所有 IT 從業者都接觸過快取,一定了解基本作業原理,業界流行一句話: 快取就是萬金油,哪里有問題哪里抹一下 ,那他的本質是什么呢?
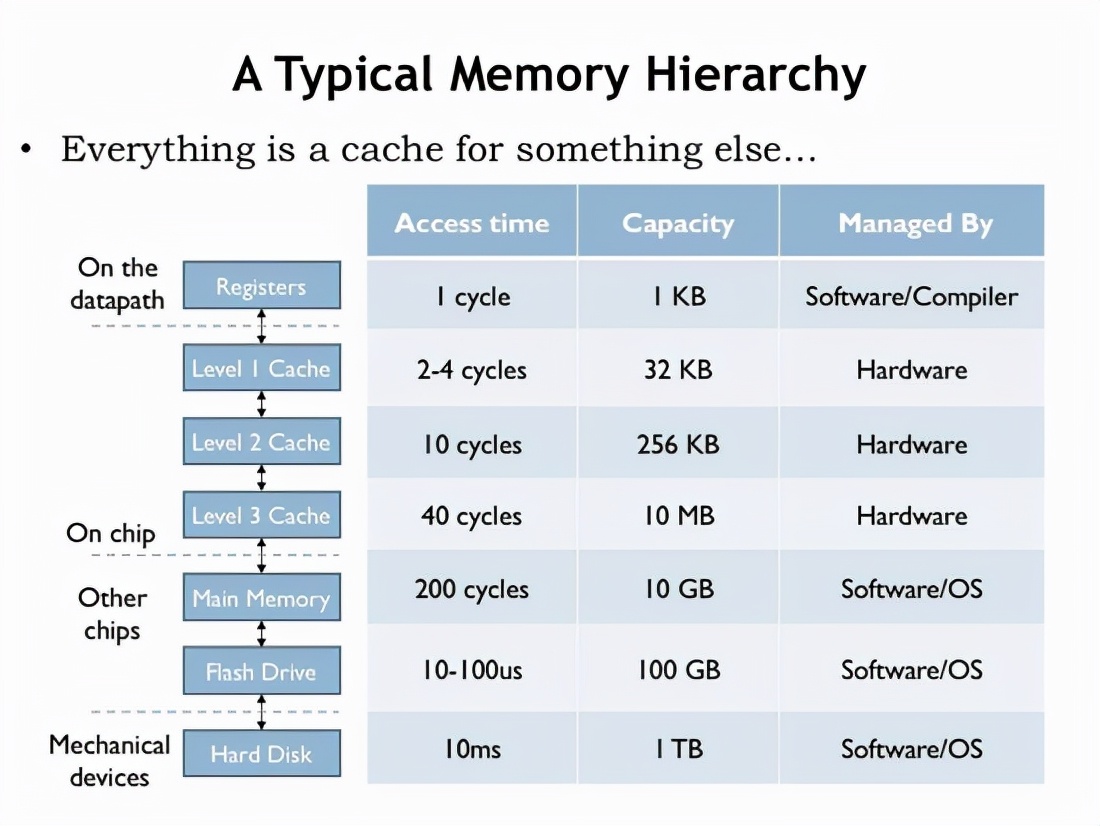
上圖代表從 cpu 到底層硬碟不同層次,不同模塊的運行速度,上層多加一層 cache, 就能解決下層的速度慢的問題,這里的慢是指兩點:IO 慢和 cpu 重復計算快取中間結果
但是 cache 受限于成本,cache size 一般都是固定的,所以資料需要淘汰,由此引出一系列其它問題:快取一致性、擊穿、雪崩、污染等等,本文通過閱讀 redis 原始碼,學習主流淘汰演算法
如果不是 leetcode 146 LRU [1] 刷題需要,我想大家也不會手寫 cache, 簡單的實作和工程實踐相距十萬八千里,真正 production ready 的快取庫非常考驗細節
Redis 快取淘汰配置
一般 redis 不建義當成存盤使用,只允許當作 cache, 并設定 max-memory, 當記憶體使用達到最大值時,redis-server 會根據不同配置開始洗掉 keys. Redis 從 4.0 版本引進了 LFU [2] , 即 Least Frequently Used ,4.0 以前默認使用 LRU 即 Least Recently Used
- volatile-lru 只針對設定 expire 過期的 key 進行 lru 淘汰
- allkeys-lru 對所有的 key 進行 lru 淘汰
- volatile-lfu 只針對設定 expire 過期的 key 進行 lfu 淘汰
- allkeys-lfu 對所有的 key 進行 lfu 淘汰
- volatile-random 只針對設定 expire 過期的進行隨機淘汰
- allkeys-random 所有的 key 隨機淘汰
- volatile-ttl 淘汰 ttl 過期時間最小的 key
- noeviction 什么都不做,如果此時記憶體已滿,系統無法寫入
默認策略是 noeviction , 也就是不驅逐,此時如果寫滿,系統無法寫入,建義設定為 LFU 相關的, LRU 優先淘汰最近未被使用,無法應對冷資料,比如熱 keys 短時間沒有訪問,就會被只使用一次的冷資料沖掉,無法反應真實的使用情況
LFU 能避免上述情況,但是 樸素 LFU 實作無法應對突發流量,無法驅逐歷史熱 keys ,所以 redis LFU 實作類似于 W-TinyLFU [3] , 其中 W 是 windows 的意思,即一定時間視窗后對頻率進行減半,如果不減的話,cache 就成了對歷史資料的統計,而不是快取
上面還提到突發流量如果應對呢?答案是給新訪問的 key 一個初始頻率值,不至于由于初始值為 0 無法更新頻率
LRU 實作
int processCommand(redisClient *c) {
......
/* Handle the maxmemory directive.
*
* First we try to free some memory if possible (if there are volatile
