Hadoop
Hadoop是Apache軟體基金會旗下的一款Java開源軟體框架,提供了大資料存盤、計算的一套解決方案,
- Hadoop HDFS 分布式檔案系統:解決海量資料存盤
- Hadoop MAPREDUCE 分布式運算編程框架:解決海量資料計算
- Hadoop YARN 作業調度和集群資源管理框架:解決集群資源任務調度
-
海量資料如何存盤?
分布式存盤
-
海量資料如何計算?
分布式計算
1. 大資料導論
1.1 大資料概念
資料:
- 是事實或觀察的結果
- 是對客觀事物的邏輯歸納
- 適用于表示客觀事物的未經加工的原始素材
資料的產生:
- 對客觀事物的計量和記錄產生資料
資料存盤單位:

大資料:
- 是指無法在一定時間范圍內用常規軟體工具進行捕捉、管理和處理的資料結合
- 是需要新處理模式才能具有更強的決策力、洞察發現里和流程優化能力的海量、高增長率
大資料時代:
- 《大資料時代》紀錄片
挑戰:
- 存盤
- 計算
1.2 大資料特點5V
- Volume 資料體量大
- 采集資料量大
- 存盤資料量大
- 計算資料量大
- TB、PB級別起步
- Variety 種類、來源多樣化
- 種類:結構化(便于決議的資料)、半結構化(json)、非結構化
- 來源:日志文本、圖片…
- Value 低價值密度
- 資訊海量但是價值密度低
- 深度復雜的挖掘分析需要機器學習參與
- Velocity 速度快
- 資料增長速度快
- 獲取資料速度快
- 資料處理速度快
- Veracity 資料的質量
- 資料的準確性
- 資料的可信賴度
1.3 大資料應用場景
-
電商領域
精準廣告位、個性化推薦、大資料殺熟
-
傳媒領域
精準營銷、猜你喜歡、互動推薦
-
金融領域
信用評估、風險管控、客戶細分、精細化營銷
-
交通領域
擁堵預測、智能紅綠燈、導航最優規劃
-
電信領域
-
醫療領域
智慧醫療、疾病預防、病原追蹤
-
……
1.4 大資料業務分析基本步驟
-
明確分析目的和思路
-
目的是整個分析流程的起點
-
思路是使分析框架體系化
-
資料分析方法論:營銷管理相關理論
用戶行為理論、PEST分析法、5W2H分析法、邏輯樹分析法、4P營銷理論
-
-
資料收集
-
資料從無到有的程序
-
資料傳輸搬運的程序
-
業務資料 RDBMS
-
日志資料
-
爬蟲資料
-
互聯網公開資料
-
-
-
資料處理
資料清洗、資料轉換、資料提取、資料計算
-
資料分析
- 用適當的分析方法及工具,對處理過的資料進行分析
- 資料挖掘本質是一種高級的資料分析方法
-
資料展現
資料可視化
-
報告撰寫
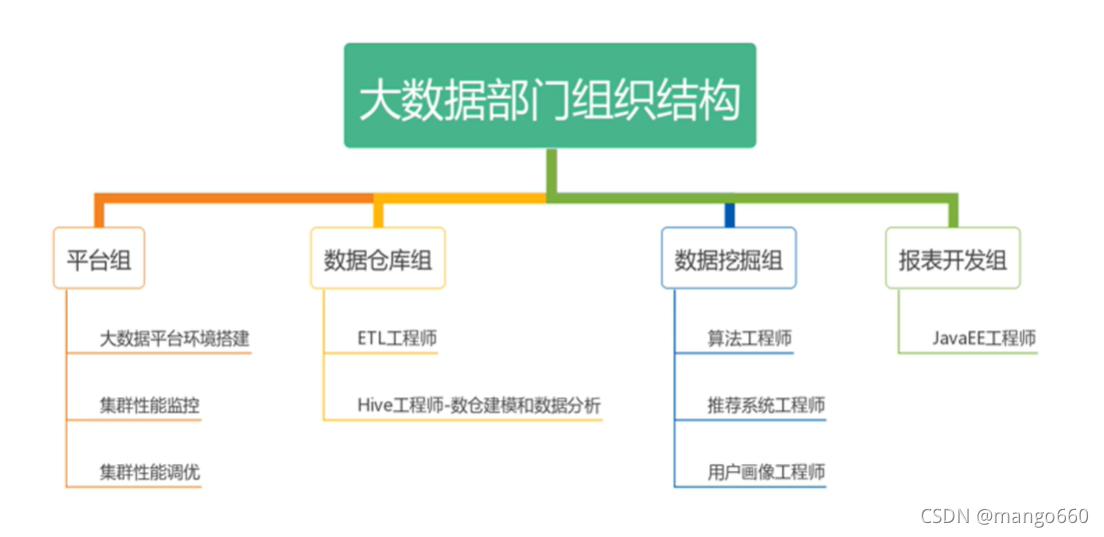
1.5 大資料部門組織架構
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354574.html
標籤:其他
上一篇:Kafka--原理--冪等/事務