該系列文章是講解Python OpenCV影像處理知識,前期主要講解影像入門、OpenCV基礎用法,中期講解影像處理的各種演算法,包括影像銳化算子、影像增強技術、影像分割等,后期結合深度學習研究影像識別、影像分類應用,希望文章對您有所幫助,如果有不足之處,還請海涵~
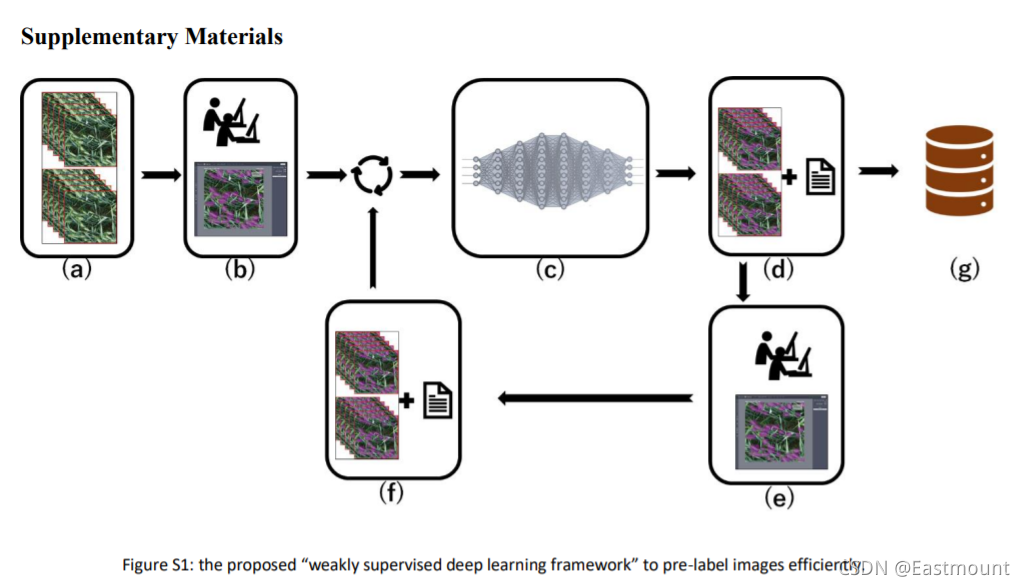
上一篇文章主要通過Keras深度學習構建CNN模型識別阿拉伯手寫文字影像,一篇非常經典的影像分類文字,本文將詳細講解Pytorch構建Faster-RCNN模型實作小麥目標檢測,主要參考kaggle大佬和劉兄的模型,推薦大家關注,這是一篇非常經典的影像識別文字,希望您喜歡,且看且珍惜,
第二階段我們進入了Python影像識別,該部分主要以目標檢測、影像識別以及深度學習相關影像分類為主,將會分享近50篇文章,感謝您一如至往的支持,作者也會繼續加油的!
- https://maoli.blog.csdn.net/article/details/117688738
文章目錄
- 一.Pytorch安裝
- 二.資料集描述
- 1.Kaggle賽題
- 2.資料集介紹
- 三.代碼實作
- 1.讀取小麥資料
- 2.可視化展示
- 3.構建Faster-RCNN模型
- 4.模型預測
- 四.總結
同時,該部分知識均為作者查閱資料撰寫總結,并且開設成了收費專欄,為小寶賺點奶粉錢,感謝您的抬愛,如果有問題隨時私聊我,只望您能從這個系列中學到知識,一起加油,代碼下載地址(如果喜歡記得star,一定喔):
- https://github.com/eastmountyxz/ImageProcessing-Python
影像識別:
- [Python影像識別] 四十五.物件檢測案例入門及ImageAI基礎用法
- [Python影像識別] 四十六.影像預處理之影像去霧詳解(ACE演算法和暗通道先驗去霧演算法)
- [Python影像識別] 四十七.Keras深度學習構建CNN識別阿拉伯手寫文字影像
- [Python影像識別] 四十八.Pytorch構建Faster-RCNN模型實作小麥目標檢測
影像處理:
- [Python影像處理] 一.影像處理基礎知識及OpenCV入門函式
- [Python影像處理] 二.OpenCV+Numpy庫讀取與修改像素
- [Python影像處理] 三.獲取影像屬性、興趣ROI區域及通道處理
- [Python影像處理] 四.影像平滑之均值濾波、方框濾波、高斯濾波及中值濾波
- [Python影像處理] 五.影像融合、加法運算及影像型別轉換
- [Python影像處理] 六.影像縮放、影像旋轉、影像翻轉與影像平移
- [Python影像處理] 七.影像閾值化處理及演算法對比
- [Python影像處理] 八.影像腐蝕與影像膨脹
- [Python影像處理] 九.形態學之影像開運算、閉運算、梯度運算
- [Python影像處理] 十.形態學之影像頂帽運算和黑帽運算
- [Python影像處理] 十一.灰度直方圖概念及OpenCV繪制直方圖
- [Python影像處理] 十二.影像幾何變換之影像仿射變換、影像透視變換和影像校正
- [Python影像處理] 十三.基于灰度三維圖的影像頂帽運算和黑帽運算
- [Python影像處理] 十四.基于OpenCV和像素處理的影像灰度化處理
- [Python影像處理] 十五.影像的灰度線性變換
- [Python影像處理] 十六.影像的灰度非線性變換之對數變換、伽馬變換
- [Python影像處理] 十七.影像銳化與邊緣檢測之Roberts算子、Prewitt算子、Sobel算子和Laplacian算子
- [Python影像處理] 十八.影像銳化與邊緣檢測之Scharr算子、Canny算子和LOG算子
