Druid 非中文官網,內容不少且介紹的挺詳細的,需要英文閱讀能力或者翻譯工具進行輔助,
1. 是什么
先看看官網怎么說:
Apache Druid is an open source distributed data store. Druid’s core design combines ideas from data warehouses, timeseries databases, and search systems to create a high performance real-time analytics database for a broad range of use cases. Druid merges key characteristics of each of the 3 systems into its ingestion layer, storage format, querying layer, and core architecture.
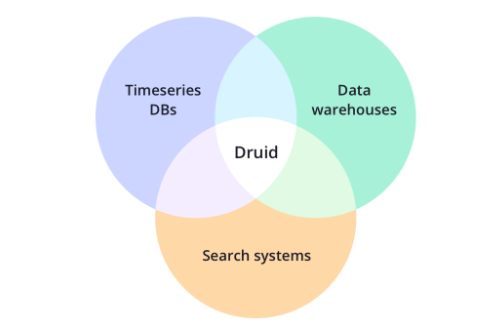
Druid 是一個分布式的支持實時分析的資料存盤系統(Data Store),Druid 設計之初的想法就是為分析而生,它在處理資料的規模、資料處理的實時性方面,比傳統的OLAP 系統有了顯著的性能改進,而且擁抱主流的開源生態,包括Hadoop 等,
Druid應用最多的是類似于廣告分析創業公司MetaMarkets中的應用場景,如廣告分析、互聯網廣告系統監控以及網路監控等,當業務中出現以下情況時,Druid是一個很好的技術方案選擇:
- 需要互動式聚合和快速探究大量資料時;
- 具有大量資料時,如每天數億事件的新增、每天數10T資料的增加;
- 對資料尤其是大資料進行實時分析時;
- 需要一個高可用、高容錯、高性能資料庫時,
2. 主要特點
官網的8大特點:
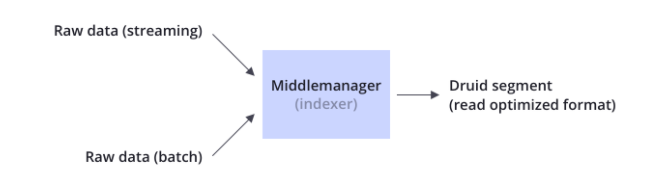
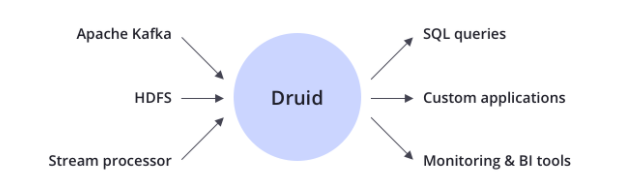
Column-oriented storage列式存盤格式,Druid使用面向列的存盤,這意味著,它只需要加載特定查詢所需要的列,這為只差看幾列的查詢提供了巨大的速度提升,此外,每列都針對其特定的資料型別進行優化,支持快速掃描和聚合,Native search indexes本地化的搜索索引,Druid為字串值創建反向索引,使用CONCISE或Roaring壓縮位圖索引來創建索引,這些索引可以快速過濾和跨多個列搜索,Streaming and batch ingest實時或批量攝取,提供 Apache Kafka, HDFS, AWS S3,流處理器等的開箱即用連接器,可以實時攝取資料(實時獲取的資料可立即用于查詢)或批量處理資料,
Flexible schemas模式靈活,Druid優雅地處理演進的模式和嵌套的資料,
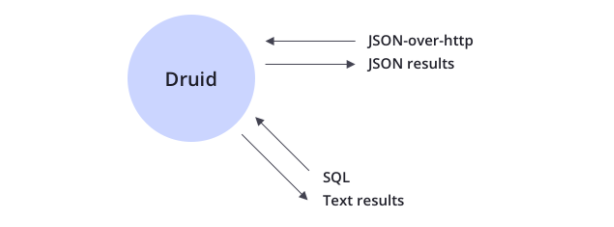
