學習總結
- 首先,利用 Spark 對 MovieLens 原始資料進行了處理,生成了訓練樣本和特征,樣本供 TensorFlow 進行模型訓練,特征存入 Redis 供線上推斷使用,
- 在 TensorFlow 平臺上,以 NeuralCF 模型為例,訓練并匯出了 NeuralCF 的模型檔案,然后使用 TensorFlow Serving 載入模型檔案,建立線上模型服務 API,推薦服務器的排序層從 Redis 中取出用戶特征和物品特征,組裝好 JSON 格式的特征資料,發送給 TensorFlow Serving API,再根據回傳的預估分數進行排序,最終生成“猜你喜歡”的推薦串列,
- 第三部分的“排序層 +TensorFlow Serving 的實作”具體搞完,挖坑,
文章目錄
- 學習總結
- 一、清點技能庫
- 1.1 模型特征工程
- 1.2 模型離線訓練
- 1.3 模型服務
- 1.4 推薦服務器內部邏輯實作
- 二、"猜你喜歡"推薦功能的技術架構
- 2.1 資料和模型部分
- 2.2 模型服務
- 2.3 推薦服務器部分
- 三、排序層 +TensorFlow Serving 的實作
- 3.1 特征樣本的拼接
- 3.2 建立起 TensorFlow Serving API
- (1)模型的匯出
- (2)模型的匯入
- 3.3 獲取回傳得分和排序
- 四、思維導圖
- 4.1 基礎模型
- 4.2 進階模型
- 4.3 前沿模型
- 五、作業
- 六、課后答疑
- Reference
一、清點技能庫
“猜你喜歡”功能幾憾訓用到所有的推薦系統模塊(如離線的特征工程、模型訓練以及線上的模型服務和推薦邏輯的實作),
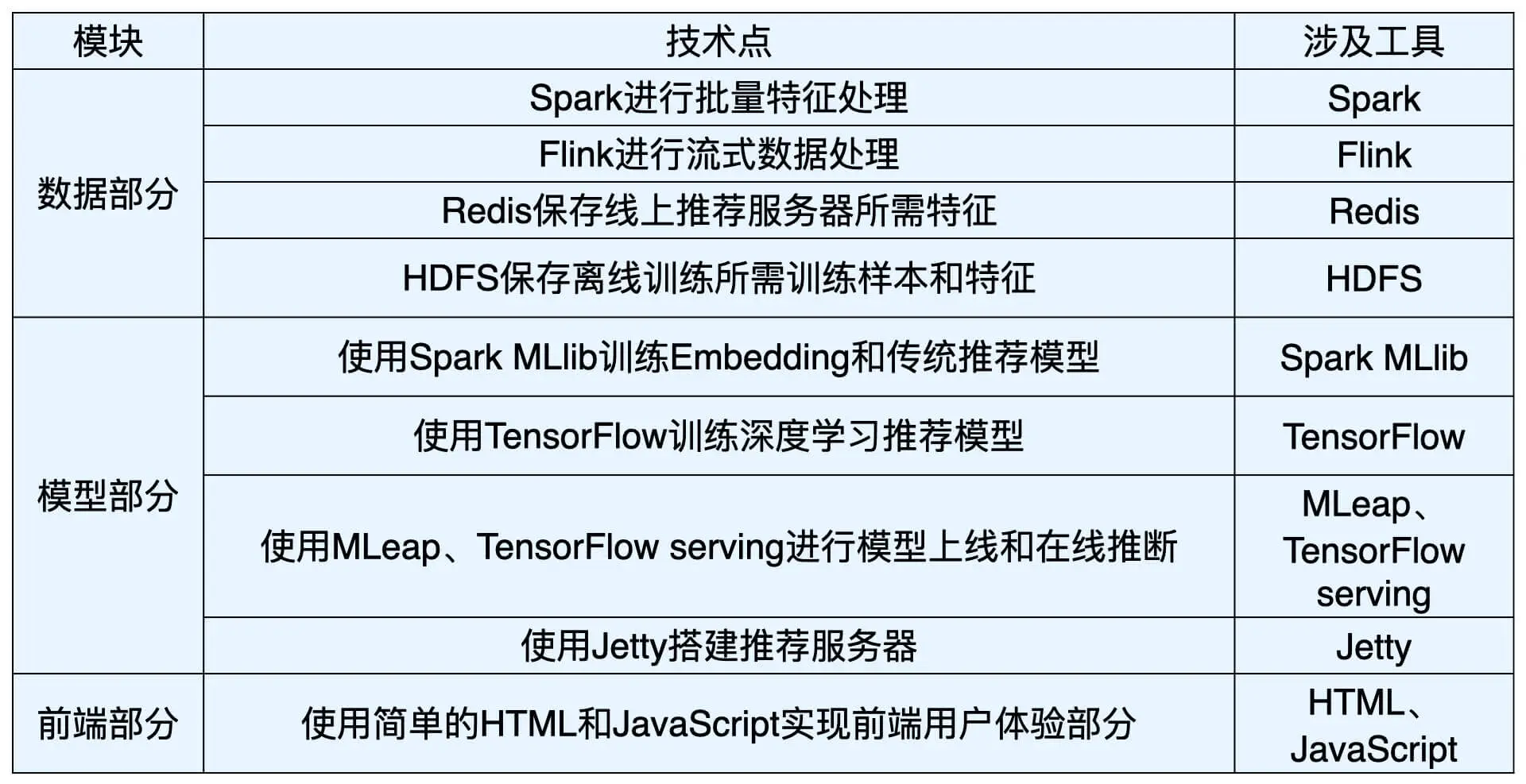
1.1 模型特征工程
為了訓練推薦模型,需要準備好模型所需的樣本和特征,在進行模型線上推斷的時候,推薦服務器也需要線上實時拼裝好包含了用戶特征、物品特征、場景特征的特征向量,發送給推薦模型進行實時推斷,
之前通過 Spark 處理好了 TensorFlow 訓練所需的訓練樣本,并把 Spark 處理好的特征插入了 Redis 特征資料庫,供線上推斷使用,
1.2 模型離線訓練
為了在線上做出盡量準確或者說推薦效果盡量好的排序,需要在離線訓練好排序所用的推薦模型,雖然之前學的深度推薦模型的結構各不相同,但它們的輸入、輸出都是一致的,輸入是由不同特征組成的特征向量,輸出是一個分數,這個分數的高低代表了這組特征對應的用戶對物品的喜好程度,
Embedding MLP、Wide&Deep、NeuralCF、雙塔模型、DeepFM 等幾種不同的深度推薦模型,它們中的任何一個都可以支持“猜你喜歡”的排序功能,
其他模型的上線方法與 NeuralCF 幾乎一致,唯一的區別是,對于不同的模型來說,它們在模型服務的部分需要載入不同的模型檔案,并且在線上預估的部分也要傳入模型相應的輸入特征,
1.3 模型服務
推薦系統中連接線上環境和線下環境的紐帶——模型服務和特征資料庫,
在離線訓練好模型后,為了讓模型在線上發揮功能(做出實時的推薦排序),我們通過【模型服務】模塊將推薦模型部署上線,和之前一樣使用tensorflow serving,
1.4 推薦服務器內部邏輯實作
