什么是分桶?:
Hive基于hash值對資料進行分桶,按照分桶欄位的hash值除以分桶的個數進行取余(bucket_id = column.hashcode % bucket.num),
分桶的作用:
1、有更高的查詢處理效率
2、使得抽樣更高效
如何分桶?:
1、分桶之前需要執行命令set hive.enforce.bucketing=true;
2、創建分桶表
首先先創建一個普通表用于給分桶表傳資料
create table employee_id(
name string,
employee_id int,
work_place array<string>,
gender_age struct<gender:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>
)
row format delimited fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
分桶表創建:
create table employee_id_buckets(
name string,
employee_id int,
work_place array<string>,
gender_age struct<gender:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>
)
#創建兩個桶
clustered by(employee_id) into 2 buckets
row format delimited fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
執行命令set map.reduce.tasks=2;
將employee_id資料寫入到分桶表employee_id_buckets,
insert overwrite table employee_id_buckets select * from employee_id;
分桶表創建完成,
一圖看懂分桶核心操作:
分完桶之后,要去查看資料,命令為(注意關鍵字是tablesample)
select * from employee_id_buckets tablesample(bucket 1 out of 4 on employee_id)s;
核心代碼:bucket X out of Y on employee_id
上面我們創建分桶時是創建了2個桶,這邊的Y必須是創建的桶數的因子或者是整數倍,也就是說Y%2==0,
X指的是查詢Y中第幾個的桶的資料,接下來上圖片!!
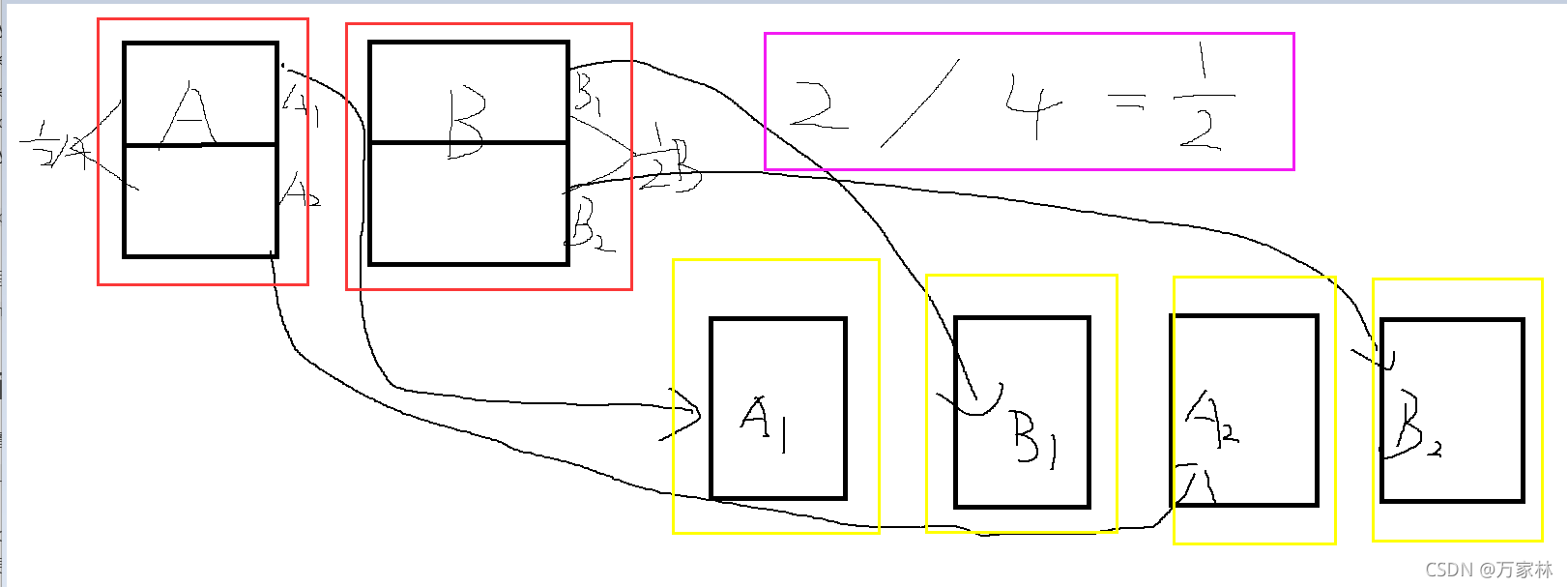
圖片些許有點潦草,但是大概能看懂意思,
這邊Y是4,也就是2的2倍,但是我們分桶是分了2個桶,所以我們這邊一塊資料就是1/2,按照順序排列開來就是A1,B1,A2,B2,這邊X是1,所以查詢的是A1的資料,也就是A桶的一半的資料,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355271.html
標籤:其他
下一篇:RabbitMq基礎