文章目錄
- RoIAlign 的用處
- RoIAlign 計算原理
- 雙線性插值(Bilinear Interpolation)
- pytorch中的實作
- 簡單示例
- 在FasterRCNN中的使用示例
- 參考鏈接
RoIAlign 的用處
RoIAlign 用于將任意尺寸感興趣區域的特征圖,都轉換為具有固定尺寸 H×W 的小特征圖,
與RoI pooling一樣,其基本原理是將 h × w h×w h×w 的特征劃分為 H × W H×W H×W 網格,每個格子是大小近似為 h / H × w / W h/H×w/W h/H×w/W 的子視窗 ,然后將每個子視窗中的值最大池化到相應的輸出網格單元中,想復習RoI pooling概念的可以看這篇,
RoIAlign 其實就是更精確版本的 RoIPooling,用雙線性插值取代了RoIPooling中的直接取整的操作,
下面用一個具體圖例看下 RoIAlign 計算原理,
RoIAlign 計算原理
輸入一個feature map,對于每個不同尺寸的proposed region,需要轉換成固定大小
H
×
W
H×W
H×W的 feature map,H和W是這一層的超引數,
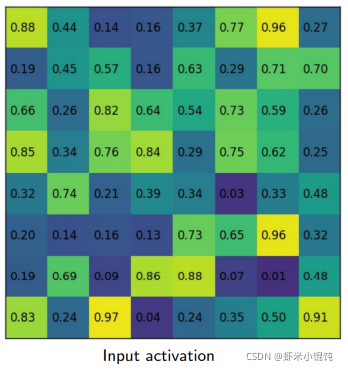
黑色粗框部分是一個
7
×
5
7×5
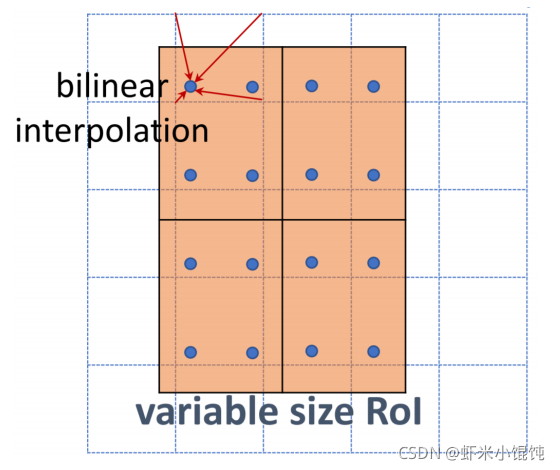
7×5 大小的 proposed region,首先切分成
H
×
W
H×W
H×W 個sections(這里以2x2為例):
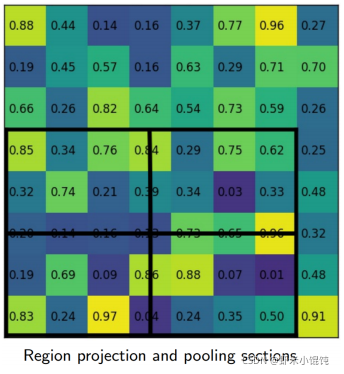
對每個section采樣四個區域,用紅色×表示其中心位置:
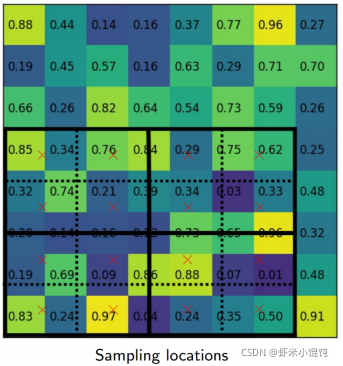
每個section中四個紅色×的值,由雙線性插值計算:
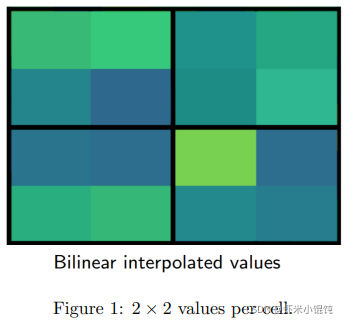
對每個 section 中四個值進行 max pooling,輸出結果:
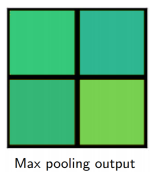
就是我們所需要的固定大小輸出了,
這個固定大小輸出可以通過全連接的層,用于邊界框回歸和分類,常用于檢測和分割模型中,
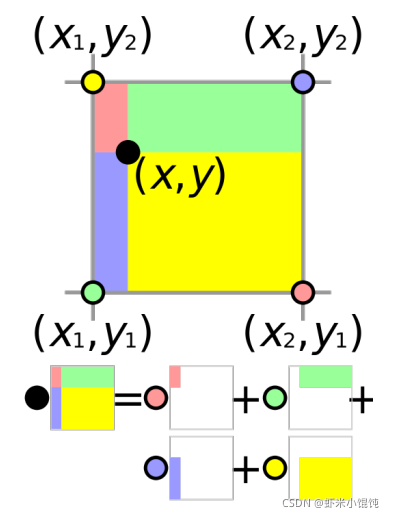
雙線性插值(Bilinear Interpolation)
借用下圖從視覺上來理解雙線性插值,黑點上的雙線期插值是附近四個點的加權和,權值是四個點對應的顏色矩形在總面積中的占比,比如左上角黃點
(
x
1
,
y
2
)
(x_1,y_2)
(x1?,y2?) 對應的是右下較大的黃色矩陣面積,
pytorch中的實作
RoIAlign在pytorch中的實作是torchvision.ops.RoIAlign,torchvision.ops中實作的是計算機視覺中特定的operators,
class: torchvision.ops.RoIAlign(output_size, spatial_scale, sampling_ratio)
- output_size (int or Tuple[int, int]) – 輸出大小,用 (height, width) 表示,
- spatial_scale (float) – 將輸入坐標映射到框坐標的比例因子,默認值1.0,
- sampling_ratio (int) – 插值網格中用于計算每個合并輸出bin的輸出值的采樣點數目,如果> 0,則恰好使用sampling_ratio x sampling_ratio網格點,如果<= 0,則使用自適應數量的網格點(計算為cell (roi_width / pooled_w),同樣計算高度),默認值1,
torchvision.ops.roi_align(input, boxes, output_size, spatial_scale=1.0, sampling_ratio=-1)
- input (Tensor[N, C, H, W]) – 輸入張量
- boxes (Tensor[K, 5] or List[Tensor[L, 4]]) – 區域包圍框以 ( x 1 , y 1 , x 2 , y 2 ) (x1, y1, x2, y2) (x1,y1,x2,y2) 形式表示,如果輸入的是單個tensor,第一串列示batch index;如果輸入是一個tensor List,每個tensor對應batch中的第 i i i個元素的方框,