模型服務雖然可以做到“猜你喜歡”中電影的排序,但要進行排序,仍然需要做大量的準備作業,比如候選集的獲取,召回層的構建,特征的獲取和拼裝等等,這些推薦邏輯都是在推薦服務器內部實作的,推薦服務器就像推薦系統的線上的心臟,是所有線上模塊的核心,
這次關注之前沒提到的特征的拼裝,以及從推薦服務器內部請求模型服務 API 的方法,
二、"猜你喜歡"推薦功能的技術架構
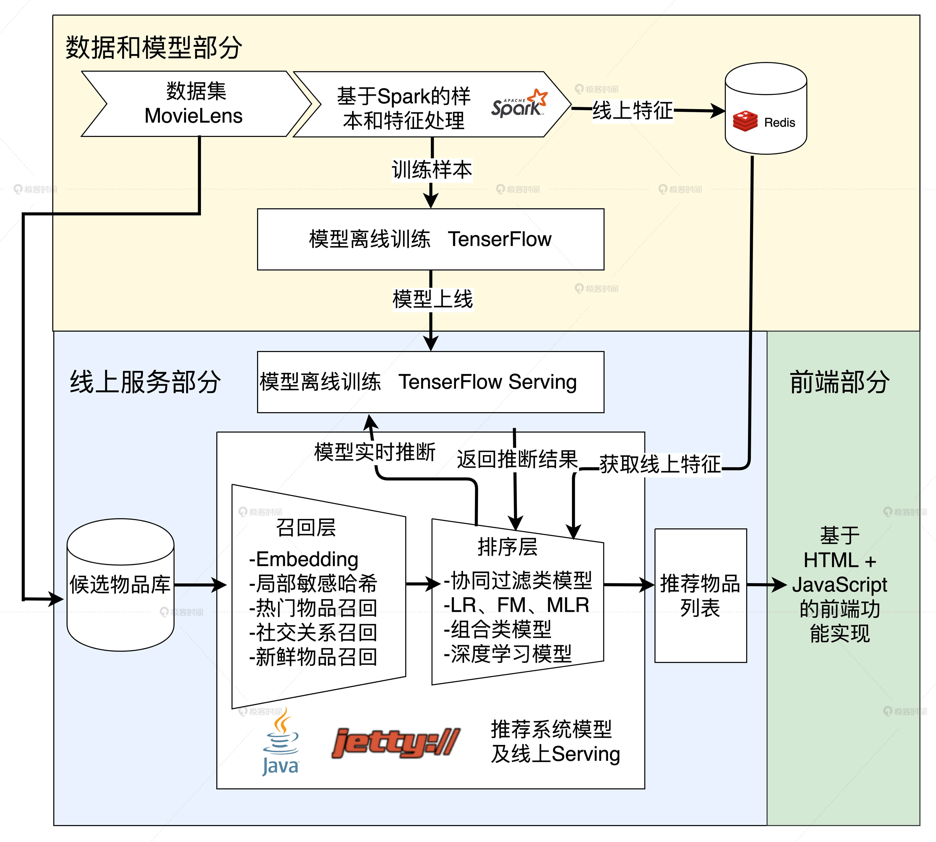
2.1 資料和模型部分
左上角是我們使用的資料集 MovieLens,它經過 Spark 的處理之后,會生成兩部分資料,分別從兩個出口出去:
(1)特征部分會存入 Redis 供線上推斷時推薦服務器使用,
(2)樣本部分則提供給 TensorFlow 訓練模型,
2.2 模型服務
TensorFlow 完成模型訓練之后,會匯出模型檔案,然后模型檔案會載入到 TensorFlow Serving 中,接著TensorFlow Serving 會對外開放模型服務 API,供推薦服務器呼叫,
2.3 推薦服務器部分
在這部分里,基于 MovieLens 資料集生成的候選電影集合會依次經過候選物品獲取、召回層、排序層這三步,最終生成“猜你喜歡”的電影推薦串列,然后回傳給前端,前端利用 HTML 和 JavaScript 把它們展示給用戶,
整個程序中,除了排序層和 TensorFlow Serving 的實作,其他部分在之前的實戰中實作過,所以這次重點講解推薦服務器排序層和 TensorFlow Serving 的實作(第三大點),
三、排序層 +TensorFlow Serving 的實作
在推薦服務器中,經過召回層后,得到的幾百量級的候選物品集,丟到排序層,在業界的實際應用中,往往交由評估效果最好的深度推薦模型來處理,
整個的排序程序可以分為三個部分:
- 準備線上推斷所需的特征,拼接成 JSON 格式的特征樣本;
- 把所有候選物品的特征樣本批量發送給 TensorFlow Serving API;
- 根據 TensorFlow Serving API 回傳的推斷得分進行排序,生成推薦串列,
3.1 特征樣本的拼接
首先,第一步的實作重點在于特征樣本的拼接,
因為實踐例子里,選用了 NeuralCF 作為排序模型,而 NerualCF 所需的特征只有 userId 和 itemId ,所以特征是比較好準備的,
如何拼接特征形成模型推斷所需的樣本:
代碼參考:com.wzhe.sparrowrecsys.online.recprocess.RecForYouProcess
/**
* call TenserFlow serving to get the NeuralCF model inference result
* @param user input user
* @param candidates candidate movies
* @param candidateScoreMap save prediction score into the score map
*/
public static void callNeuralCFTFServing(User user, List<Movie> candidates, HashMap<Movie, Double> candidateScoreMap){
