《Python深度學習》第二章筆記
- 1.第一個神經網路示例
- 2.張量與張量運算
- 張量(輸入網路的資料存盤物件)
- 張量運算(層的組成要素)
- 逐元素運算
- 廣播
- 張量點積
- 張量變形
- 3.神經網路如何通過反向傳播與梯度下降進行學習
- 隨機梯度下降
- 鏈式求導:反向傳播演算法
1.第一個神經網路示例
我們來看一個具體的神經網路示例,使用Python的Keras庫來學習手寫數字分類,
這里要解決的問題是,將手寫數字的灰度影像(28像素x28像素)劃分到10個類別中(0~9),我們將使用MNIST資料集(MNIST資料集預先加載在Keras庫中,包括4個Numpy陣列),它是機器學習領域的一個經典資料集,包含60000張訓練影像和10000張測驗影像,
接下來的作業流程如下:
- 首先,加載Keras中的MNIST資料集,得到訓練集和測驗集,
- 其次,將訓練資料輸入神經網路,
- 然后,網路學習將資料和標簽(資料對應的類別)關聯在一起,
- 最后,網路對輸入的測驗資料生成預測,并驗證這些預測值與真實值是否匹配,
#加載keras中的MNIST資料集
from keras.datasets import mnist
(train_images,train_labels),(test_images,test_labels) = mnist.load_data()
# print(train_images.shape)
# print(len(train_labels))
# print(train_labels)
本例的網路包含2個Dense層,它們是密集連接的神經層,第二層是一個10路的softmax層,它將回傳一個由10個概率值(總和為1)組成的陣列,每個概率值表示當前數字影像屬于10個數字類別中某一個的概率,
Dense層完成的具體操作后續會介紹到,
#搭建網路架構
from keras import models
from keras import layers
network = models.Sequential()
#該網路包含2個Dense層(全連接層)
network.add(layers.Dense(512,activation='relu',input_shape=(28*28,)))
network.add(layers.Dense(10,activation='softmax'))
編譯時需要人為設定的三個引數:
- 損失函式loss
- 優化器optimizer
- 在訓練和測驗程序中需要監控的指標metric
后續兩章會詳細解釋損失函式和優化器的確切用途,
#編譯
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
#準備影像資料
#資料預處理,將unit8型別的影像變換為float32陣列型別
#取值區間[0,255]→[0,1],形狀(60000,28,28)→(60000,28*28)
train_images = train_images.reshape((60000,28*28))
train_image = train_images.astype('float32')/255
test_images = test_images.reshape((60000,28*28))
test_image = test_images.astype('float32')/255
#準備標簽
from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
#訓練模型
#呼叫網路的fit方法,在訓練集上擬合(fit)模型
network.fit(train_images,train_labels,epochs=5,batch_size=128)
#在測驗上驗證
test_loss,test_acc=network.evaluate(test_images,test_labels)
print('test_acc:',test_acc)
模型經過訓練,在訓練集上的精度達到98.9%,而測驗集上的精度為97.8%,比訓練集精度低不少,為什么會這樣呢?
