一、開發模式
per-job-cluster 提交模式
1.一個Job會對應一個Flink集群,每提交一個作業會根據自身的情況,都會單獨向yarn申請資源,直到作業執行完成,一個作業的失敗與否并不會影響下一個作業的正常提交和運行,獨享Dispatcher和ResourceManager,按需接受資源申請;適合規模大長時間運行的作業,
2.優點
每次提交都會創建一個新的flink集群,任務之間互相獨立,互不影響,方便管理,任務執行完成之后創建的集群也會消失,
Session-Cluster
1.Session-Cluster模式需要先啟動Flink集群,向Yarn申請資源,以后提交任務都向這里提交,這個Flink集群會常駐在yarn集群中,除非手工停止,
2.缺點
如果提交的作業中有長時間執行的大作業, 占用了該Flink集群的所有資源, 則后續無法提交新的job.
3.優點
Session-Cluster適合那些需要頻繁提交的多個小Job, 并且執行時間都不長的Job.
(因為使用其他模式 頻繁提交多個小job,導致申請資源時間大于 執行job時間)
二、運行時架構
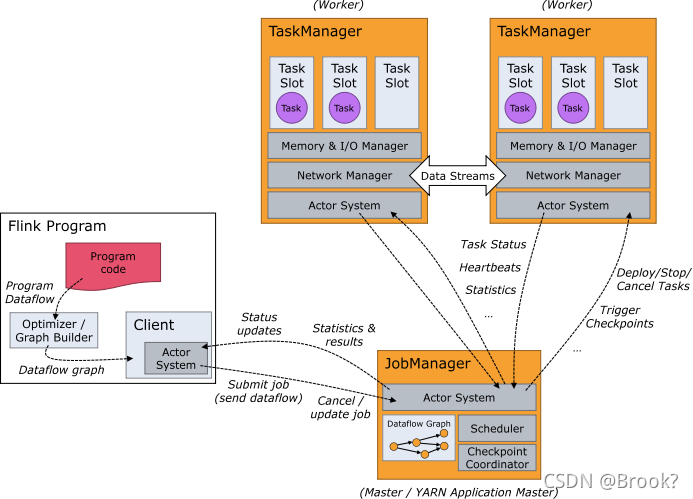
1 job manager
1>ResourceManager
整個 Flink 集群中只有一個 ResourceManager. 注意這個ResourceManager不是Yarn中的ResourceManager, 是Flink中內置的, 只是趕巧重名了而已.
主要負責管理任務管理器(TaskManager)的插槽(slot),TaskManger插槽是Flink中定義的處理資源單元,
2>Dispatcher
負責接收用戶提供的作業,并且負責為這個新提交的作業啟動一個新的JobMaster 組件. Dispatcher也會啟動一個Web UI,用來方便地展示和監控作業執行的資訊,Dispatcher在架構中可能并不是必需的,這取決于應用提交運行的方式,
3> JobMaster
JobMaster負責管理單個JobGraph的執行.多個Job可以同時運行在一個Flink集群中, 每個Job都有一個自己的JobMaster.
2.TaskManager
Flink中的作業行程,通常在Flink中會有多個TaskManager運行,每一個TaskManager都包含了一定數量的插槽(slots),插槽的數量限制了TaskManager能夠執行的任務數量,
啟動之后,TaskManager會向資源管理器注冊它的插槽;收到資源管理器的指令后,TaskManager就會將一個或者多個插槽提供給JobManager呼叫,JobManager就可以向插槽分配任務(tasks)來執行了,
任務流程
- Flink任務提交后,Client向HDFS上傳Flink的Jar包和配置
- 向Yarn ResourceManager提交任務,ResourceManager分配Container資源
- 通知對應的NodeManager啟動ApplicationMaster,ApplicationMaster啟動后加載Flink的Jar包和配置構建環境,然后啟動JobManager
- ApplicationMaster向ResourceManager申請資源啟動TaskManager
- ResourceManager分配Container資源后,由ApplicationMaster通知資源所在節點的NodeManager啟動TaskManager
- NodeManager加載Flink的Jar包和配置構建環境并啟動TaskManager
TaskManager啟動后向JobManager發送心跳包,并等待JobManager向其分配任務,
三、核心概念
什么是slot?
插槽,每個TaskManager 默認配置 1, 一般配置和cpu核心數,多個slot均分 TaskManager 的記憶體資源,與其他slot之間 記憶體隔離,共享cpu資源,slot內共享(多個task 和共享一塊記憶體)
一個job 分配多少個 slot?
所有slot共享組最大并行度之和
slot 共享組?
.slotSharingGroup("group1")
默認只有一個共享組,不同的共享組之間一定占用不同的slot
任務鏈?
多個算子 之間 組成任務鏈
Stream在算子之間傳輸資料的形式可以是one-to-one(forwarding)的模式也可以是redistributing的模式,具體是哪一種形式,取決于算子的種類,
- One-to-one:
stream(比如在source和map operator之間)維護著磁區以及元素的順序,那意味著flatmap 算子的子任務看到的元素的個數以及順序跟source 算子的子任務生產的元素的個數、順序相同,map、fliter、flatMap等算子都是one-to-one的對應關系,
- Redistributing:
stream(map()跟keyBy/window之間或者keyBy/window跟sink之間)的磁區會發生改變,每一個算子的子任務依據所選擇的transformation發送資料到不同的目標任務,例如,keyBy()基于hashCode重磁區、broadcast和rebalance會隨機重新磁區,這些算子都會引起redistribute程序,而redistribute程序就類似于Spark中的shuffle程序,
并行度相同的 前后兩個算子,并且one_to_one傳輸,則flink (自動優化)會將這兩個 task合并,
目的:減少資料交換產生的消耗,在減少時延的同時提升吞吐量,
當然也可以斷開這兩個算子
* 算子.startNewChain() => 與前面斷開
* 算子.disableChaining() => 與前后都斷開
* env.disableOperatorChaining() => 全域都不串
斷開操作鏈的好處在于減少某個slot的壓力,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355273.html
標籤:其他
上一篇:RabbitMq基礎
下一篇:搭建Zookeeper集群