Locally Differential Private Frequency Estimation with Consistency
目錄
- Locally Differential Private Frequency Estimation with Consistency
- 1. INTRODUCTION
- 國內外研究現狀:
- 利用先驗知識引入bias偏差
- 實驗
- 2. PROBLEM SETTING
- 3. FREQUENCY ORACLE PROYOCOLS
- 3.1 Generalized Random Response ——GRR
- 3.2 Optimized Local Hashing OLH
- 3.3 Accuracy
- 💜4. TOWARDS CONSISTENT FREQUENCY ORACLES
- Base
- 4.1 Baseline Methods
- 4.1.1 Base-Pos
- 4.1.2 Post-Pos
- 4.1.3 Base-Cut
- 閾值公式
- 方法評價
- 4.2 Normalization Method
- 4.2.1 Norm
- 4.2.2 Norm-Mul
- 4.2.3 Norm-Sub
- 4.2.4 Norm-Cut
- 4.3 Constrained Least Squares
- 通過KKT求得最優解程序如下
- Norm-Sub 就是 CLS公式的解
- 4.4 Maximum Likelihood Estimation
- 4.4.1 MLE-Apx
- 4.5 Least Expected Square Error
- 4.5.1 Power
- 4.5.2 PowerNS
- 4.6 Summary
- 5. EVALUATION
- 5.1 Experimental Setup
- 資料集
- 度量方法
- 5.2 Bias-variance Evaluation
- Figure 1
- Figure 2
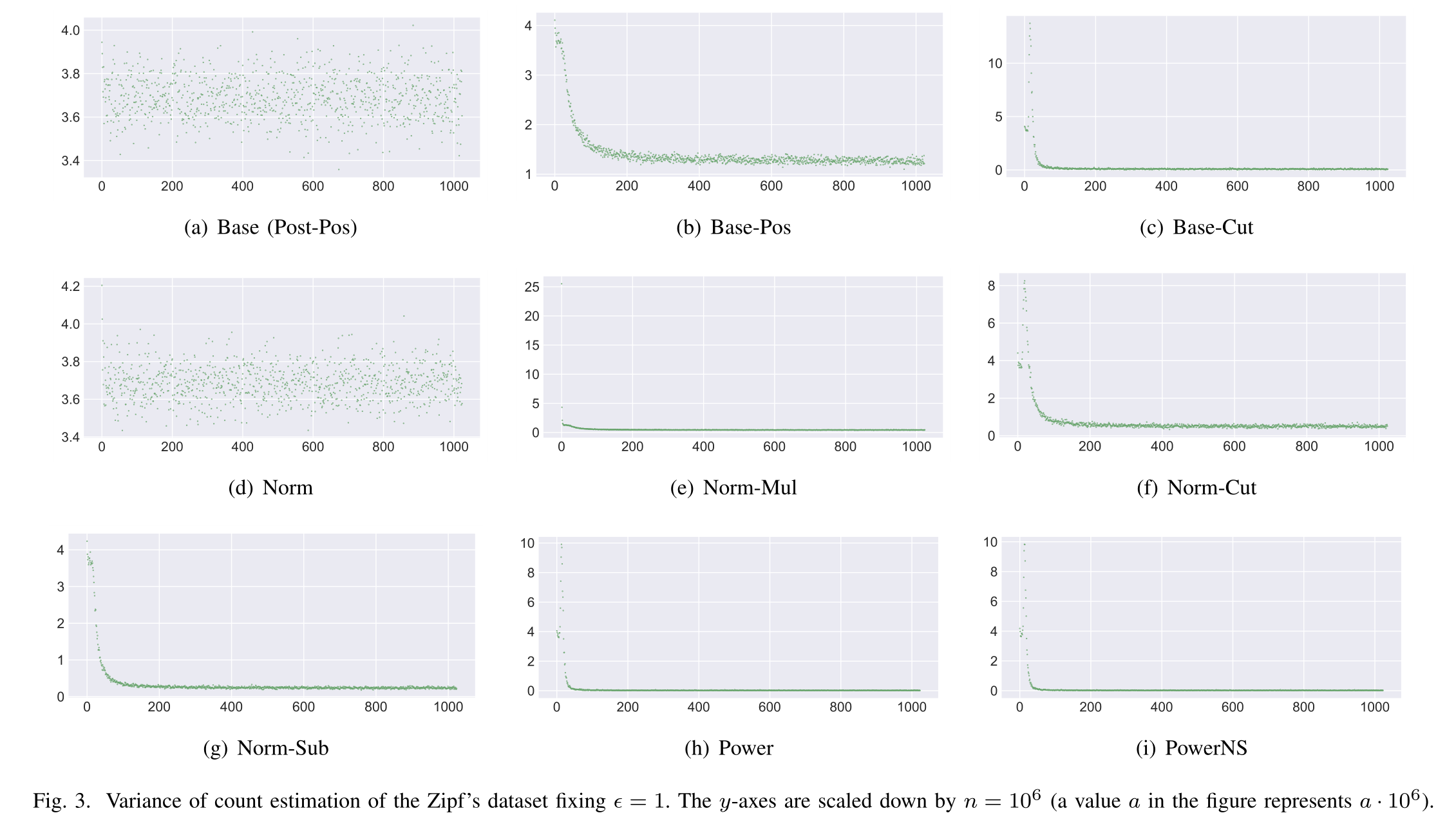
- Figure 3
- 5.3 Full domain Evaluation
- 5.4 Set-value Evaluation
- 5.5 Frequent-value Evaluation
- 5.6 Discussion
- 6. RELATED WORK
- 7. CONCLUSION
論文鏈接.
