暑期實習期間,所在的技術中臺—效能研發團隊規劃設計并結合公司開源協同實作符合DevOps理念的研發工具平臺,實作研發程序自動化、標準化;
實習期間對DevOps的理解一直懵懵懂懂,最近觀看了阿里專家帶你玩轉容器云原生DevOps公開課開始系統的學習DevOps,所以根據學習視頻整理出以下學習筆記希望分享給更多對此感興趣的同學~
課程大綱如下圖所示,會陸續進行更新:
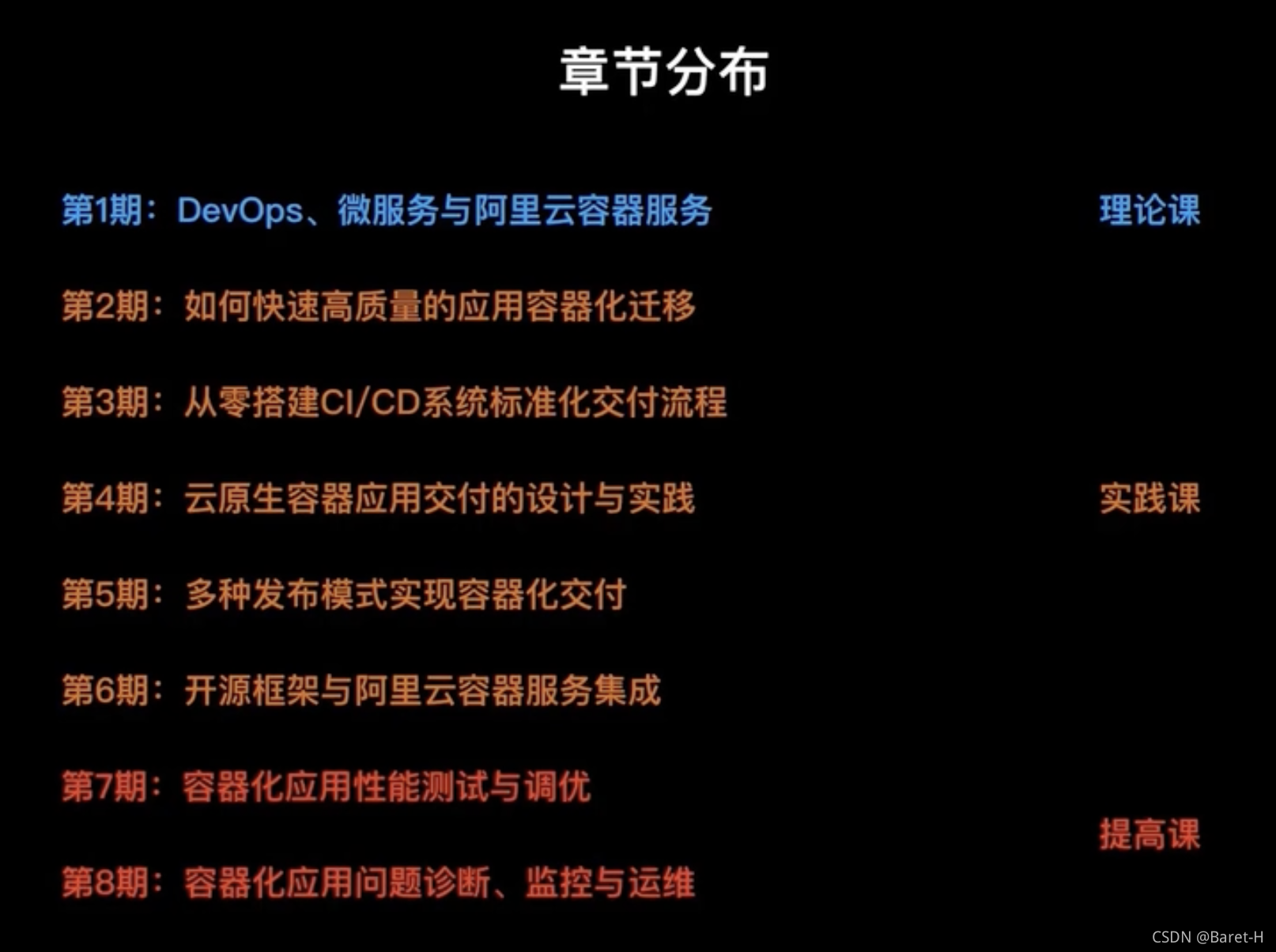
如何快速高質量的應用容器化遷移
- 1. 上節回顧
- 2. 容器化交付流程階段劃分
- 3. DockerFile入門及基本語法
- 4. DockerFile語法
- 5. DockerFile到Docker Image的底層原理
- 6. DockerFile的優化實體
- 7. 編排系統 k8s 入門
- 8. 總結
- 9. 工具推薦
本節內容是如何快速高質量的進行應用容器化的遷移,首先我們來回顧下上節內容 容器云原生DevOps——第一期:DevOps、微服務、容器服務(學習筆記)
1. 上節回顧
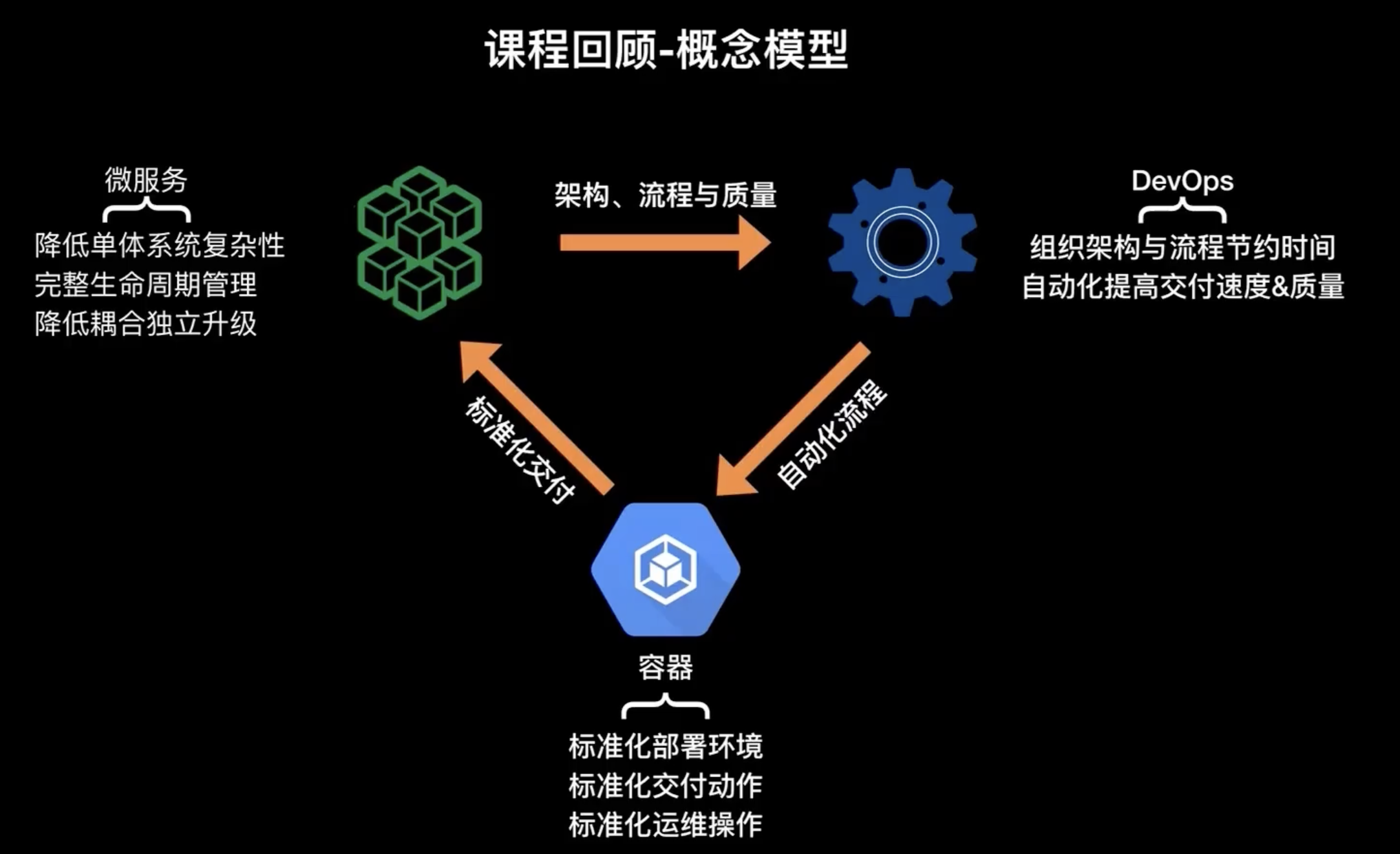
上一節介紹了三個非常重要的概念:DevOps、容器 和 微服務,以及它們之間如何有機的融合起來形成一個快速高質量的容器化交付鏈,
首先我們先回顧一下 DevOps 的概念,DevOps 是2007年的時候,一個比利時IT咨詢師 Patrick 提出來的,他希望通過更優的組織架構和流程節約時間通過自動化的方式來提高交付速度和質量,但是很可惜,在當時的一個場景之下,大部分的公司都是采用大型單體結構的方式進行應用軟體的設計,通過大兵團作戰的方式來實作整個交付的流程,以及通過瀑布流的一個設計思想來去進行質量保證,所以這也是導致當時 DevOps 很難很難快速落地的一個原因,
然后在2014年的時候,微服務 的概念提出了,概念簡單的用一句話來理解就是分而治之,將把一個大型的單體系統拆分成很多子的小型系統,且每一個小型系統都具備完整的一個生命周期管理,然后使用適合該小型系統的設計思路進行設計,拆分后的每一個系統組件都會相互在資料集隔離,都有自己的一個 scope,而這個 scope 又是和業務僅僅相結合的,且每一個組件都可以進行獨立升級,也就是說當一個大型的系統通過微服務進行拆分的時候,其實無形中在架構上會變得越來越敏捷,然后在流程上可以讓整個交付的一個流程變得越來越快速,這正是因為每一個組件的體量非常小且也有自己明確的一個 scope,所以可以更好的進行質量保證,所以從架構、流程、質量三方面來說,微服無形在概念上面彌補了 DevOps 很多缺失的部分,
但微服務它本身也不是一個十全十美的架構設計思路,當你把一個大型的系統拆分成很多子系統之后,如何有效的管理這么多的微服務,并且如何對快速的對每一個微服務進行獨立升級又是新的問題,所以此時我們特別需要一種標準化的交付方式來去協助微服務的弊端,舉一個簡單的例子,我們采用傳統結構開發的 Java 應用拆分成很多微服務后,每個服務可能采用不同的語言、不同的框架來去實作,這導致我們以前使用的很多基礎的類別庫或者是公共框架都無法再使用,那此時怎么來實作不同的框架和語言之間的一個標準化呢?