這其實是過擬合造成的,過擬合是指機器學習模型在新資料上的性能往往比在訓練資料上差,這是因為模型過于復雜、迭代次數過多,將訓練集資料學習的太好了,以至于將訓練集單個樣本的細微特點都能捕捉到,并將其學到的分類方法作為“規律”運用在沒有見過的新樣本上,導致分類錯誤,模型泛化能力下降,
2.張量與張量運算
前面例子使用的資料存盤在多維Numpy陣列中,也叫張量(tensor),
張量這一概念的核心在于,它是一個資料容器,它包含的資料幾乎總是數值資料,它是數字的容器,張量的維度(dimension)通常叫作軸(axis),張量軸的個數也叫作階(rank),
張量(輸入網路的資料存盤物件)
- 標量(0D張量):僅包含一個數字的張量,標量有0個軸(ndim==0),一個數字就是一個標量,例如
import numpy as np
x=np.array(12)#x是一個標量,x.ndim=0
- 向量(1D張量):數字組成的陣列,向量只有1個軸,例如
x=np.array([12,3,6,14,7])#x是一個向量,x.ndim=1
這個向量有5個元素,所以又稱為5D向量,注意5D向量≠5D張量,
- 矩陣(2D張量):向量組成的陣列,矩陣有2個軸(通常叫作行和列),第一個軸上的元素叫行,第二個軸上的元素叫列,例如
x=np.array([5,78,2,34,0],
[6,79,3,35,1],
[7,80,4,36,2])#x是矩陣,x.ndim=2
- 3D張量與更高維張量
3D張量可以直觀理解為數字組成的立方體,將多個3D張量組合成陣列,可以創建4D張量,以此類推,深度學習處理的一般是0D到4D的張量,但處理視頻時可能會遇到5D張量,
張量具有以下三個關鍵屬性:
- 軸的個數(ndim):例如3D張量有3個軸,矩陣有2個,
- 形狀(shape):表示張量沿每個軸的元素個數(維度大小),是一個整元陣列,例如標量的形狀為空();向量的形狀(5,);矩陣的形狀(3,5),
- 資料型別(dtype):張量中所包含資料的型別,注意Numpy(以及大多數庫)中不存在字符型張量,
在前面的例子中,我們可以使用語法train_images[i]來選擇沿著第一個軸的特定數字,選擇張量的特定元素叫作張量切片,
張量運算(層的組成要素)
深度神經網路學到的所有變換都可以簡化為數值資料張量上的一些張量運算,
在最開始的例子中,我們通過疊加Dense層來構建網路,
keras.layers.Dense(512,activation='relu')
#relu(dot(W,input)+b)
這個層可以理解為一個激活函式relu,輸入一個2D張量,回傳另一個2D張量,即輸入張量的新表示,
激活函式relu(dot(W,input)+b)中的w是一個2D張量,b是一個向量,這里有三個張量運算:輸入張量和張量w之間的點積(dot)、得到的2D張量與向量b之間的加法運算、最后的relu運算,relu(x)是max(x,0),
關于激活函式relu的介紹,可以學習以下鏈接:
https://www.jianshu.com/p/338afb1389c9
簡言之,激活函式能幫助我們引入非線性因素,使得神經網路能夠更好地解決更加復雜的問題,
逐元素運算
relu運算和加法都是逐元素運算,即該運算獨立地應用于張量中的每個元素,
import numpy as np
z = x + y #逐元素的相加
z = np.maximum(z, 0.) #逐元素的 relu
#這里的maximum函式作用是X和Y逐位進行比較,選擇最大值,最少接受兩個引數
廣播
上述逐元素運算僅支持兩個形狀相同的2D張量相加,如果將兩個形狀不同的張量相加,例如前面說到的Dense層中2D張量與向量相加,會發生什么?
