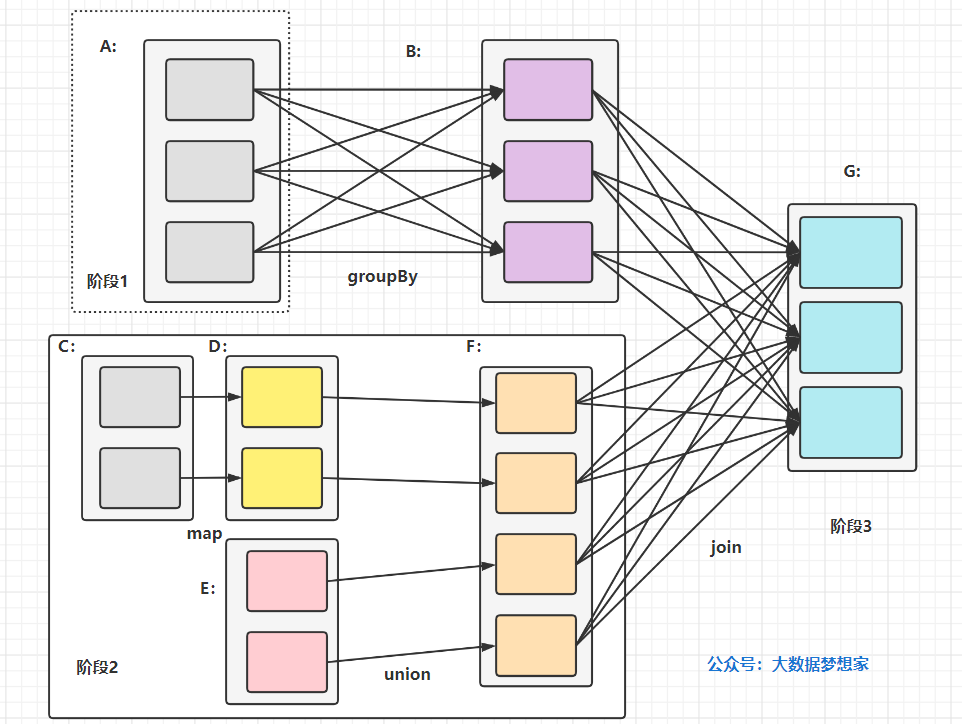
在上面的圖中, A、C、E 是從 HDFS 上加載的 RDD,A 經過 groupBy 分組統計轉換函式計算后得到的 RDD B,C 經過 map 轉換函式計算后得到 RDD D,D 和 E 經過 union 合并轉換函式計算后得到 RDD F ,B 和 F 經過 join 連接函式計算后得到最終的合并結果 RDD G ,
所以可以看到 Spark 作業調度執行的核心是 DAG,有了 DAG,整個應用就被切分成哪些階段,每個階段的依賴關系也就清楚了,之后再根據每個階段要處理的資料量生成相應的任務集合(TaskSet),每個任務都分配一個任務行程去處理,Spark 就實作了大資料的分布式計算,
具體來看的話,負責 Spark 應用 DAG 生成和管理的組件是 DAGScheduler,DAGScheduler 根據程式代碼生成 DAG,然后將程式分發到分布式計算集群,按計算階段的先后關系調度執行,
大家注意到了么,上面的例子有 4 個轉換函式,但是只有 3 個階段 ,那么 Spark 劃分計算階段的依據具體是什么呢?顯然并不是 RDD 上的每個轉換函式都會生成一個計算階段 ,