論文主要內容
已知:在頻率估計(Frequency Oracle - FO)中所有值的頻率均為非負,并且所有頻率總和為1
利用已知知識,在FO協議中添加一個后處理步驟 Post-Processing ,可以顯著提高(包括單個值的頻率、頻繁項的頻率以及子集的頻率)等各類任務的準確率
1. INTRODUCTION
國內外研究現狀:
-
現有的FO協議被設計為:最小化方差的同時,提供對單個值的無偏估計,但,它們在某些任務中表現不佳
-
現有的FO協議并沒有很好的利用任何關于要估計的分布的先驗知識
先驗知識:1)所有值的頻率均為非負,2)所有頻率總和為1
利用先驗知識引入bias偏差
在利用這些先驗知識的時候,會給最終的估計結果引入bias 偏差
- 例:施加非負約束,則導致了最終估計引入了positive bias的副作用,這些bias會導致一些的查詢結更不準確
- 提高了對單個值頻率估計的準確性
- 但是,范圍查詢(子集)中引入的positive bias越來越多,子集的頻率的準確性可能會降低
實驗
- 實驗設定
- 10種方法:不同的利用先驗知識方法
- 3個任務
- 單個值的頻率 query the frequency of every value in the domain
- 頻繁項的頻率 query the frequencies of the most frequent values
- 子集的頻率 query the aggregate frequencies of subsets of values
- 實驗結果:沒有一種方法在所有任務中都優于其他方法
- 只使用先驗知識1),對單個值的頻率估計任務表現最好
- 只使用先驗知識2),對頻繁項頻率估計的任務表現最好
- 結合使用先驗知識1和先驗知識2,對子集的頻率估計任務表現最好
2. PROBLEM SETTING
略
3. FREQUENCY ORACLE PROYOCOLS
使用pure protocol來表示FO協議
f
~
(
v
)
=
I
v
/
n
?
q
?
p
?
?
q
?
\widetilde{f}(v)=\frac{I_v/n-q^*}{p^*-q^*}
f
?(v)=p??q?Iv?/n?q??
f
~
是
\widetilde{f}是
f
?是 無偏估計,其方差為
σ
v
2
=
q
?
(
1
?
q
?
)
n
(
p
?
?
q
?
)
2
+
f
v
(
1
?
p
?
?
q
?
)
n
(
p
?
?
q
?
)
\sigma_v^2=\frac{ q^*(1-q^*)}{n(p^*-q^*)^2}+\frac{f_v(1-p^*-q^*)}{n(p^*-q^*)}
σv2?=n(p??q?)2q?(1?q?)?+n(p??q?)fv?(1?p??q?)?
方差推理程序見下圖:
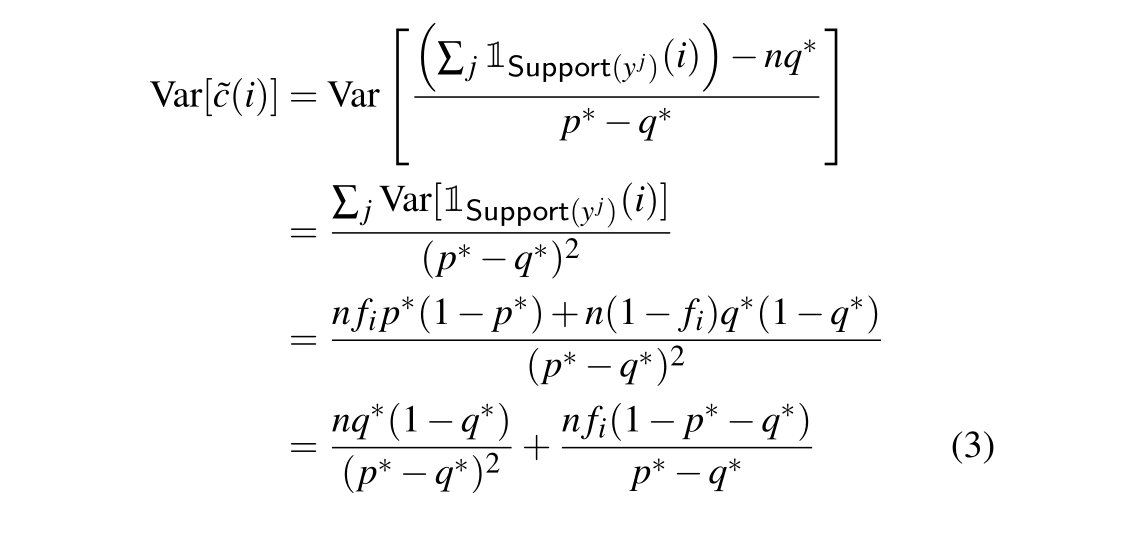
3.1 Generalized Random Response ——GRR

f ~ ( v ) = I v / n ? q ? p ? ? q ? = I v / n ? 1 e ε + d ? 1 e ε ? 1 e ε + d ? 1 \widetilde{f}(v)=\frac{I_v/n-q^*}{p^*-q^*}=\frac{I_v/n-\frac{1}{e^{\varepsilon}+d-1}}{\frac{e^{\varepsilon}-1}{e^{\varepsilon}+d-1}} f ?(v)=p??q?Iv?/n?q??=eε+d?1eε?1?Iv?/n?eε+d?11??