* keys in the dataset). If there are not the only thing we can do
* is returning an error. */
if (server.maxmemory) {
int retval = freeMemoryIfNeeded();
if ((c->cmd->flags & REDIS_CMD_DENYOOM) && retval == REDIS_ERR) {
flagTransaction(c);
addReply(c, shared.oomerr);
return REDIS_OK;
}
}
......
}
在每次處理 client 命令時都會呼叫 freeMemoryIfNeeded 檢查是否有必有驅逐某些 key, 當 redis 實際使用記憶體達到上限時開始淘汰,但是 redis 做的比較取巧,并沒有對所有的 key 做 lru 佇列,而是按照 maxmemory_samples 引數進行采樣,系統默認是 5 個 key

上面是很經典的一個圖,當到達 10 個 key 時效果更接近理論上的 LRU 演算法,但是 cpu 消耗會變高,所以系統默認值就夠了,
LFU 實作
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
/* Update the access time for the ageing algorithm.
* Don't do it if we have a saving child, as this will trigger
* a copy on write madness. */
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
val->lru = LRU_CLOCK();
}
}
return val;
} else {
returnNULL;
}
}
當 lookupKey 訪問某 key 時,會更新 LRU. 從 redis 4.0 開始逐漸引入了 LFU 演算法,由于復用了 LRU 欄位,所以只能使用 24 bits
* We split the 24 bits into two fields:
*
* 16 bits 8 bits
* +----------------+--------+
* + Last decr time | LOG_C |
* +----------------+--------+
其中低 8 位 counter 用于計數頻率,取值為從 0~255, 但是經過取對數的,所以可以表示很大的訪問頻率
高 16 位 ldt ( Last Decrement Time )表示最后一次訪問的 miniutes 時間戳, 用于衰減 counter 值,如果 counter 不衰減的話就變成了對歷史 key 訪問次數的統計了,而不是 LFU
/* Update LFU when an object is accessed.
* Firstly, decrement the counter if the decrement time is reached.