通過觀察一下上面的 DAG 圖,關于計算階段的劃分從圖上就能看出規律,當 RDD 之間的轉換連接線呈現多對多交叉連接的時候,就會產生新的階段,一個 RDD 代表一個資料集,圖中每個 RDD 里面都包含多個小塊,每個小塊代表 RDD 的一個分片,
一個資料集中的多個資料分片需要進行磁區傳輸,寫入到另一個資料集的不同分片中,這種資料磁區交叉傳輸的操作,我們在 MapReduce 的運行程序中也看到過,
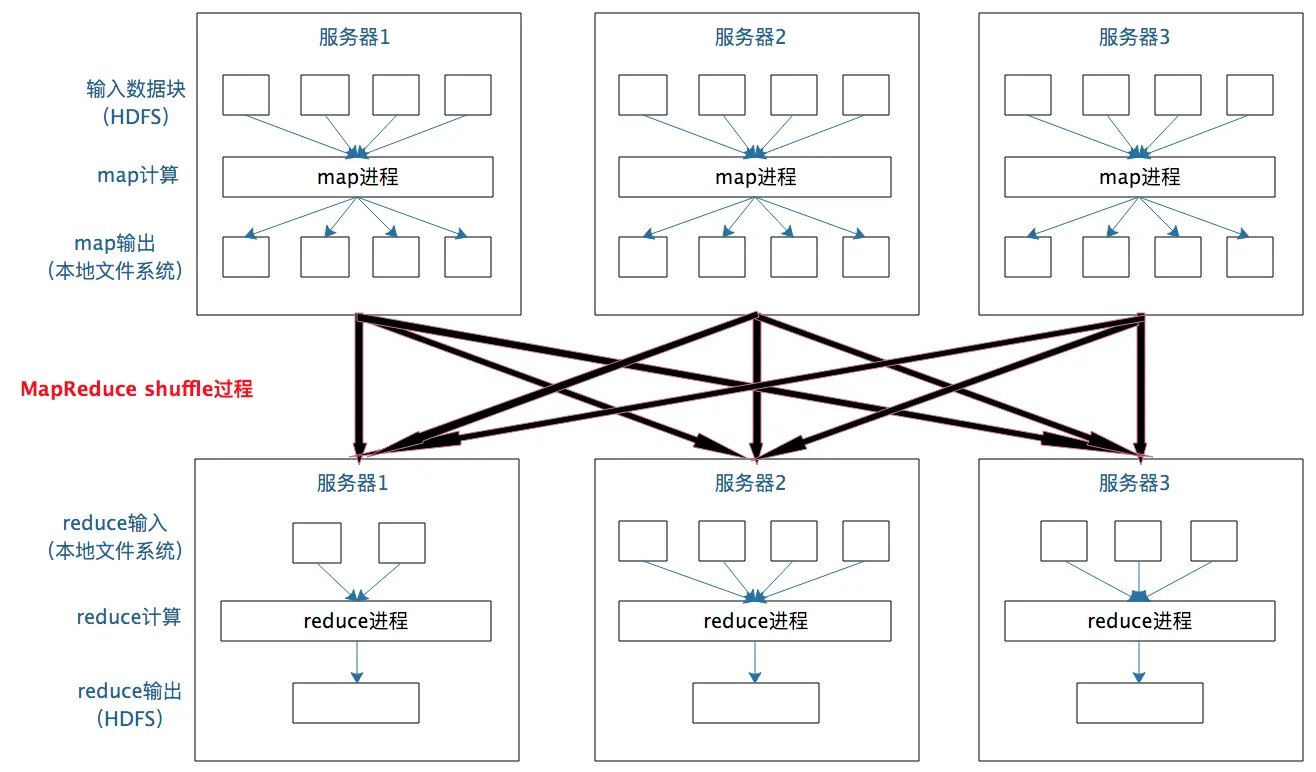
這就是 shuffle 程序,Spark 也需要通過 shuffle 將資料進行重新組合,相同 Key 的資料放在一起,進行聚合、關聯等操作,因而每次 shuffle 都產生新的計算階段,這也是為什么計算階段會有依賴關系,它需要的資料來源于前面一個或多個計算階段產生的資料,必須等待前面的階段執行完畢才能進行 shuffle,并得到資料,
所以大家需要記住,計算階段劃分的依據是 shuffle,不是轉換函式的型別 ,
思考
大家可能會想,為什么同樣經過 shuffle ,Spark 可以更高效 ?
