目錄
- 1 HDFS 的 Shell 操作(開發重點)
- 2 HDFS的常見Shell操作
- 2.1 ls:查詢指定路徑資訊
- 2.2 put:從本地上傳檔案
- 2.3 cat:查看HDFS檔案內容
- 2.4 get:下載檔案到本地
- 2.5 mkdir [-p]:創建檔案夾
- 2.6 rm [-r]:洗掉檔案/檔案夾
- 3 HDFS案例實操
- 4 Java代碼操作HDFS
- 4.1 配置Windows下Hadoop環境
- 5 資料上傳/下載的原理及程序
1 HDFS 的 Shell 操作(開發重點)
通過前面的學習,我們對HDFS有了基本的了解,下面我們就想實際操作一下,來通過實操加深對HDFS的理解
針對HDFS,我們可以在shell命令列下進行操作,就類似于我們操作linux中的檔案系統一樣,但是具體命令的操作格式是有一些區別的
格式如下:
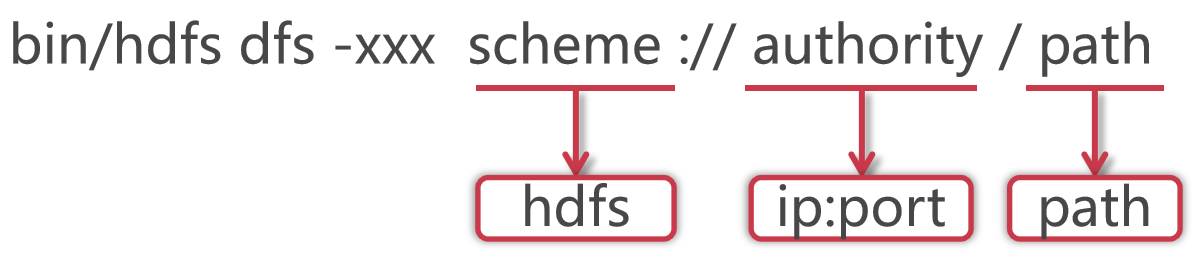
使用hadoop bin目錄的hdfs命令,后面指定dfs,表示是操作分布式檔案系統的,這些屬于固定格式,
如果在PATH中配置了hadoop的bin目錄,那么這里可以直接使用hdfs就可以了
這里的xxx是一個占位符,具體我們想對hdfs做什么操作,就可以在這里指定對應的命令了
大多數hdfs 的命令和對應的Linux命令類似
HDFS的schema是hdfs,authority是集群中namenode所在節點的ip和對應的埠號,把ip換成主機名也是一樣的,path是我們要操作的檔案路徑資訊
其實后面這一長串內容就是core-site.xml組態檔中fs.defaultFS屬性的值,這個代表的是HDFS的地址,
2 HDFS的常見Shell操作
下面我們就來學習一下HDFS中的一些常見的shell操作
其實hdfs后面支持很多的引數,但是有很多是很少用的,在這里我們把一些常用的帶著大家一塊學習一下,如果大家后期有一些特殊的需求,可以試著來看一下hdfs的幫助檔案
直接在命令列中輸入hdfs dfs,可以查看dfs后面可以跟的所有引數
注意:這里面的[]表示是可選項,<>表示是必填項
[root@bigdata01 hadoop-3.2.0]# hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
2.1 ls:查詢指定路徑資訊
首先看第一個ls命令
查看hdfs根目錄下的內容,什么都不顯示,因為默認情況下hdfs中什么都沒有
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls hdfs://bigdata01:9000/
[root@bigdata01 hadoop-3.2.0]#
其實后面hdfs的url這一串內容在使用時默認是可以省略的,因為hdfs在執行的時候會根據HDOOP_HOME自動識別組態檔中的fs.defaultFS屬性
所以這樣簡寫也是可以的
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
[root@bigdata01 hadoop-3.2.0]#
2.2 put:從本地上傳檔案
接下來我們向hdfs中上傳一個檔案,使用Hadoop中的README.txt,直接上傳到hdfs的根目錄即可
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put README.txt /
上傳成功之后沒有任何提示,注意,沒有提示就是最好的結果
確認一下剛才上傳的檔案
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 1 items
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
在這里可以發現使用hdfs中的ls查詢出來的資訊和在linux中執行ll查詢出來的資訊是類似的
在這里能看到這個檔案就說明剛才的上傳操作是成功的
2.3 cat:查看HDFS檔案內容
檔案上傳上去以后,我們還想查看一下HDFS中檔案的內容,很簡單,使用cat即可
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /README.txt
For the latest information about Hadoop, please visit our website at:
http://hadoop.apache.org/
and our wiki, at:
http://wiki.apache.org/hadoop/
...........
