1、背景
公司內部有大量SparkSQL任務,很多任務有資料傾斜或者記憶體分配不合理的情況,此博客記錄下優化腳本程序中出現的一些問題及經驗
2、WebUi應用介紹
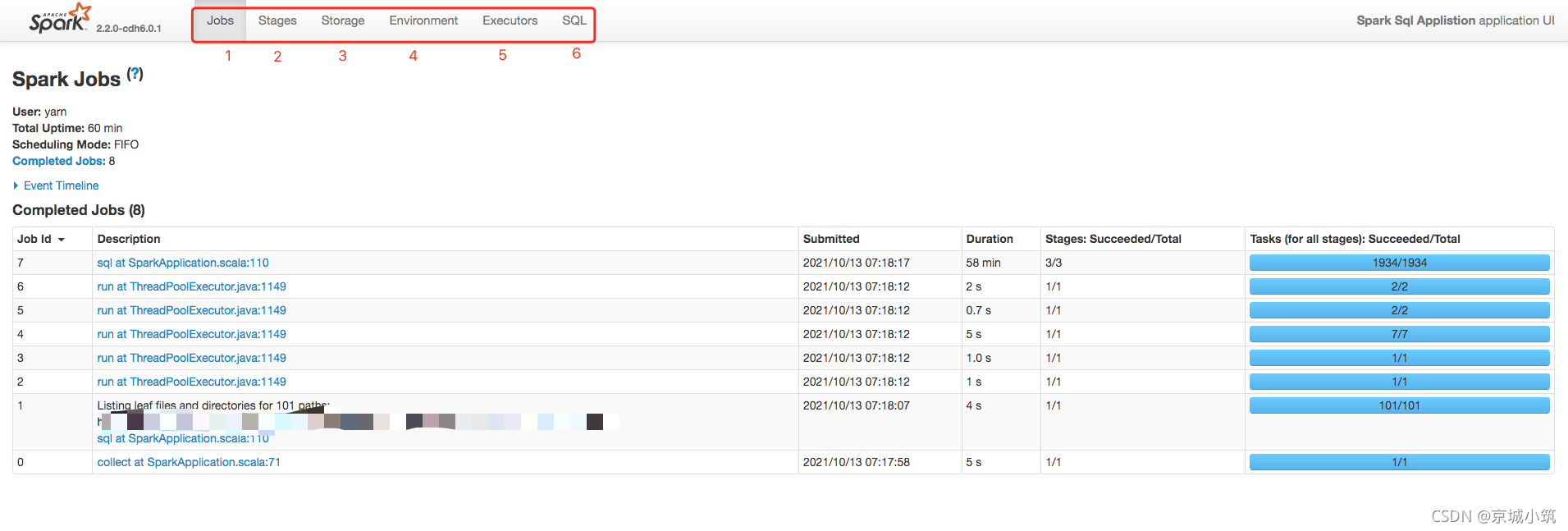
如上圖,SparkSQL Web界面可分為如上5個的模塊,以下簡單介紹下這5個模塊
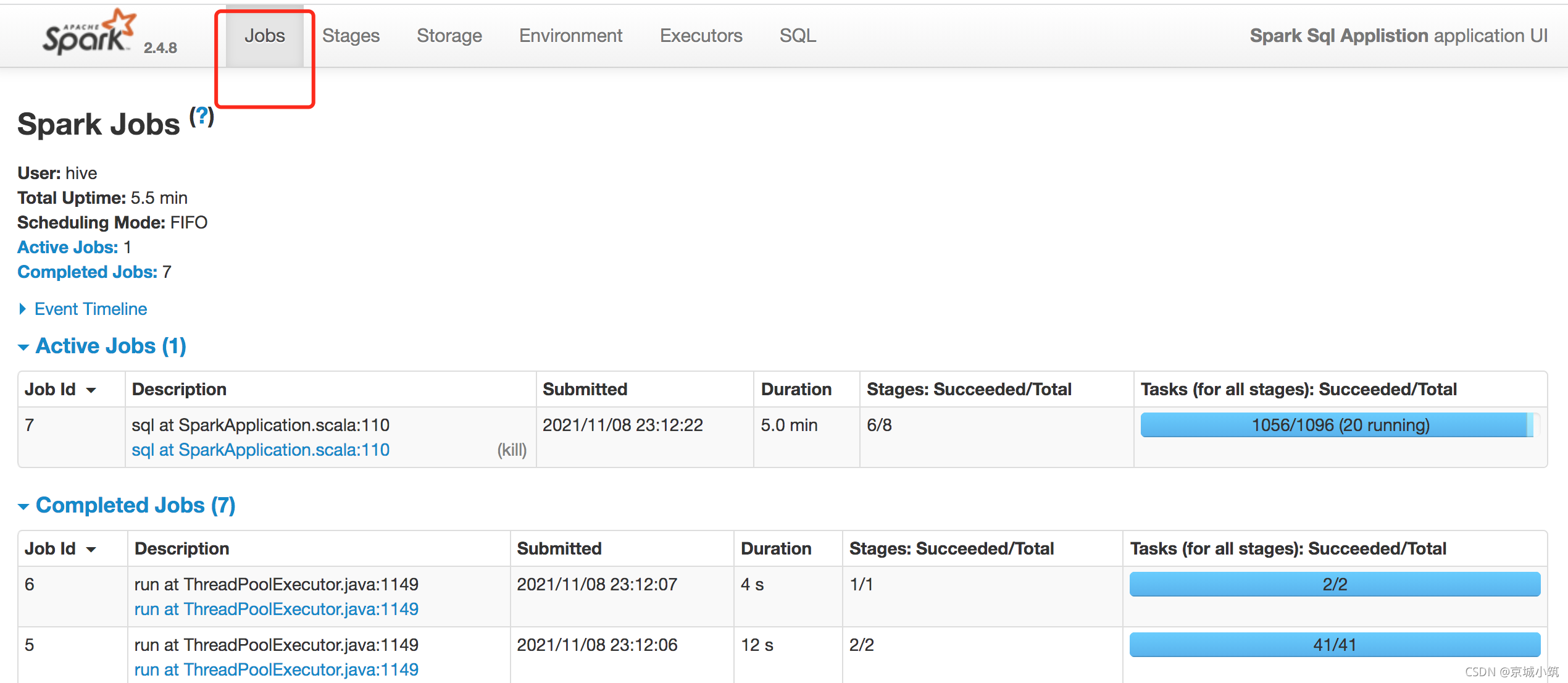
Jobs:
整個spark應用任務的job整體資訊(簡單來說就是提交給spark的任務)
- User: 提交作業的用戶,用以進行權限控制與資源分配,
- Total Uptime: spark application總的運行時長,如果此Application id 還在運行期間,此處的時間會一直變化,
- Scheduling Mode: application中task任務的調度策略,由引數spark.scheduler.mode來設定,可選的引數有FAIR和FIFO,默認是FIFO,這與yarn的資源調度策略的層級不同,yarn的資源調度是針對集群中不同application間的,而spark