華為云Hadoop與Spark集群環境搭建流程
- Hadoop 2.7.1環境搭建
- 1、購買華為云服務器
- 2、修改服務器相關配置
- 3、配置ssh免密登錄
- 4、JDK安裝
- 5、Hadoop集群搭建
- Spark 3.2.0集群環境搭建
- 1、Spark安裝
- 2、Spark檔案配置
- 3、啟動Spark集群
- 4、關閉Spark集群
所使用安裝包及對應版本:
- JDK 8
- Hadoop 2.7.1
- Spark 3.2.0
Hadoop 2.7.1環境搭建
1、購買華為云服務器
在華為云平臺購買3臺centos彈性云服務器,一臺作為master,另外兩臺作為slave,它們在同一內網中,相互之間是能ping通的,
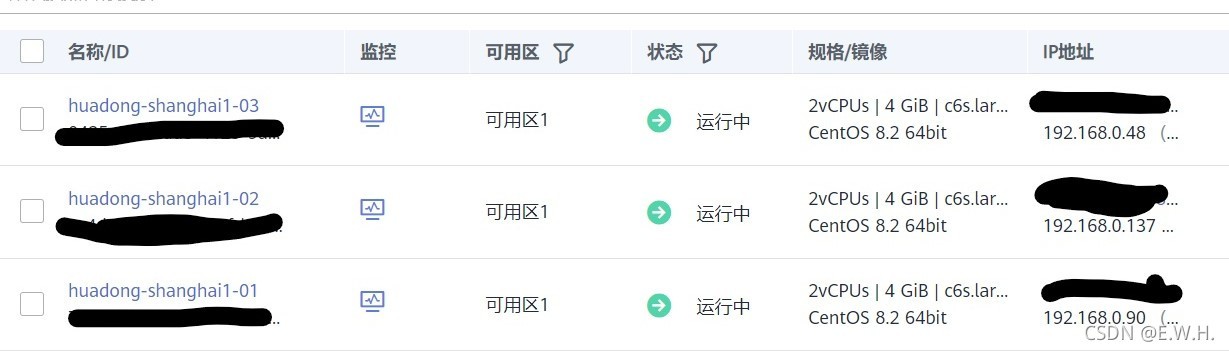
2、修改服務器相關配置
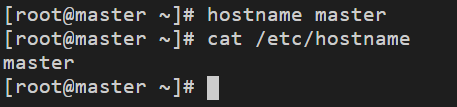
1. CloudShell遠程登錄master主機,使用如下命令修改主機名為master:
# hostname master
再進入/etc/hostname檔案,修改檔案內容為master,重新建立會話連接,就能看到主機名已經被修改為master,
同理,修改另外兩臺服務器主機名分別為slave01,slave02,
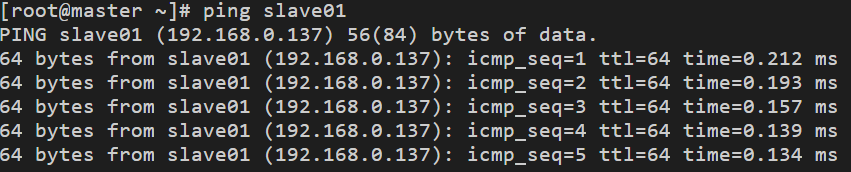
2. 分別進入三臺主機的/etc/hosts檔案,修改配置為
127.0.0.1 localhost
192.168.0.90 master
192.168.0.137 slave01
192.168.0.48 slave02
這樣,不需要輸入IP地址,只需輸入相應主機名就能ping通對應主機,
3、配置ssh免密登錄
在master主機上輸入如下命令并輸入對應密碼即可登錄slave01主機:
# ssh slave01
但在Hadoop集群環境中不可能每次都要master輸入slave的密碼,所以需要配置ssh免密登錄,華為云彈性云服務器默認配置了ssh服務,可通過如下命令查看ssh服務狀態,出現sshd行程則表示服務已經啟動,
# ps -e | grep ssh
在master主機上輸入如下命令,遇到選項全部回車或者yes即可,注:這里需要輸入一次slave01和slave02的密碼,