- [Python影像處理] 十九.影像分割之基于K-Means聚類的區域分割
- [Python影像處理] 二十.影像量化處理和采樣處理及區域馬賽克特效
- [Python影像處理] 二十一.影像金字塔之影像向下取樣和向上取樣
- [Python影像處理] 二十二.Python影像傅里葉變換原理及實作
- [Python影像處理] 二十三.傅里葉變換之高通濾波和低通濾波
- [Python影像處理] 二十四.影像特效處理之毛玻璃、浮雕和油漆特效
- [Python影像處理] 二十五.影像特效處理之素描、懷舊、光照、流年以及濾鏡特效
- [Python影像處理] 二十六.影像分類原理及基于KNN、樸素貝葉斯演算法的影像分類案例
- [Python影像處理] 二十七.OpenGL入門及繪制基本圖形(一)
- [Python影像處理] 二十八.OpenCV快速實作人臉檢測及視頻中的人臉
- [Python影像處理] 二十九.MoviePy視頻編輯庫實作抖音短視頻剪切合并操作
- [Python影像處理] 三十.影像量化及采樣處理萬字詳細總結(推薦)
- [Python影像處理] 三十一.影像點運算處理兩萬字詳細總結(灰度化處理、閾值化處理)
- [Python影像處理] 三十二.傅里葉變換(影像去噪)與霍夫變換(特征識別)萬字詳細總結
- [Python影像處理] 三十三.影像各種特效處理及原理萬字詳解(毛玻璃、浮雕、素描、懷舊、流年、濾鏡等)
- [Python影像處理] 三十四.數字影像處理基礎與幾何圖形繪制萬字詳解(推薦)
- [Python影像處理] 三十五.OpenCV影像處理入門、算數邏輯運算與影像融合(推薦)
- [Python影像處理] 三十六.OpenCV影像幾何變換萬字詳解(平移縮放旋轉、鏡像仿射透視)
- [Python影像處理] 三十七.OpenCV和Matplotlib繪制直方圖萬字詳解(掩膜直方圖、H-S直方圖、黑夜白天判斷)
- [Python影像處理] 三十八.OpenCV影像增強萬字詳解(直方圖均衡化、區域直方圖均衡化、自動色彩均衡化)
- [Python影像處理] 三十九.Python影像分類萬字詳解(貝葉斯影像分類、KNN影像分類、DNN影像分類)
- [Python影像處理] 四十.全網首發Python影像分割萬字詳解(閾值分割、邊緣分割、紋理分割、分水嶺演算法、K-Means分割、漫水填充分割、區域定位)
- [Python影像處理] 四十一.Python影像平滑萬字詳解(均值濾波、方框濾波、高斯濾波、中值濾波、雙邊濾波)
- [Python影像處理] 四十二.Python影像銳化及邊緣檢測萬字詳解(Roberts、Prewitt、Sobel、Laplacian、Canny、LOG)
- [Python影像處理] 四十三.Python影像形態學處理萬字詳解(腐蝕膨脹、開閉運算、梯度頂帽黑帽運算)
- 萬字長文告訴新手如何學習Python影像處理 (上篇完結 四十四)
一.Pytorch安裝
Pytorch安裝需要在官網選擇對應的環境,接著按自動生成的安裝命令執行,
- 官網:https://pytorch.org/
選擇與自己相匹配的版本,這里顯示是我安裝的選擇,
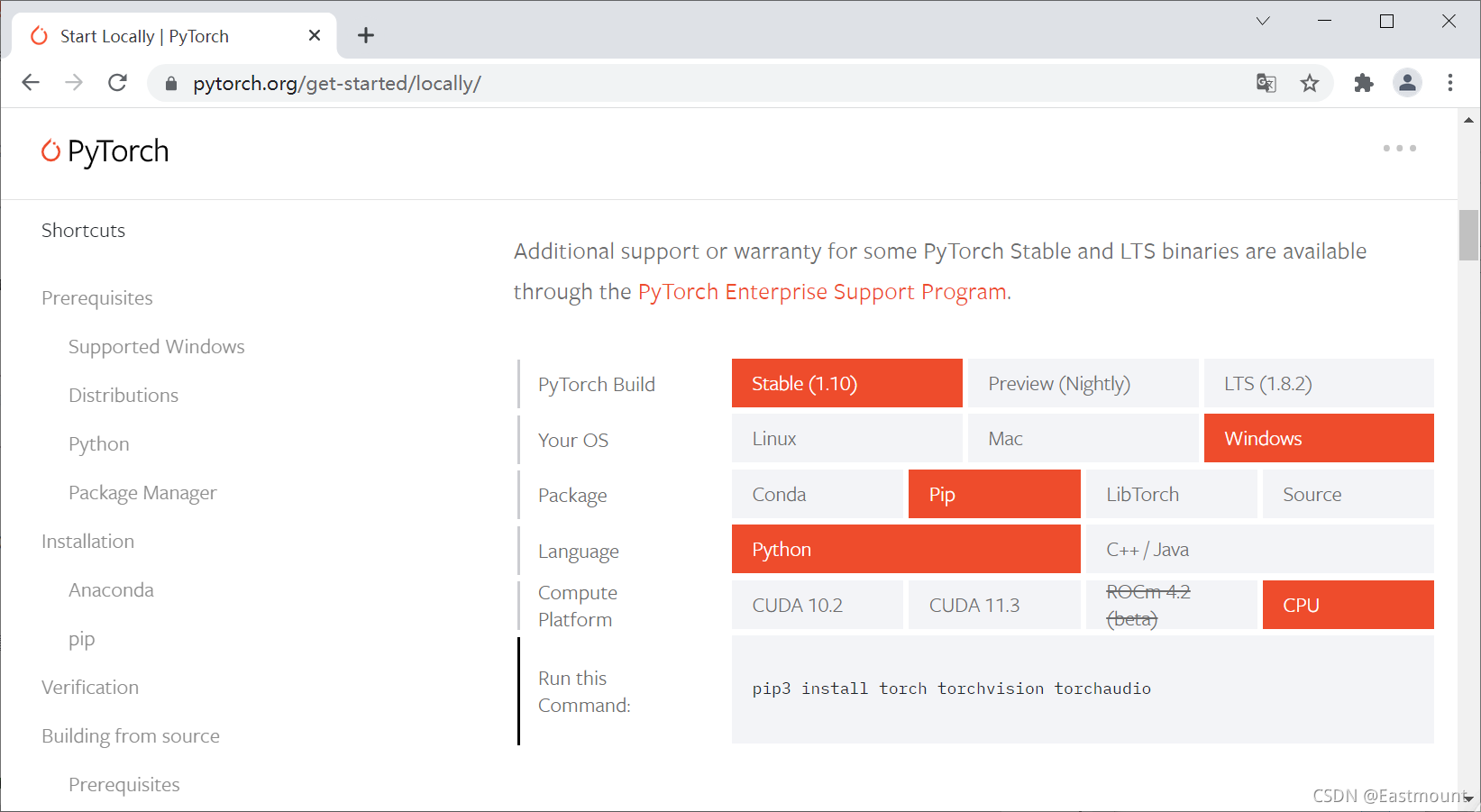
安裝代碼:
- pip3 install torch torchvision torchaudio
- conda install pytorch torchvision torchaudio cpuonly -c pytorch
同時安裝擴展包albumentations,
- pip install albumentations
二.資料集描述
1.Kaggle賽題
資料集是來自Kaggle的——全球小麥檢測資料,題目是“您能使用影像分析幫助識別小麥嗎?”
