SparkSQL編程讀寫Hive資料源
- 一、準備作業
- 二、任務分析
- 三、編碼實作
- 五、運行測驗
一、準備作業
- 實驗環境:IDEA + CentOS7 + Spark2.4.8+Hive2.3.3+MySQL2.7+Hadoop2.7.3
- 資料準備:Hive中的emp員工資訊表
- 前置作業:
- Hadoop開啟HDFS服務(
必選) - 開啟hiveserver2服務(可選)
- 開啟Spark服務(可選)
- 將hive-site.xml復制到idea工程下的resources目錄下(
必選)
- Hadoop開啟HDFS服務(
二、任務分析
借助sparksql讀寫hive表,利用純的SQL來完成對emp表中按照部門求其工資,并按照工資總額進行降序排序,
三、編碼實作
- 創建maven工程
- 添加maven依賴,即在pom.xml中添加hive的依賴,spark的依賴請參考之前的實驗,如下:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>2.4.8</version> </dependency> - 將虛擬機中的hive-site.xml匯出來,并放置在idea工程resources目錄下,如圖所示:
- 創建
HiveDemo.scala的object物件,撰寫如下代碼即可:
import org.apache.spark.sql.SparkSession
object HiveDemo {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[2]")
.appName("Test")
// 如不配置,則使用本地的warehouse
.config("spark.sql.warehouse.dir", "hdfs://niit01:9000/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()
// 引入隱士函式
import spark.implicits._
import spark.sql
sql("select deptNo,sum(sal) as total from emp group by deptNo order by total desc").show
// 關銑澩
spark.stop()
}
}
注意:代碼中的.config部分是hdfs上的路徑,故需要開啟hdfs服務,如洗掉.config,則會在工程目錄下生成metastore_db目錄,其作為hive的元資料庫的目錄
五、運行測驗
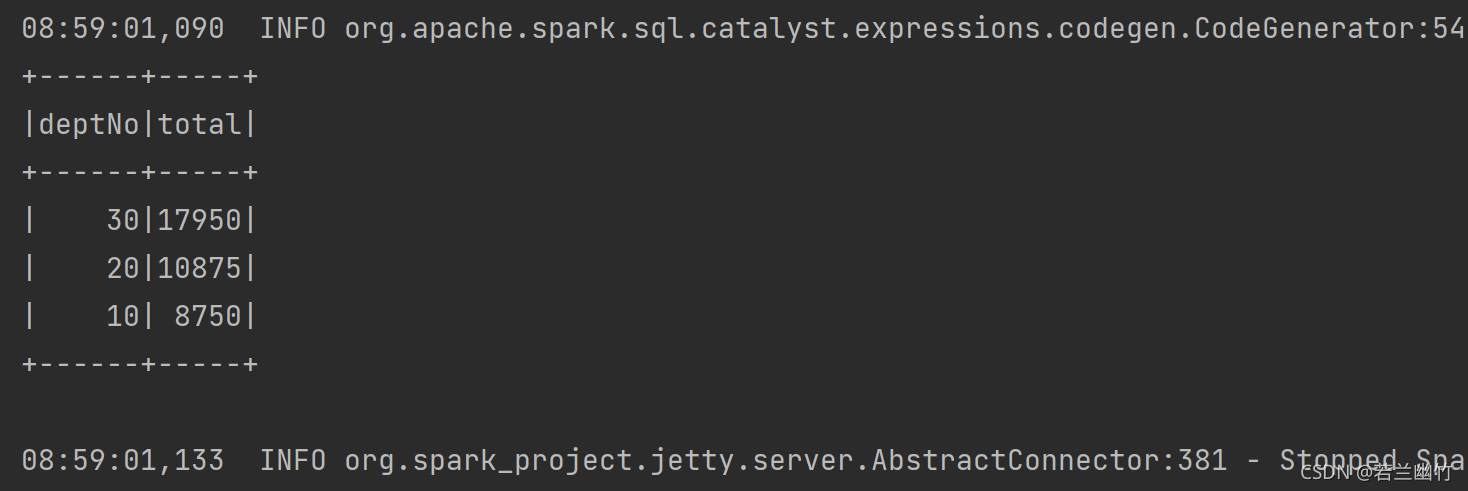
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355280.html
標籤:其他
上一篇:終于拿到阿里Java后端offer,只因我做了這個決定...
下一篇:08-hive中的函式