容器 的出現就幫我們解決了這個問題,在使用容器的時候,通常會定義 DockerFile,然后在交付時會定義一些 yaml 檔案或者是compose 檔案,其中 DockerFile 就是標準化的一個部署的環境,而類似 base-compose 或者是 k8s 的restful api 是標準化的這個交付內容和交付動作,以及后來如果用一些編排系統,可能會有一些命令和 API,而這些 API 就是準化的運維操作,從這個角度來講,容器實際上實作了一個標準化交付的場景,而標準化交付其實可以解決微服務場景中很多缺失的部分,而容器它也有它自身的一個問題,就是當你引入容器這種技術的時候,我們原本的這個交付產物是代碼包比如說jar包、tar包等,但是使用容器時,我們使用的交付中間產物是 docker image,此時你的開發團隊可能也要感知 容器架構引入而帶來的上層應用架構的變化,所以容器也會有很多固有的問題,而容器大部分的問題可以用通過 DevOps 工具來解決,比如原本鏡像打包的操作是在本地實作的,但現在可以通過 Jenkins 或 GitLab CI 來自動化解決,提高交付質量和交付速度,
所以我們看這三個概念,其實在各自的這個優勢上面是相互互補的,而他們之間相互整合起來可以變成一個非常有機的可以高質量和快速的一個軟體交付方式,所以這也是為什么,這三個概念最近經常被大家一起提到、一起出現的根本原因,
上節到后半部分,我們也給大家介紹了一些典型的容器交付流程,一個標準的容器交付流程大致就如下圖所示:
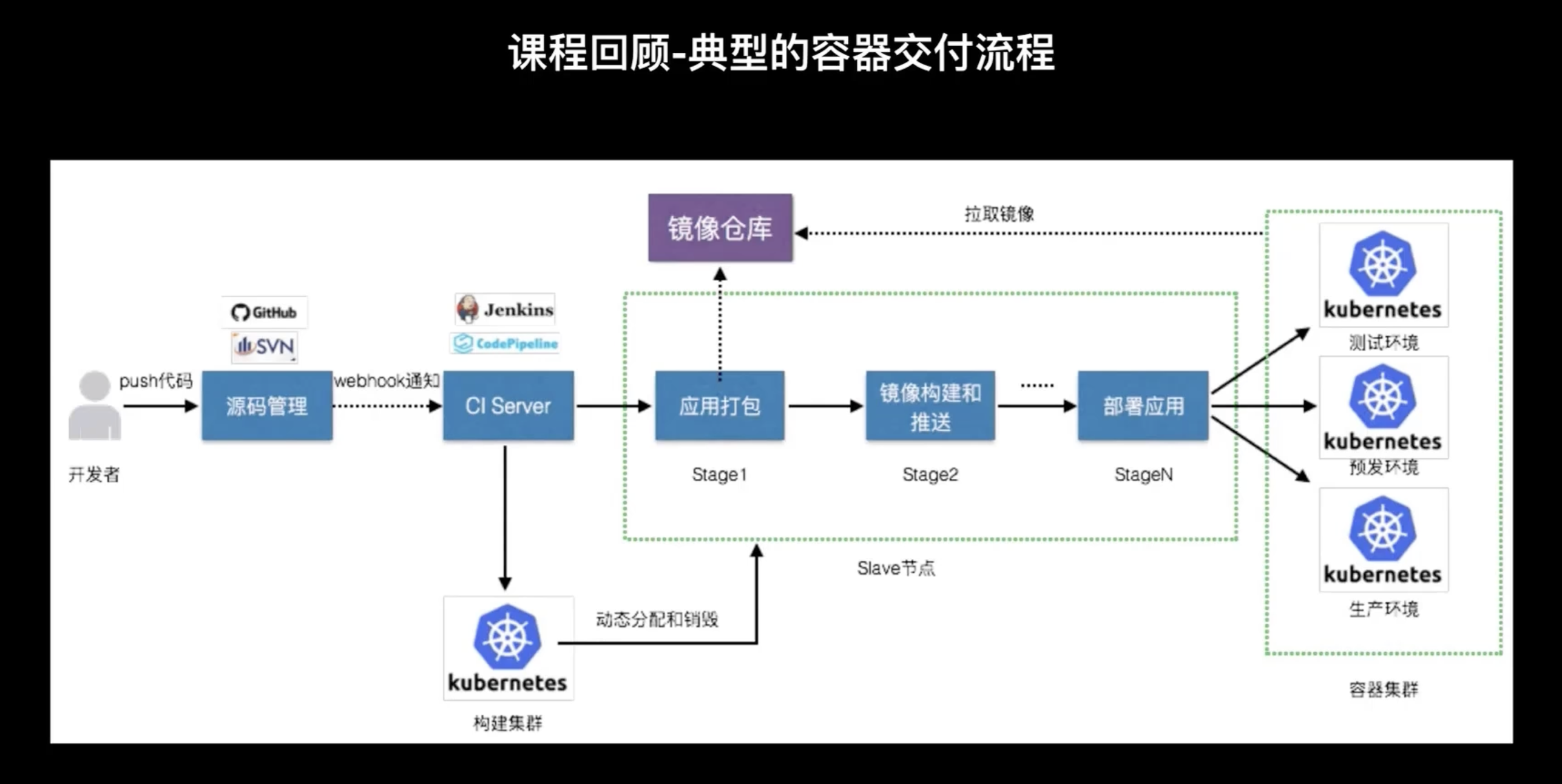
開發者將代碼提交到源代碼管理中心,可能是 GitHub、GitLab 或 SVN,而云代碼管理中心我會通過 Webhook 的方式通知 CI-Server,CI-Server 會運行客戶在源代碼里面包含的單元測驗或其他測驗的腳本,如果測驗通過,它接下來會進行代碼編譯打包、鏡像構建和推送的流程,然后進入到應用的部署的階段,在不同的環境里邊部署這個應用,最后這個環境里邊會通過編排引擎來拉取鏡像來實作一個容器化的一個部署,
2. 容器化交付流程階段劃分
如果我們將一個容器化交付流程進行階段劃分的話,其實可以劃分成如下四個階段:
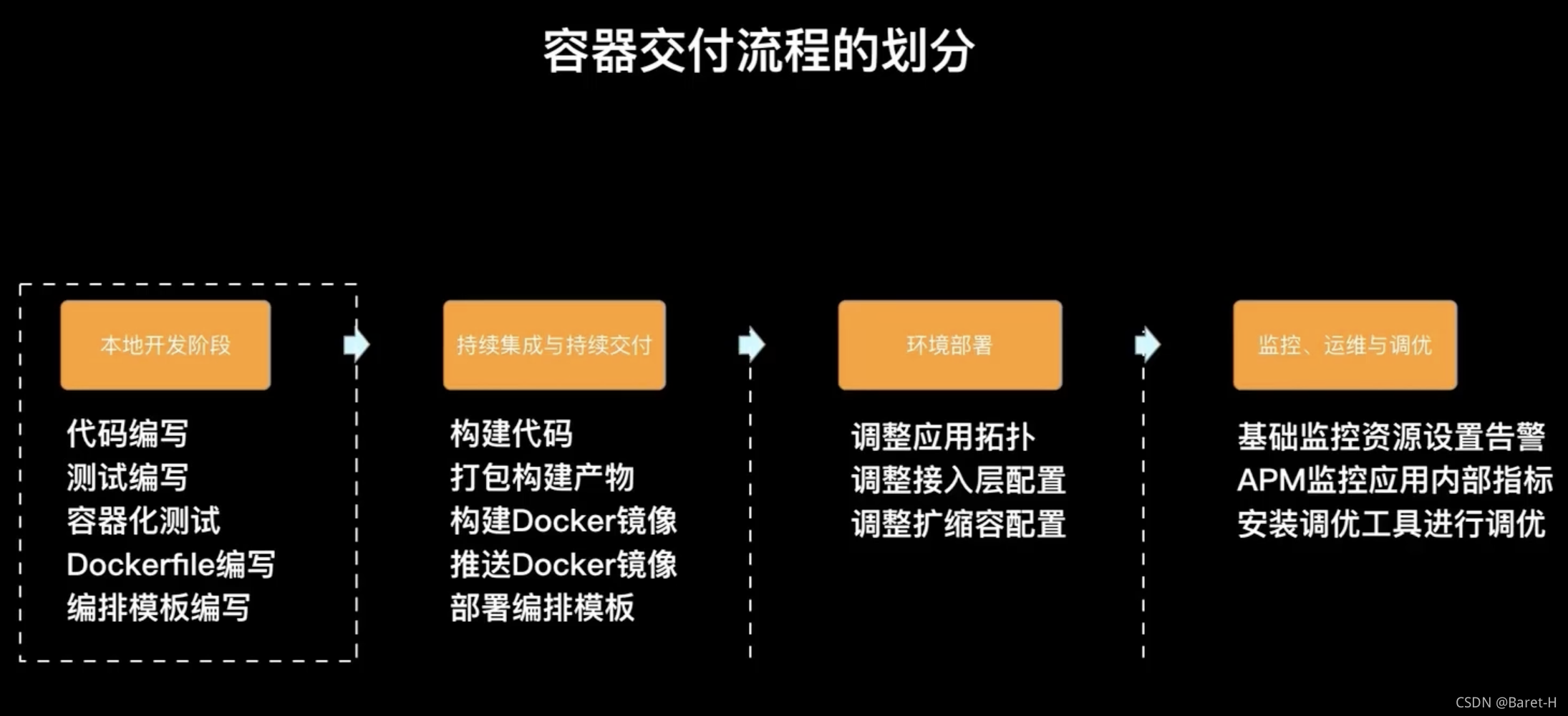
- 本地開發階段,主要是代碼撰寫、測驗撰寫、DockerFile 撰寫、容器化測驗、編排模板撰寫
- 持續集成和持續交付階段,主要進行代碼構建、打包成構建產物、構建 docker image、推送 docker image 、部署編排模版
- 環境部署階段,主要是調整一些應用拓撲關系、調整接入層的配置、調整彈性擴縮容的配置等
- 運維監控和調優階段,一個就是基礎監控資源的設定和告警;二是有些客戶可能有更細膩度的監控或告警需求,會采用APM的方式內置一些 agent 來采集一些更細致的一些指標(比如網路的一些指標:類似TCP connection 數目、各種網路協議堆疊的狀態);三是安裝一些調優工具進行調優,例如大家可能接觸的比較多的 top 、htop 等等,
本節課程主要關心的是怎么幫助大家進行本地開發階段這個部分,主要會介紹怎么去撰寫高質量 DockerFile 以及容器編排引擎的一些內置的機制和原理,幫助大家快速入門編排模板的撰寫,
3. DockerFile入門及基本語法
下圖是從 Docker 官網中摘錄的最簡化的一個 DockerFile

這四行簡單的配置就把的一個 python 應用,從基礎的環境到代碼的準備、編譯、運行完整的表達出來了,這就是一個最基本的 DockerFile,然后我們要做的就是通過按照 DockerFile 定義的規則編譯打包生成一個 Docker image,命令如下所示:
# 通過DockerFile打包成鏡像
docker build -t image:tag .