- https://www.kaggle.com/c/global-wheat-detection
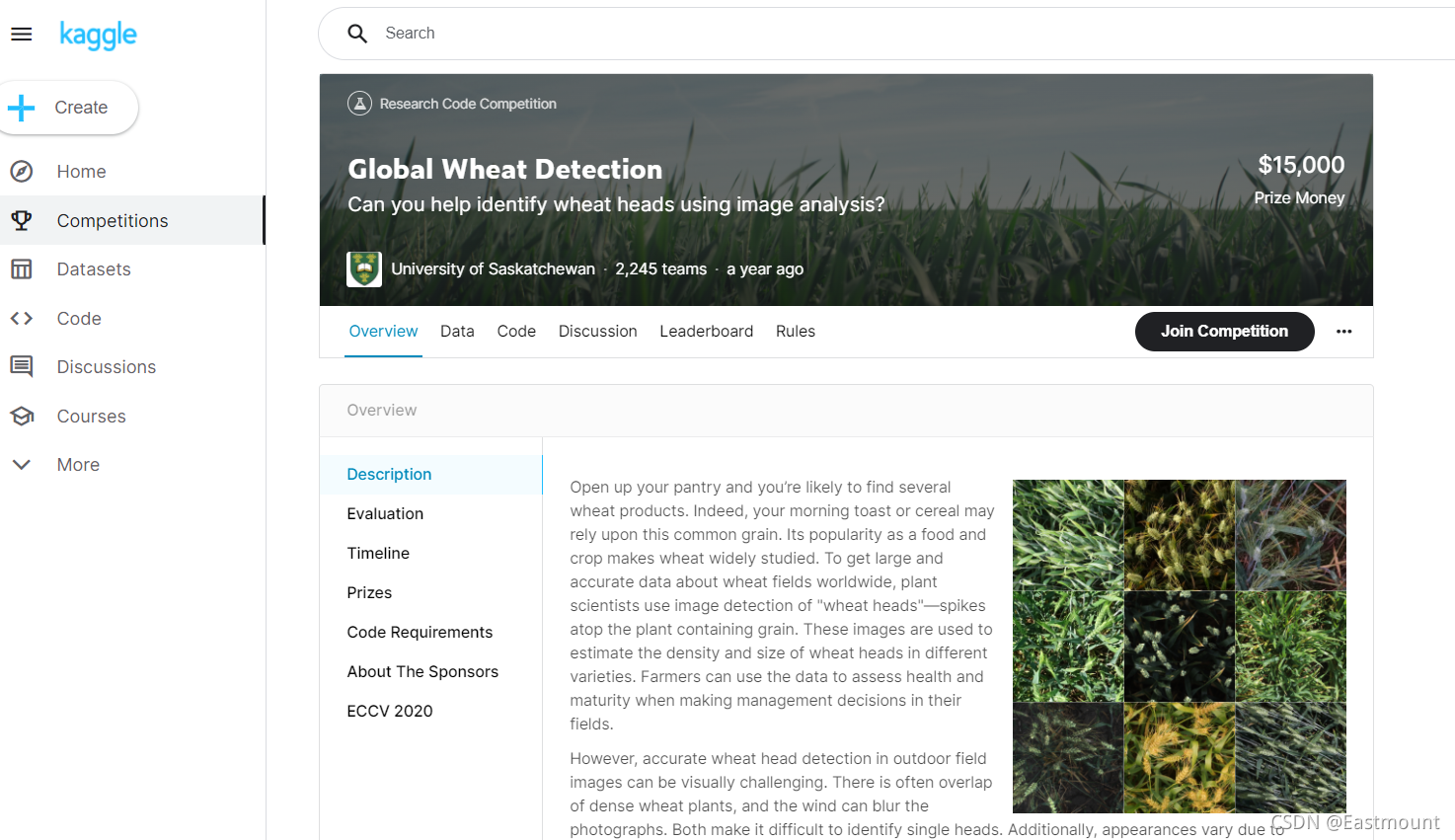
題目介紹:
打開您的食品儲藏室,您很可能會找到幾種小麥產品,事實上,您的早餐吐司或麥片可能依賴于這種常見的谷物,它作為一種流行的食物和作物,讓小麥得到了廣泛的研究,為了獲得有關全球麥田的大量準確資料,植物科學家使用“小麥頭”的影像,檢測含有谷物的植物頂部尖峰,這些影像用于估計不同品種小麥的密度和大小,農民在他們的田地做出管理決策時,可以使用這些資料來評估其健康和成熟度,
然而,在室外田間影像中準確檢測麥頭在視覺上具有挑戰性,密密麻麻的小麥植株經常重疊,風會模糊照片,兩者都使識別單個頭部變得困難,此外,外觀因成熟度、顏色、基因型別和頭部方向而異,最后,由于小麥在世界范圍內種植,因此必須考慮不同的品種、種植密度、模式和田間條件,小麥開發模型需要在不同的生長環境之間進行概括,當前的檢測方法涉及一級和二級檢測器(Yolo-v3 和 Faster-RCNN),但即使使用大型資料集進行訓練,對訓練區域的偏差仍然存在,
在全球小麥頭資料集是由來自七個國家的九個研究機構主導,包括東京大學等,此后,許多機構都加入了他們追求準確檢測小麥頭部的行列,包括全球食品安全研究所、DigitAg、Kubota 和 Hiphen,在本次比賽中,您將從小麥植物的室外影像中檢測小麥頭,包括來自全球的小麥資料集,使用全球資料,您將專注于通用解決方案來估計小麥頭的數量和大小,為了更好地衡量未知基因型、環境和觀察條件的性能,訓練資料集涵蓋多個區域,您將使用來自歐洲(法國、英國、瑞士)和北美(加拿大)的 3,000 多張影像,測驗資料包括來自澳大利亞、日本和中國的約 1,000 張影像,
小麥是全球的主食,這就是為什么這種競爭必須考慮到不同的生長條件,為小麥表型開發的模型需要能夠在環境之間進行概括,如果成功,研究人員可以準確估計不同品種小麥頭的密度和大小,通過改進的檢測,農民可以更好地評估他們的作物,最終將谷物、烤面包和其他喜愛的菜肴帶到您的餐桌上,有關資料采集和程序的更多詳細資訊,請訪問:
- https://arxiv.org/abs/2005.02162

2.資料集介紹
我們應該期望資料格式是什么?