# cd /root/.ssh
# ssh-keygen -t rsa
# ssh-copy-id -i /root/.ssh/id_rsa.pub master
# ssh-copy-id -i /root/.ssh/id_rsa.pub slave01
# ssh-copy-id -i /root/.ssh/id_rsa.pub slave01
配置完成后,若通過命令ssh slave01和ssh slave02能直接登錄slave01和slave02主機,則免密登錄配置完成,
4、JDK安裝
在Hadoop官網上看到不同版本的Hadoop支持的jdk版本: Hadoop對應jdk版本
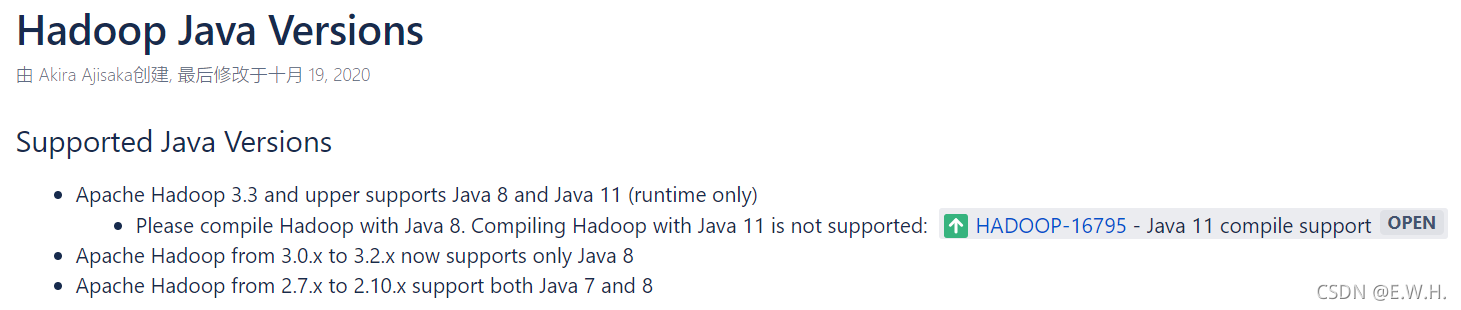
可以看到Hadoop 2.0支持Java 7和Java 8(更高的版本會報錯),這里提供本文使用的JDK8網盤鏈接,
鏈接:https://pan.baidu.com/s/1vZzs0E_3aSxRuUqoPW8C6g
提取碼:vwk5
在master主機的/usr/local目錄下新建java檔案夾,將下載好的JDK8安裝包上傳到java檔案夾中,并使用如下命令進行壓縮包的解壓:
# cd /usr/local/java
# tar -zxvf jdk-8u202-linux-x64.tar.gz
效果如圖:
使用如下命令打開/etc/profile組態檔:
# vim /etc/profile
在檔案末行添加如下java環境變數:
export JAVA_HOME=/usr/local/java/jdk1.8.0_202
export CLASSPATH=:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
輸入如下命令使組態檔生效:
# source /etc/profile
可輸入命令java或javac來查看JDK是否安裝成功,
在主機slave01和slave02上使用同樣的方法進行JDK的安裝,或者使用如下檔案拷貝命令將master整個java目錄拷貝給slave01和slave02:
# scp -r /usr/local/java/ root@slave01:/usr/local/java/
# scp -r /usr/local/java/ root@slave02:/usr/local/java/
注:slave01與slave02的java環境變數也要記得配,
5、Hadoop集群搭建
1、環境配置
本文搭建的Hadoop平臺版本為2.7.1,這里附上百度網盤鏈接,