-t 表示用于指定鏡像名和 tag id,.是需要打包的代碼檔案路徑,這里表示當前路徑(也就是在當前路徑下有 DockerFile 以及對應需要打包的檔案,如 jar包/tar包)
📄 Docker 和 Git 的相似點
Docker 和 Git 有兩點是非常相似的:
- Docker 和 Git 有兩點是非常相似的一是打標簽,這里 -t 來設定鏡像名和 tag id,在 git 里邊我們也有一個遠程倉庫名以及對應的branch分支,我們有時可能會給這個分支是打一個 tag 標簽表示說這是xxx版本,然后這個tag 可以在發布時作為一個可直接回滾的版本,比如說今天我的 branch dev 變成一個可發布的版本時,我打一個 tag:0.1,然后再過一段時間發布第二個版本時打一個 tag:0.2,如果當0.2版本出現問題時我可以回滾到0.1的這個代碼版本進行發布,其實對于 Docker image 來講也給予了這種 tag 機制,比如說今天我打了一個0.1版本的image , 那明天我可能發布的就是0.2版本的image,檔0.2這個image 有問題可以直接選擇0.1版本的進行發布
- 二是資訊的差量增加,git 它的存盤是差量存盤,當我們看到 git log 看到的實際上當前代碼和之前代碼比對的差異,然后每次的這個差異是增量往上 append 附加的,Docker 也是一樣,它基于這種機制,也是不斷的在往一個 base 鏡像基礎上去 append 需要的環境依賴等資訊,而這個資訊也是差量的去增加的,
通過這條命令之后,我們就可以構建出一個帶有 tag 的一個 docker image,有了這樣的一個鏡像之后,我們可以在本地通過 docker run -d image:tag 將鏡像跑起來,
📃 Docker 的單一行程原則
在 Docker 里有一個原則叫做單一行程原則,就是需要給 docker image 一個唯一行程作為這個 container 的主行程讓他在前臺運行,這樣該 container 才永遠的運行下去,而不會直接退出,什么是前臺運行的行程呢?比如說我們平時在 linux 系統中可能會運用這個top 命令查看一些監控資訊,此時整個 std:out 里邊是不斷的有資料在輸出,此時沒有辦法操作任何其他的命令,除非執行了control+C 來強制跳出這條命令,這樣的一個命令其實就是前臺運行的一個命令,那什么是后臺命令或者是說什么是立馬結束的命令呢?比如說我 cat 一個標準的檔案可以立馬看到這個檔案的內容,但是 std:out 立馬又出了一個新游標可以讓你輸入下一條命令,也就說明上一條命令已經直接執行完退出了,這種場景對于容器來講就不合適了,所以建議開發者給容器里面內置一個前臺運行的命令,然后讓這個命令一直耗在那兒比如說一直在列印著日志,這樣 container 可以很好的運行起來,
DockerFile 的目標,其實就是將這個應用進行抽象打包,然后把這個構建出來的 docker image 作為標準化交付的一個中間產物,提到了這個標準化交付,我們要來更深入的來講一下這個概念:
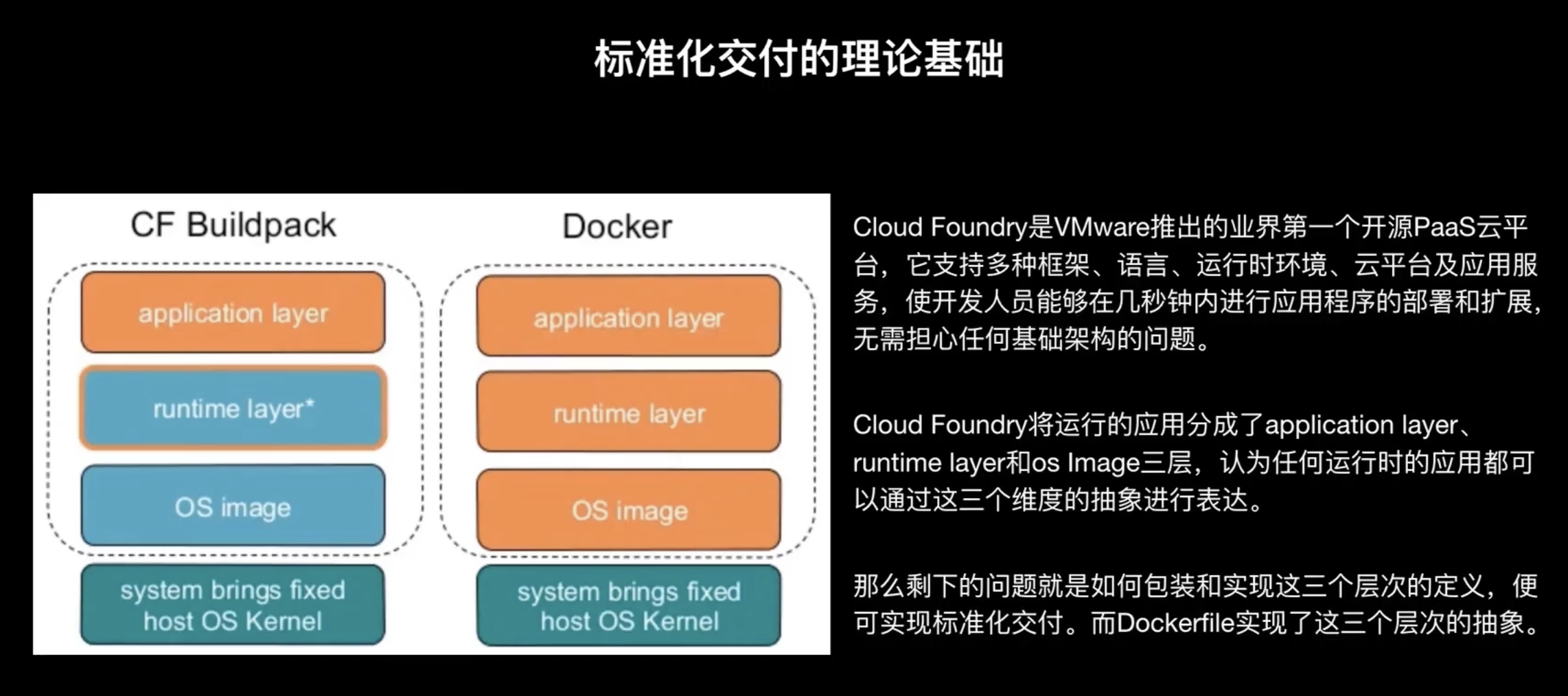
DockerFile 的這種設計思路和設計方法并不是它獨創的,最早的標準化交付的這個概念是由一些 PaaS 平臺提出的,其中有一個比較有代表性的軟體叫做 Cloud Foundry:它是 VMware 推出的業界的第一款開源的平臺,它支持多種框架語言運行時環境、云平臺以及應用服務,可以使開發者能夠在幾秒鐘之內對于應用程式進行部署和擴展,而并不需要擔心任何的架構,這是 Cloud Foundry 的一個官方的介紹,舉個簡單的例子,比如有個 java 的 spring 應用,使用 Cloud Foundry 后,我們只需要把代碼提交到代碼倉庫,然后再把這個代碼倉庫配置到 Cloud Foundry 系統里,它就會自動拉取你的代碼,然后并嘗試著通過探測機制或者代碼識別的方式來生成你的運行時環境,注意 Cloud Foundry 本身并不是使用 docker 的方式,它是應用了一個內置的叫 build pack 機制,然后它通過這種方式就探測出來這個是一個 Java 應用,使用的是 spring 的框架,繼而判斷還需要什么環境依賴:比如系統依賴ubuntu/centos,環境依賴jdk、spring組態檔的位置及啟動方式等等,通過這種探測機制 Cloud Foundry 就可以把你這個spring 的應用在一個環境里邊運行起來,
那么 Cloud Foundry 是怎么進行探測?或者是說他都生成了什么內容來把將一個應用從代碼轉換成線上的一個運行時的服務呢?其實 Cloud Foundry 把任何一個運行時的應用切分成了三個層次:
- 第一層是
application layer,就是應用所需要的這些邏輯代碼,剛才java 應用例子中我們 spring 相關代碼這一部分對于 Cloud Foundry 來講就是 application layer, - 第二層是
runtime layer,比如 spring 依賴于 Java 環境,可能還依賴于一些系統包,這一部分其實就是放在這個runtime layer, - 第三層是
OS image layer,它表示的是說應用依賴的系統的環境是什么,
Cloud Foundry 認為我有了以上三個層級之后,就可以把一個應用代碼轉換成一個線上應用,
實際上 docker 的 DockerFile 的設計思路和 Cloud Foundry 對于這種標準化交付的一個抽象是非常相似的,

我們再看一下上述那個 DockerFile,對比 Cloud Foundry 的三個層次,其中第一行對應了其 OS image layer 層,然后第二行第三行和 runtime layer 是非常相似的,而最后一行定義了這個軟體的一個運行方式,和application layer 保持一致,因此 DockerFile 使用這種 DSL 語言來去定義這個模板是有的一定理論依據的,而這個理論依據其實可以去看一下 Cloud Foundry 的的一個build pack機制來進行更深入的了解,
