作者|吳明敏,深度(平潭)科技
小 T 導讀:深度(平潭)科技有限公司是一家 IT 綜合服務提供商,致力于以工業物聯網、大資料、云計算、移動互聯為基礎進行行業軟體研發、解決方案集成及運行維護服務,公司精準把握資訊化發展趨勢,重點布局工業物聯網、智能制造、智慧水務、智慧物流、智慧樓宇,借助新興技術進行融合創新,構架智能化、智慧化的資訊服務支撐平臺,推進中國新型工業化行程,
由邯鋼牽頭的“十三五”水專項“鋼鐵行業水污染全程序控制技術系統集成與綜合應用示范”課題中,我們承擔了“提高水回圈利用的分質/分級供水技術、水系統優化和水網路智慧管理”的研究任務,創新開發了具有自主知識產權的“鋼鐵聯合企業全程序節水減排專家管理系統智慧平臺”,
該專案的初衷是讓其能夠在全國范圍內適用,但是,由于在此程序中會有海量資料產生,資料的實時寫入成為一大難題,同時,多種分析演算法、預警報警條件、報警處理流程、運行日報、綜合統計分析報表可云端動態配置、實時的動態分析計算和歷史大量資料回測在線計算也是新的技術挑戰,在此背景下,如果想要滿足大資料采集計算需求,如何引入高效的分布式實時處理系統,如何設計平臺的計算框架,以及如何選擇適宜的時序資料庫是我們必須要解決的問題,
在 2018 年開始實施這個專案時,可供我們選型的產品并不多,基本上是工業現場的實時資料庫和通用的業務型資料庫,但是工業實時庫擴展能力和資料安全達不到我們的要求,配置上需要配合驅動,這就要求我們要了解一些工業現場協議,成本相對較高;如果使用如 MySQL 一般的通用資料庫,隨著監控點增加,按照時間對表進行水平劃分容易出現資料熱點問題,而按照監測點 hash 取模進行劃分時,擴展又會變得比較困難,
后來,我們也嘗試了 Kafka+Strom+HDFS 這個組合,并且已經完成開發,但是隨著業務的不斷發展,在每天要處理將近一億條資料的情況下:實時和歷史資料的讀取、開發優化、資料一致性、部署運維的成本都變得越來越高,
如何才能以低成本達成高性能?選型迫在眉睫
針對以上業務場景和痛點,我們決定更換資料方案、進行產品選型,并優先對比了物聯網云平臺和時序資料庫,
選型資料量參考如下:
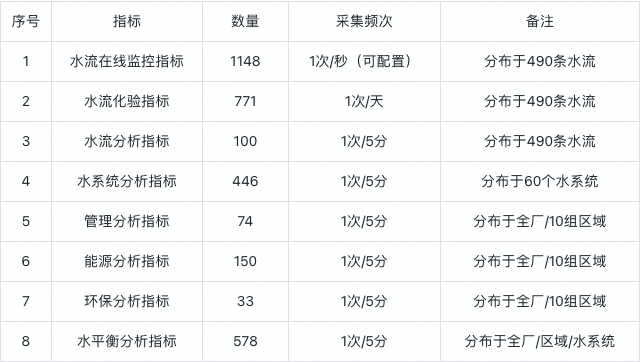
物聯網云平臺的優點是為能夠資料開發者提供一站式服務,有效降低開發門檻、縮短開發周期,其缺點也非常顯著,雖然說在接入以后零代碼更加方便了配置,但前期設備廠商還需要針對平臺介面進行適配就不是很友好了,平臺的費用加上實時流式計算按次收費的方式,成本瞬間提升,此外,在我們的業務中,由于業主要求生產資料不離廠,離線部署成本高、運維難且現場設備多樣協議繁多,還需要定制介面,