if (null == user || null == candidates || candidates.size() == 0){
return;
}
//保存所有樣本的JSON陣列
JSONArray instances = new JSONArray();
for (Movie m : candidates){
JSONObject instance = new JSONObject();
//為每個樣本添加特征,userId和movieId
instance.put("userId", user.getUserId());
instance.put("movieId", m.getMovieId());
instances.put(instance);
}
JSONObject instancesRoot = new JSONObject();
instancesRoot.put("instances", instances);
//請求TensorFlow Serving API
String predictionScores = asyncSinglePostRequest("http://localhost:8501/v1/models/recmodel:predict", instancesRoot.toString());
//獲取回傳預估值
JSONObject predictionsObject = new JSONObject(predictionScores);
JSONArray scores = predictionsObject.getJSONArray("predictions");
//將預估值加入回傳的map
for (int i = 0 ; i < candidates.size(); i++){
candidateScoreMap.put(candidates.get(i), scores.getJSONArray(i).getDouble(0));
}
}
在代碼中:
- 先把
userId和movieId加入了 JSON 格式的樣本中,然后再把樣本加入到 Json 陣列中, - 接下來,我們又以 http post 請求的形式把這些 JSON 樣本發送給 TensorFlow Serving 的 API,進行批量預估,
- 在收到預估得分后,保存在候選集 map 中,供排序層進行排序,
3.2 建立起 TensorFlow Serving API
第二步的重點在于如何建立起 TensorFlow Serving API
通過之前的模型服務部分,搭建起一個測驗模型的 API 了,想要搭建起我們自己的 TensorFlow Serving API,只需要把之前載入的測驗模型檔案換成我們自己的模型檔案就可以了,這里以 NerualCF 模型為例,看一看模型檔案是如何被匯出和匯入的,
(1)模型的匯出
首先是模型的匯出,在 NeuralCF 的 TensorFlow 實作中,我們已經把訓練好的模型保存在了 model 這個結構中,接下來需要呼叫 tf.keras.models.save_model 這一函式來把模型序列化,
下面的代碼中,這一函式需要傳入的引數有要保存的 model 結構,保存的路徑,還有是否覆寫路徑 overwrite 等等,