資料是麥田的影像,每個識別的麥頭都有邊界框,并非所有影像都包含小麥頭/邊界框,這些影像被記錄在世界各地的許多地方,
- CSV 資料很簡單:影像 ID 與給定影像的檔案名相匹配,并且包含影像的寬度和高度以及邊界框(見下文),train.csv每個邊界框都有一行,并非所有影像都有邊界框,大多數測驗集影像是隱藏的,包含一小部分測驗影像供您在撰寫代碼時使用,
我們在預測什么?
您正在嘗試預測影像中每個小麥頭周圍的邊界框,如果沒有小麥頭,則必須預測沒有邊界框,
資料集包含四個檔案
- train.csv - 訓練資料
- sample_submission.csv - 格式正確的示例提交檔案
- train.zip - 訓練影像
- test.zip - 測驗影像
資料集如下圖所示:
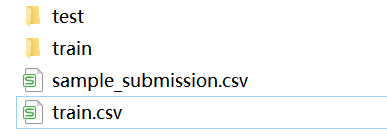
檔案夾中包含小麥影像,名稱是其ID,

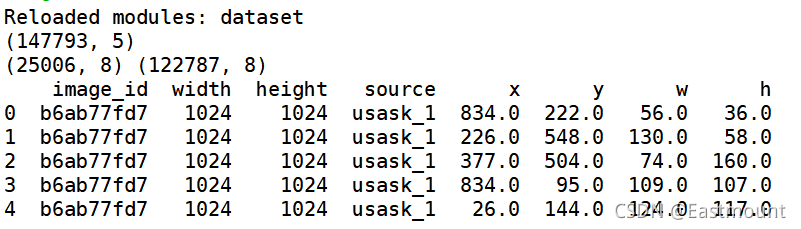
train.csv中對應五列結果,分別是:
- image_id - 唯一的影像 ID
- width - 影像的寬度
- height - 影像的高度
- bbox - 一個邊界框,格式為 [xmin, ymin, width, height] 的 Python 樣式串列
- source - 影像對應的類別
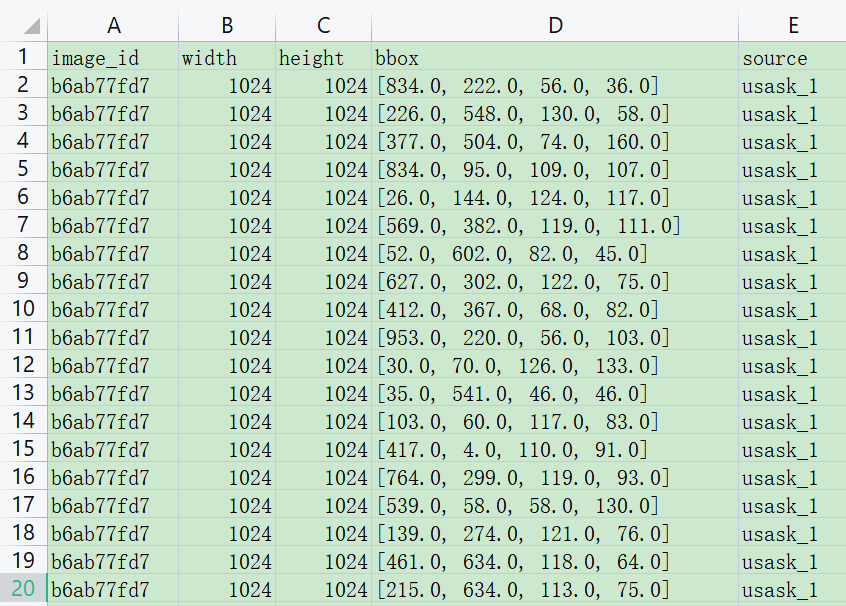
訓練集中各小麥型別分布如下圖所示:
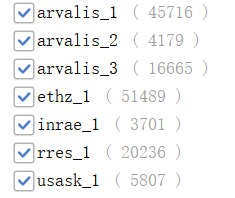
整個小麥預測的大致流程如下圖所示:
模型評估引數如下所示,推薦大家閱讀kaggle官網介紹,

提交格式需要以空格分隔的一組邊界框,例如:
- ce4833752, 0.5 0 0 100 100
表示影像ce4833752有一個邊界框,aconfidence為 0.5,在x== 0 和y== 0,awidth和height為 100,
該檔案應包含標題并具有以下格式,您提交的每一行都應包含給定影像的所有邊界框,
image_id,PredictionString
ce4833752,1.0 0 0 50 50
adcfa13da,1.0 0 0 50 50
6ca7b2650,
1da9078c1,0.3 0 0 50 50 0.5 10 10 30 30
7640b4963,0.5 0 0 50 50
三.代碼實作
下面我們參考Kaggle Peter老師的代碼,來復現Faster-RCNN模型,
- https://www.kaggle.com/pestipeti/pytorch-starter-fasterrcnn-train
模型的框架如下圖所示,相信大家都比較熟悉,也推薦大家使用并深入了解背后的原理,
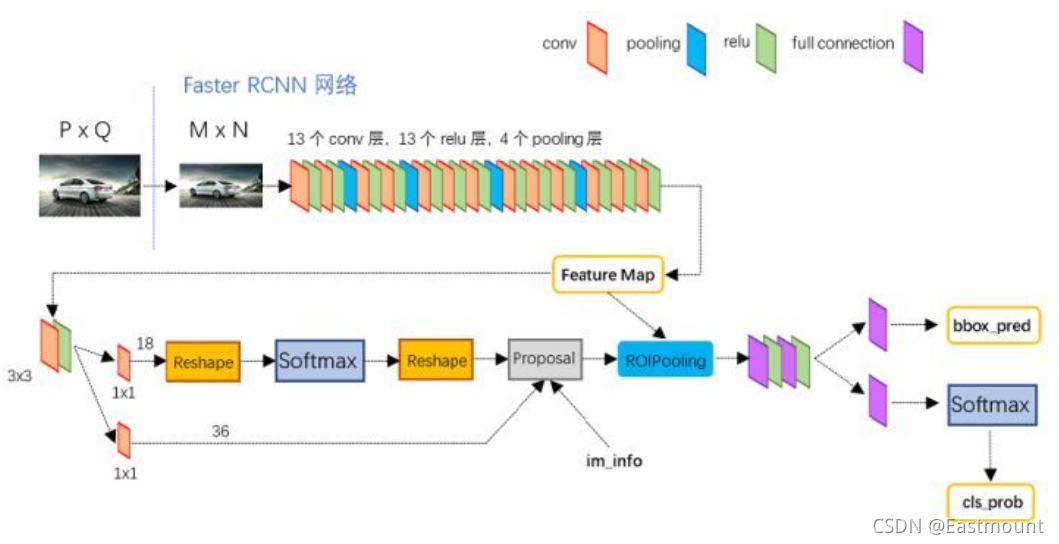
1.讀取小麥資料
讀取小麥資料集的代碼如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 29 13:42:38 2021
@author: xiuzhang
"""
import os
import re
import cv2
import pandas as pd
import numpy as np
from PIL import Image
import albumentations as A
from matplotlib import pyplot as plt
from albumentations.pytorch.transforms import ToTensorV2
import torch
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import SequentialSampler
from dataset import WheatDataset
#-----------------------------------------------------------------------------
#第一步 函式定義
#----------------------------------------------------------------------------
#提取box的四個坐標
def expand_bbox(x):
r = np.array(re.findall("([0-9]+[.]?[0-9]*)", x))
if len(r) == 0:
r = [-1, -1, -1, -1]
return r
#訓練影像增強 Albumentations
def get_train_transform():
return A.Compose([
A.Flip(0.5),
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
#驗證影像增強
def get_valid_transform():
return A.Compose([
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
def collate_fn(batch):
return tuple(zip(*batch))
#-----------------------------------------------------------------------------
#第二步 定義變數并讀取資料
#-----------------------------------------------------------------------------
DIR_INPUT = 'data'
DIR_TRAIN = f'{DIR_INPUT}/train'
DIR_TEST = f'{DIR_INPUT}/test'
train_df = pd.read_csv(f'{DIR_INPUT}/train.csv')
print(train_df.shape)
train_df['x'] = -1
train_df['y'] = -1
train_df['w'] = -1
train_df['h'] = -1
#讀取box四個坐標
train_df[['x', 'y', 'w', 'h']] = np.stack(train_df['bbox'].apply(lambda x: expand_bbox(x)))
train_df.drop(columns=['bbox'], inplace=True)
train_df['x'] = train_df['x'].astype(np.float)
train_df['y'] = train_df['y'].astype(np.float)
train_df['w'] = train_df['w'].astype(np.float)
train_df['h'] = train_df['h'].astype(np.float)
#獲取影像id
image_ids = train_df['image_id'].unique()
valid_ids = image_ids[-665:]
train_ids = image_ids[:-665]
valid_df = train_df[train_df['image_id'].isin(valid_ids)]
train_df = train_df[train_df['image_id'].isin(train_ids)]
print(valid_df.shape, train_df.shape)
print(train_df.head())
顯示結果如下圖所示,分別獲取影像id和資料,并劃分為train(訓練)和valid(驗證),
其中,dataset.py檔案代碼如下:
- 獲取影像id
- 獲取影像像素值并歸一化處理
- 獲取影像對應的邊界(x | y | w | h)
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 29 13:42:38 2021