4. DockerFile語法
我們接下來從更高的一個維度來全覽一下 DockerFile 里邊的 這些命令和標簽,

其中每個標簽的功能如下圖所示:比較常用的可能是from、run、expose、env、copy、cmd、user、workdir 這幾個命令,其他的可能并不是很常用,
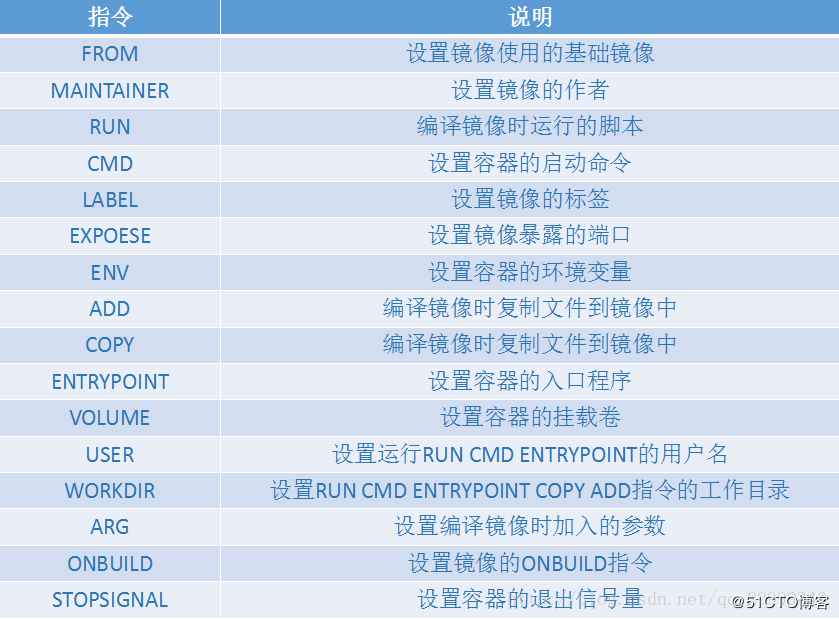
-
FROM標簽就是用來設定鏡像使用的基礎鏡像 -
MAINTAINER標簽就是用來標注 DockerFile 的作者,但是該標簽有一個問題,就是它只在 DockerFile 里面可以看得到,但是當容器運行時作者資訊就丟失了,所以在新版本的 DockerFile 里面,MAINTAINER 標簽已經逐漸的被棄用了,Docker 推薦的另一種方式就是打LABEL標簽的方式,我們可以在標簽中寫出容器的相關資訊,這樣的好處在于標簽中的內容其實都會在運行起來的容器中里邊看得到,因此就可以讓這個 container 運行出錯時追責的資訊的鏈路更順暢,我們可以直接使用 docker inspect containerID 命令就可以看到 container 的label標簽資訊, -
RUN標簽就是是定義一些要里邊執行的命令,這些命令其實只在 DockerFile 構建成 Docker image 時候生效, -
LABEL標簽所標注的內容最侄訓在這個容器啟動時能看到,該標簽表面上看上去使用方式非常簡單,但實際上它有很多用處:比如說我可以給一個image 打上特殊的標簽,而這個標簽會隨著這個container 運行起來的時候也存在,所以特別是對于一些監控系統或探測系統,它可以通過這個container 的 label 來去識別這個 container 里面的一些資訊,比如說很多的監控方案是通過這個 label 來去做上層概念的一個聚合,舉個簡單的例子,比如說在K8S里面,我們有很多的概念,類似像 development 等等,而這些概念其實和真正的 container 的之間是沒有嚴格的物理的關系的,所以很多監控系統會把這些 label 打到 container 之上,表示這個container 是屬于一個development,然后通過這種方式把一些原資料資訊進行下發,以此來進行標識,采集系統也類似如此,它會把 label 采集上來,然后再做上述的一個聚合,所以 label 的用法是很靈活的,可以通過 label 打上很多特征的一個資訊, -
EXPOSE標簽表示的是說我要暴露哪些埠,DockerFile 默認支持的是TCP和UDP兩種協議,如果你什么都不寫的話,那默認情況下指的是TCP的協議,但是值得大家注意的一點是這個 expose 只是起到一種檔案描述的作用,并沒有什么實際作用,只是說讓這個DockerFile 變得更可讀,幫助你更好的去使用 DockerFile ,更好的去把這個容器啟動起來,比如你寫一條expose 80/tcp的話,其實對于使用這個 DockerFile 的開發者他就能知道說這個 container 里邊運行的程式需要暴露80埠,因此在run這個container的時候就可以做一些埠映射等等 -
ENV標簽我們在這個 linux 命令列里面使用的 export 比較類似,就是把一個key value 的環境變數暴露到 container 里邊,然后是在 container 運行時生效的,該標簽的使用是非常推薦大家使用的一種方式,因為我們比較建議的是說能夠盡可能的去抽象 docker image,比如說我們有的時候會把一些業務邏輯的代碼放到這個 container 里邊,但是我們可能會有測驗環境、預發環境或者是線上環境,每個環節里邊會有一些差異性,我們這個時候并不希望每一個開發者都去打三個鏡像,而是說盡可能的把一些變化的資訊抽離出來,以組態檔或者是以環境變數的方式進行注入,在docker 里邊我們比較推薦大家的是把這些變的東西放到環境變數里面,然后通過這種環境變數注入的方式來去實作, -
ADD和COPY這兩個標簽非常相似,add 的出現是比較早的,copy 命令是后來才有的,現在官方推薦使用 copy 命令,而 add 的命令實際上是 copy 命令的一個超集,它還支持了兩種額外的場景:一種場景是 add 一個壓縮包并且自解壓的一個場景,第二個場景是add的一個遠程地址,然后并下載到這個image 里邊,除了這兩種場景,默認情況下使用copy 就已經是足夠用的了, -
CMD、ENTRYPOINT、SHELL三個標簽中,對于大部分的開發者來講,使用 cmd 和 entrypoint 這兩條命令就已經足夠用了,對于這兩個命令的選擇:如果需要繼承自父 DockerFile 的一些命令的話,使用 entrypoint,否則使用cmd,shell 不常用,shell 最大的一個作用就是它可以在默認的終端環境,你比如說你想用 bush 或者是你想用這個ipad 的ASH等等就這個地方是可以通過shell 這條標簽來去進行替換,注意:entrypoint 有一個最大的弊端是它默認的情況下是以/bin/sh -c的方式進行執行的,所以在 entrypoint 里設定的一些命令,它最終不會是以容器里邊的PID為1的行程來運行,這樣會導致就是如果說我在外層去殺container 時,我的容器里面只有PID=1的行程可以收到這個信號量,但是如果你是以 entrypoint 的方式執行的話,那實際上你自己的這個應用程式是沒有辦法收到這個信號量的,所以這個時候會導致你的這個容器是直接被殺掉,而不能夠做很優雅的停止,如果對于沒有捕獲信號量的一個場景,那你的container 會自動在超時過后被強制刪掉,所以這種場景也會觸發一些小小的一個bug,比如說很多客戶使用entrypoint 的方式來去運行自己的一個 DockerFile 然后發現說我在這個容器服務上面點擊了洗掉,但是我很久我的這個container 還沒有洗掉掉,我覺得可能是網路慢,或者說容器服務有問題,但是很多時候其實是由于PID不為1的這個行程無法收到停止的信號量,所以只能等到容器超時之后才被強制洗掉掉,