注意保存路徑,可以看到在保存路徑中加上了一個模型版本號 002,這對于 TensorFlow Serving 是很重要的,因為 TensorFlow Serving 總是會找到版本號最大的模型檔案進行載入,這樣做就保證了我們每次載入的都是最新訓練的模型,詳細代碼參考 NeuralCF.py,
tf.keras.models.save_model(
model,
"file:///Users/zhewang/Workspace/SparrowRecSys/src/main/resources/webroot/modeldata/neuralcf/002",
overwrite=True,
include_optimizer=True,
save_format=None,
signatures=None,
options=None
)
(2)模型的匯入
其次是模型的匯入,匯入命令就是 TensorFlow Serving API 的啟動命令,我們直接看下面命令中的引數,
docker run -t --rm -p 8501:8501 -v "/Users/zhewang/Workspace/SparrowRecSys/src/main/resources/webroot/modeldata/neuralcf:/models/recmodel" -e MODEL_NAME=recmodel tensorflow/serving &
這里面最重要的引數,就是指定載入模型的路徑和預估 url,而載入路徑就是我們剛才保存模型的路徑:/Users/zhewang/Workspace/SparrowRecSys/src/main/resources/webroot/modeldata/neuralcf,但是在這里,我們沒有加模型的版本號,這是為什么呢?因為版本號是供 TensorFlow Serving 查找最新模型用的,TensorFlow Serving 在模型路徑上會自動找到版本號最大的模型載入,因此不可以在載入路徑上再加上版本號,
除此之外,冒號后的部分“/models/recmodel”指的是 TensorFlow Serving API 在這個模型上的具體 url,剛才我們是通過請求 http://localhost:8501/v1/models/recmodel:predict 獲取模型預估值的,請求連接中的 models/recmodel就是在這里設定的,
在正確執行上面的命令后,就可以在 Docker 上運行起 TensorFlow Serving 的 API 了,
3.3 獲取回傳得分和排序
最后,我們來看第三步的實作重點:獲取回傳得分和排序,
先來看一下 TensorFlow Serving API 的回傳得分格式,它的回傳值也是一個 JSON 陣列的格式,陣列中每一項對應著之前發送過去的候選電影樣本,所以我們只要把回傳的預估值賦給相應的樣本,然后按照預估值排序就可以了,
參考 com.wzhe.sparrowrecsys.online.recprocess.RecForYouProcess 中全部排序層的代碼,
{
"predictions": [[0.824034274], [0.86393261], [0.921346784], [0.957705915], [0.875154734], [0.905113697], [0.831545711], [0.926080644], [0.898158073]...