2.4 get:下載檔案到本地
如果我們想把hdfs中的檔案下載到本地linux檔案系統中需要怎么做呢?使用get即可實作
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -get /README.txt .
get: `README.txt': File exists
注意:這樣執行報錯了,提示檔案已存在,我這條命令的意思是要把HDFS中的README.txt下載當前目錄中,但是當前目錄中已經有這個檔案了,要么換到其它目錄,要么給檔案重命名
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -get /README.txt README.txt.bak
[root@bigdata01 hadoop-3.2.0]# ll
total 188
drwxr-xr-x. 2 1001 1002 203 Jan 8 2019 bin
drwxr-xr-x. 3 1001 1002 20 Jan 8 2019 etc
drwxr-xr-x. 2 1001 1002 106 Jan 8 2019 include
drwxr-xr-x. 3 1001 1002 20 Jan 8 2019 lib
drwxr-xr-x. 4 1001 1002 4096 Jan 8 2019 libexec
-rw-rw-r--. 1 1001 1002 150569 Oct 19 2018 LICENSE.txt
-rw-rw-r--. 1 1001 1002 22125 Oct 19 2018 NOTICE.txt
-rw-rw-r--. 1 1001 1002 1361 Oct 19 2018 README.txt
-rw-r--r--. 1 root root 1361 Apr 8 15:41 README.txt.bak
drwxr-xr-x. 3 1001 1002 4096 Apr 7 22:08 sbin
drwxr-xr-x. 4 1001 1002 31 Jan 8 2019 share
2.5 mkdir [-p]:創建檔案夾
后期我們需要在hdfs中維護很多檔案,所以就需要創建檔案夾來進行分類管理了
下面我們來創建一個檔案夾,hdfs中使用mkdir命令
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -mkdir /test
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 2 items
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-08 15:43 /test
如果要遞回創建多級目錄,還需要再指定-p引數
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -mkdir -p /abc/xyz
You have new mail in /var/spool/mail/root
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 3 items
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-08 15:44 /abc
drwxr-xr-x - root supergroup 0 2020-04-08 15:43 /test
想要遞回顯示所有目錄的資訊,可以在ls后面添加-R引數
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls -R /
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:34 /README.txt
drwxr-xr-x - root supergroup 0 2020-04-08 15:44 /abc
drwxr-xr-x - root supergroup 0 2020-04-08 15:44 /abc/xyz
drwxr-xr-x - root supergroup 0 2020-04-08 15:43 /test
2.6 rm [-r]:洗掉檔案/檔案夾
如果想要洗掉hdfs中的目錄或者檔案,可以使用rm
洗掉檔案
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm /README.txt
Deleted /README.txt