@author: xiuzhang
"""
import numpy as np
import cv2
import torch
from torch.utils.data import Dataset
class WheatDataset(Dataset):
def __init__(self, dataframe, image_dir, transforms=None):
super().__init__()
self.image_ids = dataframe['image_id'].unique()
self.df = dataframe
self.image_dir = image_dir
self.transforms = transforms
def __getitem__(self, index: int):
image_id = self.image_ids[index]
records = self.df[self.df['image_id'] == image_id]
image = cv2.imread(f'{self.image_dir}/{image_id}.jpg', cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).astype(np.float32)
image /= 255.0
boxes = records[['x', 'y', 'w', 'h']].values
boxes[:, 2] = boxes[:, 0] + boxes[:, 2]
boxes[:, 3] = boxes[:, 1] + boxes[:, 3]
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
area = torch.as_tensor(area, dtype=torch.float32)
# there is only one class
labels = torch.ones((records.shape[0],), dtype=torch.int64)
# suppose all instances are not crowd
iscrowd = torch.zeros((records.shape[0],), dtype=torch.int64)
target = {}
target['boxes'] = boxes
target['labels'] = labels
# target['masks'] = None
target['image_id'] = torch.tensor([index])
target['area'] = area
target['iscrowd'] = iscrowd
if self.transforms:
sample = {
'image': image,
'bboxes': target['boxes'],
'labels': labels
}
sample = self.transforms(**sample)
image = sample['image']
target['boxes'] = torch.stack(tuple(map(torch.tensor, zip(*sample['bboxes'])))).permute(1, 0)
return image, target, image_id
def __len__(self) -> int:
return self.image_ids.shape[0]
2.可視化展示
接下來我們對小麥影像進行簡單的可視化操作,代碼如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 29 13:42:38 2021
@author: xiuzhang
"""
import os
import re
import cv2
import pandas as pd
import numpy as np
from PIL import Image
import albumentations as A
from matplotlib import pyplot as plt
from albumentations.pytorch.transforms import ToTensorV2
import torch
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import SequentialSampler
from dataset import WheatDataset
#-----------------------------------------------------------------------------
#第一步 函式定義
#----------------------------------------------------------------------------
#提取box的四個坐標
def expand_bbox(x):
r = np.array(re.findall("([0-9]+[.]?[0-9]*)", x))
if len(r) == 0:
r = [-1, -1, -1, -1]
return r
#訓練影像增強 Albumentations
def get_train_transform():
return A.Compose([
A.Flip(0.5),
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
#驗證影像增強
def get_valid_transform():
return A.Compose([
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
def collate_fn(batch):
return tuple(zip(*batch))
#-----------------------------------------------------------------------------
#第二步 定義變數并讀取資料
#-----------------------------------------------------------------------------
DIR_INPUT = 'data'
DIR_TRAIN = f'{DIR_INPUT}/train'
DIR_TEST = f'{DIR_INPUT}/test'
train_df = pd.read_csv(f'{DIR_INPUT}/train.csv')
print(train_df.shape)
train_df['x'] = -1
train_df['y'] = -1
train_df['w'] = -1
train_df['h'] = -1
#讀取box四個坐標
train_df[['x', 'y', 'w', 'h']] = np.stack(train_df['bbox'].apply(lambda x: expand_bbox(x)))
train_df.drop(columns=['bbox'], inplace=True)
train_df['x'] = train_df['x'].astype(np.float)
train_df['y'] = train_df['y'].astype(np.float)
train_df['w'] = train_df['w'].astype(np.float)
train_df['h'] = train_df['h'].astype(np.float)
#獲取影像id
image_ids = train_df['image_id'].unique()
valid_ids = image_ids[-665:]
train_ids = image_ids[:-665]
valid_df = train_df[train_df['image_id'].isin(valid_ids)]