]
}
如果已經正確建立起了 Redis 和 TensorFlow Serving API 服務,并且已經分別匯入了特征資料和模型檔案,我們就可以啟動 Sparrow Recsys Server,查看“猜你喜歡”的結果了,用戶 ID 為 6 的用戶在 NerualCF 模型下的推薦結果(http://localhost:6010/user.html?id=6&model=nerualcf),注意通過在連接中設定 model 變數為 nerualcf,來決定產生結果的模型,
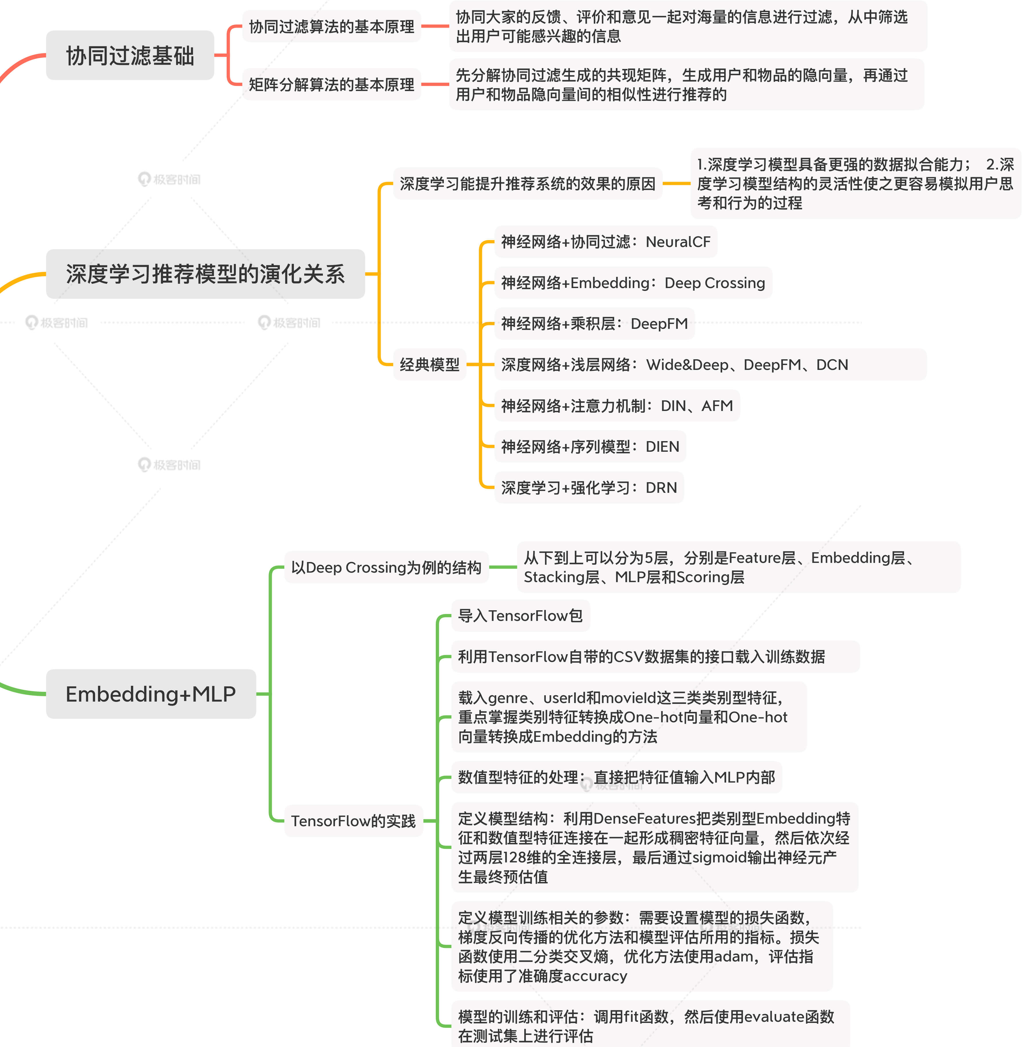
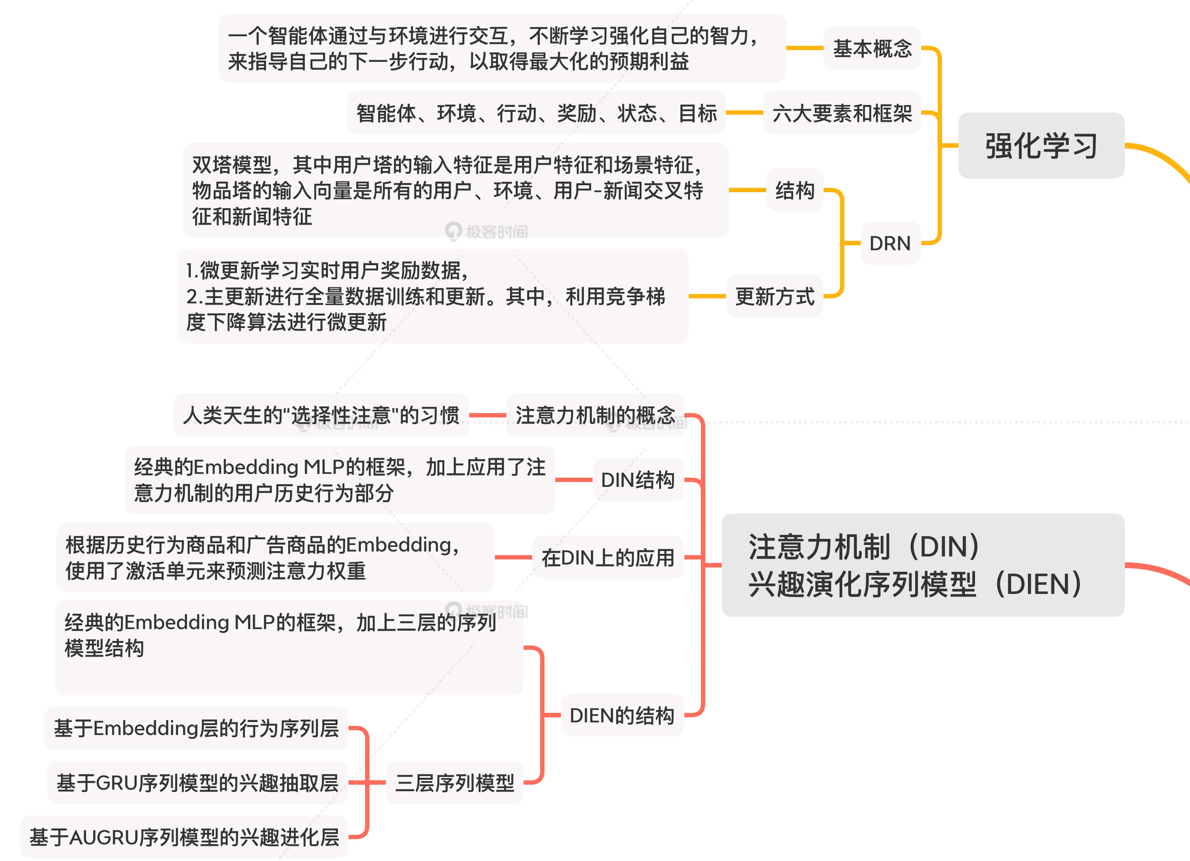
四、思維導圖
4.1 基礎模型