洗掉目錄,注意,洗掉目錄需要指定-r引數
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm /test
rm: `/test': Is a directory
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /test
Deleted /test
如果是多級目錄,可以遞回洗掉嗎?可以
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /abc
Deleted /abc
錯誤解決:
hdfs上傳檔案沒有權限寫入的問題解決put: Permission denied: user=root, access=WRITE
問題:
如題,在上傳檔案的時候出現沒有權限寫入的問題:
命令:
hdfs dfs -put dummy_log_data /user/impala/data/logs/year=2013/month=07/day=28/host=host1
報錯資訊:
put: Permission denied: user=root, access=WRITE, inode="/user/impala/data/logs/year=2013/month=07/day=28/host=host1":hdfs:impala:drwxr-xr-x
解決:
1、查看該用戶的權限
[root@hadoop09-test1-rgtj1-tj1 test_pro]# hdfs dfs -ls /user/impala/data/logs/year=2013/month=07/day=28
Found 1 items
drwxr-xr-x - hdfs impala 0 2020-02-17 22:32 /user/impala/data/logs/year=2013/month=07/day=28/host=host1
2、切換用戶進行寫入
sudo切換用戶指定該用戶的目錄進行上傳寫入即可,
sudo -uhdfs hdfs dfs -put dummy_log_data /user/impala/data/logs/year=2013/month=07/day=28/host=host1
3 HDFS案例實操
需求:統計HDFS中檔案的個數和每個檔案的大小
我們先向HDFS中上傳幾個檔案,把hadoop目錄中的幾個txt檔案上傳上去
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put LICENSE.txt /
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put NOTICE.txt /
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -put README.txt /
1:統計根目錄下檔案的個數
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls / |grep /| wc -l
3
2:統計根目錄下每個檔案的大小,最終把檔案名稱和大小列印出來
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls / |grep / | awk '{print $8,$5}'
/LICENSE.txt 150569
/NOTICE.txt 22125
/README.txt 1361
4 Java代碼操作HDFS
4.1 配置Windows下Hadoop環境
在windows系統需要配置hadoop運行環境,否則直接運行代碼會出現以下問題:
缺少winutils.exe
缺少hadoop.dll
步驟:
第一步:將hadoop2.7.5檔案夾拷貝到一個沒有中文沒有空格的路徑下面
第二步:在windows上面配置hadoop的環境變數: HADOOP_HOME,并將%HADOOP_HOME%\bin添加到path中
第三步:把hadoop2.7.5檔案夾中bin目錄下的hadoop.dll檔案放到系統盤:C:\Windows\System32 目錄
第四步:關閉windows重啟
前面我們學習了在shell命令行下操作hdfs,shell中操作hdfs是比較常見的操作,但是在作業中也會遇到一些需求是需要通過代碼操作hdfs的,下面我們就來看一下如何使用java代碼操作hdfs,在具體操作之前需要先明確一下開發環境,代碼編輯器使用idea,當然了eclipse也可以