scheduler mode則是針對application內部task set級別的資源分配,不同FAIR策略的引數配置方式與yarn中FAIR策略的配置方式相同,
- Completed Jobs: 已完成Job的基本資訊,如果想查看job的運行情況,可以點擊此選項(一般選擇直接點開stage查看,這樣比較直觀)
- Active Jobs: 正在運行的Job,
- Event Timeline: 用來表示調度job何時啟動何時結束,以及Excutor何時加入何時移除(底部有添加及移除的具體時間點)我們可以很方便看到哪些job已經運行完成,使用了多少Excutor,哪些正在運行,是查看excutor增加和移除的圖形化界面
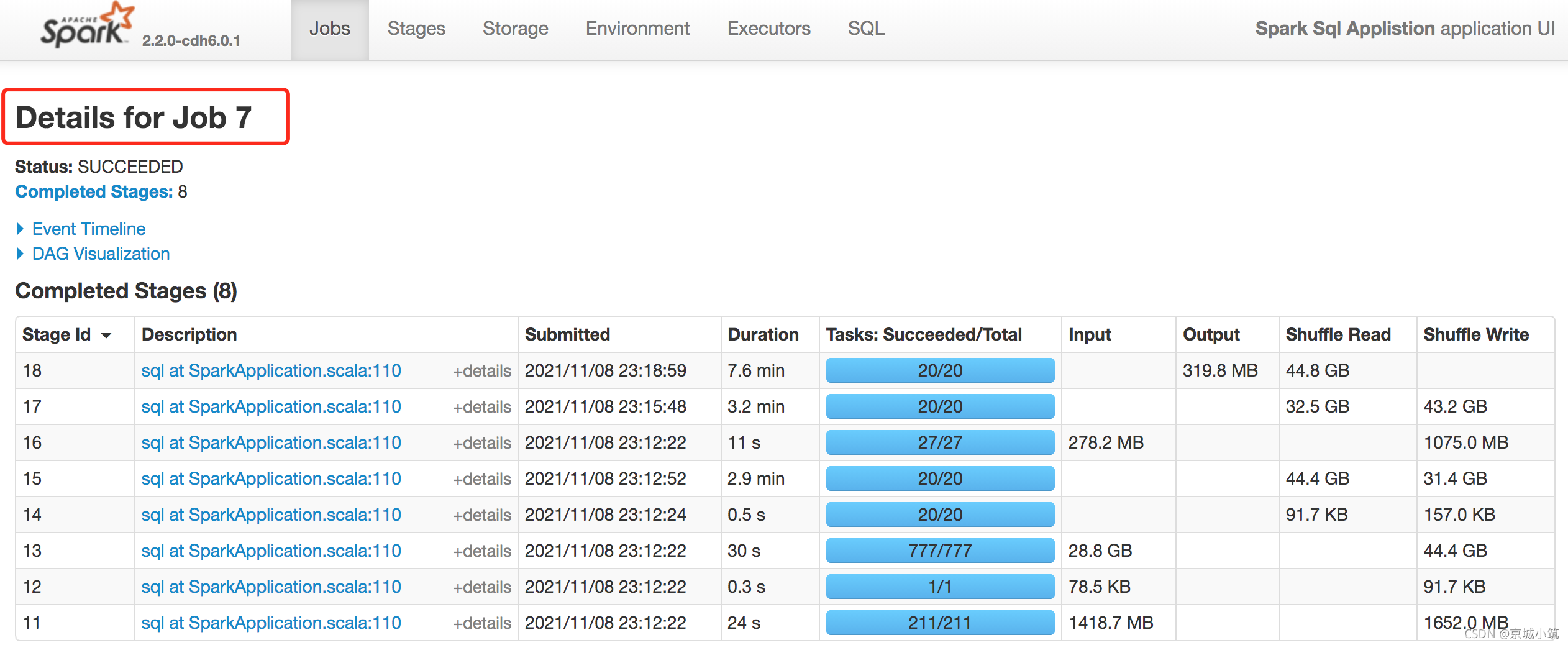
Job Details:
Jobs 中正在運行(Active Stage)的或者已經結束(Completed Stages) 中Description一欄便可看到具體details資訊(job對應的具體資訊,可以清楚的看到job被劃分為幾個stage)