其次就是時序資料庫,由于市面上產品種類眾多,我們就從自身的需求出發,對兩款市面流行的時序資料庫進行了相關調研,分別是 InfluxDB 和 TDengine,前者雖然市場占有率相對較高,但非常可惜其社區版集群功能并未開源,不能完全滿足我們的業務需求,而 TDengine 盡管相對比較“年輕”,卻能夠保障在提供高性能的同時也極大降低安裝、部署和維護的成本,此外它還具備如下特點:
- 安裝簡單
- 集群功能開源
- 從時序資料的特點出發,設計了創新的超級表概念
- 具有豐富的函式,還有支持視窗查詢和連續查詢等諸多優勢
經過認真測驗和對比后,最終我們決定將 TDengine 接入到水處理專業化運維系統中進行后期改造,而 TDengine 也沒有辜負我們的期望,幫助我們達成了降本增效的目標,
TDengine 中間性試驗資訊如下表所示:
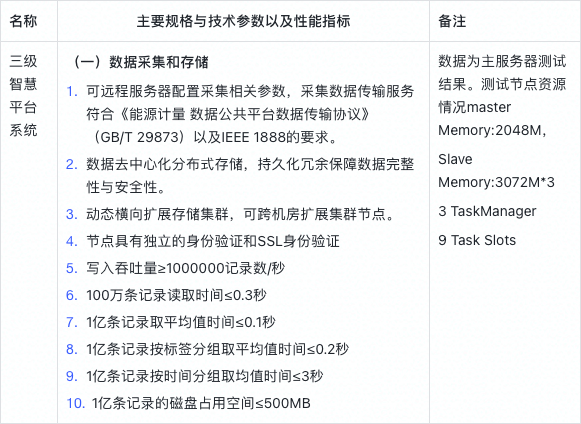
面對海量資料,TDengine 能力如何?
下面我們一起來看一下 TDengine 在業務實踐中的具體表現,
首先我們根據業務型別,創建了 5 張超級表,資料量比較大的兩張表結構如下:

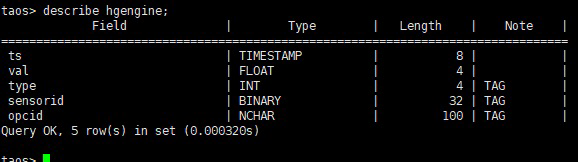
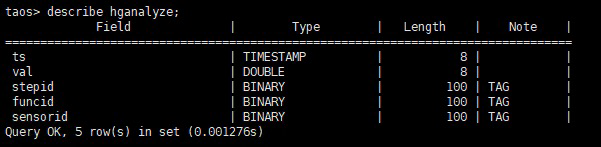
這兩張表的資料量達到了 25 億以上,加上其余超級表后總資料行數大概在 26 億左右,
對超級表 hgengine 查詢所有設備的最新狀態值,TDengine 的耗時是 0.23s,這里不得不提一下,由于我們是 2.0.7 的舊版本,距今已經 1 年之久,很多函式都沒有快取之類的優化,所以性能和新版差距很大,但是由于專案穩定運行很久了,所以就一直都沒有升級到最新版本體驗,十分遺憾,

接下來我們看一下存盤,TDengine 在以上資料量之下(26 億行),占用的磁盤空間其實只有 2.8G,而實際上入庫的原資料大小應為(26 億行,每行包含時間戳列 8 位元組以及 float 和 double 混搭大概 4.2 位元組,總共 317 億位元組)30G 左右,TDengine 的列式存盤壓縮率可以達到驚人的 10%,
但更重要的是,由于 TDengine 的超級表特性,我們還從結構上省下了 26 億行的標簽資料,想象一下如果 hgengine 表的每一行資料都還要帶上這幾個資料(type,sendorid,opcid,合計 436 位元組),那這個表的原本資料量直接就會達到 TB 級別,就算壓縮率再好也要占用百 G 級別的存盤,