在創建專案的時候我們會創建maven專案,使用maven來管理依賴,是比較方便的,在這里我會把idea的安裝包和maven的安裝包發給大家,考慮可能會有同學沒有使用過maven,所以在這里大致說一下maven在windows中的安裝配置,在這里我們使用apache-maven-3.0.5-bin.zip ,當然了,其它版本也可以,沒有什么本質的區別,把apache-maven-3.0.5-bin.zip解壓到某一個目錄下面,在這里我解壓到了D:\Program Files (x86)\apache-maven-3.0.5目錄,解壓之后,建議修改一下maven的組態檔,把maven倉庫的地址修改到其它盤,例如D盤,默認是在C盤的用戶目錄下,修改D:\Program Files (x86)\apache-maven-3.0.5\conf下的settings.xml檔案,將localRepository標簽從注釋中移出來,然后將值該為D:.m2,效果如下:
這里的目錄名字可以隨意起,只要易于識別就可以
<localRepository>D:\.m2</localRepository>
這樣修改之后,maven管理的依賴jar包都會保存到D:.m2目錄下了,
接下來需要配置maven的環境變數,和windows中配置JAVA_HOME環境變數是一樣的,
先在環境變數中配置M2_HOME=D:\Program Files (x86)\apache-maven-3.0.5
然后在PATH環境變數中添加%M2_HOME%\bin即可
環境變數配置完畢以后,打開cmd視窗,輸入mvn命令,只要能正常執行就說明windows本地的maven環境配置好了,
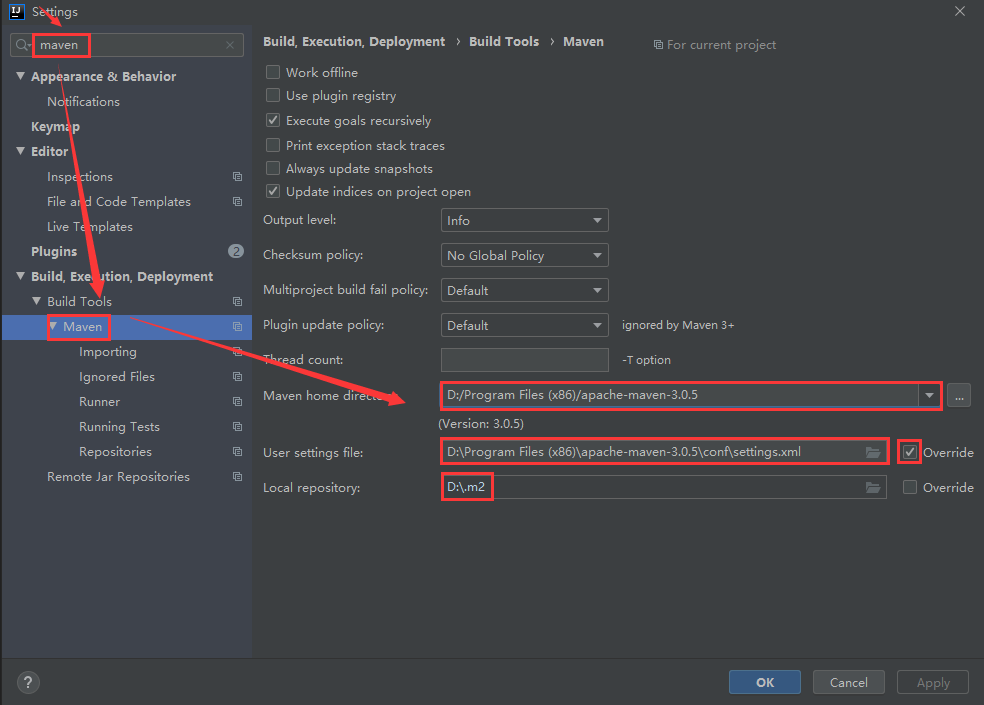
這還沒完,還需要在idea中指定我們本地的maven配置
點擊idea左上角的File–>Settings,進入如下界面,搜索maven,把本地的maven添加到這里面即可,
下面我們來創建一個maven專案
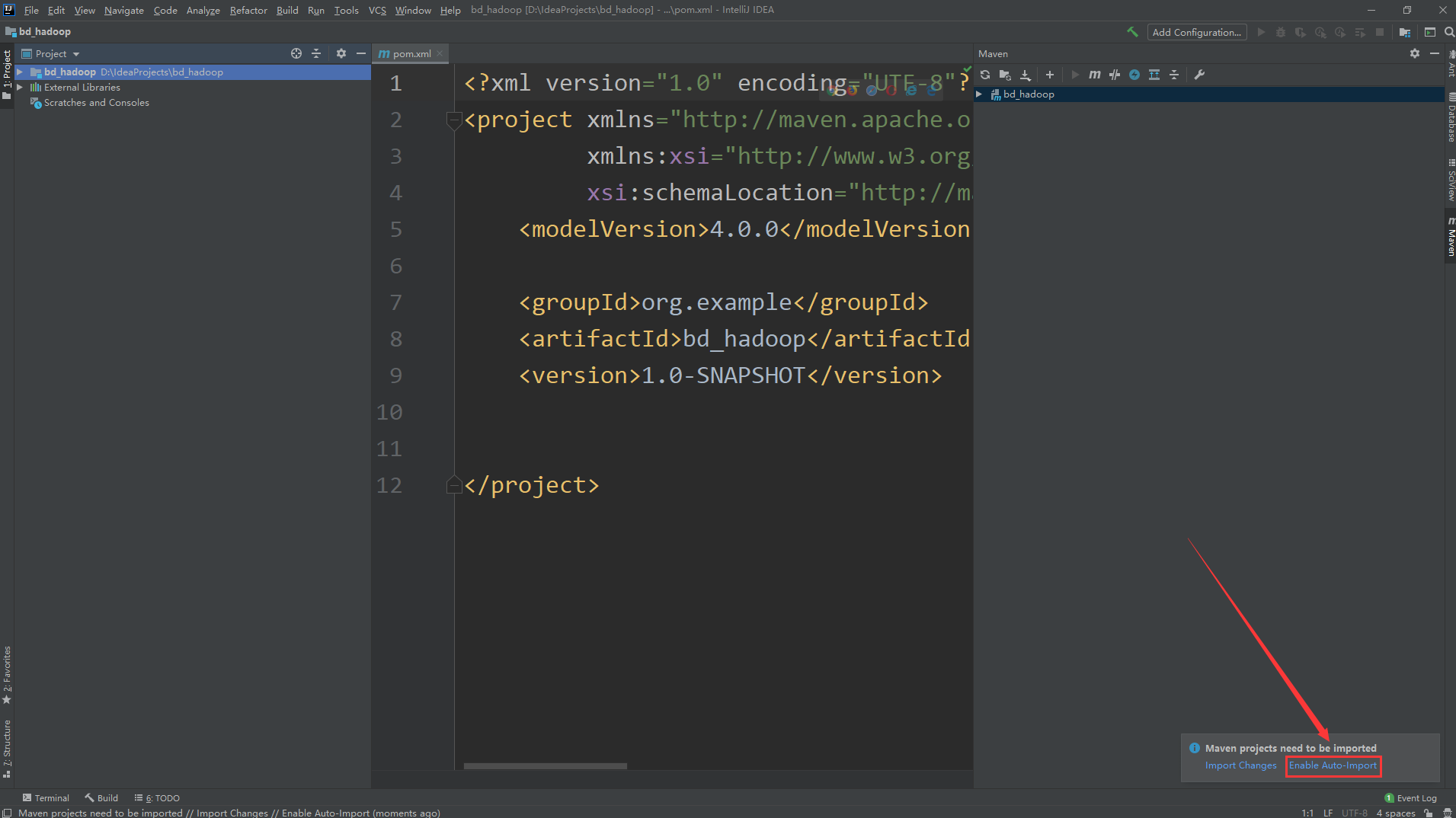
專案名稱為db_hadoop
注意:專案創建好以后,在新打開的界面中需要點擊右小角的Enable Auto Import,這樣添加到maven依賴會自動引入,否則會發現引入依賴了,但是代碼中還是識別不了,這個時候還需要手動引入,比較麻煩,
ok,專案創建好了以后,就需要引入hadoop的依賴了
在這里我們需要引入hadoop-client依賴包,到maven倉庫中去找,添加到pom.xml檔案中
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
然后創建代碼
- 上傳檔案
package com.imooc.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.net.URI;
/**
* Java代碼操作HDFS
* 檔案操作:上傳檔案、下載檔案、洗掉檔案
* Created by xuwei
*/
public class HdfsOp {
public static void main(String[] args) throws Exception{
//創建一個配置物件
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//獲取操作HDFS的物件
FileSystem fileSystem = FileSystem.get(conf);
//獲取HDFS檔案系統的輸出流
FSDataOutputStream fos = fileSystem.create(new Path("/user.txt"));
//獲取本地檔案的輸入流
FileInputStream fis = new FileInputStream("D:\\user.txt");
//上傳檔案:通過工具類把輸入流拷貝到輸出流里面,實作本地檔案上傳到HDFS
IOUtils.copyBytes(fis,fos,1024,true);
}
}
執行代碼,發現報錯,提示權限拒絕,說明windows中的這個用戶沒有權限向HDFS中寫入資料
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=yehua, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
解決辦法有兩個