鏈接:https://pan.baidu.com/s/1HwmgNu502HmYBcZRhbUjgg
提取碼:9t4d
在master主機的/usr/local目錄下新建hadoop檔案夾,將下載好的hadoop壓縮包上傳到該檔案夾中,使用如下命令進行解壓:
# cd /usr/local/hadoop
# tar -zxvf hadoop-2.7.1.tar.gz
修改組態檔/etc/profile,添加如下配置:
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
輸入命令使組態檔生效:
# source /etc/profile
2、修改相關檔案
修改master主機中Hadoop的如下組態檔,這些組態檔都位于/usr/local/hadoop/hadoop-2.7.1/etc/hadoop目錄下,
- 修改slaves檔案,這里讓master節點主機僅作為NameNode節點使用,
slave01
slave02
- 修改hadoop-env.sh export JAVA_HOME項:
export JAVA_HOME=/usr/local/java/jdk1.8.0_202
注:這里需要顯示申明JAVA_HOME,不然會在運行的時候出現找不到java路徑的錯誤,
- 修改core-site.xml:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/hadoop-2.7.1/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
- 修改hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop-2.7.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop-2.7.1/hdfs/data</value>
</property>
</configuration>
- 修改mapred-site.xml:
將mapred-site.xml.template檔案內容復制到mapred-site.xml,再修改mapred-site.xml檔案,相關命令和修改內容如下:
# cd /usr/local/hadoop/hadoop-2.7.1/etc/hadoop
# cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 修改yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
3、slave節點配置Hadoop
通過如下命令將master主機的hadoop目錄拷貝給slave01和slave02,
# scp -r /usr/local/hadoop/ root@slave01:/usr/local/hadoop/
# scp -r /usr/local/hadoop/ root@slave02:/usr/local/hadoop/
再配置/etc/profile檔案中Hadoop相關環境變數即可,
4、啟動Hadoop集群
在master主機中輸入如下命令即可啟動Hadoop集群:
# cd /usr/local/hadoop/hadoop-2.7.1
# bin/hdfs namenode -format
# sbin/start-all.sh
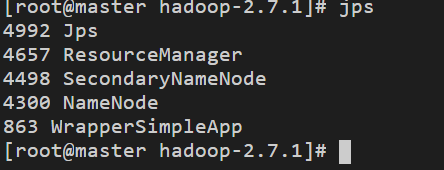
在master主機中輸入命令jps即可看到如下行程資訊,
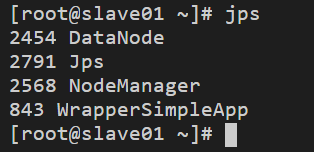
在slave01中輸入命令jps即可看到如下行程資訊,
注:關閉Hadoop集群命令如下,盡量保證服務有開就有停,可以避免很多問題出現,
# sbin/stop-all.sh
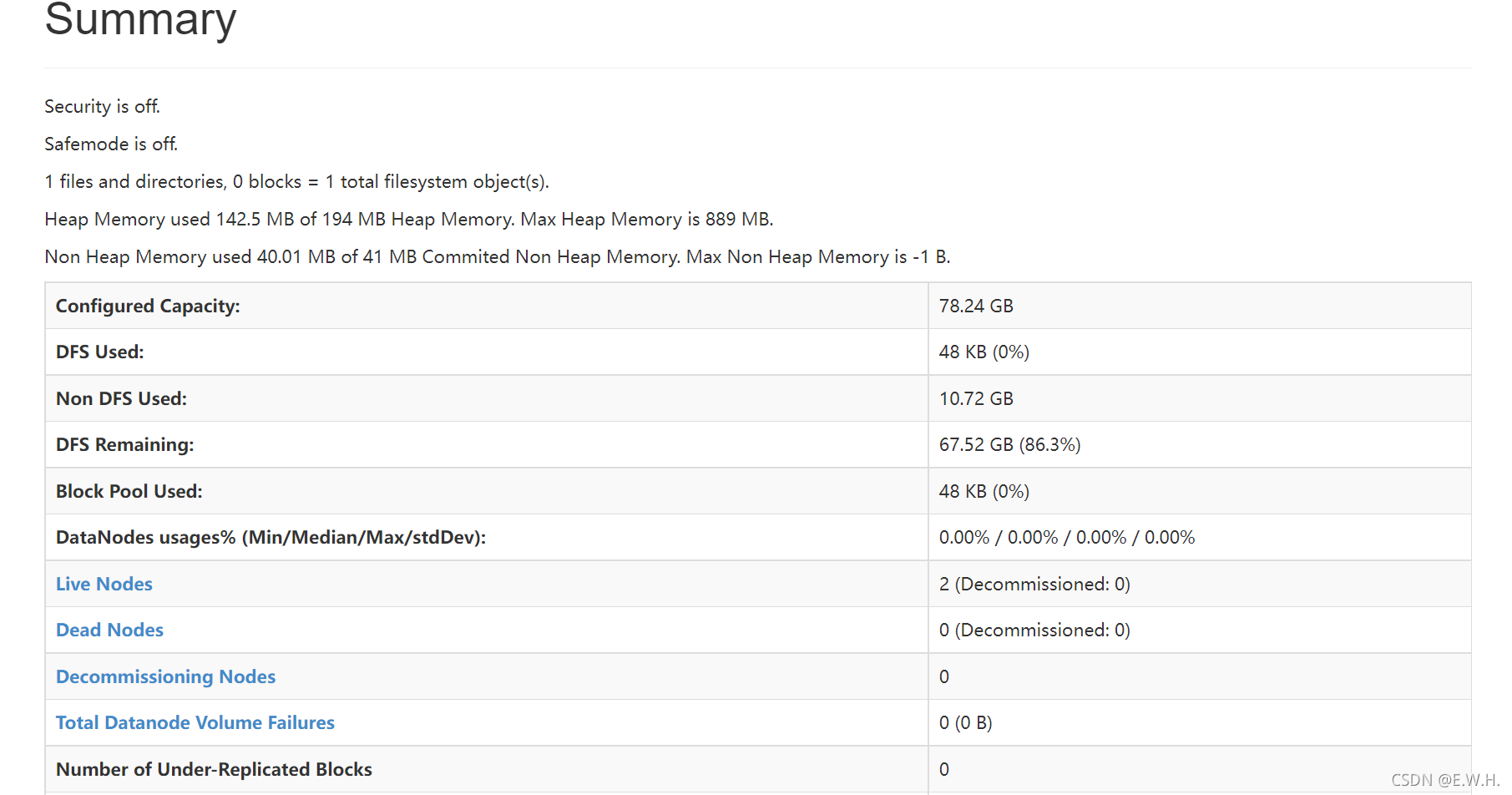
5、查看Hadoop管理頁面
瀏覽器輸入http://master公網IP:50070即可訪問到如下Hadoop管理頁面,
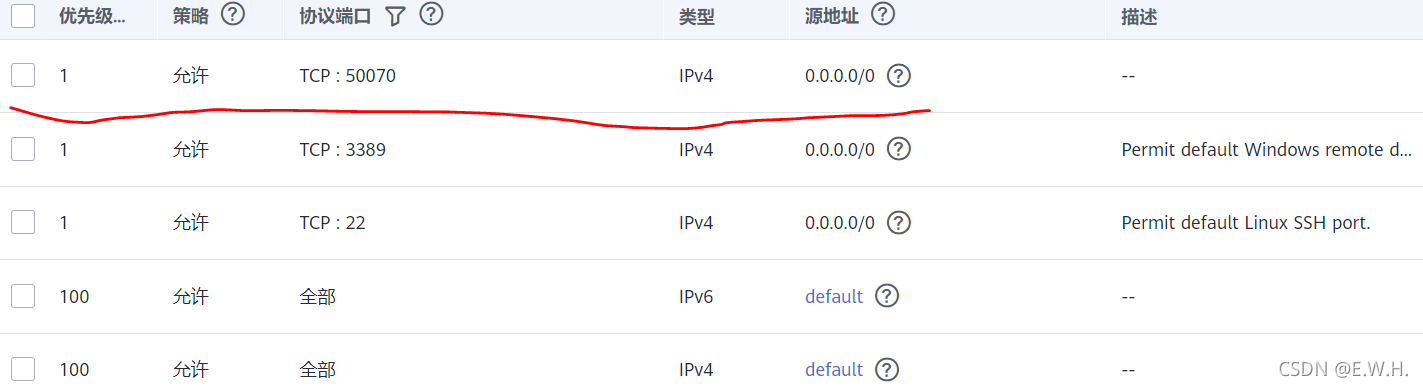
注:若打不開Hadoop管理頁面,可能是HDFS中NameNode的默認埠50070沒有開放,在華為云服務器安全組中添加如下規則即可,
Spark 3.2.0集群環境搭建
1、Spark安裝
Spark分布式集群的安裝環境,需要事先配置好Hadoop的分布式集群環境,可以去Apache官網下載與Hadoop匹配的Spark版本,
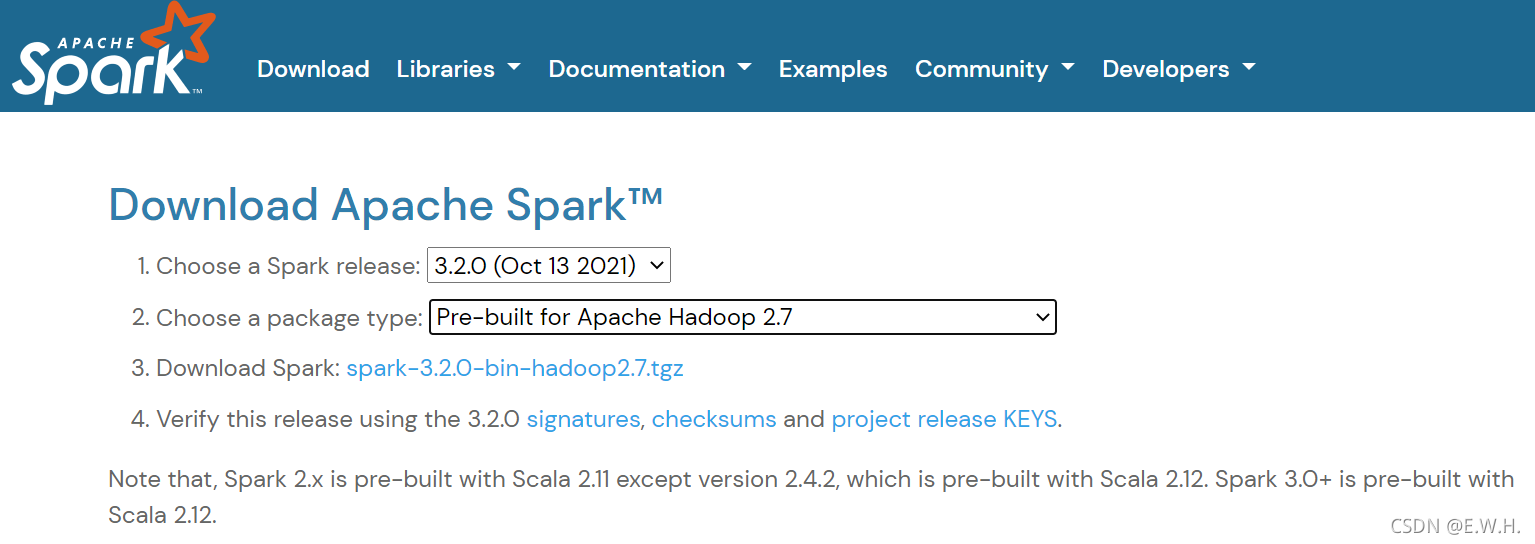
這里附上本文使用的Spark 3.2.0網盤鏈接,
鏈接:https://pan.baidu.com/s/1R40ZXixzRyPT04uGhBgKfw
提取碼:35fl