從本質上看,Spark 可以算作是一種 MapReduce 計算模型的不同實作,Hadoop MapReduce 簡單粗暴地根據 shuffle 將大資料計算分成 Map 和 Reduce 兩個階段,然后就算完事了,而 Spark 更細膩一點,將前一個的 Reduce 和后一個的 Map 連接起來,當作一個階段持續計算,形成一個更加優雅、高效的計算模型,雖然其本質依然是 Map 和 Reduce,但是這種多個計算階段依賴執行的方案可以有效減少對 HDFS 的訪問,減少作業的調度執行次數,因此執行速度也更快,
并且和 Hadoop MapReduce 主要使用磁盤存盤 shuffle 程序中的資料不同,Spark 優先使用記憶體進行資料存盤,包括 RDD 資料,除非是記憶體不夠用了,否則是盡可能使用記憶體, 這也是 Spark 性能比 Hadoop 高的另一個原因,
Spark 執行流程
Spark 支持 Standalone、Yarn、Mesos、Kubernetes 等多種部署方案,幾種部署方案原理也都一樣,只是不同組件角色命名不同,但是核心功能和運行流程都差不多,
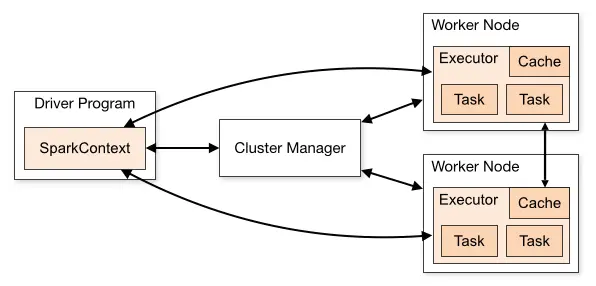
上面這張圖就是 Spark 的運行流程 ,
首先,Spark 應用程式啟動在自己的 JVM 行程里,即 Driver 行程,啟動后呼叫 SparkContext 初始化執行配置和輸入資料,SparkContext 啟動 DAGScheduler 構造執行的 DAG 圖,切分成最小的執行單位也就是計算任務,
然后 Driver 向 Cluster Manager 請求計算資源,用于 DAG 的分布式計算,Cluster Manager 收到請求以后,將 Driver 的主機地址等資訊通知給集群的所有計算節點 Worker,
Worker 收到資訊以后,根據 Driver 的主機地址,跟 Driver 通信并注冊,然后根據自己的空閑資源向 Driver 通報自己可以領用的任務數,Driver 根據 DAG 圖開始向注冊的 Worker 分配任務,
Worker 收到任務后,啟動 Executor 行程開始執行任務,Executor 先檢查自己是否有 Driver 的執行代碼,如果沒有,從 Driver 下載執行代碼,通過 Java 反射加載后開始執行,
Spark性能調優與故障處理
關于 Spark 的性能調優,就有很多可以值得探討的地方, 我們一般能快速想到的是常規的性能調優,包括最優的資源配置,RDD優化,并行度調節等等,除此之外,還有算子調優,Shuffle 調優,JVM 調優 ,而關于故障處理,我們一般討論的是解決 Spark 資料傾斜 的問題,我們一般會通過聚合原資料,過濾導致傾斜的 key,提升shuffle 操作程序中的 reduce 并行度等方式 ,因為本篇文章主要介紹架構設計和原理思想,基于篇幅限制,詳細步驟就不展示詳細描述,正好最近收集了一本 Spark性能調優與故障處理 的 pdf ,里面對于詳解的步驟均做了詳細的說明 ,
關注大資料領域優質公眾號:大資料夢想家,后臺回復 “spark” 即可免費下載 Spark性能調優與故障處理.pdf
Spark 生態
最后,我們來看看 Spark 的生態!