3.2 Optimized Local Hashing OLH
在OLH中,在Encoding和Perturbe步驟中都會有資訊損失,而引數d的選擇則是這兩個步驟的資訊損失之間的權衡,當g=eε+1(或最接近的整數),方差
f ~ ( v ) = I v / n ? q ? p ? ? q ? = I v / n ? 1 g p ? ? 1 g \widetilde{f}(v)=\frac{I_v/n-q^*}{p^*-q^*}=\frac{I_v/n-\frac{1}{g}}{p^*-\frac{1}{g}} f ?(v)=p??q?Iv?/n?q??=p??g1?Iv?/n?g1??
3.3 Accuracy
參考論文
Calibrate: Frequency Estimation and Heavy Hitter Identification with Local Differential Privacy via Incorporating Prior Knowledge閱讀筆記
論文鏈接.
由于cv服從Binomial分布,通過中心極限定理得: f ~ v ≈ f v + N ( 0 , σ v ) \widetilde{f}_v \approx f_v+\mathcal{N}(0,\sigma_v) f ?v?≈fv?+N(0,σv?)
當d較大,而ε不是特別大得時候,可以通過忽略fv得到下式:
σ
2
≈
q
?
(
1
?
q
?
)
n
(
p
?
?
q
?
)
2
f
~
v
≈
f
v
+
N
(
0
,
σ
)
\sigma^2 \approx \frac{q^*(1-q^*)}{n(p^*-q^*)^2} \\ \widetilde{f}_v \approx f_v + \mathcal{N}(0,\sigma)
σ2≈n(p??q?)2q?(1?q?)?f
?v?≈fv?+N(0,σ)
💜4. TOWARDS CONSISTENT FREQUENCY ORACLES
Base
不做 post-processing,沒有偏差,方差可以通過理論計算
4.1 Baseline Methods
4.1.1 Base-Pos
在執行FO協議后,將所有負頻率估計都轉化為0
-
減少了方差:通過把錯誤的負值轉化為0,更加接近真實值
-
Base-Pos引入了 positive bias 正偏差:一些負偏差通過這個程序消除,而正偏差沒有被去除
Lemma1
所有的值v 經過Base-Pos都引入了正偏差
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-EuDle974-1636380936690)(C:/Users/CLOUDNESS/AppData/Roaming/Typora/typora-user-images/image-20211102195537086.png)]
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-8UiZhqIT-1636380936691)(C:/Users/CLOUDNESS/AppData/Roaming/Typora/typora-user-images/image-20211102195545352.png)]
p o s i t i v e b i a s = E [ f v ’ ] ? f v > 0 positive\ bias =E[f^{’}_v]-f_v>0 positive bias=E[fv’?]?fv?>0
4.1.2 Post-Pos
對于每個查詢(query:這里可以是單個值的頻率、頻繁項的頻率以及子集的頻率)結果,如果是負值,則轉化為0