train_df = train_df[train_df['image_id'].isin(train_ids)]
print(valid_df.shape, train_df.shape)
print(train_df.head())
#-----------------------------------------------------------------------------
#第三步 加載資料
#-----------------------------------------------------------------------------
train_dataset = WheatDataset(train_df, DIR_TRAIN, get_train_transform())
valid_dataset = WheatDataset(valid_df, DIR_TRAIN, get_valid_transform())
train_data_loader = DataLoader(
train_dataset,
batch_size=2,
shuffle=False,
num_workers=0,
collate_fn=collate_fn
)
valid_data_loader = DataLoader(
valid_dataset,
batch_size=2,
shuffle=False,
num_workers=0,
collate_fn=collate_fn
)
#-----------------------------------------------------------------------------
#第四步 資料可視化
#-----------------------------------------------------------------------------
#提取訓練資料和類別
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
images, targets, image_ids = next(iter(train_data_loader))
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
boxes = targets[0]['boxes'].cpu().numpy().astype(np.int32)
sample = images[0].permute(1, 2, 0).cpu().numpy()
fig, ax = plt.subplots(1, 1, figsize=(10, 8))
#繪制小麥目標識別box
for box in boxes:
cv2.rectangle(sample,
(box[0], box[1]),
(box[2], box[3]),
(255, 0, 0), 3)
ax.text(box[0],
box[1] - 2,
'{:s}'.format('wheat'),
bbox=dict(facecolor='blue', alpha=0.5),
fontsize=12,
color='white')
ax.set_axis_off()
ax.imshow(sample)
plt.show()
輸出結果如下圖所示,按照train.csv定義好的邊界我們繪制了wheat紅色框,將小麥標記,最終的測驗集,我們希望能自動預測小麥的邊界,從而有效識別小麥區域和數量,
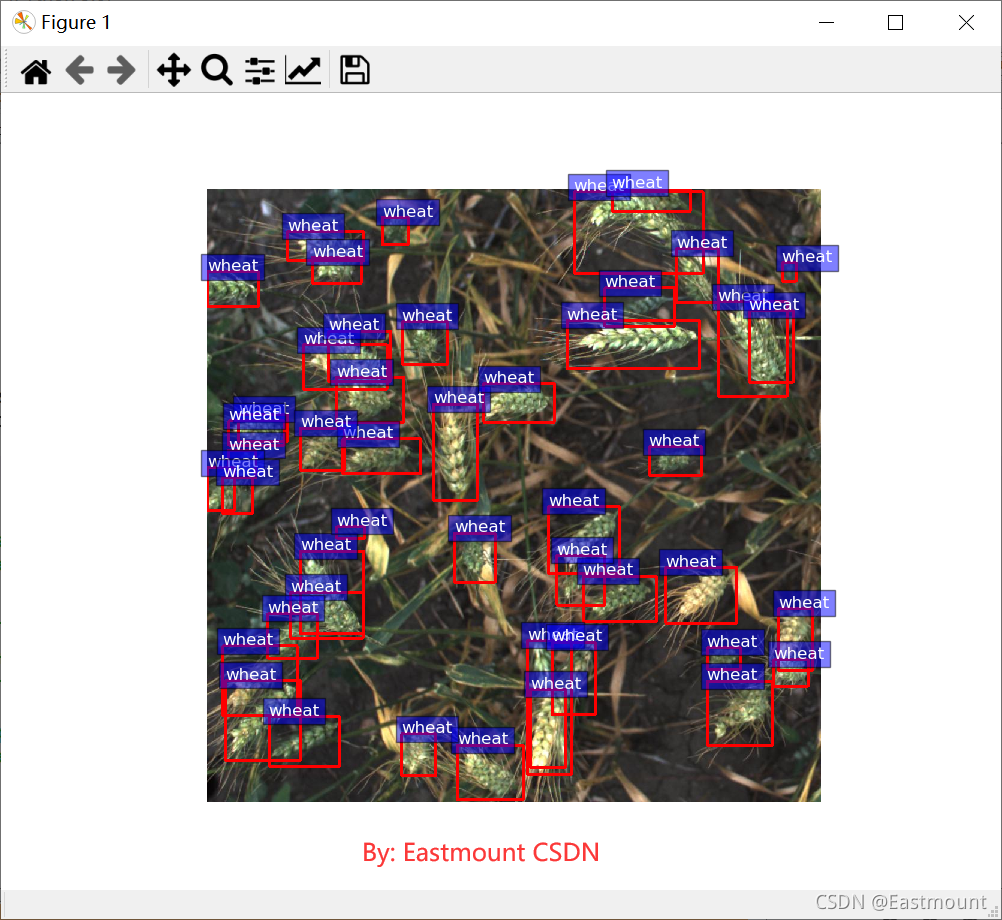
警告:
- Clipping input data to the valid range for imshow with RGB data ([0…1] for floats or [0…255] for integers).
3.構建Faster-RCNN模型
接下來構造Faster-RCNN模型,這是目標檢測的經典模型,其核心代碼如下所示:
- model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
#-----------------------------------------------------------------------------
#第五步 模型構建
#-----------------------------------------------------------------------------
num_classes = 2 #1 class (wheat) + background
lr_scheduler = None
num_epochs = 1
itr = 1
class Averager:
def __init__(self):
self.current_total = 0.0
self.iterations = 0.0
def send(self, value):
self.current_total += value
self.iterations += 1
@property
def value(self):
if self.iterations == 0:
return 0
else:
return 1.0 * self.current_total / self.iterations
def reset(self):
self.current_total = 0.0
self.iterations = 0.0
#load a model pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
#獲取分類器輸入特征數量
in_features = model.roi_heads.box_predictor.cls_score.in_features
#replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
#引數設定
model.to(device)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
#lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
loss_hist = Averager()
print("Start training....")
# 迭代訓練
for epoch in range(num_epochs):
loss_hist.reset()
for images, targets, image_ids in train_data_loader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
for t in targets:
t['boxes'] = t['boxes'].float()
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
loss_value = losses.item()
loss_hist.send(loss_value)
print("loss is :",loss_value)
optimizer.zero_grad()
losses.backward()
optimizer.step()
if itr % 50 == 0:
print(f"Iteration #{itr}/{len(train_data_loader)} loss: {loss_value}")
itr += 1
#更新學習率
if lr_scheduler is not None:
lr_scheduler.step()
print(f"Epoch #{epoch} loss: {loss_hist.value}")
torch.save(model.state_dict(), 'fasterrcnn_resnet50_fpn.pth')
print("Next Test....")