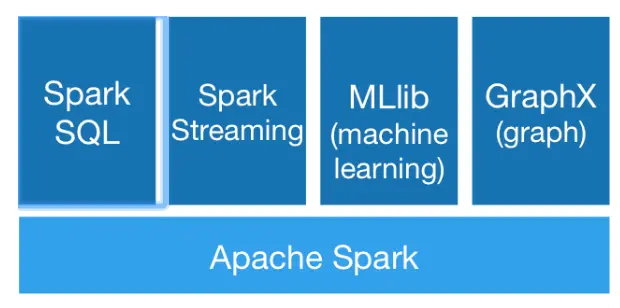
跟我們之前介紹的 Hadoop 一樣,Spark 也有他自己的生態體系 ,以 Spark 為基礎,有支持 SQL 陳述句的 Spark SQL,有支持流計算的 Spark Streaming,有支持機器學習的 MLlib,還有支持圖計算的 GraphX,利用這些產品,Spark 技術堆疊支撐起大資料分析、大資料機器學習等各種大資料應用場景,
為了方便大家了解,下面對這些組件進行一一介紹:
Spark SQL:用來操作結構化資料的核心組件,通過Spark SQL可以直接查詢Hive、 HBase等多種外部資料源中的資料,Spark SQL的重要特點是能夠統一處理關系表和RDD在處理結構化資料時,開發人員無須撰寫 MapReduce程式,直接使用SQL命令就能完成更加復雜的資料查詢操作,
Spark Streaming:Spark提供的流式計算框架,支持高吞吐量、可容錯處理的實時流式資料處理,其核心原理是將流資料分解成一系列短小的批處理作業,每個短小的批處理作業都可以使用 Spark Core進行快速處理,Spark Streaming支持多種資料源,如 Kafka以及TCP套接字等,
MLlib:Spark提供的關于機器學習功能的演算法程式庫,包括分類、回歸、聚類、協同過濾演算法等,還提供了模型評估、資料匯入等額外的功能,開發人員只需了解一定的機器學習演算法知識就能進行機器學習方面的開發,降低了學習成本,
GraphX: Spark提供的分布式圖處理框架,擁有圖計算和圖挖掘演算法的API介面以及豐富的功能和運算子,極大地方便了對分布式圖的處理需求,能在海量資料上運行復雜的圖演算法,
Spark生態系統各個組件關系密切,并且可以相互呼叫,這樣設計具有以下顯著優勢,
(1)Spark生態系統包含的所有程式庫和高級組件都可以從 Spark核心引擎的改進中獲益,
(2)不需要運行多套獨立的軟體系統,能夠大大減少運行整個系統的資源代價,
(3)能夠無縫整合各個系統,構建不同處理模型的應用,
巨人的肩膀
- 《從零開始學大資料》
- 《從零開始學 Spark 》
- https://www.itheima.com/
總結
Spark 有三個主要特性:RDD 的編程模型更簡單,DAG 切分的多階段計算程序更快速,使用記憶體存盤中間計算結果更高效,這三個特性使得 Spark 相對 Hadoop MapReduce 可以有更快的執行速度,以及更簡單的編程實作,
另外,從 Spark 的生態我們可以看出,Spark 框架對大資料的支持從記憶體計算、實時處理到互動式查詢,進而發展到圖計算和機器學習模塊,Spark 生態系統廣泛的技術面,一方面挑戰占據大資料市場份額最大的 Hadoop,另一方面又隨時準備迎接后起之秀 Flink 、Kafka 等計算框架的挑戰,從而使Spark 在大資料領域更好地發展 !
更多精彩內容請關注 微信公眾號 👇「大資料夢想家」🔥:
一枚喜歡閱讀,輸出,復盤的大資料愛好者,熱衷于分享大資料基礎原理,技術實戰,架構設計與原型實作之外,還喜歡輸出一些有趣實用的編程干貨內容,與閱讀心得 …
🚀 關注后回復 【簡歷】獲取大資料精品簡歷模板 800+
🚀 關注后回復 【面經】獲取互聯網一線大廠java校招筆試真題面經匯總
🚀 關注后回復 【Flink知識圖譜】獲取Flink最新權威知識圖譜
🚀關注后回復【大資料高頻面試題】獲取海量大資料高頻面試題+企業級面試真題108套
🚀關注后回復回復【Python學習路線圖】獲取Python學習完整路線
…
更多精彩福利干貨,期待您的關注 ~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/353323.html
標籤:其他