-
VOLUME標簽表示的在容器里邊定義一個掛載點,這個掛載點是可以類似檔案一樣的告訴后續的開發者怎么去使用這個volume,更多是一個檔案的作用并沒有實際的一個價值,特別是對于一些依賴外部配置的,可以通過這種方式讓你的 DockerFile 變得更好的能夠自描述, -
USER標簽表示 countainer 運行起來的時候使用的這個用戶身份是什么,對于很多開發者而言,使用 docker 有一定的安全性考慮,我們以設定容器里邊不通的 user 權限,然后來保證容器的主行程是在一個降權的user 的這個環節之下來去執行,其他行程也可控的賦予不同的 user 權限, -
WORKDIR標簽表示的是當前執行的目錄環境,比如說我可以定義當前執行的這個路徑是在 /root 下,剩下每一條命令其實都以 root 這個路徑來作為根路徑來執行的, -
ONBUILD、STOPSIGNAL和HEALTHCHECK標簽只需要了解使用方式就好,并不常用,unbuild 主要是指在這個構建時要執行的動作;stopsignal 表示的是在什么樣的信號到來的時候這個容器會被殺掉;最后這個healthcheck 表示的是說,如果health是不通過的話,這個容器就起不起來,
5. DockerFile到Docker Image的底層原理
接下來我們來看一個常見語言 Node.JS 的 DockerFile 實體:

要想撰寫出一個很精簡高效的 DockerFile,然后生成一個高質量的 docker image,我們首先要知道這個 DockerFile 是怎么變成 docker image 的以及 docker image 的原理是什么?
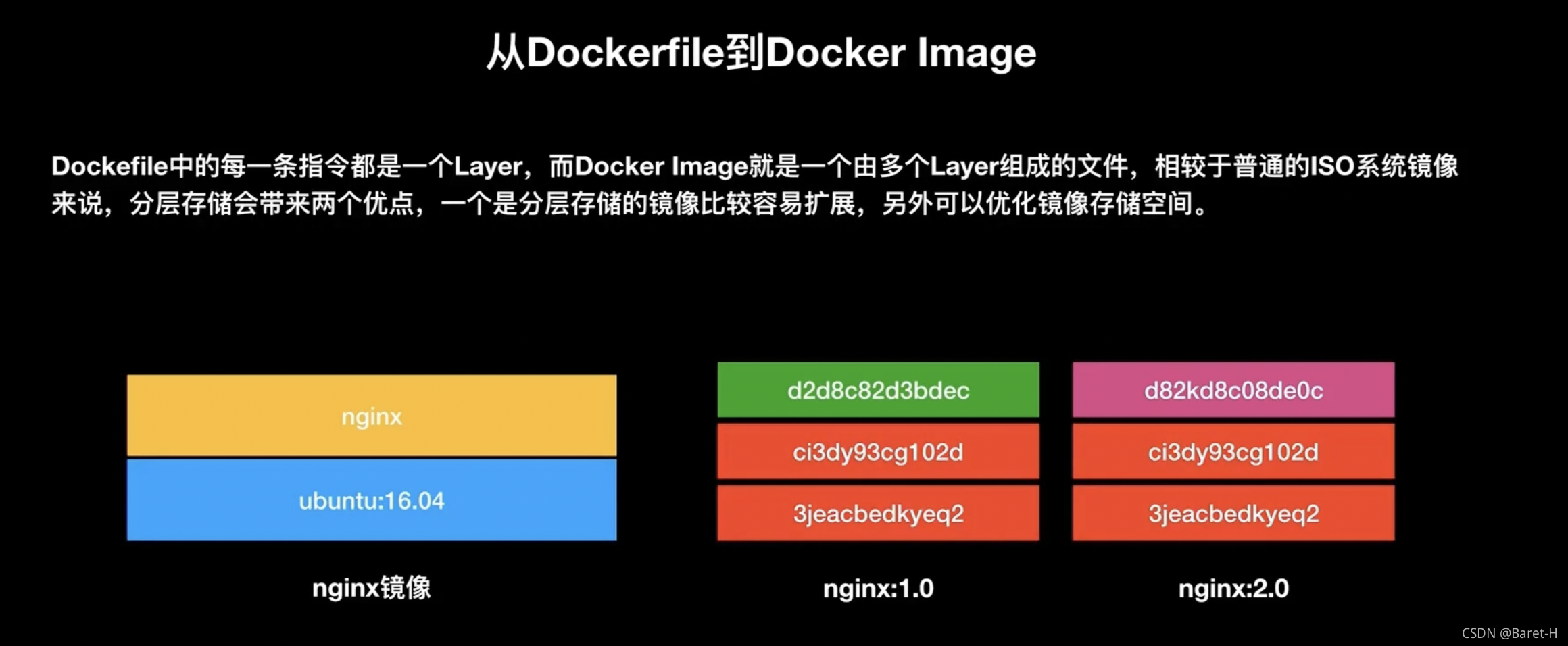
DockerFile 中的每一條指令都是一個 layer,而 docker image 就是一個由多個 layer 組成的檔案,相比普通的 ISO 系統鏡像來說,分層存盤會帶來以下優點:
- 第一個比較容易擴展,比如說我們剛才from unbuntu 16.04 構建了我們自己的這個python 應用,其實這就是一個分層的一個體現,ubuntu 是一層,然后我的上層的python 又是一層,而這種方式就可以使鏡像變成是一個組裝的一個方式,首先拿一個base 鏡像,然后再往上去組你自己的這個 layer 層就可以,
- 第二個可以優化存盤空間,因為相同的 layer 在 docker 的鏡像倉庫或是在本地環中只存盤一份,比如說你有兩個鏡像都依賴于 ubuntu 的這個標準鏡像且是同樣的tag,這樣第一個鏡像下載一遍之后,第二個鏡像就無需下載,因為本地已經有了一份,所以這個是鏡像層機制節省空間的優勢,
分層機制就是大致原理和上圖右側的比較相像,就是差異性的部分會在獨立的一層,而相同的部分會以相同的方式進行存盤,這樣可以降低很多的存盤空間,也可以降低網路的拉取事件,
我們再看一下這個docker image 底層的實作:
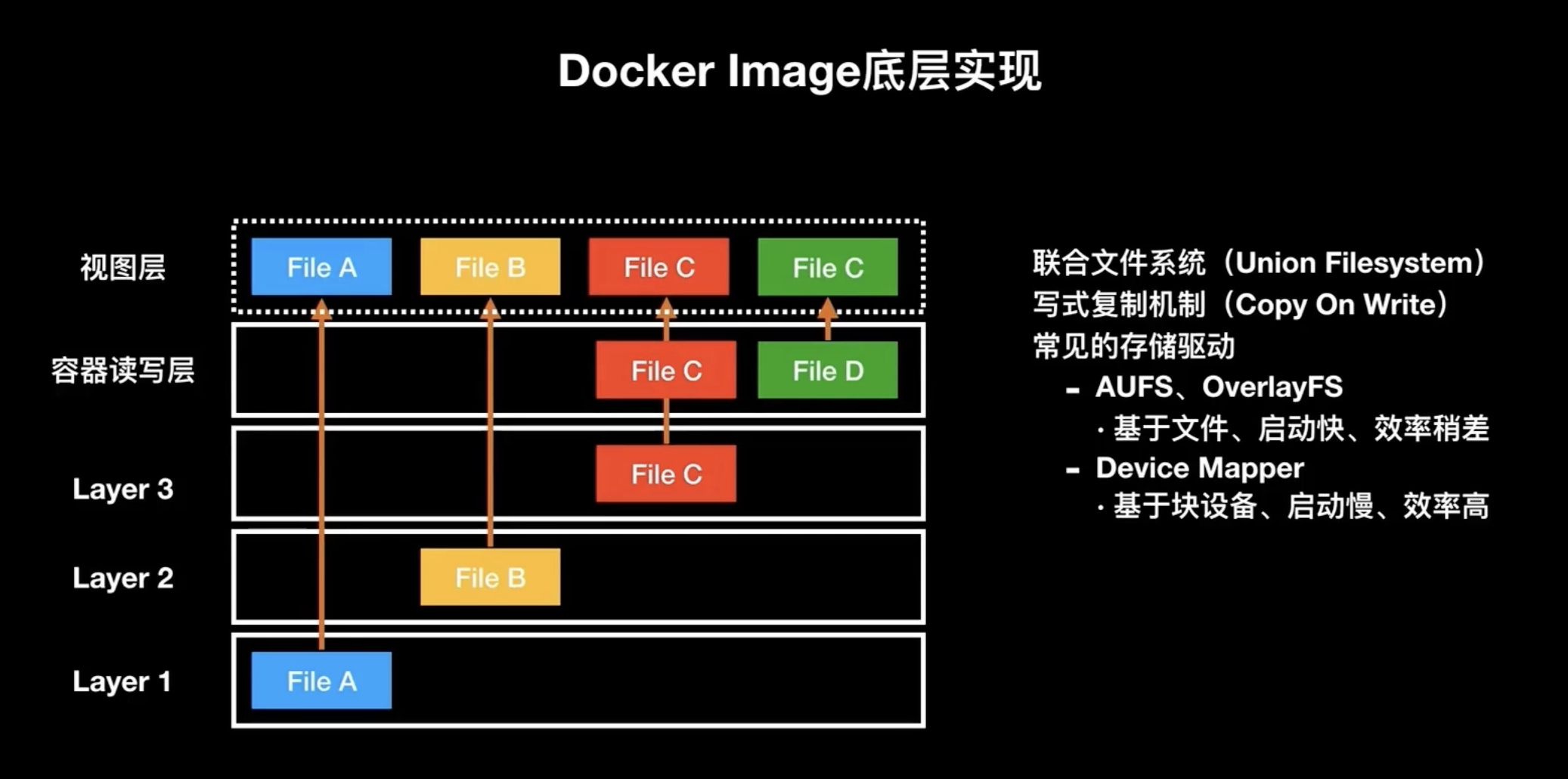
我們剛才已經提到了一個 docker image 是由多層組成,比如上圖是一個三層的鏡像,其中每層里面都會有自己的內容,當我們真正把一個鏡像跑成 container 的時候,實際上 container 會增加一個容器的讀寫層,如果從客戶的視角來看的話,實際上是把每一層的這個內容用聯合檔案系統的方式,用寫式復制的一個機制進行拷貝,比如說我對這個 layer1 里面的 file A 進行了一個寫,實際上layer 1 做了一件事情就是把這個 file A 拷貝到了這個容器的這個讀寫層,看上去像我有了這個file A,但實際上他只是拷貝了一個副本,同樣,如果我要建立一個新的檔案,實際上是在視圖層里面先建立了一個檔案,再扔到這個容器讀寫層,然后增加了這一層在該層里面來去實作鏡像的內容,所以這個是很多容器存盤驅動實作的一個機制,就是 copy on wright,寫的時候我再把這個檔案復制上來然后進行修改,
常見的存盤驅動主要包含了兩種:
- 第一種是 AUFS 或者是 OLFS,這種是基于檔案的這種存盤驅動,特點是啟動快,但是效率會稍微差一點,
- 第二種是 Device Mapper,這種更為底層,是基于快驅動的,它的啟動會相對來講比較慢,而且會有很多奇怪的bug,但是效率特別高
以上就是 docker image 的底層實作,總結就是基于多層且遵循 copy on wright 機制,
6. DockerFile的優化實體
接下來我們要看說如何去撰寫一個高質量的 DockerFile:

比如說在這個例子里面是一個 java 應用,首先依賴基礎景象 jdk:8-alpine,然后安裝 maven,通過 maven 進行了一個構建,再就是添加了 pom.xml 以及源代碼,然后進行打包,把jar包拷貝到相應個目錄下,最后啟動該應用,
以上 DockerFile 很具有代表性,我們很多開發者剛開始寫的 DockerFile 都是這樣的型別,那這個有什么問題呢?我們可以做什么樣的一個優化呢?
1?? 減少 layer 層數
DockerFile 中的每一個標簽所代表的一行都會成為在鏡像倉庫里邊的一個 layer,layer 越來越多會導致這個鏡像越來越臃腫,所以降低 layer 是我們優化 docker image 的第一條,方法就是把不同層如果可以放到一層那就把它們放到一層,如下所示:在這個優化里邊,我們就將一個14層的 layer 轉變成了7層的 layer,

2?? 清理鏡像構建的中間產物
我們剛才通過wget的方式安裝了maven,此外我們還可能采用 apt 或者是 yum 對方式來安裝,安裝完成后都會在本地系統里邊會存一份安裝包的 cache,如果以 apt-get 的方式安裝的話實際上它會在 var/lib/apt/lists 下邊放一份cache,如果我們不需要的話直接移除掉可以減少存盤空間,
所以我們在這里面加了命令 mvn verify package 實際上是把很多我們不需要的maven壓縮包進行了洗掉,降低了存盤空間,