如果沒有歧義的話,較小的張量會被廣播,以匹配較大張量的形狀,廣播包含以下兩步:
- 向較小的張量添加軸(叫作廣播軸),使其 ndim 與較大的張量相同,
- 將較小的張量沿著新軸重復,使其形狀與較大的張量相同,
來看一個具體的例子,假設 X 的形狀是 (32, 10),y 的形狀是 (10,),首先,我們給 y添加空的第一個軸,這樣 y 的形狀變為 (1, 10),然后,我們將 y 沿著新軸重復 32 次,這樣 得到的張量 Y 的形狀為 (32, 10),現在, 我們可以將 X 和 Y 相加,因為它們的形狀相同,
在實際的實作程序中并不會創建新的2D張量,因為那樣做非常低效,重復的操作完全是虛擬的,它只出現在演算法中,而沒有發生在記憶體中,
下面這個例子利用廣播將逐元素的maximum運算應用于兩個形狀不同的張量:
import numpy as np
x = np.random.random((64,3,32,10))#隨機張量(64,3,32,10)
y = np.random.random((32,10))
z = np.maximum(x,y)#輸出z的形狀是(64,3,32,10),與x形狀相同
張量點積
點積(dot)運算,也叫張量積,與逐元素的運算不同,它將輸入張量的元素合并在一起,
import numpy as np
z=np.dot(x,y)
- 兩個向量之間的點積結果是一個標量,且只有元素個數相同的向量之間才能做點積,
- 你還可以對一個矩陣和一個向量做點積,回傳值是一個向量,其中每個元素是y和x的每一行之間的點積,
- 最常見的應用是兩個矩陣之間的點積, 對于兩個矩陣 x 和 y,當且僅當 x.shape[1] == y.shape[0] 時,你才可以對它們做點積(dot(x, y)),得到的結果是一個形狀為 (x.shape[0], y.shape[1]) 的矩陣,
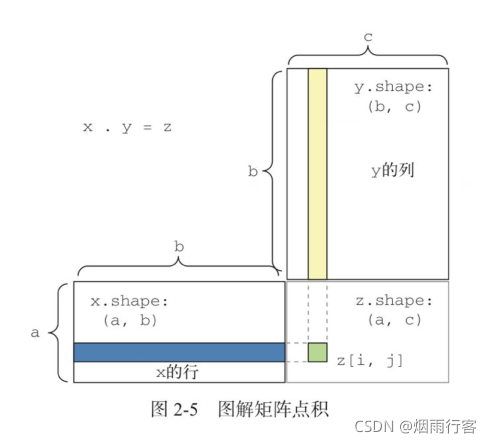 圖2-5中,x、y和z都用矩形表示,x的行必須和y的列大小相同,
圖2-5中,x、y和z都用矩形表示,x的行必須和y的列大小相同,
更一般地說,你可以對更高維的張量做點積,只要其形狀匹配遵循與前面 2D 張量相同的原則:
(a, b, c, d) . (d,) -> (a, b, c)
(a, b, c, d) . (d, e) -> (a, b, c, e)
注意:如果兩個張量中有一個的ndim大于1,那么dot運算就不再是對稱的,dot(x,y)不等于dot(y,x),
張量變形
雖然前面神經網路第一個例子的Dense層中沒有用到它,但在將影像資料輸入神經網路之前,我們在預處理時用到了這個運算,
train_images=train_images.reshape((60000,28*28))
張量變形是改變張量的行和列,以得到想要的形狀,變形后的張量的元素總個數與初始張量相同,
一種特殊的張量變形是轉置,
x=np.zeros((300,20))
x=np.transpose(x)
3.神經網路如何通過反向傳播與梯度下降進行學習
我們的第一個神經網路示例中,每個神經層都用下述方法對輸入資料進行變換,
output = relu(dot(W, input) + b)
在這個運算式中,w和b都是張量,被稱為該層的權重或可訓練引數,分別對應kernal和bias屬性,
一開始,這些權重矩陣取較小的隨機值,這一步叫作隨機初始化,下一步則是根據反饋信號調節這些權重,
上述程序發生在一個訓練回圈內,
- 提取資料:抽取訓練樣本 x 和對應目標 y 組成的資料批量,
- 前向傳播:在 x 上運行網路(這一步叫作前向傳播(forward pass)),得到預測值 y_pred,
- 計算損失:計算網路在這批資料上的損失,用于衡量 y_pred 和 y 之間的距離,
- 反向傳播:更新網路的所有權重,使網路在這批資料上的損失略微下降,
降低損失可以使用梯度下降的方法,
梯度是張量運算的導數,多元函式是以張量作為輸入的函式,
假設網路中所有運算都是可微的,有一個輸入向量x、一個矩陣w、一個目標y和一個損失函式loss,你可以用w來計算預測值y_pred,然后計算損失,或者說預測值y_pred和目標y之間的距離,
y_pred = dot (w,x)#預測值
loss_value = loss(y_pred, y)#預測值和目標值之間的距離
如果輸入資料x和y保持不變,那么這可以看作將w映射到損失值的函式,
loss_value = f(w)
假設w的當前值為w0,f在w0點的導數是一個張量gradient(f)(w0),其形狀與w相同,張量gradient (f) (w0)是函式f(w) = loss_value在w0的導數,
對于一個函式f(x),你可以通過將x向導數的反方向移動一小步來減小f(x)的值,同樣,對于張量的函式f(w),你也可以通過將w向梯度的反方向移動來減小f(w),比如w1 = w0 - step *gradient (f)(w0),其中step是一個很小的比例因子,又叫學習率,也就是說,沿著曲率的反方向移動,直觀上來看在曲線上的位置會更低,
注意,step是人為設定的,范圍為0~1,剛開始訓練時學習率以 0.01 ~ 0.001 為宜,這是為了防止步長太長而錯過損失函式loss的最低點,
隨機梯度下降
隨機梯度中的隨機是什么意思?