所以,TDengine 從根源下手,把設備的靜態資料抽取出來做為子表的一條標簽放在了記憶體中,從根本上就解決了這一物聯網大資料場景下的典型問題,最終,磁盤只用了 2.8G,我們準備的 1.8T 磁盤,目前只用了千分之一,

正是在 TDengine 的強大助力下,我們平臺的整體運作也越來越順滑,取得了以下成效:
① 物聯全程序
基于物聯網,打通資料邊界,打破工具壁壘,將整個鋼鐵園區全程序水系統資訊匯入平臺,集成統一管理,實作全流程一體化管控,
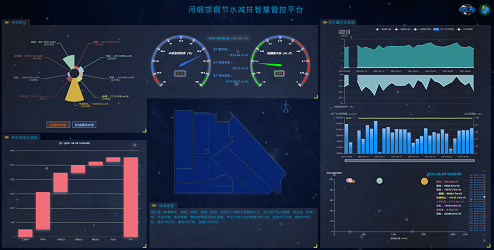
② 生產全監控
實時追蹤水足跡,以水流監控圖的形式對水系統的運行工況進行監控,顯示歷史和實時的運行引數,從而判定各指標是否符合生產工藝要求并進行即時分析及預警報警,實作水資源的智慧化和可視化管理,

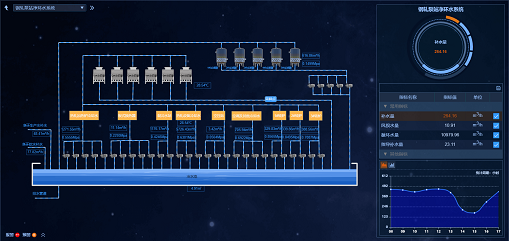
③ 系統全平衡
分析水質水量平衡,以圖表的形式即時顯示全廠、區域、用水單元三級水平衡現狀,從而有效實作水的調度,實作水的高效分質分級回用,
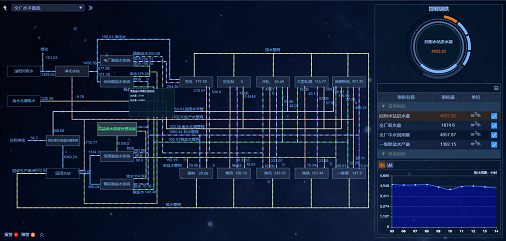
④ 管控全平臺
根據用戶需求自動生成報表與圖表,融合多因子水質水量平衡優化演算法,并內置專家管理模型以及相應知識庫,采用逐步趨近法漸次調節,實作了水系統的智能化運行分析和優化管理,
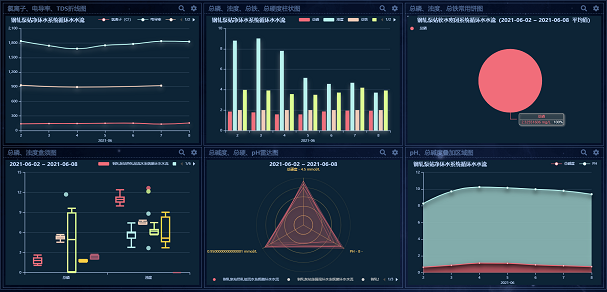
從高效、快捷、精準的特點出發,平臺以全廠、區域、水系統三級管理,涵蓋了鋼鐵生產中各個工序的用排水系統以及水處理、綜合污水處理系統,實作了鋼鐵園區全生命周期水系統運行、能源管理、環保管理、資料統計分析,以及廠區內水平衡調控的智能化、資料化、可視化,在達成這個成就的程序中,TDengine 提供了不小的助力,
寫在最后
在本專案中,TDengine 可以說是量身定做一般,將其強大的性能表現體現得淋漓盡致,監控資料上報后的實時展示、計算分析、歷史回溯都非常快,更優秀的是其學習和運維成本卻并不高,為我們整個專案的完美運作提供了強大助力,未來,希望 TDengine 能夠開發出更多更好的優質特性,也希望我們能夠和 TDengine 展開更多更深層次的合作,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354025.html
標籤:其他
上一篇:sql注入入門--必懂知識點