第一種:去掉hdfs的用戶權限檢驗機制,通過在hdfs-site.xml中配置dfs.permissions.enabled為false即可
第二種:把代碼打包到linux中執行
在這里為了在本地測驗方便,我們先使用第一種方式
1:停止Hadoop集群
[root@bigdata01 ~]# cd /data/soft/hadoop-3.2.0
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
Stopping namenodes on [bigdata01]
Last login: Wed Apr 8 20:25:17 CST 2020 from 192.168.182.1 on pts/1
Stopping datanodes
Last login: Wed Apr 8 20:25:40 CST 2020 on pts/1
Stopping secondary namenodes [bigdata01]
Last login: Wed Apr 8 20:25:41 CST 2020 on pts/1
Stopping nodemanagers
Last login: Wed Apr 8 20:25:44 CST 2020 on pts/1
Stopping resourcemanager
Last login: Wed Apr 8 20:25:47 CST 2020 on pts/1
2:修改hdfs-site.xml組態檔
注意:集群內所有節點中的組態檔都需要修改,先在bigdata01節點上修改,然后再同步到另外兩個節點上
在bigdata01上操作
[root@bigdata01 hadoop-3.2.0]# vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
同步到另外兩個節點中
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/hdfs-site.xml bigdata02:/data/soft/hadoop-3.2.0/etc/hadoop/
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/hdfs-site.xml bigdata03:/data/soft/hadoop-3.2.0/etc/hadoop/
3:啟動Hadoop集群
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
Starting namenodes on [bigdata01]
Last login: Wed Apr 8 20:25:49 CST 2020 on pts/1
Starting datanodes
Last login: Wed Apr 8 20:29:57 CST 2020 on pts/1
Starting secondary namenodes [bigdata01]
Last login: Wed Apr 8 20:29:59 CST 2020 on pts/1
Starting resourcemanager
Last login: Wed Apr 8 20:30:04 CST 2020 on pts/1
Starting nodemanagers
Last login: Wed Apr 8 20:30:10 CST 2020 on pts/1
重新再執行代碼,沒有報錯,到hdfs上查看資料
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 4 items
-rw-r--r-- 2 root supergroup 150569 2020-04-08 15:55 /LICENSE.txt
-rw-r--r-- 2 root supergroup 22125 2020-04-08 15:55 /NOTICE.txt
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:55 /README.txt
-rw-r--r-- 3 yehua supergroup 17 2020-04-08 20:31 /user.txt
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /user.txt
jack
tom
jessic
下面還需要實作其他功能,對代碼進行封裝提取
package com.imooc.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URI;