術語隨機(stochastic)是指每批資料都是隨機抽取的,
- 小批量隨機梯度下降(SGD)是每次抽取批量資料,
小批量隨機梯度下降:
(1)抽取訓練樣本x和對應目標y組成的資料批量,
(2)在x上運行網路,得到預測值y_pred,
(3)計算網路在這批資料上的損失,用于衡量y_pred和y之間的距離,
(4)計算損失相對于網路引數的梯度(一次反向傳播)
(5)將引數沿著梯度的反方向移動一點,比如w -= step * gradient,從而使這批資料上的損失減小一點, - 真 SGD(有別于小批量 SGD)是小批量SGD 演算法的一個變體,是每次迭代時只抽取一個樣本和目標,而不是抽取一批資料,
- 還有另一種極端,每一次迭代都在所有資料上 運行,這叫作批量 SGD,這樣做的話,每次更新都更加準確,但計算代價也高得多,
SGD還有很多變體,其區別在于計算下一次權重更新時還要考慮上一次權重更新,而不是僅僅考慮當前梯度值,比如帶動量的變體,
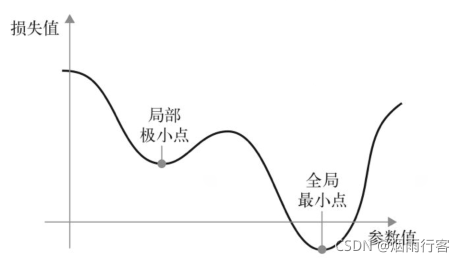
動量解決了SGD的兩個問題:收斂速度和區域極小點,動量方法的實作程序是每一步更新w不僅要考慮當前的梯度值,還要考慮上一次引數的更新,如圖所示,在某個引數值附近,有一個區域極小點,使用動量的方法可以避免陷入區域極小點,
鏈式求導:反向傳播演算法
在前面的演算法中,我們假設函式是可微的,因此可以明確計算其導數,在實踐中,神經網路函式包含許多連接在一起的張量運算,每個運算都有簡單的、已知的導數,例如,下面這個網路f包含3個張量運算a、b和c,還有3個權重矩陣w1、w2和 w3,
f(w1,w2,w3) = a(w1,b(W2,c(W3)))
根據微積分的知識,這種函式鏈可以利用下面這個恒等式進行求導,它稱為鏈式法則:
(f(g(x) ) ) ’ = f '(g(x)) * g '(x)
將鏈式法則應用于神經網路梯度值的計算,得到的演算法叫作反向傳播( backpropagation),反向傳播從最終損失值開始,從最頂層反向作用至最底層,利用鏈式法則計算每個引數對損失值的貢獻大小,
反向傳播演算法原理:
https://www.jianshu.com/p/964345dddb70
現在,你應該對神經網路背后的原理有了大致的了解,可以回頭再看一下第一個例子,重新閱讀每一段代碼,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354501.html
標籤:AI
上一篇:線性回歸——實驗