-
**v.s. Base-Pos :**不對估計的分布進行后處理,而是分別對每個查詢結果進行后處理
當query為查詢單個值的頻率的時候 等價 Base-Pos
-
當query為查詢子集的頻率,
- 由于結果通常大于0,所以與Base相似
- 引入的偏差要比Base-Pos來的小
- 可能會給出不一致inconsistency的結果,A∪B的頻率 ≠ A + B的頻率
4.1.3 Base-Cut
在執行FO協議后,將所有小于敏感度閾值的頻率估計都轉化為0
- 最初設計目標:恢復頻繁項的頻率值,所以只有高于閾值的估計才會被考慮
閾值公式
T = F ? 1 ( 1 ? α d ) σ T=F^{-1}(1-\frac{\alpha}{d})\sigma T=F?1(1?dα?)σ
d:域大小
F-1(x):是標準正態分布的累計函式的反函式
σ:LDP機制的標準差
α:控制低頻但頻率估計高于閾值的項的數量,
α引數的選擇是在false positive和false negatives 之間進行的權衡
對于一個真實頻率為0的值,其經過FO協議后的頻率估計大于T的概率至多為 α/d

已知一個頻率估計大于T,則這個值的真實頻率為0的概率至多為 d × α / d = α d \times \alpha/d = \alpha d×α/d=α
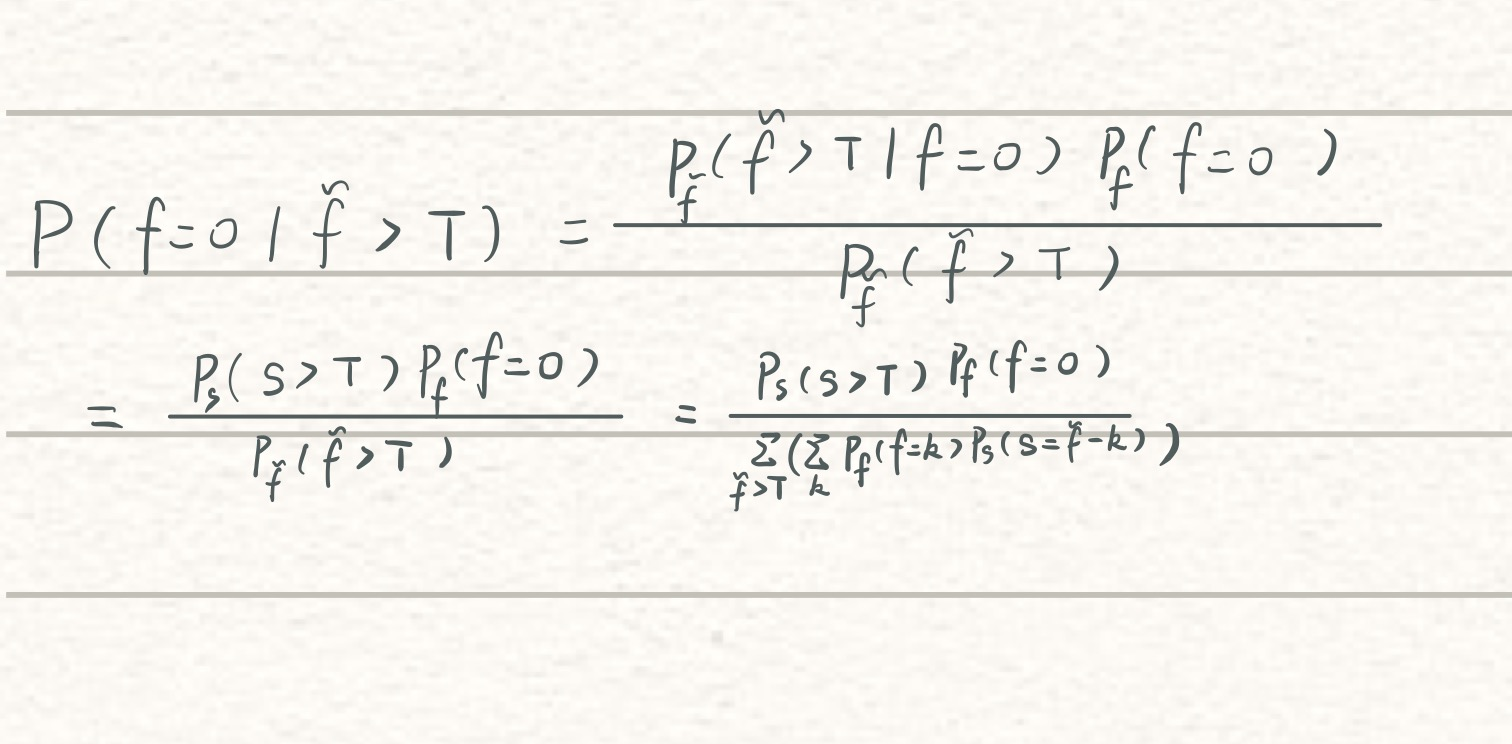
- α越大,1-α/d越小,即密度概率曲線下面積越小,則T越小
- α引數的選擇是在false positive和false negatives 之間進行的權衡
- 常規統計學中設定,α=5%,在實驗中表現不好,是因為當d和ε不是特別大時,這個閾值T太大了
- 本文中設定α=2,如果由20個項的頻率估計>T,則true positive : false positive = 10: 1
方法評價
- 確保頻率估計無負值,不確保頻率估計總和為1
- 經過Base-Cut的頻率估計,要么較高(大于T),要么為0
- 對于每個非零的頻率估計值,都會收到兩種方向偏差的作用力
- negative bias effect: 當估計值被削減到0
- positive bias effect: 當較大的噪聲導致估計值高于閾值,所得的估計值高于真實頻率
4.2 Normalization Method
通過歸一化方法,確保整個域的頻率估計和為1
Lemma 2
通過歸一化方法調整無偏估計,使得頻率估計的和為1,那么整個域引入的偏差和也為0
4.2.1 Norm
在執行FO協議后,給每個頻率估計加上δ,以實作總和為1
-
該方法不強制要求非負性
-
對于GRR、Hadamard Response 和Subset Selection這個方法沒有意義,因為這些協議的估計總和已經為1
-
對于OLH,協議總和不再為1
For OLH, however, each user reports a randomly selected subset whose size is a random variable, and Norm would change the estimations.
Lemma 3
Norm 為每一個值提供無偏估計
-
已知 根據Norm 的定義有: ∑ v ∈ D f v ‘ = ∑ v ∈ D f ~ v + δ \sum_{v\in D}f^‘_v=\sum_{v \in D}\widetilde{f}_v+\delta ∑v∈D?fv‘?=∑v∈D?f ?v?+δ 根據FO協議的輸出是無偏估計有: E ( f ~ v ) = f V E(\widetilde{f}_v)=f_V E(f ?v?)=fV?