/**
* Java代碼操作HDFS
* 檔案操作:上傳檔案、下載檔案、洗掉檔案
* Created by xuwei
*/
public class HdfsOp {
public static void main(String[] args) throws Exception{
//創建一個配置物件
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS","hdfs://bigdata01:9000");
//獲取操作HDFS的物件
FileSystem fileSystem = FileSystem.get(conf);
put(fileSystem);
}
/**
* 檔案上傳
* @param fileSystem
* @throws IOException
*/
private static void put(FileSystem fileSystem) throws IOException {
//獲取HDFS檔案系統的輸出流
FSDataOutputStream fos = fileSystem.create(new Path("/user.txt"));
//獲取本地檔案的輸入流
FileInputStream fis = new FileInputStream("D:\\user.txt");
//上傳檔案:通過工具類把輸入流拷貝到輸出流里面,實作本地檔案上傳到HDFS
IOUtils.copyBytes(fis,fos,1024,true);
}
}
- 下載檔案
執行代碼,到windows的D盤驗證檔案是否生成,如果有就表示執行成功
/**
* 下載檔案
* @param fileSystem
* @throws IOException
*/
private static void get(FileSystem fileSystem) throws IOException{
//獲取HDFS檔案系統的輸入流
FSDataInputStream fis = fileSystem.open(new Path("/README.txt"));
//獲取本地檔案的輸出流
FileOutputStream fos = new FileOutputStream("D:\\README.txt");
//下載檔案
IOUtils.copyBytes(fis,fos,1024,true);
}
- 洗掉檔案
執行洗掉操作代碼
/**
* 洗掉檔案
* @param fileSystem
* @throws IOException
*/
private static void delete(FileSystem fileSystem) throws IOException{
//洗掉檔案,目錄也可以洗掉
//如果要遞回洗掉目錄,則第二個引數需要設定為true
//如果是洗掉檔案或者空目錄,第二個引數會被忽略
boolean flag = fileSystem.delete(new Path("/LICENSE.txt"),true);
if(flag){
System.out.println("洗掉成功!");
}else{
System.out.println("洗掉失敗!");
}
}
然后到hdfs中驗證檔案是否被洗掉,從這里可以看出來/LICENSE.txt檔案已經被洗掉
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -ls /
Found 3 items
-rw-r--r-- 2 root supergroup 22125 2020-04-08 15:55 /NOTICE.txt
-rw-r--r-- 2 root supergroup 1361 2020-04-08 15:55 /README.txt
-rw-r--r-- 3 yehua supergroup 17 2020-04-08 20:31 /user.txt
我們在執行代碼的時候會發現輸出了很多紅色的警告資訊,雖然不影響代碼執行,但是看起來很礙眼,強迫癥實在忍不了
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
log4j:WARN No appenders could be found for logger (org.apache.htrace.core.Tracer).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
如何解決這個問題呢?
