前言
多模態情感分析是一個新興的研究領域,旨在使機器能夠識別、解釋和表達情感,通過跨模態互動,我們可以得到說話人更全面的情感特征,(BERT)是一種有效的預訓練語言表示模型,然而,以往的研究大多只基于文本資料,如何通過引入多模態資訊來學習更好的表示仍然值得探索,在本文中,我們提出了跨模態的BERT(CM-BERT),它依賴于文本和音頻模態的互動來微調預先訓練好的BERT模型,
作為CM-BERT的核心單元,, masked multimodal attention 通過結合文本資訊和音頻模態資訊來動態調整單詞的權重
貢獻
- 提出了一個跨模態的BERT(CM-BERT)模型,該模型引入了音頻模態的資訊,以幫助文本模態對預先訓練好的BERT模型進行微調,
- 我們設計了一種新型的mask多模態注意(masked multimodal attention),它可以通過兩種注意之間的相互作用動態調整單詞的權重
模型結構
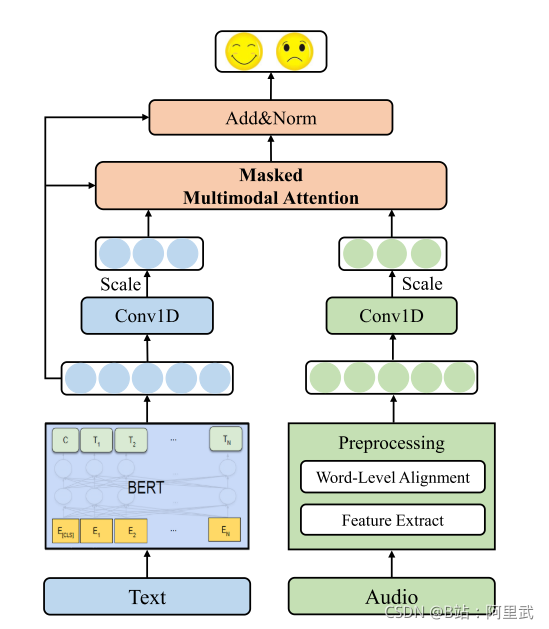
文本方向
- 文本過預訓練BERT 得到 最后一層encoder 的結果 作為文本輸入
- 通過1維卷積 將文本特征維度 進行縮小 , 縮小到和聲音特征維度相同
- 為了防止點集過大 對其進行放縮
聲音方向
- COVAREP 提取 語音特征
- P2FA 進行文本和語言的對齊
- 使用 zero Padding 至 長度文本聲音序列相同
Masked Mulitmodal Attention
- Q 和 K 同源 且 使用Relu 進行算權重
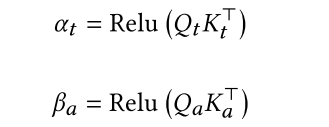
- 通過加權計算出 兩個模態的融合表示
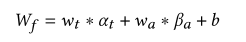
? 其中wt 表示每個單詞的權重 wa 表示 聲音的權重, b表示偏置
- 通過mask機制 解決 sequence padding 問題, solfmax算權重
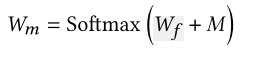
和Transformer里面的attention 是一樣的,
- 將BERT 得到的單詞向量進行加權
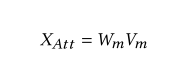
殘差連接和預測
類似 Transformer的 encoder 的結構, 只不過X 表示 原來沒加權的模態
實驗結果
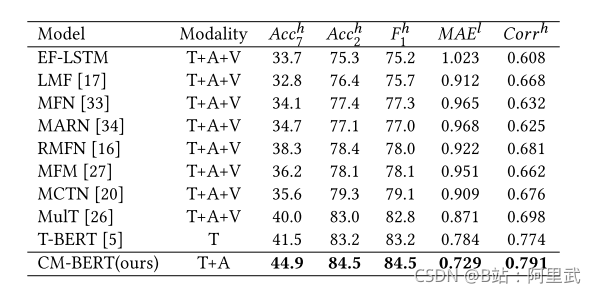
只用兩個模態 效果最好, 有點好用
心得
- attention 機制 基本是一樣的 所謂的mask 是為了去 去除padding 的影響
- 不是跨模態的attention 其中的Q, K 都是相同的 , 本質是self-attention
- 最后的權重是乘以 文本模態,而權重的得來是兩個部分, 其實就相當于 文本模態的 self-attention 然后加上 KV為聲音, Q為文本的attention
- 加權和殘差
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/353727.html
標籤:其他
下一篇:XML“識別”標簽