-
易混淆 FO協議無偏只代表其分布的均值為fv,不代表一次實體就是fv; 同理,FO協議無偏,表示其估計的和的均值為1,但本身可能不為1
-
證明

Lemma 4
通過歸一化方法調整無偏估計,使得頻率估計的和為1的同時所有值非負,那么會對接近0的值引入正偏差
證明:對于一些足夠接近0的值,其存在估計為正的可能性,也存在估計為負的可能性,但經過歸一化方法后,只能為正,所以引入了一個 positive bias
引理4說明:任何同時滿足下圖兩個約束的方法引入的偏差都不能全為0

4.2.2 Norm-Mul
在執行FO協議后,將所有負頻率估計都轉化為0,再給每個頻率估計乘以一個乘數因子γ,以實作總和為1
∑
v
∈
D
m
a
x
(
γ
×
f
~
v
,
0
)
=
1
\sum_{v\in D}max(\gamma \times \widetilde{f}_v,0)=1
v∈D∑?max(γ×f
?v?,0)=1
f v ‘ = m a x ( γ × f ~ v , 0 ) f^‘_v=max(\gamma \times \widetilde{f}_v,0) fv‘?=max(γ×f ?v?,0)
- 該方法在比較 平滑 的資料上表現更好,對于分布不對稱的方法(往往是LDP感興趣的),表現得很差
- 該方法針對低頻項引入 positive bias, 針對高頻項引入 negative positive, 且一個值的真實頻率越高,引入的 negative bias 越大
- 原因:γ的值通常在[0,1]范圍內,則頻率越高,削減的值越多
4.2.3 Norm-Sub
在執行FO協議后,給所有頻率加上δ,再將所有負值都轉化為0,以實作總和為1
∑
v
∈
D
m
a
x
(
δ
+
f
~
v
,
0
)
=
1
\sum_{v\in D}max(\delta + \widetilde{f}_v,0)=1
v∈D∑?max(δ+f
?v?,0)=1
f v ‘ = m a x ( δ + f ~ v , 0 ) f^‘_v=max(\delta + \widetilde{f}_v,0) fv‘?=max(δ+f ?v?,0)
- 該方法針對低頻項引入 positive bias, 針對高頻項引入 negative bias
- 但是相較 Norm-Mul 其bias 的分布要更加均勻
4.2.4 Norm-Cut
在執行FO協議后,將所有的負值和較小的正值都轉化為0,以實作總和為1
-
在Norm-Sub中,高頻項有較高的negative bias,=》解決思路:講較低的正值轉化為0
-
Norm-Cut后處理的兩種情況
-
∑ v ∈ D m a x ( f ~ v , 0 ) ≤ 1 \sum_{v \in D}max(\widetilde{f}_v,0)\le1 ∑v∈D?max(f ?v?,0)≤1, 簡單將每個負值轉化為0
-
∑ v ∈ D m a x ( f ~ v , 0 ) > 1 \sum_{v \in D}max(\widetilde{f}_v,0) > 1 ∑v∈D?max(f ?v?,0)>1,找到一個值 θ \theta θ使得大于 θ \theta θ的值的和小于等于1,即 ∑ v ∈ D ∣ f ~ v > θ f ~ v ≤ 1 \sum_{v \in D|\widetilde{f}_v>\theta}\widetilde{f}_v\le1 ∑v∈D∣f ?v?>θ?f ?v?≤1
f ‘ = 0 , f ~ v < θ f ‘ = f ~ v , f ~ v ≥ θ f^‘=0,\ \ \widetilde{f}_v<\theta\\ f^‘=\widetilde{f}_v,\ \ \widetilde{f}_v \ge \theta f‘=0, f ?v?<θf‘=f ?v?, f ?v?≥θ
-
-
v.s. Base-Cut
閾值的選擇方法不同,Norm-Cut可能產生 頻率估計的和小于1的結果
4.3 Constrained Least Squares
**CLS:**在執行FO協議后,使用帶有約束條件的最小二乘法來恢復估計值
KaTeX parse error: Expected 'EOF', got '&' at position 12: minimize: &?||f^‘-\widetild…
通過KKT求得最優解程序如下

f
v
‘
=
f
~
v
?
1
D
1
(
∑
v
∈
D
1
f
~
v
?
1
)
f^‘_v=\widetilde{f}_v-\frac{1}{D_1}(\sum_{v\in D_1}\widetilde{f}_v-1)
fv‘?=f
?v??D1?1?(v∈D1?∑?f
?v??1)
Norm-Sub 就是 CLS公式的解
δ = ? 1 D 1 ( ∑ v ∈ D 1 f ~ v ? 1 ) \delta = -\frac{1}{D_1}(\sum_{v\in D_1}\widetilde{f}_v-1) δ=?D1?1?(v∈D1?∑?f ?v??1)
4.4 Maximum Likelihood Estimation
將問題視為恢復真實的概率值
4.4.1 MLE-Apx
在執行FO協議后,計算帶有約束條件的MLE(最大似然函式)來恢復估計值
最大似然函式公式推導
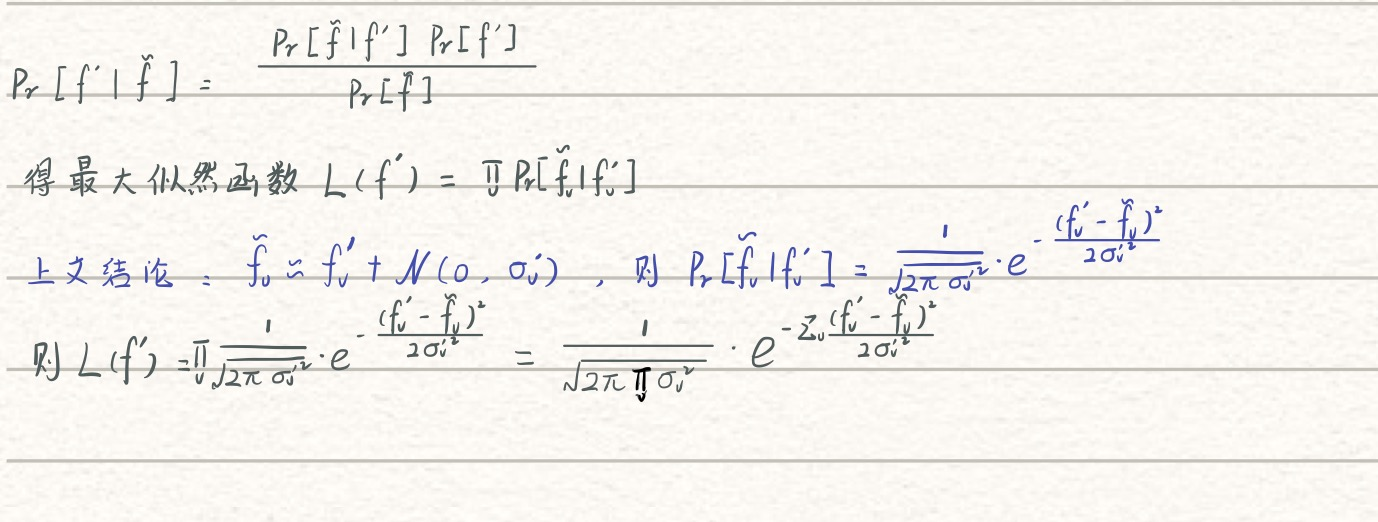
同理使用KKT求解最優值

可將公式改寫為
KaTeX parse error: Expected 'EOF', got '&' at position 9: f^‘_v =&? \widetilde{f}_…
-
因此MLE-Apx 很像Norm-Sub 和 Norm-Mul的結合
-
當 y ~ 1 y \sim 1 y~1時,MLE-Apx與Norm-Sub很接近
4.5 Least Expected Square Error
首先假設資料遵循某種型別的分布(但引數未知),然后通過最小期望平方誤差來擬合分布的引數、
4.5.1 Power
參考論文
Calibrate: Frequency Estimation and Heavy Hitter Identification with Local Differential Privacy via Incorporating Prior Knowledge閱讀筆記
論文鏈接.