3?? 充分利用鏡像構建快取
利用構建的快取來加快鏡像構建速度,Docker構建默認會開啟快取,快取生效有三個關鍵點:鏡像父層沒有發生變化、構建指令不變、添加檔案校驗和一致,只要一個構建指令滿足這三個條件,這一層鏡像構建就不會再執行,它會直接利用之前構建的結果,需要注意的是,某一層的鏡像快取失效之后,它之后的鏡像層快取都會失效,所以我們應該把變化最少的部分放在Dockerfile的前面,這樣可以充分利用鏡像快取,

4?? 優化網路請求
我們使用一些鏡像源或者在 DockerFile 中使用互聯網的url時,可以去用一些網路比較好的開源站點來節約時間、減少失敗率
例如在國內的maven源一直都不穩定,然后阿里云提供了maven鏡像源,我們可以使用該鏡像源

5?? 多階段構建
Docker 從17.05版本提出了一個叫多階段構建multi- stage builds的概念,將構建程序分為多個階段,每個階段都可以指定一個基礎鏡像,這樣在一個Dockerfile就能將多個鏡像的特性同時用到,
如下圖所示,看起來好像將兩個 DockerFile 合并成了一個 DockerFile,但是上面的FROM標簽里多了AS builder標識,下面的COPY標簽里多了--from=builder標識,作用就是它是把一些流程放到了 DockerFile 里面,例如下圖中上半部分做的一件事情就是構建了一個編譯環境,最終的產出是一個jar包,而第下半部分的作用就是定義了一個生產環境,它從第一個構建環境里面把這個jar包拷貝一份來進行啟動,

這樣會有什么好處呢?由于 docker image 它有分層機制,其中也有快取的一個機制,而快取機制的原理就是如果沒有變化就可以使用快取,因此這種方式多階段構建的一個好處就是:如果你的構建沒有變化,那實際上對于下半部分的 DockerFile 來講不需要做任何構建的,所以能夠極大的優化構建時間,
比如上述例子的構建時間:第一次優化前構建用了102秒,優化后用了55秒;第二次優化前構建用了86秒,優化后只用了8秒,這正是因為上半部分的 DockerFile 在第二次執行的時候根本不需要做任何的構建程序,只需要執行了下半部分里邊的拷貝動作并執行,
那么多階段構建在存盤空間上面有什么優化呢?第一個傳統的構建需要137MB的空間,而優化后的只需要81MB的空間;第二次構建的時候,由于是一個增量的構建,所以優化前只增加了9.73MB,但優化之后只增加了1.93KB,所以從存盤空間上多階段構建也有很大的優化,
總結:為了去構建一個高質量的DockerFile,我們有以下幾條原則:
- 減少鏡像層數,盡量的把一些功能上統一的命令合并到一起,
- 注意清理鏡像的中間構建產物,比如說一些 apt 或者是 yum 的安裝包,或者是 wget 下載下來的一些內容,只要不需要的就移除掉,這樣可以降低很多的鏡像空間,
- 注意優化網路請求,我們可以去配置一些鏡像源來提高構建速度,可以優化這個鏡像的構建時間,減少失敗率,
- 盡量去使用構建快取,我們把一些不變的或者是比較少變化的東西放在 DockerFile 的前面,因為 docker 快取機制原理是一旦出現有差異,那后面的東西就都是新的需要重新進行,因此如果把不變的東西放在前面就可以更多的使用快取,
- 使用多階段進行構建,把代碼的編譯的流程和真正運行時的流程拆分開,這樣可以避免將一些不需要的東西添加到真正運行的 DockerFile 里面,比如說 java 的JDK只是在開發階段有用,而真正運行時只需要JRE即可,所以這種方式可以很好的利用快取的機制,也可以更好更快的精簡我們的真正的 DockerFile,
7. 編排系統 k8s 入門
在了解 DockerFile 之后,我們接下來要講的是如何進行編排模板的撰寫,在提到編排模板之前,我們首先了解一下編排模板所承載的這個編排系統,
對于容器場景比較熟悉的開發者,可能對 Docker Swarm、k8s、Amazon ECS 都有所耳聞,這三個可以說是這幾年來廝殺比較激烈的容器編排系統,接下來我們以其中最為主流的 k8s 為例進行講解,
我們要想寫好就是 k8s 里面的 yaml 檔案,首先我們要理解就是 yaml 檔案的設計原理,以及它在 k8s 中的實作原理,
下圖是 k8s 的架構圖:
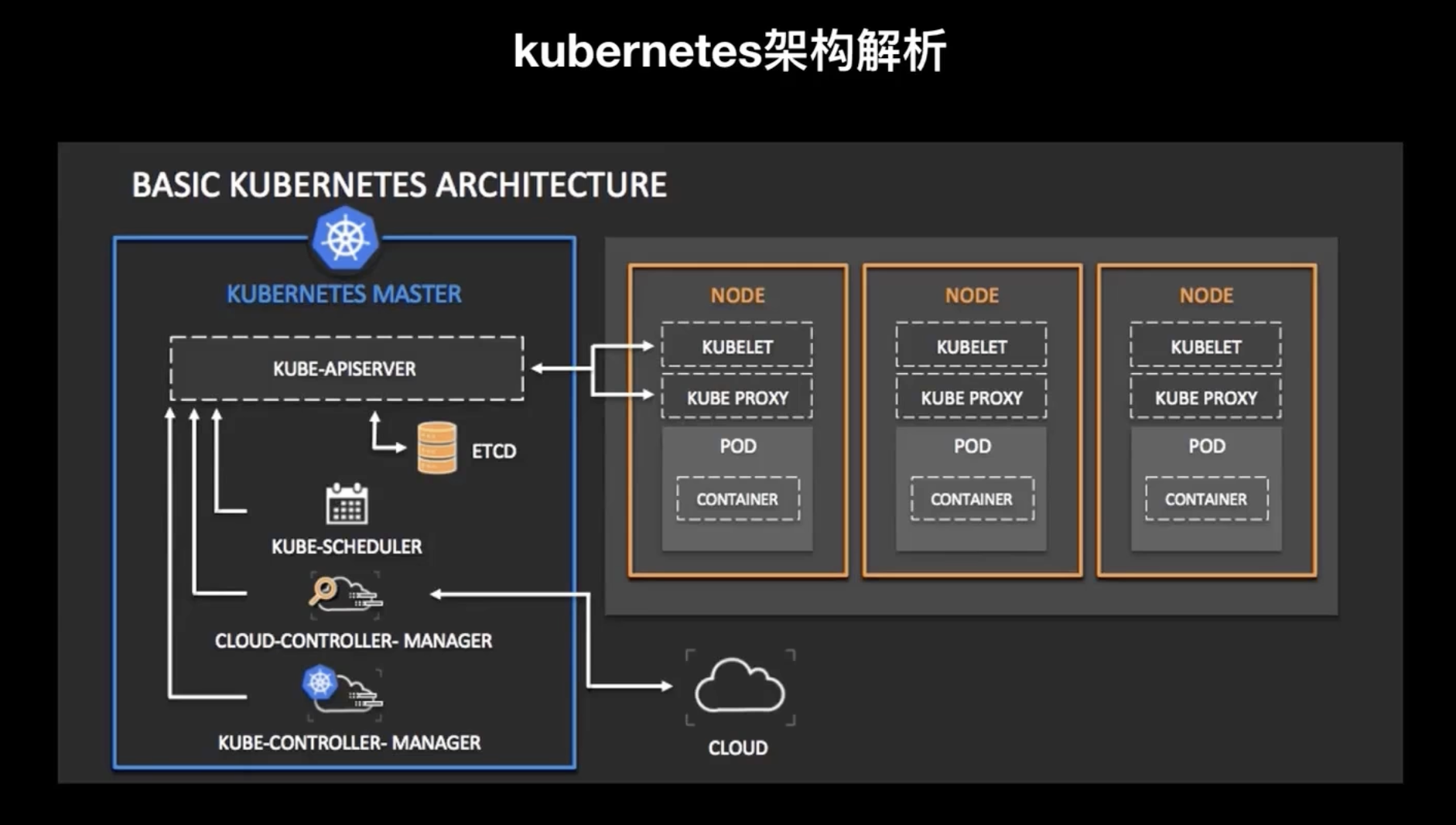
從物理的角度來講,k8s network 會分為master 節點和 worker節點,上圖中藍色部分就是 master 節點,而黃色部分是 worker 節點,
- 在 master 節點上面會部署 k8s 里的幾個主要管控的組件,比如說
kube-apiserver,它是 k8s 中核心的驅動機,主要提供的是API的服務,任何其他的 k8s 里的組件都會和它打交道進行資料交換,kube-apiserver 之下是etcd,etcd 是一個分布式存盤,k8s 集群中的所有資料都存盤在當中,并且 kube-apiserver 也會暴露ETCD的一些介面給其他的組件進行資料的存盤和查詢的功能,再往下是kube-scheduler,它是 k8s 里邊進行調度的組件,然后再往下是cloud-controller-manager,它是 k8s 里面負責這個云資源管理的組件,再往下是kube-controller-manager,它是 k8s 里負責一些抽象邏輯的管理組件, - 在 worker 節點上面主要會運行
kubelet和kube proxy,kubelet 主要會進行 pod 創建的這一部分,而 kube-proxy 主要是負責網路的部分,
上圖中我們已經大體的了解 k8s 組件的分布情況以及每一個組件的基本功能,接下來我們要看我們要以一個實體來看看各個組件之間是怎么進行通信的,以及是怎么完成一個pod 創建流程的,
我們首先來看一個實際中 pod 創建的這個流程,來看一下這個資料流是怎么走的:
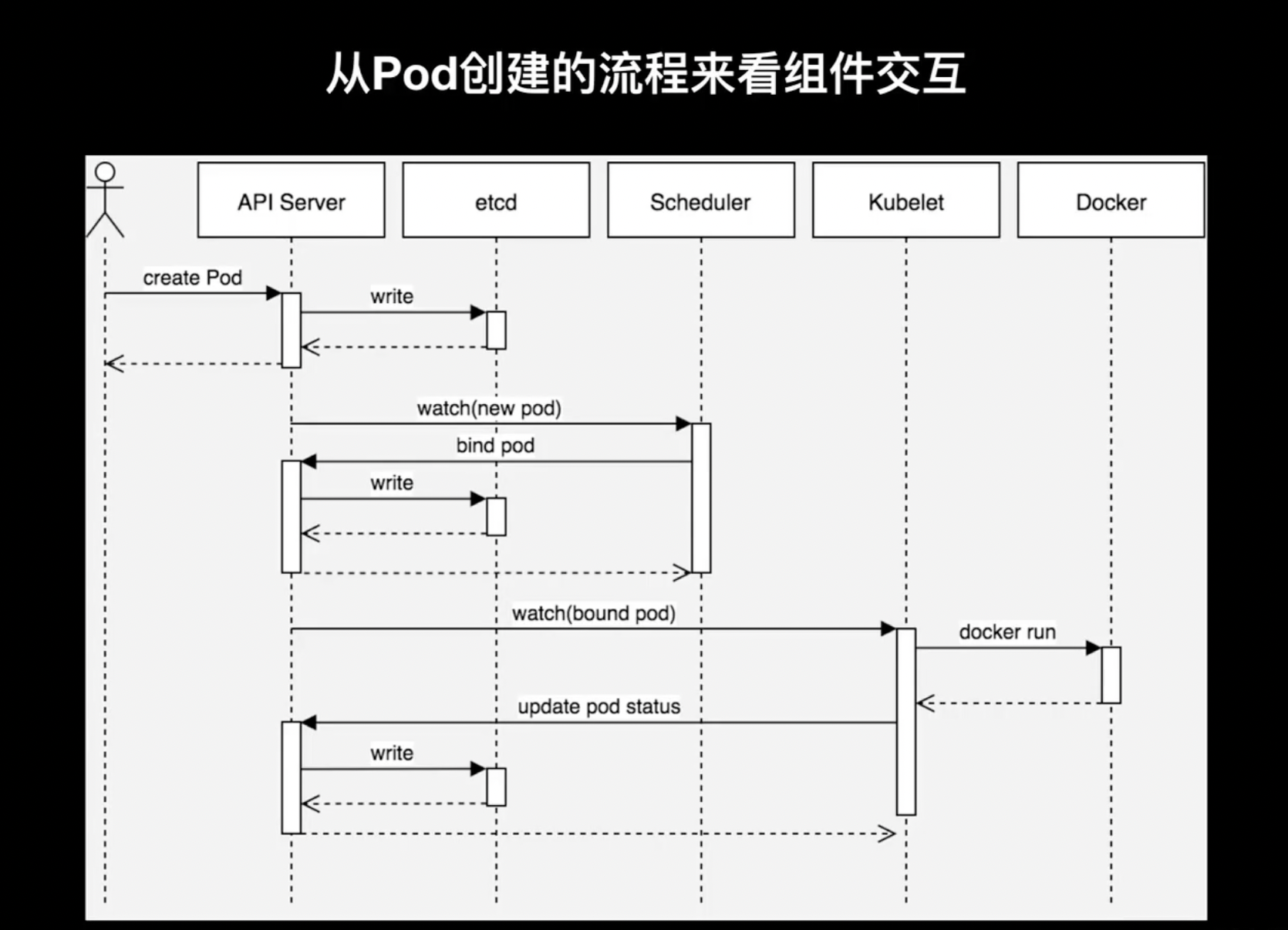