- Staus: 展示Job的當前狀態資訊,
- Active Stages: 正在運行的stages資訊,點擊某個stage可進入查看具體的stage資訊(這個步驟可以很明顯的發現是否發生資料傾斜問題),
- Pending Stages: 待分配的stages資訊,正在排隊
- Completed Stages: 已經完成的stages資訊,
- Event Timeline: 見上 (Jobs中的Event Timeline)
- DAG Visualization: 有向無環圖,當前Job所包含的所有stage資訊(stage中包含的明細的transformation操作,DAG Scheduler 會根據 RDD 的 transformation 動作,將 DAG 分為不同的 stage,每個 stage 中分為多個 task,這些 task 可以并行運行),以及各stage間的DAG依賴圖,DAG也是一種調度模型,在spark的作業調度中,有很多作業存在依賴關系,所以沒有依賴關系的作業可以并行執行,有依賴的作業不能并行執行
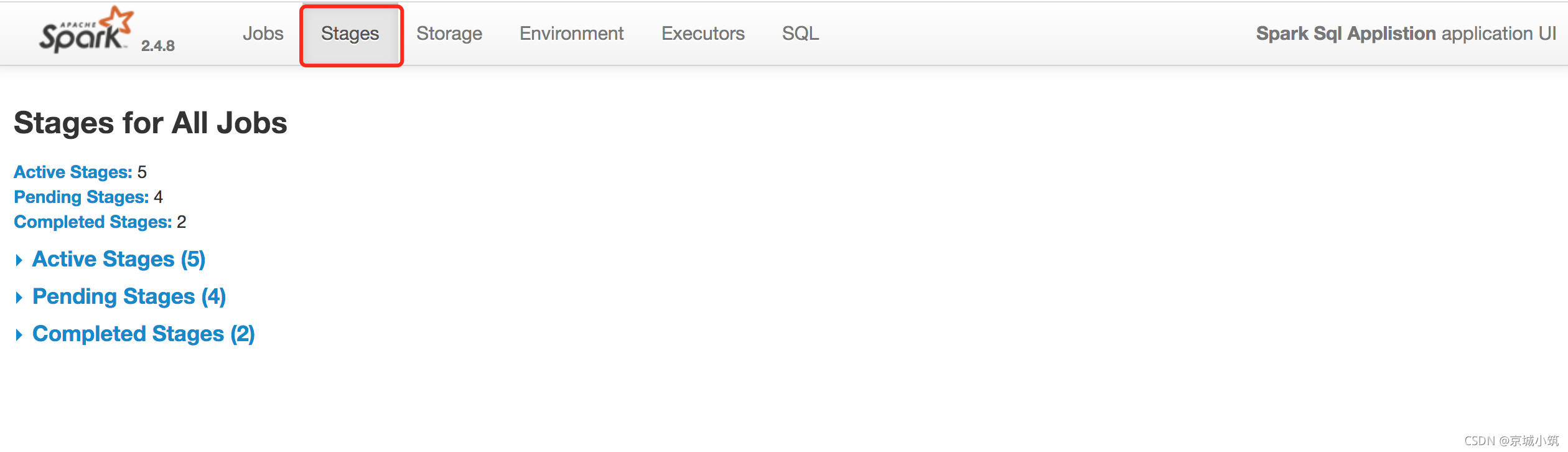
Stage:
直接點擊Stage欄位,或者從Job Details中點開對應的stage(Stage是每一個job處理程序要分為的幾個階段)
- Total time across all tasks: 當前stage中所有task花費的時間和,
- Locality Level Summary: 不同本地化級別下的任務數,本地化級別是指資料與計算間的關系(PROCESS_LOCAL行程本地化:task與計算的資料在同一個Executor中,NODE_LOCAL節點本地化:情況一:task要計算的資料是在同一個Worker的不同Executor行程中;情況二:task要計算的資料是在同一個Worker的磁盤上,或在 HDFS 上,恰好有 block 在同一個節點上,RACK_LOCAL機架本地化,資料在同一機架的不同節點上:情況一:task計算的資料在Worker2的Executor中;情況二:task計算的資料在Worker2的磁盤上,ANY跨機架,資料在非同一機架的網路上,速度最慢),