* Then logarithmically increment the counter, and update the access time. */
void updateLFU(robj *val) {
unsigned long counter = LFUDecrAndReturn(val);
counter = LFULogIncr(counter);
val->lru = (LFUGetTimeInMinutes()<<8) | counter;
}
LFUDecrAndReturn 將已有的 counter 計數衰減后回傳, LFULogIncr 嘗試對計數加一(有可能不加)后取對數,最后更新 val-lru
unsigned long LFUTimeElapsed(unsigned long ldt) {
unsigned long now = LFUGetTimeInMinutes();
if (now >= ldt) return now-ldt;
return 65535-ldt+now;
}
注意由于 ldt 只用了 16位計數,最大值 65535,所以會出現回卷 rewind
LFU 獲取己有計數
* counter of the scanned objects if needed. */
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8;
unsigned long counter = o->lru & 255;
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}
num_periods 代表計算出來的待衰減計數, lfu_decay_time 代表衰減系數,默認值是 1,如果 lfu_decay_time 大于 1 衰減速率會變得很慢
最后回傳的計數值為衰減之后的,也有可能是 0
LFU 計數更新并取對數
/* Logarithmically increment a counter. The greater is the current counter value
* the less likely is that it gets really implemented. Saturate it at 255. */
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}
計數超過 255, 就不用算了,直接回傳即可, LFU_INIT_VAL 是初始值,默認是 5
如果減去初始值后 baseval 小于 0 了,說明快過期了,就更傾向于遞增 counter 值
double p = 1.0/(baseval*server.lfu_log_factor+1);
這個概率演算法中 lfu_log_factor 是對數的,默認是 10, 當 counter 值較小時自增的概率較大,如果 counter 較大,傾向于不做任何操作
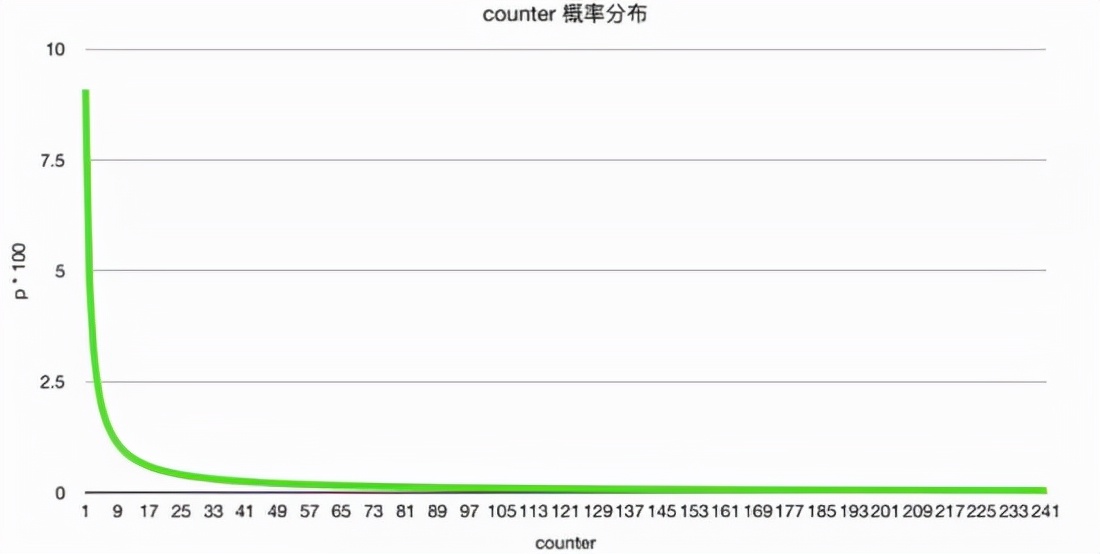
counter 值從 0~255 可以表示很大的訪問頻率,足夠用了
# +--------+------------+------------+------------+------------+------------+
# | factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits |
# +--------+------------+------------+------------+------------+------------+
# | 0 | 104 | 255 | 255 | 255 | 255 |
# +--------+------------+------------+------------+------------+------------+
# | 1 | 18 | 49 | 255 | 255 | 255 |
# +--------+------------+------------+------------+------------+------------+
# | 10 | 10 | 18 | 142 | 255 | 255 |
# +--------+------------+------------+------------+------------+------------+
# | 100 | 8 | 11 | 49 | 143 | 255 |
# +--------+------------+------------+------------+------------+------------+
基于這個特性,我們就可以用 redis-cli --hotkeys 命令,來查看系統中的最近一段時間的熱 key, 非常實用,老版本中是沒這個功能的,需要人工統計
$ redis-cli --hotkeys
# Scanning the entire keyspace to find hot keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
......