假設真實頻率服從Power-Law分布,然后最小化期望的平方誤差.
此方法需要已知資料的概率分布,或資料的知識來獲得對應的概率分布
-
認為頻率估計由兩部分組成 f ~ v ≈ f v + N ( 0 , σ ) \widetilde{f}_v \approx f_v + \mathcal{N}(0,\sigma) f ?v?≈fv?+N(0,σ)
-
最小化 E [ ( f v ? f v ‘ ) 2 ∣ f ~ v ] E[(f_v-f_v^‘)^2|\widetilde{f}_v] E[(fv??fv‘?)2∣f ?v?],
最優化結果得到頻率估計計算公式如下
f ‘ = ∑ k k ? P r ( f = k ∣ f ~ = f ~ v ) f^‘=\sum_k k·Pr(f=k|\widetilde{f}=\widetilde{f}_v) f‘=k∑?k?Pr(f=k∣f ?=f ?v?) -
得到校正頻率估計 f v ‘ f_v^‘ fv‘?公式如下
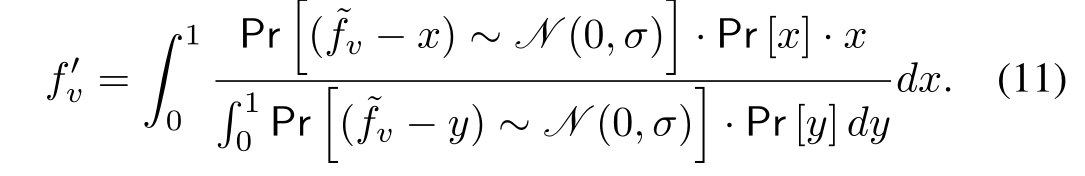

- 如果噪聲太多,或擬合的分布與真實分布不同,則使得校正結果的精度較差
4.5.2 PowerNS
由于Power方法獨立對每個 f v ‘ f_v^‘ fv‘?進行校正,所以其無法滿足約束2)sum=1,故我們對Power的結果使用Norm-Sub后處理方法
4.6 Summary
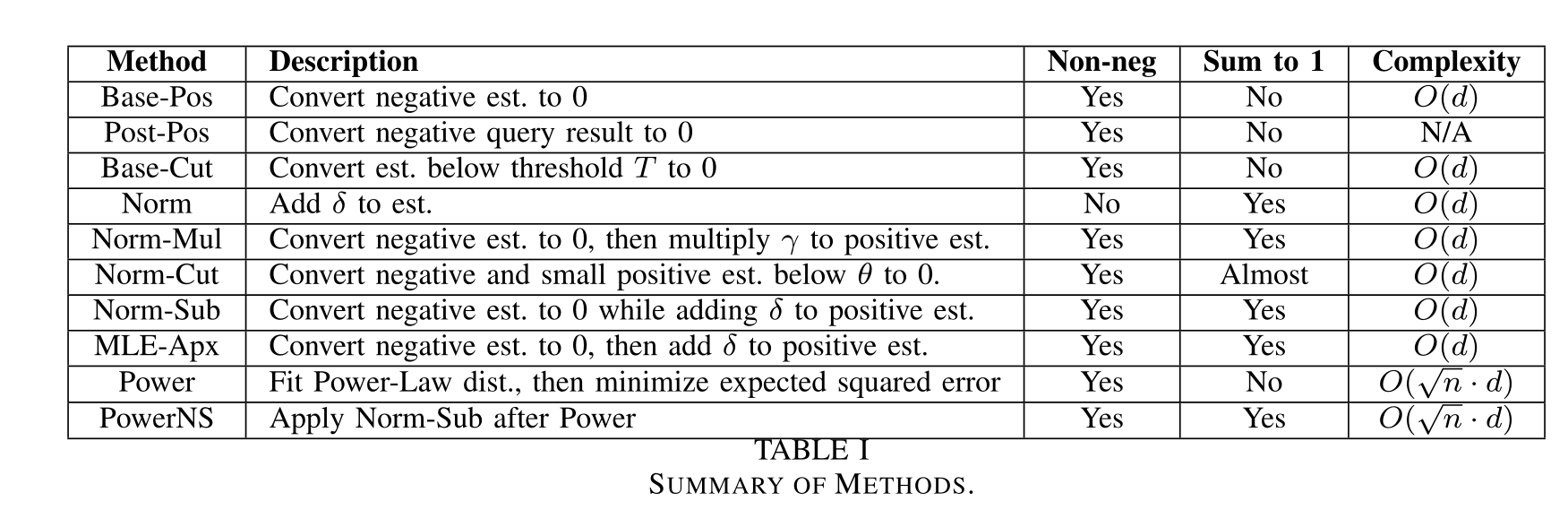
5. EVALUATION