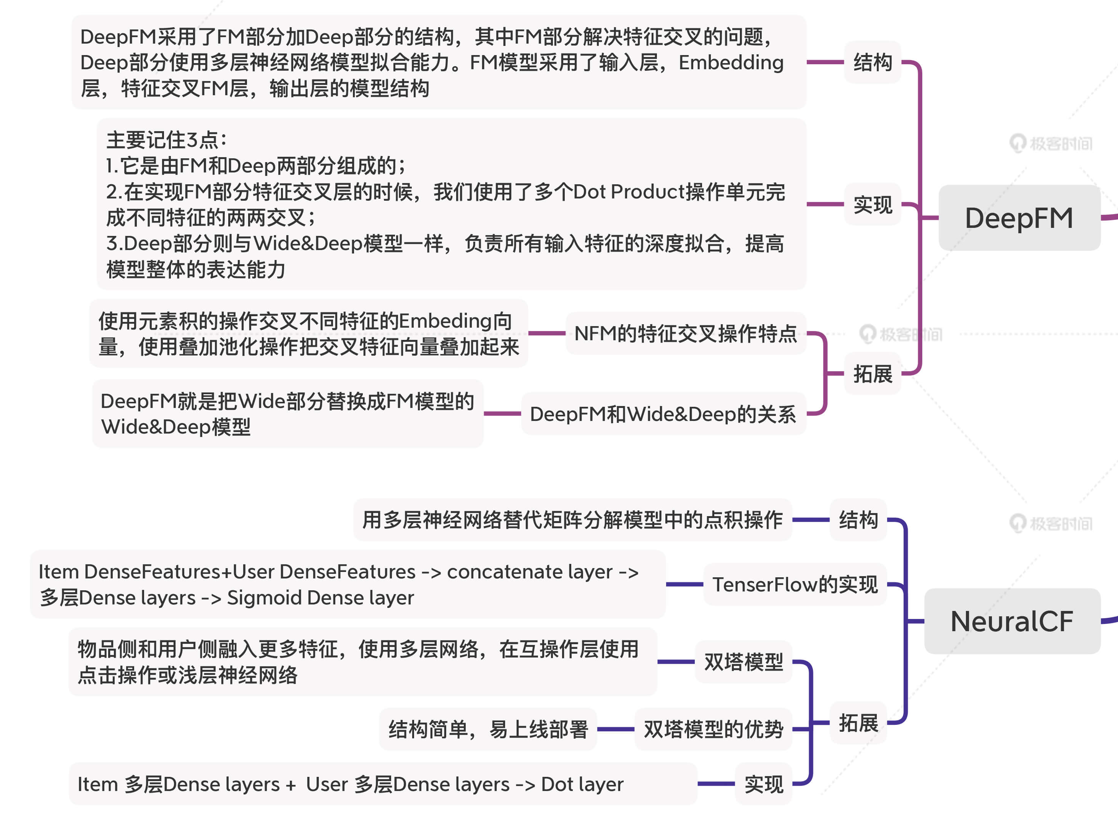
4.2 進階模型

4.3 前沿模型
五、作業
推薦系統的特征預處理是一項很重要的作業,比如一些連續特征的歸一化,分桶等等,那么這些預處理的程序,我們應該放在線上部分的哪里完成呢?是在 Tensorflow Serving 的部分,還是在推薦服務器內部,還是在離線部分完成?你有什么好的想法嗎?