在 K8S 里面創建一個pod,首先需要對應的 yaml 檔案,然后把這個 yaml 檔案提交給 kube-apiserver,kube-apiserver 做的事情非常簡單,它只是把這個 yaml 檔案的內容傳給后邊的底層存盤 ETCD 并寫到 ETCD 中,然后接下來 kube-schedule 會通過 watch 機制定期的輪詢 kube-apiserver 中關于一些資源的變化,這里是 pod 的創建,schedule 會去 watch pod 這個資源,然后它發現 pod 有一個新的 yaml 檔案產生,他就會把這個 pod 的相關資訊拉下來,就可以看到這個 pod 的申請的資源,然后 kube-schedule 會經過一系列的計算選擇其中的一個 worker 節點,然后再把這個 worker 節點的資訊 append 到剛才生成的這個檔案上,然后再把這個 yaml 檔案回寫給 kube-apiserver ,kube-apiserver 又把這個資訊回寫到 ETCD,然后 kubelet 也監聽 kube-apiserver 里這個pod的變化,它發現有一個 pod 上面的 yaml 檔案發生變化,而且系結了一個節點,然后 kubelet 發現這個節點和我自己所在的這個節點相同,那它就會把這個 yaml 檔案拉下來,然后在自己的節點上去運行,于是通過docker run 這條命令來運行起一個 container,再把這個 container 的狀態回寫給ETCD,
這就是 pod 創建一個流程,在其中我們可以看到 kube-apiserver、ETCD、kube-schedule、kubelet 和docker 之間相互互動的流程,可以發現其中除了kube-apiserver 和其他組件有直接的互動,其他組件之間是沒有直接互動的,
這個其實是 k8s 的設計原則和設計概念,接下來我們再深入來看一下 k8s 的設計思路是什么樣子的:

-
一是面向資源簡化模型,在 k8s 中有各種各樣的抽象,比如對交付物件的抽象 pod,在 Docker 中,我們通常稱容器為 container,兩者的區別在于 pod 是 container 之上的一層抽象,一個 pod 可能包含著多個 container,此外,k8s 里還有其他的抽象例如 Deployment、StatefulSet、DaemonSet 等等,這就是 k8s 的一種設計方式,它將很多互動中涉及到的名詞或物體都抽象成了一種資源,并通過 go-restful 框架在 kube-apiserver 中實作了對應資源各種各樣的 restful API,也就是說每一個在 k8s 里面定義的抽象在 kube-apiserver 里面都能夠找到與之對應的 restful API 用于操作,
-
二是異步動作保障性能,上述在創建一個 pod 的流程中我們提到,k8s 組件之間都通過了一種 watch 監聽機制來實作,就是一種生產者消費者模式來進行遠程監聽的思路,通俗來講就是你有變化就通知我來進行操作,這其實是一個異步的動作,所有依賴于資源的組件都通過這種異步監聽的方式來實作,可以很好的來控制自己執行命令的頻度及時機來保證性能,
在 k8s 實作這種異步監聽的原理是通過 informer 機制實作對,informer 可以說是 golang 的一個類別庫,專門用來去做 k8s 中這種資源監聽的場景,其中主要會做兩件事情:一是定義的各種監控的端點,比如說創建更新、洗掉等等這樣的一個監控端點,你可以通過在這個監控端點里面注冊一些方法來實作你自己的邏輯;二是 informer 里邊實作了一個 reset 方法,在 k8s 中是命令是不可靠的,意思就是并不是說我下發一個創建pod 的命令就一定能夠執行成功,還必須要有一種機制能夠以反饋的方式去驗證是否執行成功,或者不成功的時候能有一種方式能夠去訂正,reset 就是以一個補償的方式來去實作失敗訂正,比如說我現在 watch pod 的變化,那可能我第一次的時候 miss 掉了沒有 watch,通過 reset 可以定期的輪詢剛才的 pod list 來查看這個pod 是否變化,如果有變化就再去全量更新一次,以此來幫我們協助進行訂正這個動作,
-
三是 k8s 是基于狀態機來實作這個狀態基線,所有的資訊都通過期望、實施、反饋的機制存盤在 etcd 中,資料即狀態,這個地方怎么理解呢?上述我們看到了在整個資料流中流轉的實際上是 k8s 的 yaml 檔案,它不斷的被各種各樣的組件 append 各種各樣的資訊,其中包括有一些狀態實際上是由組件進行修改的,這樣我們只要根據 k8s 中流轉的 yaml 檔案就知道當前 pod 的狀態,這其實就是狀態機的一種機制,就是我先設定我期望它能夠達到的狀態,然后我再通過一些機制去實作它,如果這個狀態沒有達到,我立馬退回到另一個狀態,但是我在任何時刻都能通過一個明確的組態檔來知道當前所處的狀態,這樣可以很好的協助我們來進行一些狀態的遷移,甚至一些 back up、restore 等等,
-
四是反饋機制保證狀態,剛才我們也提到 informer 里邊有這種定期的 reset 方法來處理中間態,來保證這個狀態機能夠到達一個期望的一個狀態,
-
五是組件之間的可插拔,組件之間的通信要么通過 kube-apiserver 進行中轉,要么通過這個API-group 進行解耦,組件之間沒有強依賴關系,部分的組件還自帶熔斷器機制,比如說像 dashboard 組件里邊就包含了類似像 JHipster 之類的熔斷器可以保證有一些組件不存在的時候,依然可以有一個降級的顯示,
在 k8s 里面最重要的一個概念就是抽象,它抽象了很多互動上面的一些內容,比如說下圖實際上是 k8s 里面抽象出的一些邏輯概念:
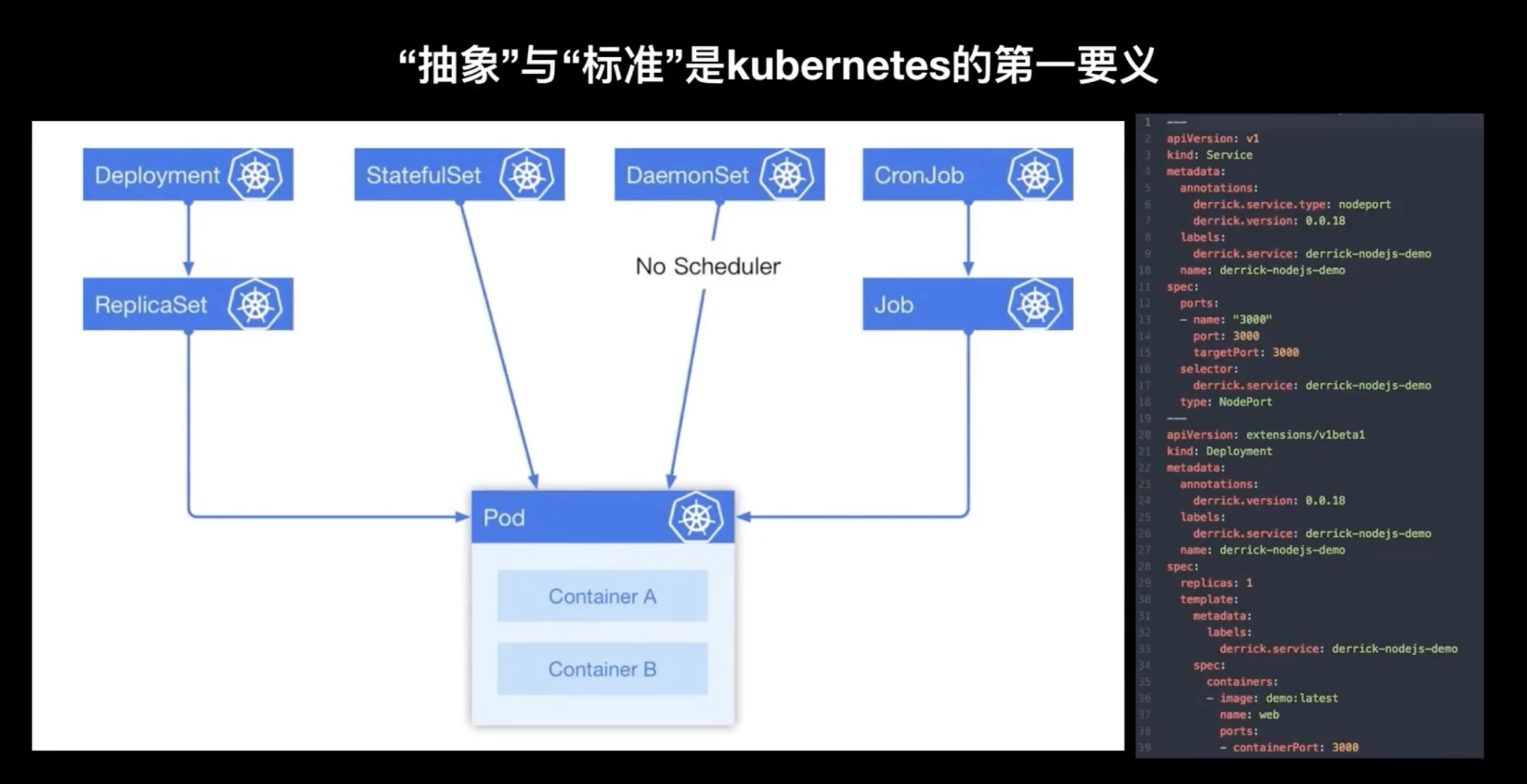
k8s 對常見的應用場景里都有對應的抽象,比如說一般的普通無狀態應用都可以用 Deployment 來表示,對于一些有狀態的應用可以會抽象成 StatefulSet,對于像在每臺機器上都要運行的守護型別的應用,它會用這個 DaemonSet 進行抽象,對于一些生命周期比較短、需要定期執行/定時執行的一些應用,會使用這個 CornJob 或者 Job 來去定義,