運行程序如下圖所示:
Downloading: "https://download.pytorch.org/models/fasterrcnn_resnet50_fpn_coco-258fb6c6.pth"
to C:\Users\xxx/.cache\torch\hub\checkpoints\fasterrcnn_resnet50_fpn_coco-258fb6c6.pth
100%|██████████| 160M/160M [04:06<00:00, 679KB/s]
4.模型預測
增加模型預測的最終完整代碼如下:
- 第一步:函式定義
- 第二步:定義變數并讀取資料
- 第三步:加載資料
- 第四步:資料可視化
- 第五步:Faster-RCNN模型構建
- 第六步:模型測驗
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 29 13:42:38 2021
@author: xiuzhang
"""
import os
import re
import cv2
import pandas as pd
import numpy as np
from PIL import Image
import albumentations as A
from matplotlib import pyplot as plt
from albumentations.pytorch.transforms import ToTensorV2
import torch
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.sampler import SequentialSampler
from dataset import WheatDataset
#-----------------------------------------------------------------------------
#第一步 函式定義
#----------------------------------------------------------------------------
#提取box的四個坐標
def expand_bbox(x):
r = np.array(re.findall("([0-9]+[.]?[0-9]*)", x))
if len(r) == 0:
r = [-1, -1, -1, -1]
return r
#訓練影像增強 Albumentations
def get_train_transform():
return A.Compose([
A.Flip(0.5),
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
#驗證影像增強
def get_valid_transform():
return A.Compose([
ToTensorV2(p=1.0)
], bbox_params={'format': 'pascal_voc', 'label_fields': ['labels']})
def collate_fn(batch):
return tuple(zip(*batch))
#-----------------------------------------------------------------------------
#第二步 定義變數并讀取資料
#-----------------------------------------------------------------------------
DIR_INPUT = 'data'
DIR_TRAIN = f'{DIR_INPUT}/train'
DIR_TEST = f'{DIR_INPUT}/test'
train_df = pd.read_csv(f'{DIR_INPUT}/train.csv')
print(train_df.shape)
train_df['x'] = -1
train_df['y'] = -1
train_df['w'] = -1
train_df['h'] = -1
#讀取box四個坐標
train_df[['x', 'y', 'w', 'h']] = np.stack(train_df['bbox'].apply(lambda x: expand_bbox(x)))
train_df.drop(columns=['bbox'], inplace=True)
train_df['x'] = train_df['x'].astype(np.float)
train_df['y'] = train_df['y'].astype(np.float)
train_df['w'] = train_df['w'].astype(np.float)
train_df['h'] = train_df['h'].astype(np.float)
#獲取影像id
image_ids = train_df['image_id'].unique()
valid_ids = image_ids[-665:]
train_ids = image_ids[:-665]
valid_df = train_df[train_df['image_id'].isin(valid_ids)]
train_df = train_df[train_df['image_id'].isin(train_ids)]
print(valid_df.shape, train_df.shape)
print(train_df.head())
#-----------------------------------------------------------------------------
#第三步 加載資料
#-----------------------------------------------------------------------------
train_dataset = WheatDataset(train_df, DIR_TRAIN, get_train_transform())
valid_dataset = WheatDataset(valid_df, DIR_TRAIN, get_valid_transform())
train_data_loader = DataLoader(
train_dataset,
batch_size=2,
shuffle=False,
num_workers=0,
collate_fn=collate_fn
)
valid_data_loader = DataLoader(
valid_dataset,
batch_size=2,
shuffle=False,
num_workers=0,
collate_fn=collate_fn
)
#-----------------------------------------------------------------------------
#第四步 資料可視化
#-----------------------------------------------------------------------------
#提取訓練資料和類別
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
images, targets, image_ids = next(iter(train_data_loader))
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
boxes = targets[0]['boxes'].cpu().numpy().astype(np.int32)
sample = images[0].permute(1, 2, 0).cpu().numpy()
fig, ax = plt.subplots(1, 1, figsize=(10, 8))
#繪制小麥目標識別box
for box in boxes:
cv2.rectangle(sample,
(box[0], box[1]),
(box[2], box[3]),
(255, 0, 0), 3)
ax.text(box[0],
box[1] - 2,
'{:s}'.format('wheat'),
bbox=dict(facecolor='blue', alpha=0.5),
fontsize=12,
color='white')
ax.set_axis_off()
ax.imshow(sample)
plt.show()
#-----------------------------------------------------------------------------
#第五步 模型構建
#-----------------------------------------------------------------------------
num_classes = 2 #1 class (wheat) + background
lr_scheduler = None
num_epochs = 1
itr = 1
class Averager:
def __init__(self):
self.current_total = 0.0
self.iterations = 0.0
def send(self, value):
self.current_total += value
self.iterations += 1
@property
def value(self):
if self.iterations == 0:
return 0
else:
return 1.0 * self.current_total / self.iterations
def reset(self):
self.current_total = 0.0
self.iterations = 0.0
#load a model pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
#獲取分類器輸入特征數量
in_features = model.roi_heads.box_predictor.cls_score.in_features
#replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
#引數設定
model.to(device)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)
#lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
loss_hist = Averager()
print("Start training....")
# 迭代訓練
for epoch in range(num_epochs):
loss_hist.reset()
for images, targets, image_ids in train_data_loader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
for t in targets:
t['boxes'] = t['boxes'].float()
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
loss_value = losses.item()
loss_hist.send(loss_value)
#print("loss is :",loss_value)
optimizer.zero_grad()
losses.backward()
optimizer.step()
if itr % 50 == 0:
print(f"Iteration #{itr}/{len(train_data_loader)} loss: {loss_value}")
itr += 1
#更新學習率
if lr_scheduler is not None:
lr_scheduler.step()
print(f"Epoch #{epoch} loss: {loss_hist.value}")
torch.save(model.state_dict(), 'fasterrcnn_resnet50_fpn.pth')
print("Next Test....")