對于全域查詢full-domain query,Base-Cut表現最佳
對于子集查詢set-value query,PowerNS表現最佳
對于頻繁項查詢high-frequency-value query,Norm表現最佳
5.1 Experimental Setup
資料集
兩個資料集
-
一個合成資料集,服從Zipf冪律分布
-
一個Emoji資料集

度量方法
使用MSE方法度量
-
對于全域查詢
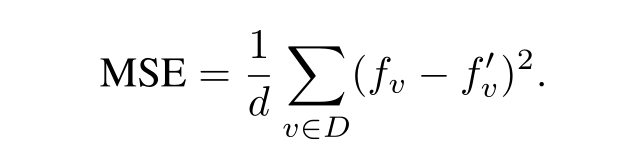
-
對于頻繁項查詢
我們計算top-k頻率的項,而不是整個域D
-
對于子集查詢
不同于度量單個項的誤差,我們首先度量子集的誤差,即,先對一組值的頻率求和,再度量誤差
5.2 Bias-variance Evaluation
Figure 1
針對Zipf資料集嗎,藍線為真實概率分布,綠線為不同的后處理后的概率估計
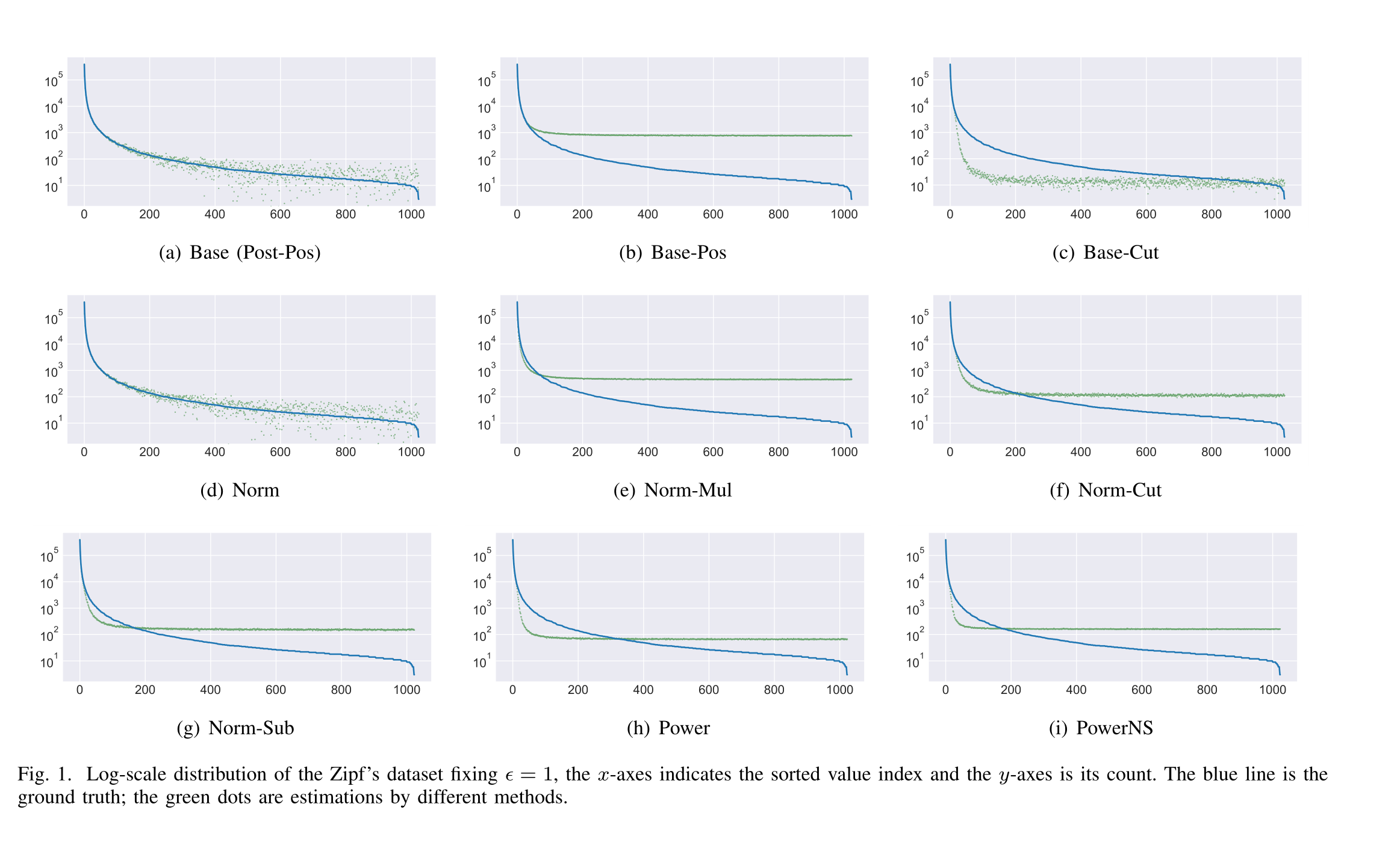
Figure 2
- 經驗偏差,可以得到Base、Norm無偏
- Base-Pos有 positive bias
- Base-Cut對于頻繁項無偏,對于部分的值,收到positive bias和 negative bias ,所以可能會出現無偏估計
- 對于Norm-Cut分析同樣適用,Norm-Sub的閾值要比Base-Cut來的小
- 對于Norm-Sub,對 所有的值減去δ,然后將所有小于零的值,置為0
- 對于Power對頻繁項沒有太大變化,和Norm-Cut類似,對于低頻的值,有很大的偏差