簡單示例
import torch
import torchvision
# 創建RoIAlign層
pooler = torchvision.ops.RoIAlign(output_size=2,sampling_ratio=2,spatial_scale=5)
# 輸入一個 8x8 的feature:
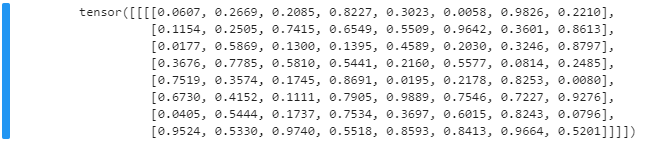
inputTensor = torch.rand(1,1,8,8)
inputTensor類似如下:
再創建一個box:
box = torch.tensor([[0.0,0.375,0.875,0.625]])
output = pooler(inputTensor,[box])#shape:[1, 1, 2, 2]
輸出結果:

在FasterRCNN中的使用示例
import torchvision
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# load a pre-trained model for classification and return
# only the features
backbone = torchvision.models.mobilenet_v2(pretrained=True).features
# FasterRCNN needs to know the number of
# output channels in a backbone. For mobilenet_v2, it's 1280
# so we need to add it here
backbone.out_channels = 1280
# let's make the RPN generate 5 x 3 anchors per spatial
# location, with 5 different sizes and 3 different aspect
# ratios. We have a Tuple[Tuple[int]] because each feature
# map could potentially have different sizes and
# aspect ratios
anchor_generator = AnchorGenerator(sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),))
# let's define what are the feature maps that we will
# use to perform the region of interest cropping, as well as
# the size of the crop after rescaling.
# if your backbone returns a Tensor, featmap_names is expected to
# be [0]. More generally, the backbone should return an
# OrderedDict[Tensor], and in featmap_names you can choose which
# feature maps to use.
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'],
output_size=7,
sampling_ratio=2)
# put the pieces together inside a FasterRCNN model
model = FasterRCNN(backbone,
num_classes=2,
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler)
參考鏈接
https://zhuanlan.zhihu.com/p/59692298
https://zhuanlan.zhihu.com/p/73138740
https://pytorch.org/docs/1.2.0/torchvision/ops.html
https://pytorch.org/docs/1.2.0/_modules/torchvision/ops/roi_align.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354503.html
標籤:AI