這里同樣先搭建master主機的Spark環境,再通過檔案拷貝搭建slave01與slave02環境,在master主機的/usr/local目錄下新建spark檔案夾,將下載好的Spark壓縮包上傳到該檔案夾中,使用如下命令進行解壓,并修改檔案夾名稱為spark-3.2.0:
# cd /usr/local/spark
# tar -zxvf spark-3.2.0-bin-hadoop2.7.tgz
# mv spark-3.2.0-bin-hadoop2.7 spark-3.2.0
打開/etc/profile檔案,添加如下配置:
export SPARK_HOME=/usr/local/spark/spark-3.2.0
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
并使用如下命令使配置生效:
# source /etc/profile
2、Spark檔案配置
在master主機上進行如下操作:
- 配置workers檔案:
將workers.template 拷貝到workers
# cd /usr/local/spark/spark-3.2.0/conf
# cp workers.template workers
workers檔案設定Worker節點,把默認內容localhost替換成如下內容:
slave01
slave02
- 配置spark-env.sh檔案:
將 spark-env.sh.template 拷貝到 spark-env.sh
#cp spark-env.sh.template spark-env.sh
編輯spark-env.sh,添加如下內容:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/hadoop-2.7.1/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.7.1/etc/hadoop
export SPARK_MASTER_IP=192.168.0.90
export JAVA_HOME=/usr/local/java/jdk1.8.0_202
注:
① SPARK_MASTER_IP 指定 Spark 集群 Master 節點的 IP 地址,
② 最后一行的JAVA_HOME一定要申明,不然會出現slave節點找不到JAVA_HOME的錯誤,
配置好后,將Master主機上的/usr/local/spark檔案夾復制到各個節點上,在Master主機上執行如下命令:
# scp -r /usr/local/spark/ root@slave01:/usr/local/spark/
# scp -r /usr/local/spark/ root@slave02:/usr/local/spark/
注:別忘了配置slave01與slave02的/etc/profile檔案,
3、啟動Spark集群
1、啟動Hadoop集群
啟動Spark集群前,要先啟動Hadoop集群,在Master節點主機上運行如下命令:
# cd /usr/local/hadoop/hadoop-2.7.1
# sbin/start-all.sh
2、啟動Spark集群
- 啟動Master節點
在Master節點主機上運行如下命令:
# cd /usr/local/spark/spark-3.2.0
# sbin/start-master.sh
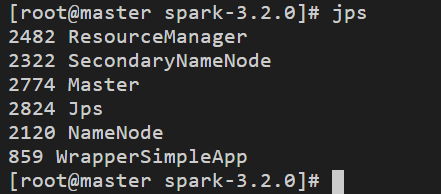
在Master節點上運行jps命令,可以看到多了個Master行程:
- 啟動所有Slave節點
在Master節點主機上運行如下命令:
# sbin/start-slaves.sh
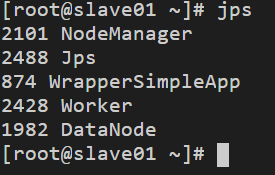
分別在slave01、slave02節點上運行jps命令,可以看到多了個Worker行程
3、在瀏覽器上查看Spark獨立集群管理器的集群資訊
打開瀏覽器,訪問http://master公網IP:8080,如下圖:
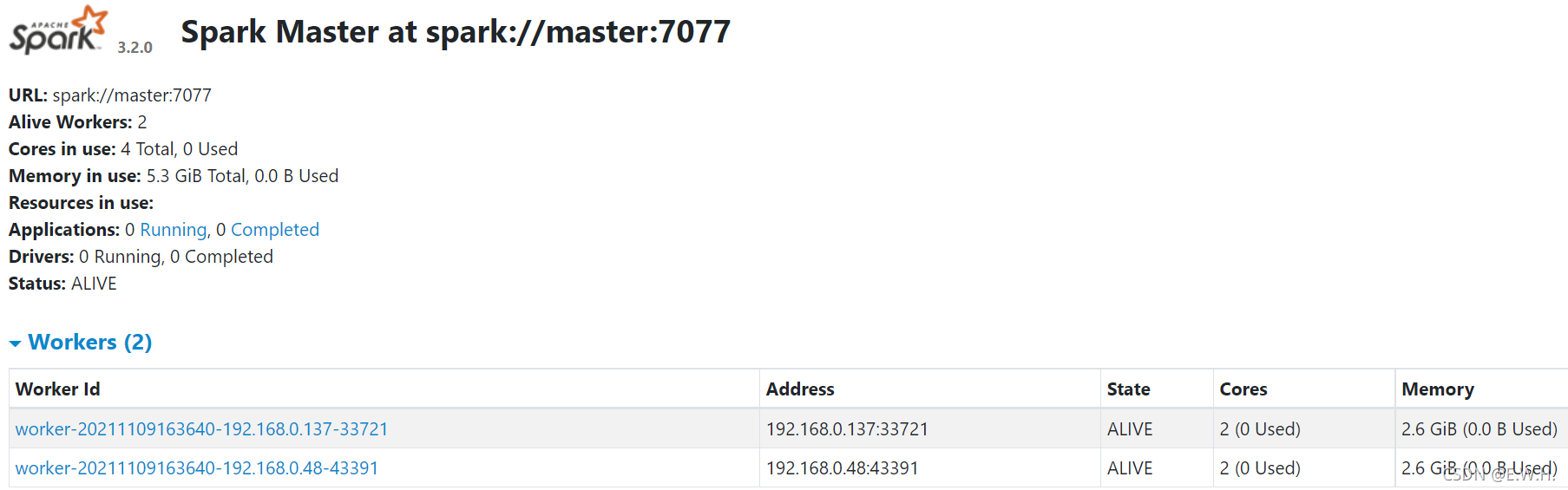
注:若無法訪問,可能是安全組8080埠未開放,安全組中開放8080埠即可,
4、關閉Spark集群
1、關閉master節點
# sbin/stop-master.sh
2、關閉Worker節點
# sbin/stop-slaves.sh
3、關閉Hadoop集群
# cd /usr/local/hadoop/hadoop-2.7.1
# sbin/stop-all.sh
參考檔案:
http://dblab.xmu.edu.cn/blog/1177-2/
http://dblab.xmu.edu.cn/blog/1187-2/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355275.html
標籤:其他
上一篇:搭建Zookeeper集群