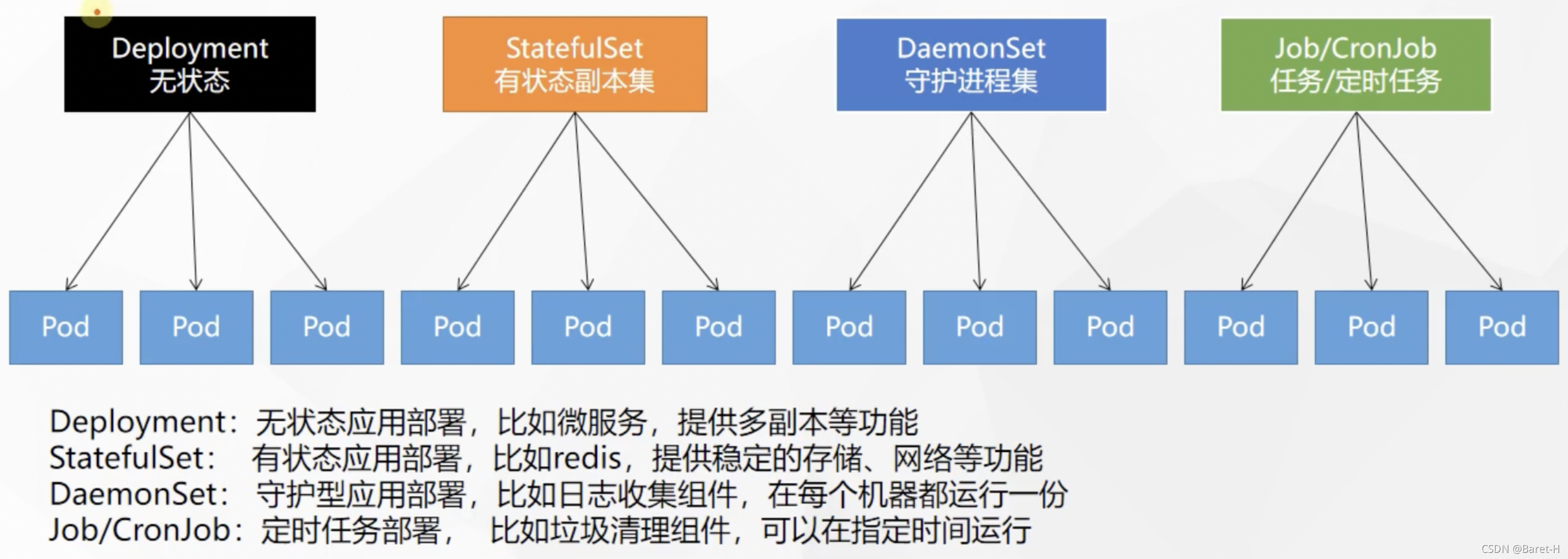
此外,對于接入層 k8s 也有抽象 service,還有對組態檔的抽象 ConfigMap,對敏感資訊的抽象 Secret,
所以在 k8s 將所有能想到的交付內容都有對應的抽象,而每一種抽象都可以用 yaml 檔案進行表達也有對應的 API 進行操作,所以 k8s 可以很好的將這個交付流程進行自動化,因為每一個抽象已經可以用代碼來表示,所以就可以很好的進行交付,
再接下來我們來看一下在 k8s 里面的兩個非常典型的 yaml 示例,第一個是 Deployment 的 yaml,第二個是 service 的 yaml,

然后我們首先來看這個deployment 的yaml:
apiVersion表示資源的API版本,在 k8s 里所有抽象都是一種資源,而資源 api 的設計的方式是 restful 的形式,所以為了保證版本的兼容,它給每一個 api 都定義了一個版本,在這個例子里面是 apps/v1 的這個版本,kind表示的就是抽象的型別,在這個例子里是 deployment,metadata表示的是對于 kind 為 Deployment 的 yaml 里邊的 meta 資訊,包括一個名字和一個label標簽,spec是真正的定義的引數,比如說這個 replicas 為3表示的是有三個副本,然后 selector 下面有一個 match labels,表示是和哪個label 進行匹配,然后在 template 里面實際上是相應的 pod 的相關的一些配置,比如說他設定了這個 meta data 里邊有這個label,然后 spec 里面有 containers 指定使用的鏡像和暴露的埠,
service 負責的是接入層,它與相應的 Deployment 之間掛載的方式是通過 label、selector 來實作的,像本地里邊要定義的這個selector,然后設定的這個label 和 deployment 的這個label 是一致的,都是nginx
上圖最右側是通過 kubectl descrive 這個nginx的Deployment ,然后可以獲取上圖的一些資訊,其實這些資訊大部分情況下都是從在 k8s 的 yaml 檔案獲取過來的,除了底下的 events 是一個獨立的部分,
8. 總結
k8s 的設計思路就是通過抽象來去定義標準化交付,掌握了這個設計思路之后可以協助這個開發者入門k8s,這樣開發者只需要了解 k8s 定義了哪些抽象以及相應面向的場景,然后剩下的就是查檔案根據不同場景選擇合適的抽象進行使用,
9. 工具推薦
1?? Kompose
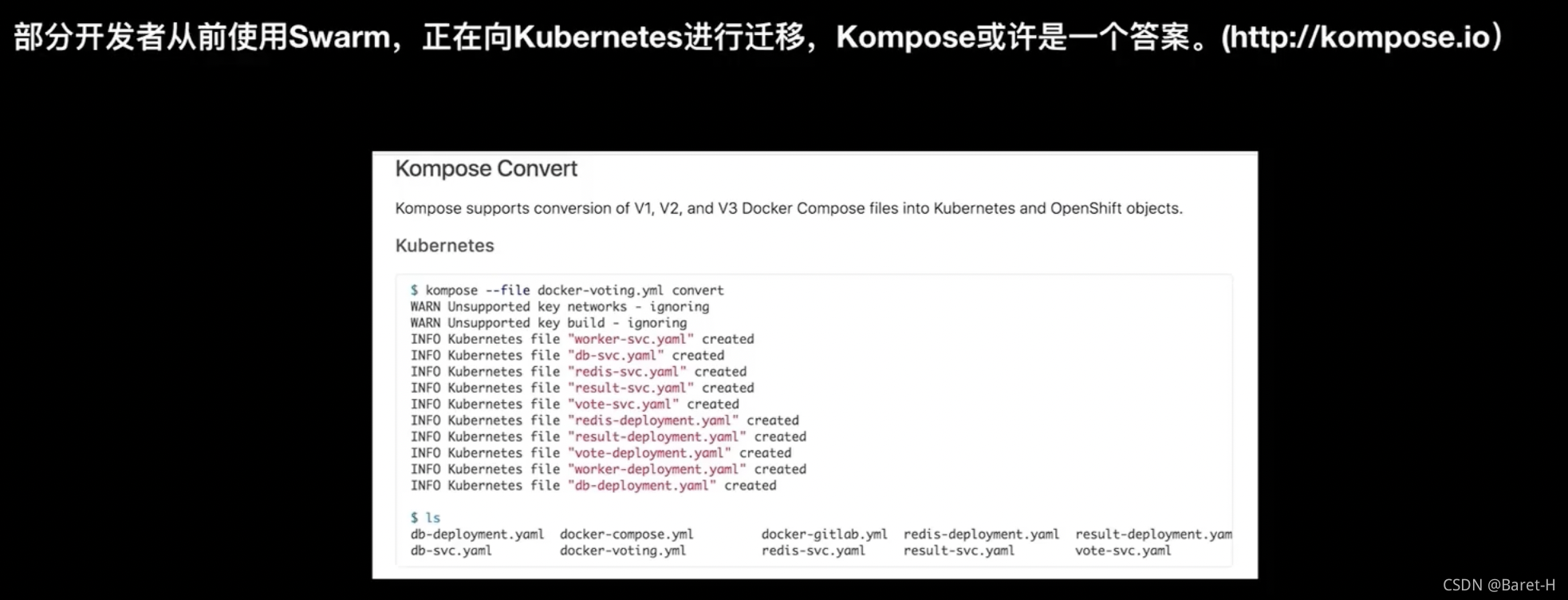
現在依然有很多的開發者在使用 Swarm,而且有客戶正在將 Swarm 的一些應用向 k8s 進行遷移,這里給大家介紹一個工具叫 Kompose,這個工具就是為了解決 Swarm 應用向 k8s 遷移問題,它可以它有兩種方式:一種方式是直接將一個docker compose 在 k8s 集群里邊部署運行起來;第二種方式是將一個 docker compose 檔案轉換成 k8s 的 yaml 檔案,
下圖所示就是通過一個標準的一個 Swarm 的一個 yaml 轉換成了 k8s 的多個 yaml,因為 k8s 的yaml 其實和swarm 的 yaml再表達的內容上面包括表達的形象利益上來講是有很多的相似性的,所以可以Kompose 的一個目標就是將這個docker composed swarm 轉換成K8S的yaml,
2?? Derrick
最后給大家介紹一個阿里云獨立開發的一個工具叫做 Derrick ,Derrick 是一個容器遷移工具,是由 python 撰寫的一個命令列工具,它可以幫助你動態的生成 DockerFile / docker compose,然后在 k8s 里面也可以生成 k8s 的 yaml 檔案,以及 Jenkins file,它目前支持 Swarm 和 k8s 兩種編排系統,支持 Java、Node.JS、Golang、Python、PHP 5種語言,三十余個框架,
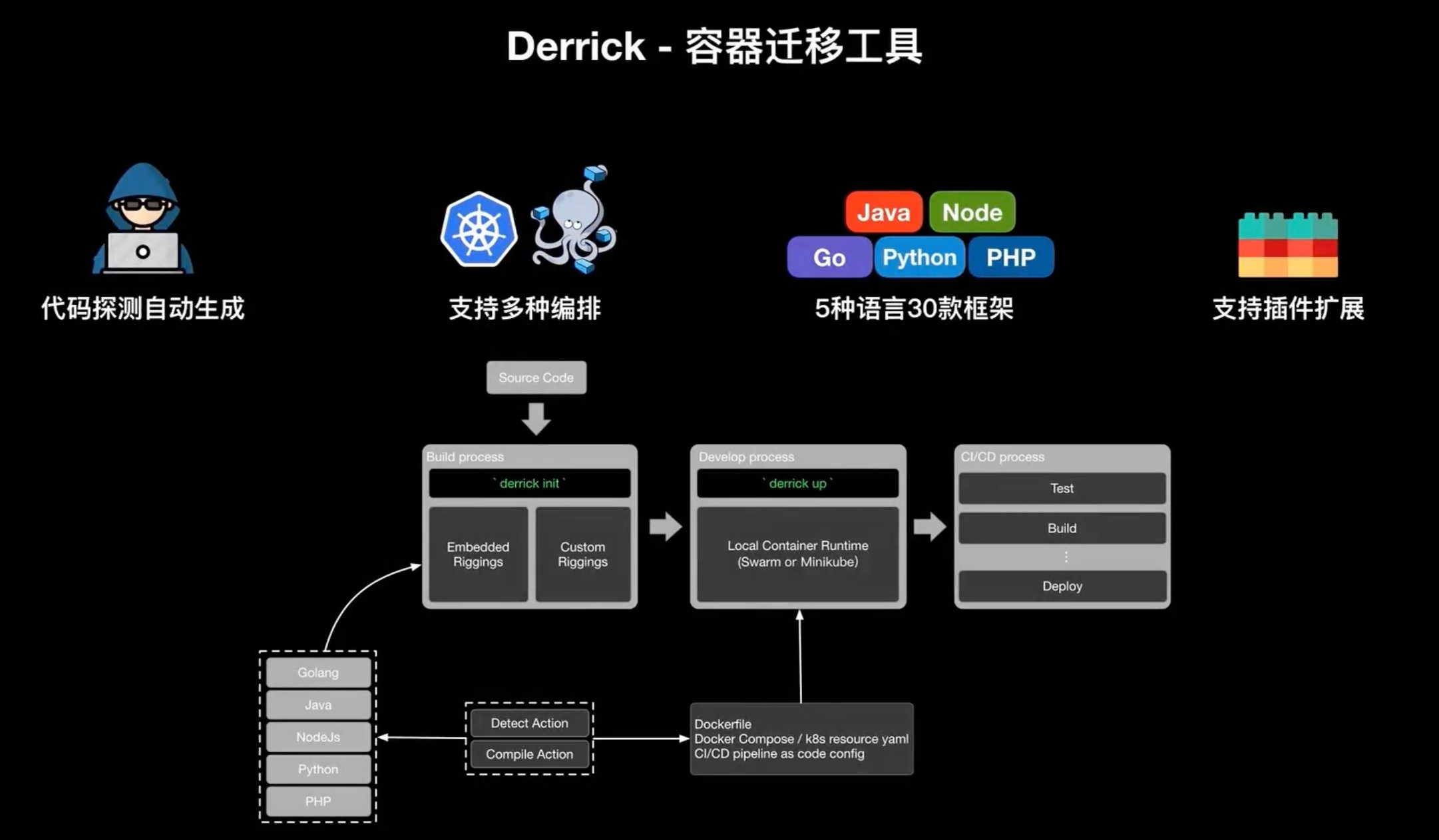
它的大致的一個實作原理就是你有一個源代碼,然后在這個源代碼根目下執行 derrick init 命令,derrick 就會探測源代碼使用的語言版本、框架型別以及一些特征資訊(比如說包管理器的一些特征資訊),然后呼叫自己內置的一些插件或者是開發者自己定義的插件,來實作相應的 build pack 機制,比如說生成 DockerFile、生成 docker compose 的yaml、 K8s的yaml、Jenkins file、publines as code 的CI/CD的配置,然后當生成完這些配置之后我們再執行 derrik up 時他會將你的這個 container 進行本地一個編譯和打包并進行本地的一個驗證,沒有問題后,你再把這些生成的配置推送到遠程的代碼倉庫,然后觸發CI/CD的一個流程來實作完整的一個本地互動互動鏈的程序,
今天我們回顧一下我們的這個課程,我們首先講了關于 DokcerFile 該怎么去撰寫,然后介紹在K8S里面的一些內置組件之間的相互依賴,以及K8S是怎么通過抽象的方式使用壓迫檔案來定義各種交付的一個產物,
最后也介紹了類似 Kompose 和 Derrick 的兩個工具,在下一節中,我們會主要針對于容器化的標準交付里面的CI/CD的部分給大家講解一下,就是一些現成的一些解決方案,以及怎么快速的搭建一個CI/CD server,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354805.html
標籤:其他
上一篇:Ubuntu21.10版本安裝zsh、配置ohmyzsh及插件、主題更換
下一篇:監控系統zabbix相關