[47.62%] Hot key 'key17' found so far with counter 6
[57.14%] Hot key 'key43' found so far with counter 7
[57.14%] Hot key 'key14' found so far with counter 6
[85.71%] Hot key 'key42' found so far with counter 7
[85.71%] Hot key 'key45' found so far with counter 8
[95.24%] Hot key 'key50' found so far with counter 7
-------- summary -------
Sampled 105 keys in the keyspace!
hot key found with counter: 7 keyname: key40
hot key found with counter: 7 keyname: key42
hot key found with counter: 7 keyname: key50
談談快取的指標
前面提到的是 redis LFU 實作,這是集中式的快取,我們還有很多行程的本地快取,如何評價一個快取實作的好壞,有好多指標,細節更重要
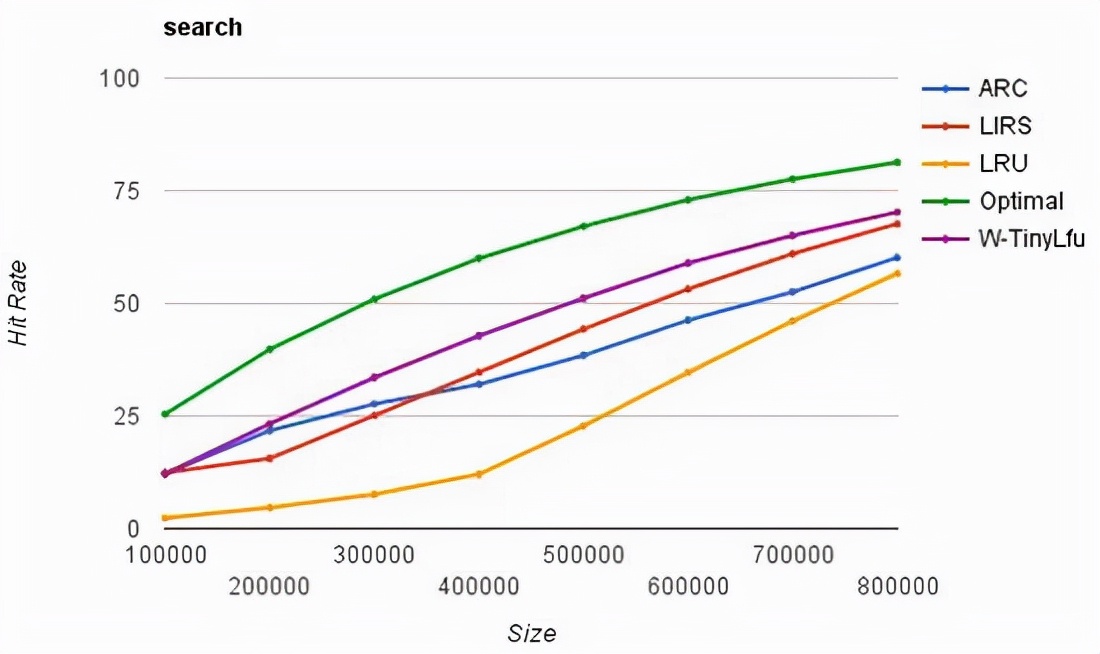
- 吞吐量:常說的 QPS, 對標 bucket 實作的 hashmap 復雜度是 O(1), 快取復雜度要高一些,還有鎖競爭要處理,總之快取庫實作的效率要高
- 快取命中率:光有吞吐量還不夠,快取命中率也非常關鍵,命中率越高說明引入快取作用越大
- 高級特性:快取指標統計,如何應對快取擊穿等等
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354545.html
標籤:其他
上一篇:LeetCode 732 我的日程安排表 III[插旗法] HERODING的LeetCode之路
下一篇:CF進制轉換專題進階