通過分析錯誤資訊發現第一個是缺少log4j的實作類,第二個是缺少log4j的組態檔
1:pom.xml中增加log4j依賴
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.10</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.10</version>
</dependency>
2:resources目錄下添加log4j.properties檔案
在專案的src\main\resources目錄中添加log4j.properties
log4j.properties檔案內容如下:
log4j.rootLogger=info,stdout
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
再執行代碼,發現就不會有那些紅色的警告資訊了,
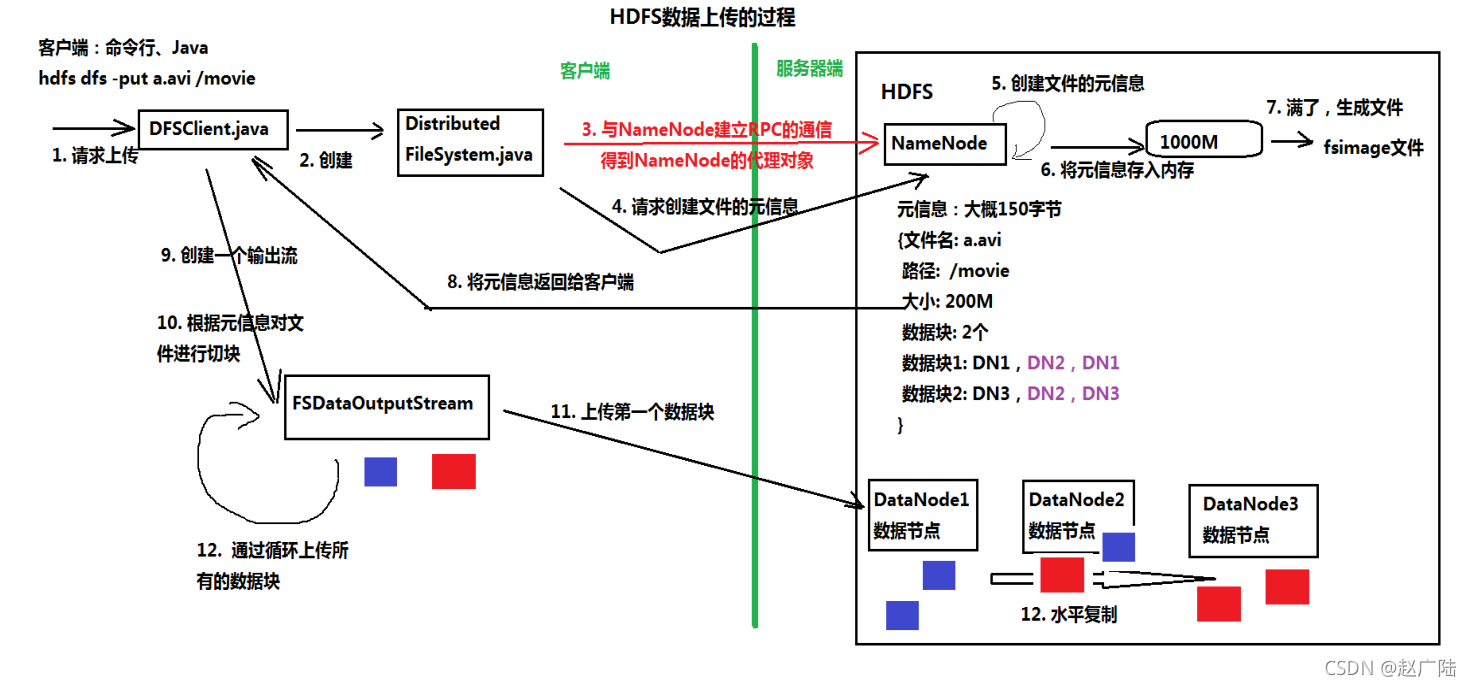
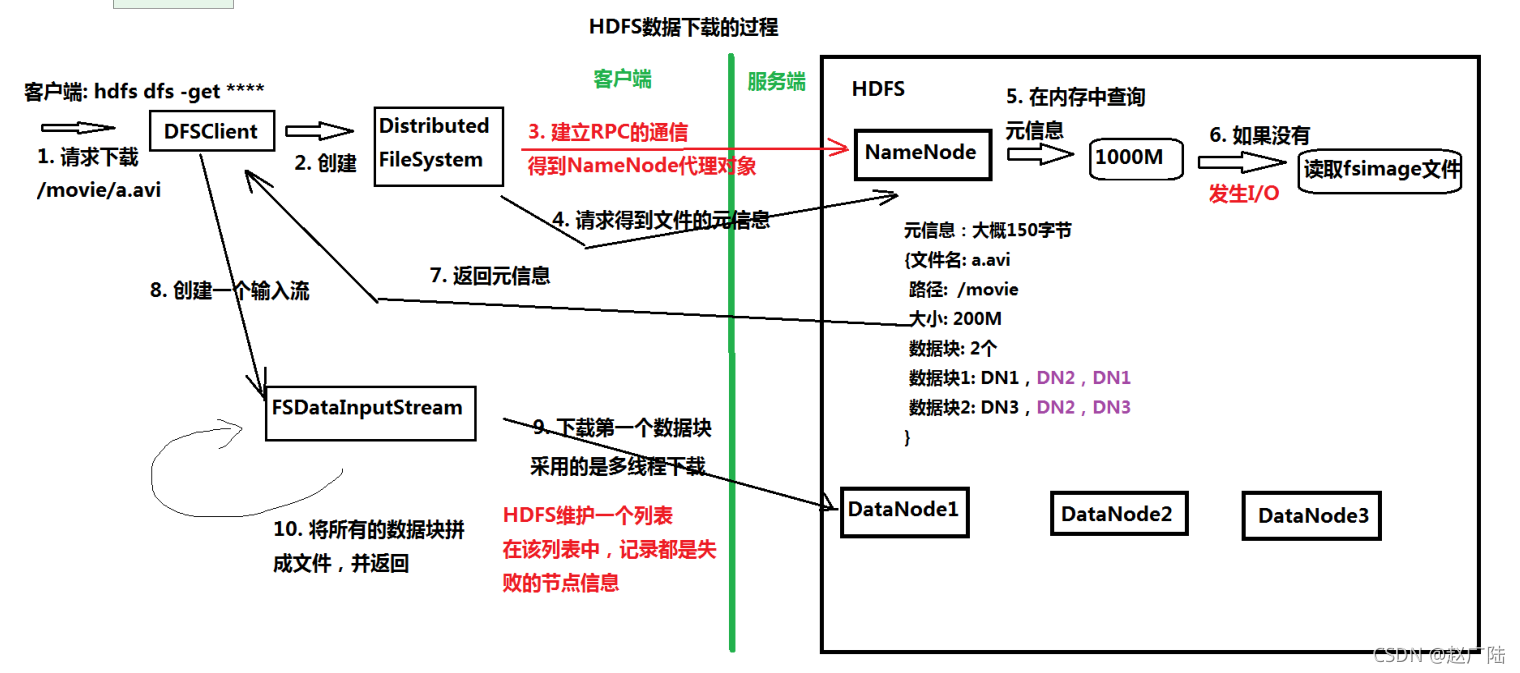
5 資料上傳/下載的原理及程序
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354580.html
標籤:其他
下一篇:三件小事~