#-----------------------------------------------------------------------------
#第六步 模型測驗
#-----------------------------------------------------------------------------
images, targets, image_ids = next(iter(valid_data_loader))
images = list(img.to(device) for img in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
boxes = targets[0]['boxes'].cpu().numpy().astype(np.int32)
sample = images[0].permute(1, 2, 0).cpu().numpy()
model.eval()
cpu_device = torch.device("cpu")
outputs = model(images)
outputs = [{k: v.to(cpu_device) for k, v in t.items()} for t in outputs]
fig, ax = plt.subplots(1, 1, figsize=(16, 8))
for box in boxes:
cv2.rectangle(sample,
(box[0], box[1]),
(box[2], box[3]),
(220, 0, 0), 3)
ax.set_axis_off()
ax.imshow(sample)
plt.show()
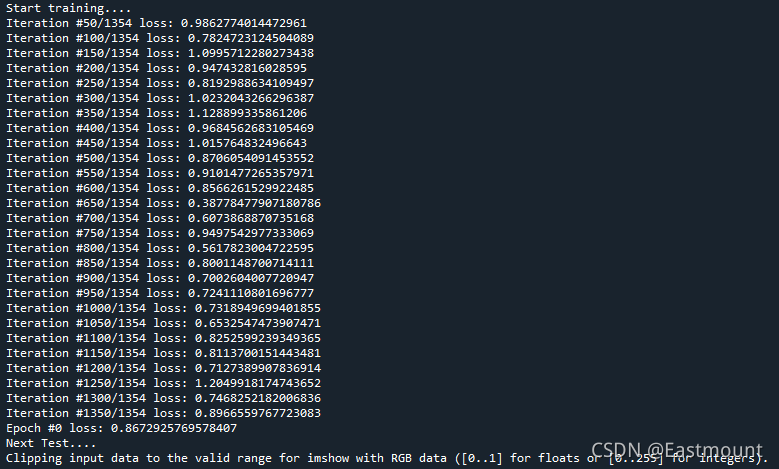
模型運行結果如下圖所示,可以看到迭代的loss,推薦大家用好的目標檢測環境實驗,
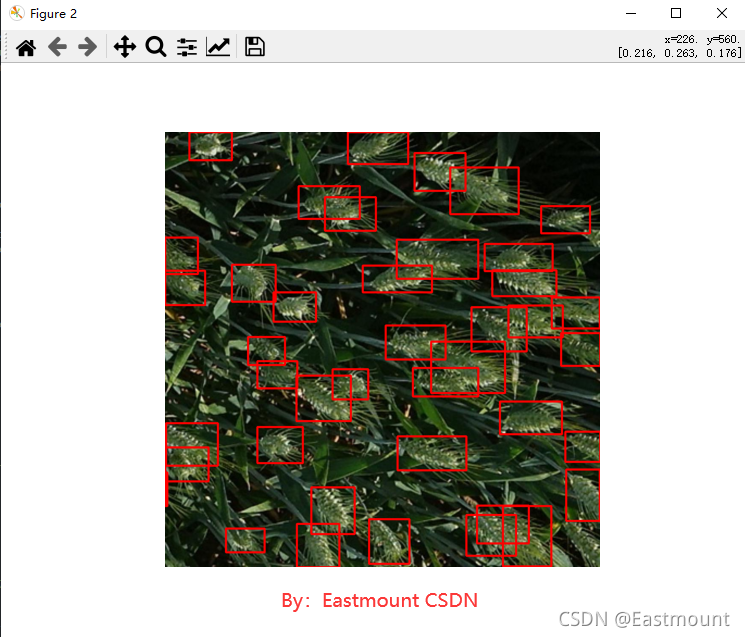
同時對測驗集或驗證集的影像進行識別,如下圖所示:
四.總結
寫到這里,這篇文章就介紹結束了,希望對您有所幫助,詳細的對比實驗和演算法評估還請讀者自行完成,后續作者的文章也會深入介紹,
- 一.Pytorch安裝
- 二.資料集描述
1.Kaggle賽題
2.資料集介紹 - 三.代碼實作
1.讀取小麥資料
2.可視化展示
3.構建Faster-RCNN模型
4.模型預測
代碼和資料集下載地址:
- https://github.com/eastmountyxz/ImageProcessing-Python
《立冬–小珞情》
初冬已至,泛黃的銀杏葉隨著寒風飄落,觀山大道旁不時傳來陣陣殘香,冷風也裹緊了路人的衣裳,隨著時光的流淌,我渡過了生命中的第一年,雖然還不能用言語表達,但我早已熟悉了這美妙的世界,感受到了家人對我的疼愛,當然也偶爾會經歷一些煩惱,比這兩天的感冒,每當我難受的時候,我就會嘶吼,或煩躁,還好,媽媽和婆婆總能第一時間將我抱起,在懷抱中搖擺著安撫我穩定,搖著搖著,看到媽媽那雙疼愛的眼睛,我總會立時揚起嘴角,那是一種只有在媽媽懷抱中才會揚起的傻笑,接著進入甜美的夢境中,雖然我還小,但似乎也能感受到媽媽對這個微笑的喜歡,恰是立冬的第一杯奶茶,暖暖地流進她的心底,
“叮咚叮…”,醒來的我聽到了電話里傳來了遠方的微信視頻,我迫不及待地搶走了手機,但又不知道如何接通,此時的媽媽扶著我按下了綠色接聽鍵,看到那似熟非熟的眼鏡娃娃胡子臉,我叫了一聲“粑粑”(就是這發音),親情,那一朵永遠微笑著的薔薇,無論過了多久都讓人無法忘卻,散發著芬芳,電話里,聽爸爸說,他朋友圈里的北方迎來了初雪,EDG奪得了冠軍,喬木和街道昨夜已悄然換上了雪白的冬裝,讓我們記得保暖,媽媽回復到,貴陽的寒風這兩天格外的凜冽,小珞珞感冒快好了,也讓爸爸記得多穿衣服,聽著他倆嘮家常,我在旁邊不時地翻滾嬉鬧,似乎要證明我才是家里最重要的一員,“媽做的酸湯魚好了,我們準備吃飯去了,你也早點吃飯,珞珞別擔心,保重身體 ”,隨著家里那口老鍋的熱氣升騰,就此結束通話,
或許,一歲的我還不知道這意味著什么,但我知道在媽媽懷抱中看著視頻里遠方的爸爸就很快樂,像極了我吃西瓜的甘甜,大一點,我的小學作文里,可能會寫上一句:“這就是家的味道,也是人們在生命里追蹤的情思,恰似這灶火間酸湯魚燃燒的人間喜怒酸甜,正是因為這種味道,媽媽才會愛上爸爸,爸爸也才會追求媽媽,他們都才會愛最可愛的我”,
或許,我童真的世界記不了這些,但爸爸和媽媽會永遠記住我的每一天,愛,在當下,愛,在頃刻間,小珞珞祝大家立冬快樂,

(By:Eastmount 2021-11-08 夜于武漢 http://blog.csdn.net/eastmount/ )
感謝幾位大佬的分享,參考文獻如下:
- https://www.kaggle.com/pestipeti/pytorch-starter-fasterrcnn-train
- https://blog.csdn.net/qq_39071739/article/details/108193935
- https://maoli.blog.csdn.net/article/details/118575041
- https://maoli.blog.csdn.net/article/details/119571695
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/353552.html
標籤:其他
上一篇:NLP之語音轉換
下一篇:影像增強---灰度變換