Time-optimized partitioning實時優化磁區,Druid基于時間和基于時間的查詢智能地劃分資料,比傳統資料庫快得多,SQL supportSQL支持,除了原生的基于JSON的語言,Druid還通過HTTP或JDBC使用SQL,Druid支持通過 json over http 和SQL查詢資料,除了標準SQL運算子外,Druid還支持獨特的運算子,這些運算子利用其近似演算法套件來提供快速計數、排序和分位數,
Horizontal scalability水平伸縮(可擴展的分布式系統),Druid通常部署在數十到數百臺服務器的集群中,并且提供數百萬條/秒的攝取率,保留數百萬條記錄,以及亞秒級到幾秒鐘的查詢延遲,Easy operation操作簡單,集群擴展和縮小,只需添加或洗掉服務器,集群將在后臺自動重新平衡,無需任何停機時間,容錯架構圍繞服務器故障進行路由,
可以提煉出的特點:
Druid可以在整個集群中進行大規模的并行查詢,支持原生云、容錯的架構,不會丟失資料,一旦Druid吸收了您的資料,副本就安全地存盤在深度存盤中(通常是云存盤、HDFS或共享檔案系統),即使每個Druid服務器都失敗,也可以從深層存盤恢復資料,對于僅影響少數Druid服務器的更有限的故障,復制確保在系統恢復時仍然可以執行查詢,
Druid包括用于近似計數、近似排序以及計算近似直方圖和分位數的演算法,這些演算法提供了有限的記憶體使用,并且通常比精確計算快得多,對于準確度比速度更重要的情況,Druid還提供精確的計數-明確和準確的排名,
插入資料時自動聚合,Druid可選地支持攝取時的資料自動匯總,預先匯總了您的資料,并且可以導致巨大的成本節約和性能提升,
3. 三個設計原則
1?? Fast Query 快速查詢:部分資料的聚合(Partial Aggregate)+ 記憶體化(In-emory)+ 索引(Index),
??對于資料分析場景,大部分情況下,我們只關心一定粒度聚合的資料,而非每一行原始資料的細節情況,因此,資料聚合粒度可以是1 分鐘、5 分鐘、1 小時或1 天等,部分資料聚合(Partial Aggregate)給Druid 爭取了很大的性能優化空間,
??資料記憶體化也是提高查詢速度的殺手锏,記憶體和硬碟的訪問速度相差近百倍,但記憶體的大小是非常有限的,因此在記憶體使用方面要精細設計,比如Druid 里面使用了Bitmap 和各種壓縮技術,
另外,為了支持Drill-Down 某些維度,Druid 維護了一些倒排索引,這種方式可以加快AND 和OR 等計算操作,
2?? Horizontal Scalability 水平擴展能力:分布式資料(Distributed Data)+ 并行化查詢(Parallelizable Query),