- Input Size/Records: 輸入的資料位元組數大小/記錄條數,
- Shuffle Write: 只有join、group by transformation算子等才會產生shuffle ,Shuffle Write為下一個依賴的stage提供輸入資料,shuffle程序中通過網路傳輸的資料位元組數/記錄條數,應該盡量減少shuffle的資料量及其操作次數,這是spark任務優化的一潭訓本原則,
- Shuffle Spill (Memory): 略
- Shuffle Spill (Disk):略
- DAG Visualization: 見上 (Job Details中的DAG Visualization)
- Metrics: 當前stage中所有task的一些指標(每一指標項滑鼠移動上去后會有對應解釋資訊)統計資訊,
- Event Timeline: 直觀的展示了每個Executor上各個task的各個階段的時間統計資訊,可以清楚地看到task任務時間是否有明顯傾斜(底部有添加及移除的具體時間點),以及傾斜的時間主要是屬于哪個階段,從而有針對性的進行優化,
- Aggregated Metrics by Executor: 將task運行的指標資訊按excutor做聚合后的統計資訊,并可查看某個Excutor上任務運行的日志資訊,
- Tasks: 當前stage中所有任務運行的明細資訊,是與Event Timeline中的資訊對應的文字展示(可以點擊某個task查看具體的任務日志
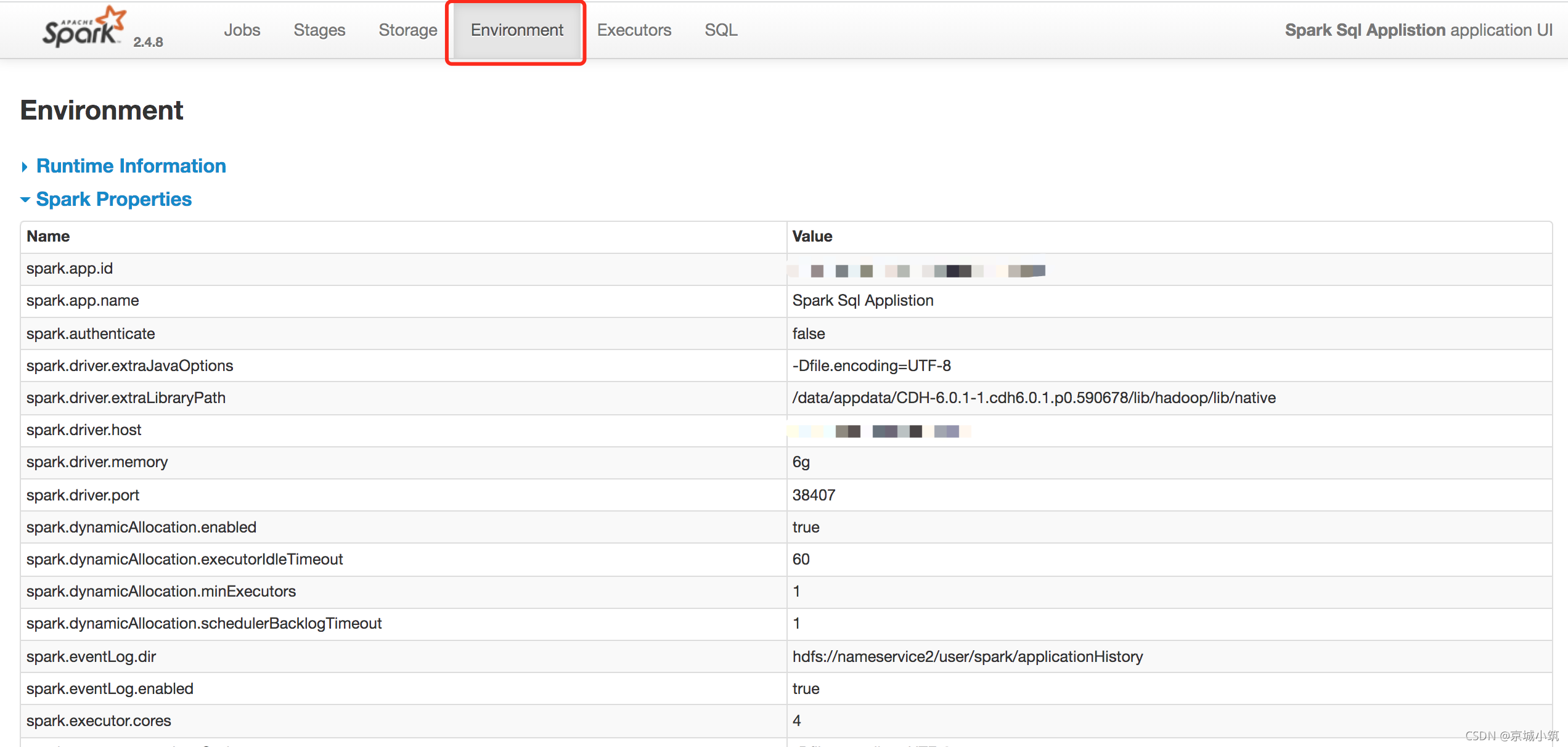
Enviroment:
此選項提供有關Spark應用程式(或SparkContext)中使用的各種屬性和環境變數的資訊,用戶可以通過這個選項卡得到非常有用的各種Spark屬性資訊,而不用去翻找屬性組態檔,此處需要注意的是,如果你的腳本中單獨SET某個變數值的話,此處顯示的是Submit提交的引數值,此處切記不要混淆(敲黑板)
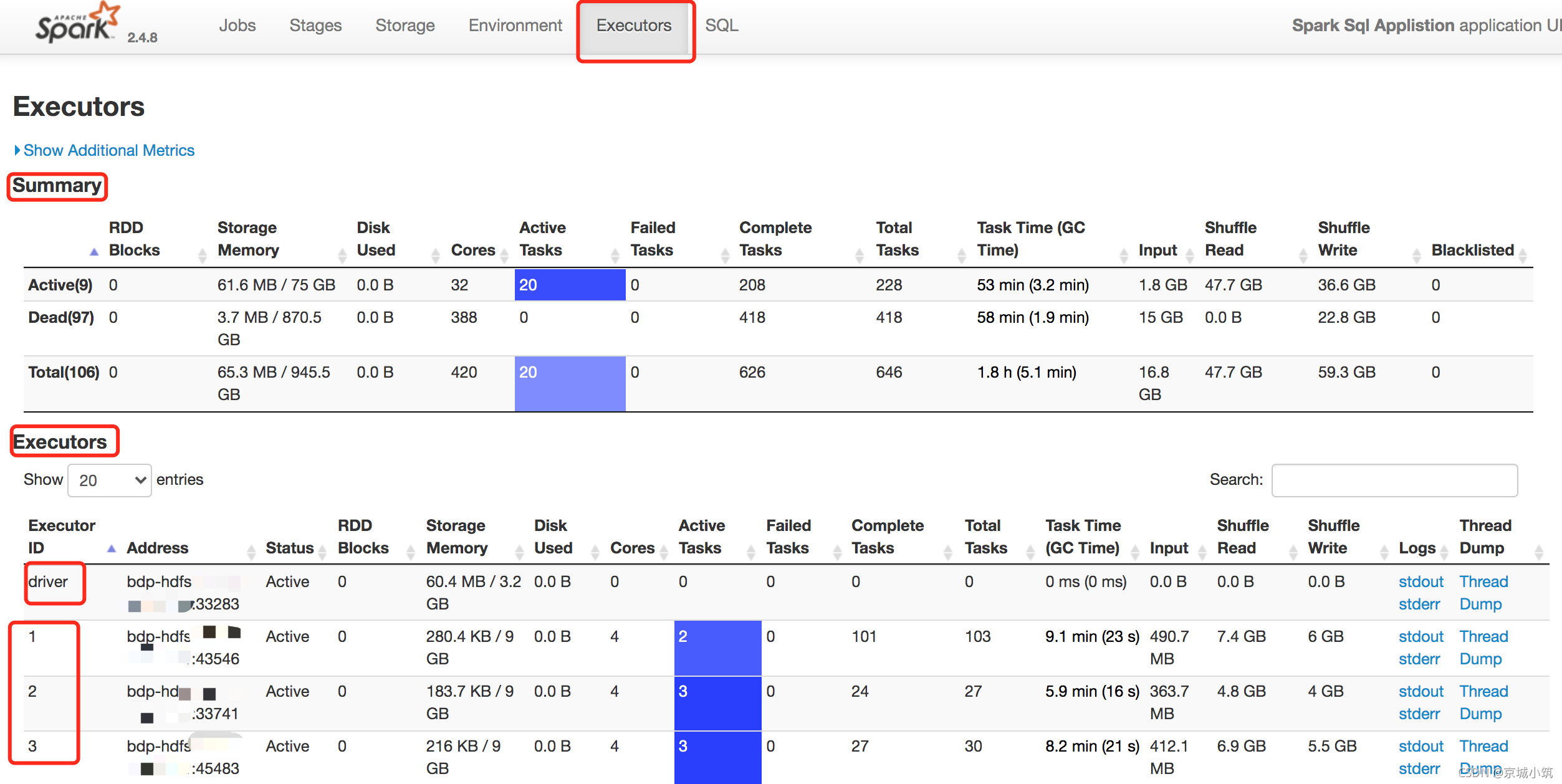
Executor:
Executor提供了關于記憶體、CPU和其他被Executors使用的資源的資訊,這些資訊在Executor級別和匯總級別都可以獲取到,一方面通過它可以看出來每個excutor是否發生了資料傾斜,另一方面可以具體分析目前的應用是否產生了大量的shuffle,是否可以通過資料的本地性或者減小資料的傳輸來減少shuffle的資料量,
- Summary: 該application運行程序中使用Executor的統計資訊,
- Executors: 每個Excutor的詳細資訊(包含driver),可以點擊查看某個Executor中任務運行的詳細日志,
- driver行程就是應用的main()函式并且構建sparkContext物件,當我們提交了應用之后,便會啟動一個對應的driver行程
- executor節點是一個作業行程,負責在 Spark 作業中運行任務,任務間相互獨立,Spark 應用啟動時,Executor節點被同時啟動,并且始終伴隨著整個 Spark 應用的生命周期而存在,如果有Executor節點發生了故障或崩潰,Spark 應用也可以繼續執行,會將出錯節點上的任務調度到其他Executor節點上繼續運行,
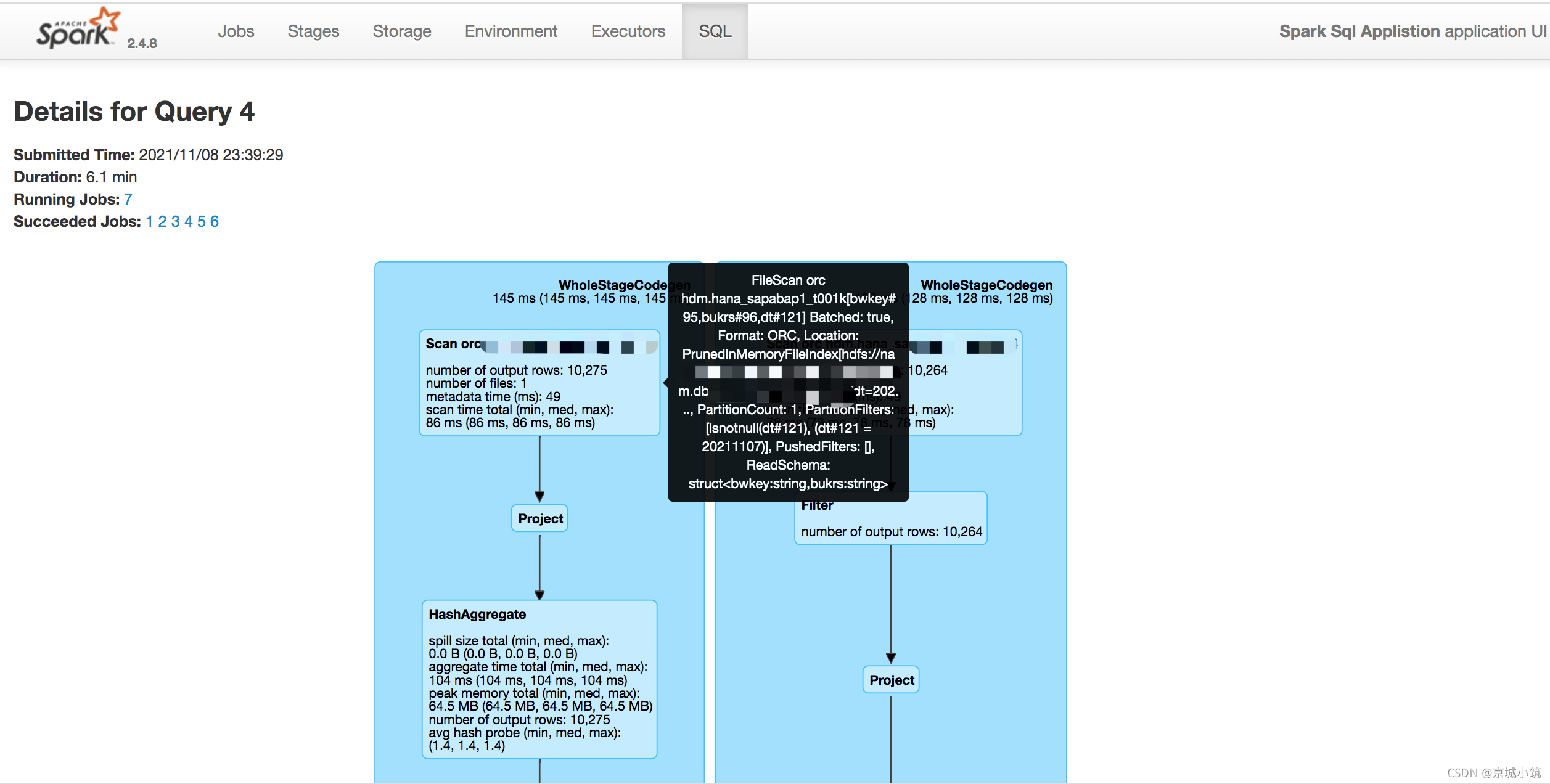
SQL:
此選項(只有執行了spark SQL查詢才會有SQL選項)可以查看SQL執行計劃的細節,它提供了SQL查詢的DAG以及顯示Spark如何優化已執行的SQL查詢的查詢計劃,此步驟可以看到sql的執行順序情況,包括表是否被廣播等,
3、總結
如果想了解Spark作業如何優化,首先你需要先了解Submit各個引數的作用以及學會如何通過WebUI定位Spark作業的問題,比如資料傾斜等,本文章較詳細的介紹了Web界面各個引數的作用(當然了,參考了很多大佬的博客,結尾會把相關文章放進來,大家也可以參考下)后續同專欄會持續推出針對SparkSQL作業優化的相關文章,最后弱弱的吐槽下,CSDN的這個排版真心不會用,碼字10分鐘,排版倆小時,
參考資料:
spark入門之spark Driver Web UI_minge_se的博客-CSDN博客
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354564.html
標籤:其他