【答】推薦服務器內部專門開發特征加工模塊,進行一些人工的處理,比如點擊率特征,實際上“點擊”會包含多種點擊行為,各種行為如何融合,需要靈活配置,既不能放在離線存(更新不便),也不能放在tf serving里(邏輯多了太慢)
1、tf serving只負責簡單的模型運算;
2、離線redis等負責通用特征資料的存盤;
3、推薦系統服務器進行資料加工
線上服務篇的task2:
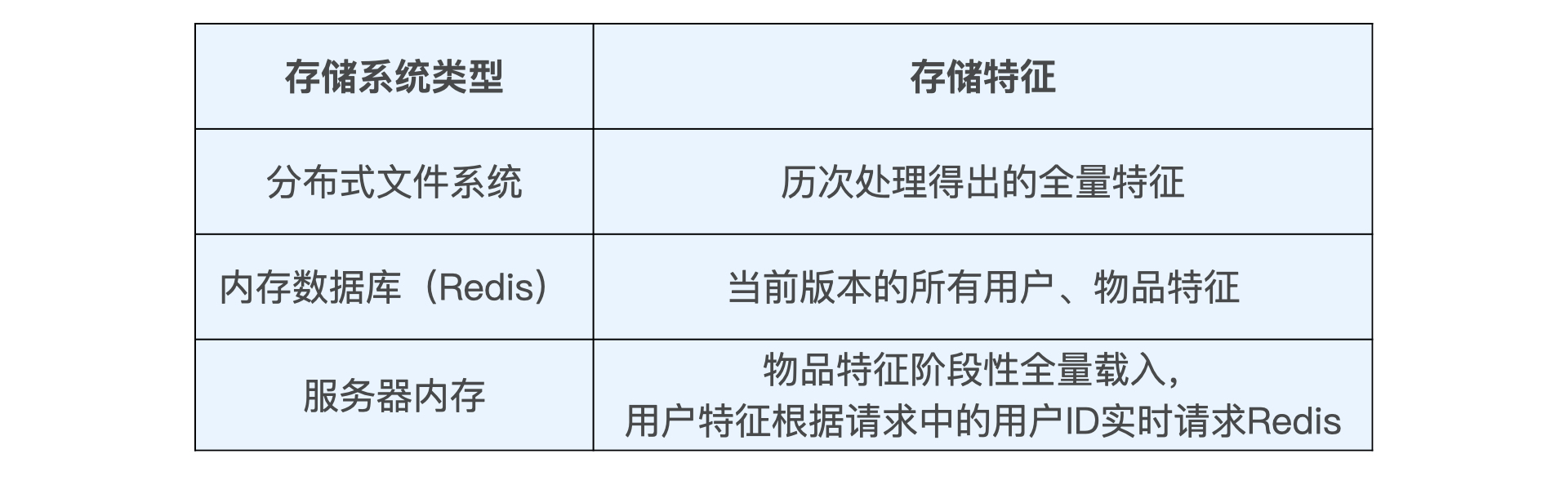 :
:
六、課后答疑
(1)Sparrow專案代碼中新增了pyspark推薦系統的工程實作部分,對于大資料量的特征工程處理,選擇用scala還是python版的spark實作有沒有什么建議?
【答】現實作業中建議最好還是用scala來維護,畢竟是spark原生支持的語言,真正的大資料工程師一般會使用scala,但是也不反對python來維護,跟其他python專案在一起維護會方便些,
spark+tf 正常演算法工程師主要會這兩個,實時計算和推薦引擎應該有其他的同事負責,如果這幾個部分還沒拆分開的話,可能你們還沒有達到必須要用推薦的時候,可以將實時計算給忽略,都去做的話,就什么也不會精通,也只有在小公司里了,個人(ID:范思思)最近一段時間面試的結論,僅供參考,你可以什么都學過一點,但一定要有一個十分精通的技術,作為下一步發展的目標
(2)特征處理這部分,應該是離線計算好得到每個特征的map資料,在推薦服務器內部加載這些map資料,直接將原始特征映射成深度學習需要的向量,將得到的向量送入Tensorflow Serving得到推薦結果
如果在Tensorflow Serving做特征預處理的作業,會導致推薦服務的回應時間邊長
【答】最好是可以在推薦服務器內部把特征都準備好,處理好,tf serving只做inference,不承擔太多特征預處理壓力,
(3)現在邊緣計算或端智能,多大程度解決了用戶特征更新的問題,端智能的應用前景如何?
【答】王喆大佬說看好邊緣計算的發展,一直是近兩年看好的方向,至于多大程度解決了特征更新的問題,覺得他們會一直共存,邊緣計算永遠也替代不了服務器端的特征更新設施,
Reference
(1)https://github.com/wzhe06/Reco-papers
(2)《深度學習推薦系統實戰》,王喆
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354571.html
標籤:其他
下一篇:Kafka--原理--冪等/事務