??Druid 查詢性能在很大程度上依賴于記憶體的優化使用,資料可以分布在多個節點的記憶體中,因此當資料增長的時候,可以通過簡單增加機器的方式進行擴容,為了保持平衡,Druid按照時間范圍把聚合資料進行磁區處理,對于高基數的維度,只按照時間切分有時候是不夠的(Druid 的每個Segment 不超過2000 萬行),故Druid 還支持對Segment 進一步磁區,
??歷史Segment 資料可以保存在深度存盤系統中,存盤系統可以是本地磁盤、HDFS 或遠程的云服務,如果某些節點出現故障,則可借助Zookeeper 協調其他節點重新構造資料,
??Druid 的查詢模塊能夠感知和處理集群的狀態變化,查詢總是在有效的集群架構中進行,集群上的查詢可以進行靈活的水平擴展,
3?? Realtime Analytics 實時分析:不可變的過去,只追加的未來(Immutable Past,Append-Only Future)這個特點跟HBase很像,
??Druid 提供了包含基于時間維度資料的存盤服務,并且任何一行資料都是歷史真實發生的事件,因此在設計之初就約定事件一但進入系統,就不能再改變,
??對于歷史資料Druid 以Segment 資料檔案的方式組織,并且將它們存盤到深度存盤系統中,例如檔案系統或亞馬遜的S3 等,當需要查詢這些資料的時候,Druid 再從深度存盤系統中將它們裝載到記憶體供查詢使用,
4. Architecture 架構
【官網介紹】基于微服務的體系結構,可以看作是一個可分解的資料庫,Druid中的每個核心服務(攝取、查詢和協調)可以單獨或聯合部署在商用硬體上,Druid明確地命名了每個主要服務,允許操作員根據用例和作業負載對每個服務進行微調,例如,如果作業負載需要,操作員可以將更多的資源分配給Druid的攝取服務,而將更少的資源分配給Druid的查詢服務,Druid服務可以獨立故障而不影響其他服務的操作,
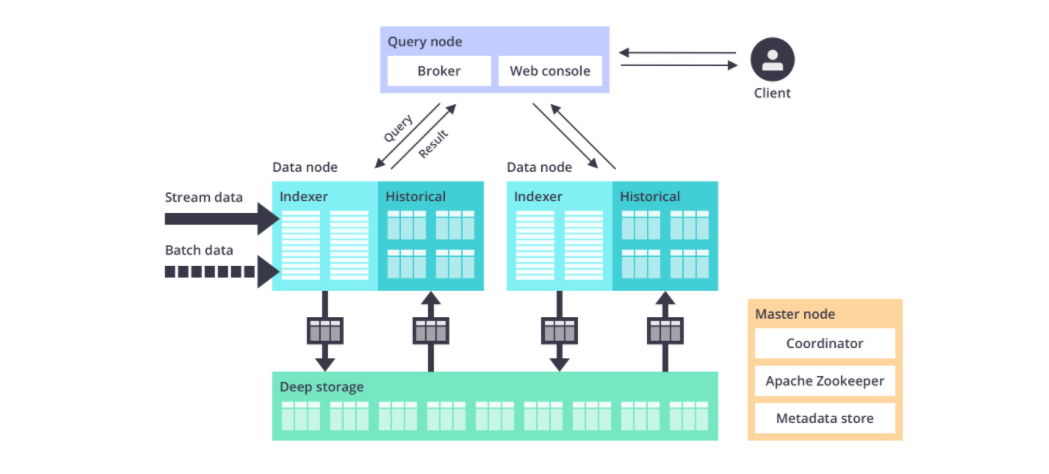 Druid總體包含 5?? 類節點:
Druid總體包含 5?? 類節點:
MiddleManager Node中間管理節點:及時攝入實時資料,已生成Segment資料檔案,Historical Node歷史節點:加載已生成好的資料檔案,以供資料查詢,historical 節點是整個集群查詢性能的核心所在,因為historical會承擔絕大部分的segment查詢,Broker Node查詢節點:接收客戶端查詢請求,并將這些查詢轉發給Historicals和MiddleManagers,當Brokers從這些子查詢中收到結果時,它們會合并這些結果并將它們回傳給呼叫者,Coordinator Node協調節點:主要負責歷史節點的資料負載均衡,以及通過規則(Rule)管理資料的生命周期,協調節點告訴歷史節點加載新資料、卸載過期資料、復制資料、和為了負載均衡移動資料,Overlord Node統治者:行程監視MiddleManager行程,并且是資料攝入Druid的控制器,他們負責將提取任務分配給MiddleManagers并協調Segement發布,
Druid還包含 3?? 類外部依賴:
Deep Storage資料檔案存盤庫:存放生成的Segment資料檔案,并供歷史服務器下載,對于單節點集群可以是本地磁盤,而對于分布式集群一般是HDFS,Metadata Store元資料庫:存盤Druid集群的元資料資訊,比如Segment的相關資訊,一般用MySQL或PostgreSQL,Zookeeper:為Druid集群提供以執行協調服務,如內部服務的監控,協調和領導者選舉,
5. 資料結構
與Druid架構相輔相成的是其基于DataSource與Segment的資料結構,它們共同成就了Druid的高性能優勢,
5.1 DataSource 結構
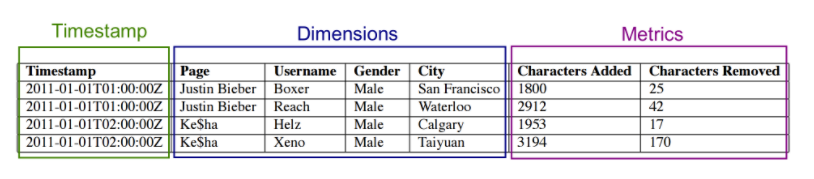
與傳統的關系型資料庫管理系統比較,Druid的DataSource可以理解為 RDBMS 中的表Table,DataSource的結構包含以下幾個方面:
Timestamp時間列:表明每行資料的時間值,默認使用 UTC時間格式且精確到毫秒級別,這個列是資料聚合與范圍查詢的重要維度,跟HBase的時間戳類似,Dimensions維度列:維度來自于 OLAP 的概念,用來標識資料行的各個類別資訊,Metrics指標列:指標對應于 OLAP 概念中的 Fact,是用于聚合和計算的列,這些指標列通常是一些數字,計算操作通常包括 Count、Sum 和 Mean等,
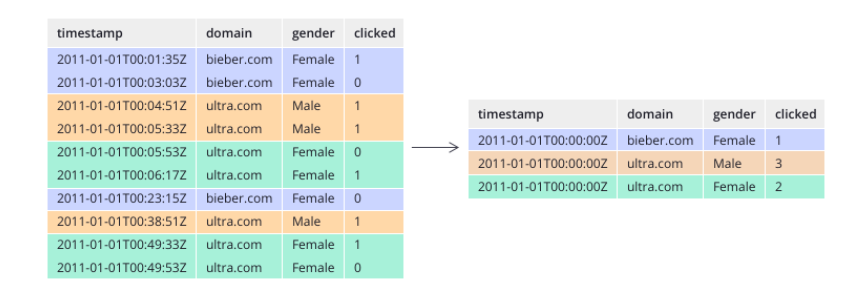
無論是實時資料消費還是批量資料處理, Druid在基于DataSource結構存盤資料時即可選擇對任意的指標列進行聚合( RollUp)操作,該聚合操作主要基于維度列與時間范圍兩方面的情況,
下圖顯示的是執行聚合操作后 DataSource的資料情況,

相對于其他時序資料庫, Druid在資料存盤時便可對資料進行聚合操作是其一大特點,該特點使得 Druid不僅能夠節省存盤空間,而且能夠提高聚合查詢的效率,
5.2 Segment 結構
DataSource是一個邏輯概念, Segment卻是資料的實際物理存盤格式, Druid正是通過 Segment 實作了對資料的橫縱向切割( Slice and Dice)操作,從資料按時間分布的角度來看,通過引數 segmentGranularity 的設定,Druid將不同時間范圍內的資料存盤在不同的 Segment資料塊中,這便是所謂的資料橫向切割,

這種設計為 Druid 帶來一個顯而易見的優點:按時間范圍查詢資料時,僅需要訪問對應時間段內的這些 Segment資料塊,而不需要進行全表資料范圍查詢,這使效率得到了極大的提高,
通過 Segment將資料按時間范圍存盤,同時,在 Segment中也面向列進行資料壓縮存盤,這便是所謂的資料縱向切割,而且在 Segment中使用了 Bitmap等技術對資料的訪問進行了優化,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354578.html
標籤:其他