- 對于PowerNS于Power相近,在Power后執行Norm-Sub,減去一些估算值
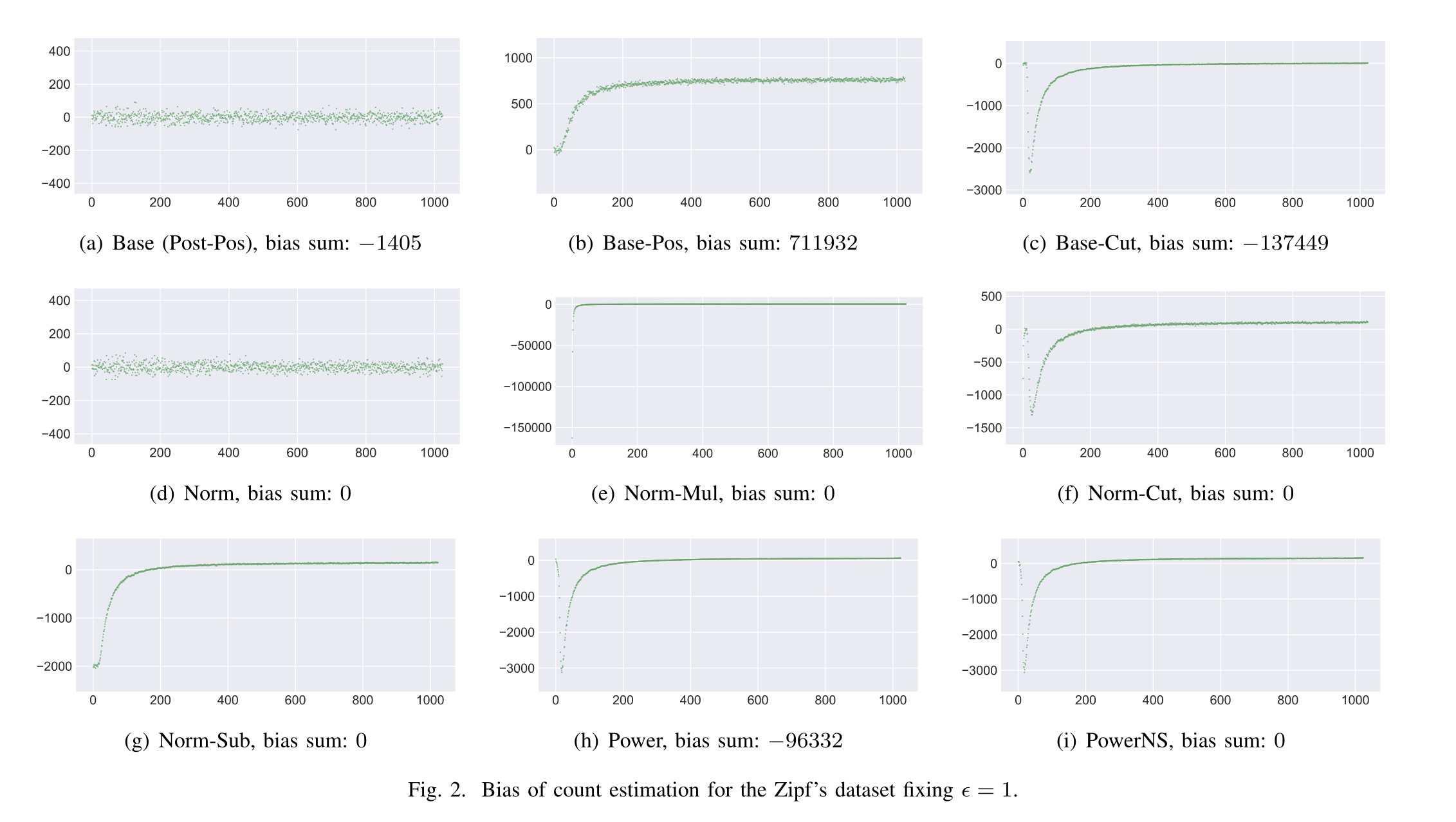
Figure 3
方差
- Base和Norm中所有值的方差都是相似的,Norm中稍好一些
- 其他的方法,方差隨著頻率估計排名的下降而下降,因為對于低頻項,他們的估計和均值多為0
5.3 Full domain Evaluation
具體見論文
5.4 Set-value Evaluation
具體見論文
5.5 Frequent-value Evaluation
具體見論文
5.6 Discussion
-
Norm-Sub和MLE-Apx表現相近;Base和Norm表現相近
-
如果要進行 set-value estimation 可以選擇PowerNS,如果set固定,可以對經過Norm-Sub處理的資料集選擇最優方法
直覺是,PowerNS 改進了MLE(即Norm-Sub,一種理論證明方法)因為它使得資料更加接近真實頻率估計的分布
-
如果要進行frequent-value estimation 可以選擇Norm,雖然也可以選擇Base但是Norm減少了方差,這兩個方法不會顯著的改變任何值
-
如果要進行single value estimate 可以選擇Base-Cut
后處理準則
6. RELATED WORK
7. CONCLUSION
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354513.html
標籤:其他
下一篇:常見中間件漏洞復現